






在处理时间序列数据时,时间特征往往是最基础且独特的要素,我们的目标通常是预测某种未来的响应或结果。
不过在很多情况下,除了时间特征之外,我们还能获取到一系列其他相关的特征或变量。
时间序列数据中的特征工程涉及从原始时间序列数据中创建信息丰富的特征,以提升机器学习模型的性能。

以下是时间序列数据中一些常见的特征类型:
日期时间相关特征: 这些特征是从日期时间列中提取的,如月份、日期、星期几、小时等。在时间序列中,这些特征可能包含有助于机器学习算法学习的某种影响或模式。
滞后特征: 滞后特征涉及使用时间序列的过去值作为特征。例如,你可以通过包括时间序列在先前时间步长的值作为预测因子来创建滞后特征。这允许模型捕捉时间依赖性。
窗口特征: 时间序列中的基于窗口的特征工程涉及在固定大小的窗口或间隔内聚合数据以创建特征。这种技术捕捉时间序列中的局部行为和时间模式。一些例子包括3天平均值、2天中位数等。
周期性特征: 时间序列中的周期性特征指的是捕获在特定间隔内重复出现的模式或周期的变量。这些特征对于建模时间序列数据中的季节性和其他周期性模式至关重要。例如,与同年6月相比,12月更接近下一年的1月。但在机器学习中,当我们输入月份列时,12月会被标记为12,1月会被标记为1,6月则是6。
为了让机器学习算法理解这一点,我们需要引入周期性特征来捕捉这些关系。
接下来,是编码阶段,本文的核心是简化这些特征的提取过程。
现在,让我们通过一个例子来深入探索:
数据集和时间序列、大语言模型LLM学习资料一起打包好了
**

