



“
Preference Tuning LLMs with Direct Preference Optimization Methods
https://hf-mirror.com/blog/pref-tuning
在这篇文章中,对三种有前景的大型语言模型(LLMs)对齐算法进行了实证评估:直接偏好优化(DPO)、身份偏好优化(IPO)和卡尼曼-特沃斯基优化(KTO)。在两个经过监督微调但未进行偏好对齐的高质量7B参数LLMs上进行了实验。虽然有一种算法明显优于其他算法,但要达到最佳结果,必须调整关键的超参数。
没有强化学习的对齐
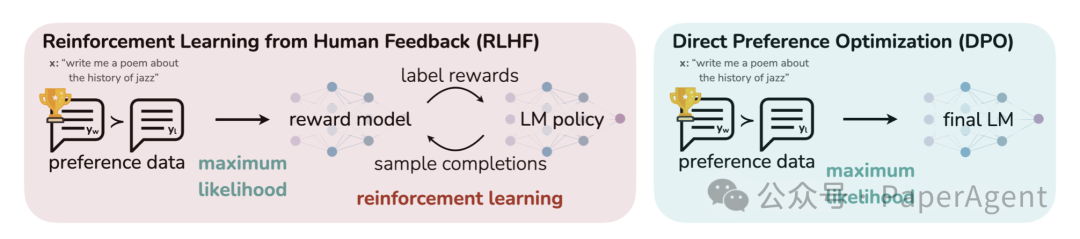
DPO论文的图片(https://arxiv.org/abs/2305.18290)
直接偏好优化(DPO)已成为将大型语言模型(LLMs)与人类或AI偏好对齐的有前景的替代方法。与传统基于强化学习的对齐方法不同,DPO将对齐问题重新定义为一个简单的损失函数,可以直接在偏好数据集上进行优化。这使得DPO在实践中易于使用,并已成功应用于训练如Zephyr和Intel的NeuralChat等模型。
DPO的成功促使研究人员开发了新的损失函数,以两个主要方向推广该方法:
-
鲁棒性:DPO的一个缺点是它倾向于在偏好数据集上快速过拟合。为了避免这一点,Google DeepMind的研究人员引入了身份偏好优化(IPO),它在DPO损失中添加了一个正则化项,使得模型可以在不需要像早停这样的技巧的情况下收敛。
-
完全放弃成对偏好数据:像大多数对齐方法一样,DPO需要一个成对偏好的数据集,其中标注者根据一系列标准(如有帮助性或有害性)标记哪个回答更好。在实践中,创建这些数据集是一项耗时且成本高昂的任务。ContextualAI最近提出了一个有趣的替代方案,称为卡尼曼-特沃斯基优化(KTO),它完全基于被标记为“好”或“坏”的单个例子定义损失函数(例如,在聊天UI中看到的👍或👎图标)。这些标签在实践中更容易获取,KTO是持续更新生产环境中运行的聊天模型的一个有前景的方法。
同时,这些方法伴随着超参数,最重要的是β(beta),它控制了参考模型偏好的权重。通过像🤗 TRL这样的库,这些替代方案现在可供实践者使用。一个自然的问题是,这些方法和超参数中哪一个能产生最好的聊天模型?
这篇文章旨在通过实证分析这三种方法来回答这个问题。将在关键超参数(如β和训练步骤)上进行扫描,然后通