# Importing the Data and Cleaning them
import pandas as pd
import matplotlib.pyplot as plt
filename = 'AirQualityUCI.csv'
# load the data
data = pd.read_csv(
filename, sep=';', parse_dates=[['Date', 'Time']]
).iloc[:, :-2] # drops last 2 columns, not real variables
# drop missing values
data.dropna(inplace=True)
new_var_names = [
'Date_Time',
'CO_true',
'CO_sensor',
'NMHC_true',
'C6H6_true',
'NMHC_sensor',
'NOX_true',
'NOX_sensor',
'NO2_true',
'NO2_sensor',
'O3_sensor',
'T',
'RH',
'AH',
]
data.columns = new_var_names
predictors = data.columns[1:]
for var in predictors:
if data[var].dtype =='O':
data[var] = data[var].str.replace(',', '.')
data[var] = pd.to_numeric(data[var])
data['Date_Time'] = data['Date_Time'].str.replace('.', ':', regex=False)
data['Date_Time'] = pd.to_datetime(data['Date_Time'],dayfirst=True)
data.sort_index(inplace=True)
data.to_csv('AirQualityUCI_Cleaned.csv', index=False)
上述代码将清理数据。接下来,我们需要通过pip安装feature-engine库,它是一个为时间序列数据特征工程提供大量便捷功能的库。
pip install feature-engine
然后,导入创建特征所需的库,
import numpy as np
import pandas as pd
from feature_engine.creation import CyclicalFeatures
from feature_engine.datetime import DatetimeFeatures
from feature_engine.imputation import DropMissingData
from feature_engine.selection import DropFeatures
from feature_engine.timeseries.forecasting import LagFeatures, WindowFeatures
包括来自Sklearn的Pipeline,它有助于我们执行特征工程。
# In this function we load a dataset from UCI website, we parse the columns, and sort the time, filter and remove the outliers
def load_data():
# Data lives here.
filename = "AirQualityUCI_Cleaned.csv"
# Load data: only the time variable and CO.
data = pd.read_csv(
filename,
usecols=["Date_Time", "CO_sensor", "RH"],
parse_dates=["Date_Time"],
index_col=["Date_Time"],
)
# Sanity: sort index.
data.sort_index(inplace=True)
# Reduce data span.
data = data.loc["2004-04-01":"2005-04-30"]
# Remove outliers
data = data.loc[(data["CO_sensor"] >= 0) & (data["RH"] >= 0)]
return data
# Load data.
data = load_data()
提取日期时间特征
第一步是从日期时间字段中提取日期时间特征。
datetime_features= DatetimeFeatures( variables='index',
features_to_extract=['month',
'week',
'day_of_week',
'day_of_month',
'hour',
'weekend'])
data=datetime_features.fit_transform(data)
在本例中,我们使用索引作为变量,因为时间序列字段已被设置为索引。
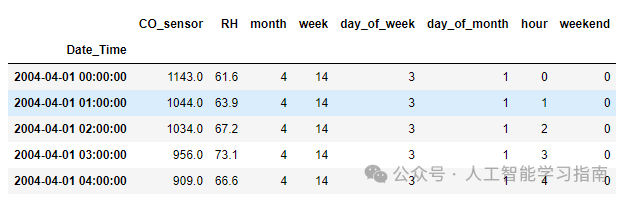
提取滞后特征
lag_features= LagFeatures(variables=['CO_sensor','RH'],
freq=['1H','24H'],
missing_values='ignore')
data= lag_features.fit_transform(data)
data.head(26)
在这里,我们创建滞后特征。请注意,在上面的代码中,我们将频率设置为1小时和24小时,因此它会为每个上面定义的变量创建两个单独的特征。
# Seeing all the Lag Features alone
data[[features for features in data.columns if 'lag' in features]]
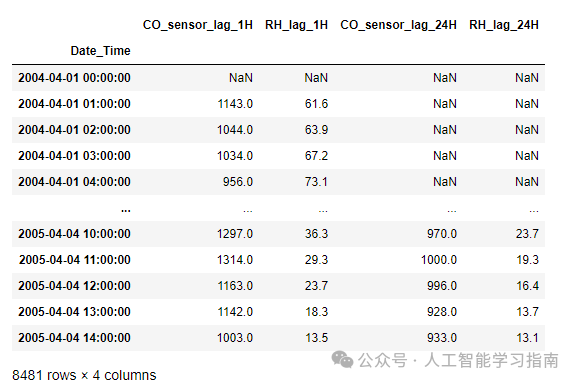
基于窗口的特征
window_features= WindowFeatures(variables=['CO_sensor','RH'],
window='3H', # This will window the last 3 hours
freq='1H', # Do this for every hour
missing_values='ignore')
data=window_features.fit_transform(data)
这将创建一个3小时移动平均值的窗口特征。由于该函数在上方未定义,因此默认情况下它会采用平均值作为窗口函数。
# Seeing all the Window Features alone
data[[features for features in data.columns if 'window' in features]]
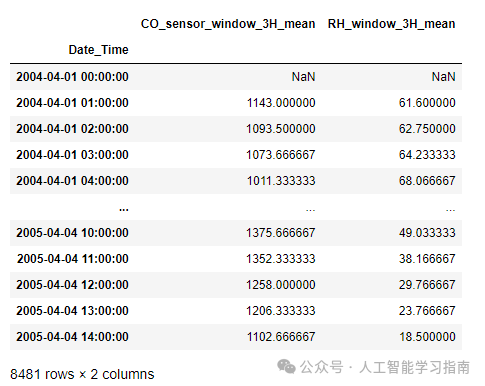
周期性特征
如上所述,周期性特征将保持月份或其他日期字段的连续性。
cyclic_features= CyclicalFeatures(variables=['month','hour'],
drop_original=False)
data= cyclic_features.fit_transform(data)
# Seeing all the Periodic Features alone
data[[features for features in data.columns if 'month' in features or 'hour' in features]]
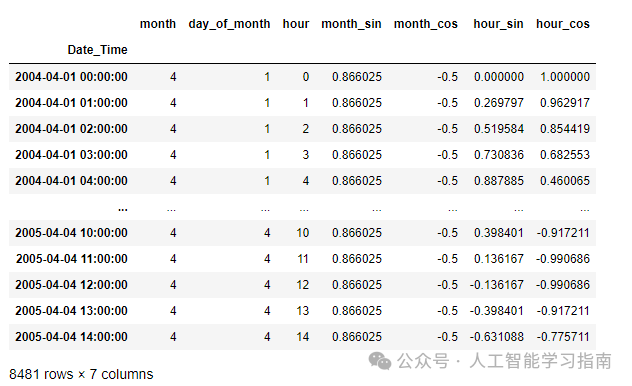
这里需要注意的是,在创建某些特征时会产生NaN值,我们需要将它们移除。如果需要,我们可以使用相同的feature-engine库来执行此操作。
imputer=DropMissingData()
data=imputer.fit_transform(data)
此外,我们还可以删除不需要的特征,
drop_features=DropFeatures(features_to_drop=['CO_sensor','RH'])
data=drop_features.fit_transform(data)
因为我们已经从原始特征中提取了必要的特征,保留它们会导致数据泄漏,因为模型会重复学习相同的信息,从而导致过拟合。
Create a Pipeline of all Combined
data = load_data()
这将加载已清理的原始数据,且未包含上述任何特征。
pipe= Pipeline([
('datetime_features',datetime_features),
('lag_features',lag_features),
('window_features',window_features),
('cyclic_features',cyclic_features),
('dropnan',imputer),
('drop_dataleak_features',drop_features)
])
data=pipe.fit_transform(data)
这将创建所有特征,移除NaN值,并同时删除原始特征。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 1377
1377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}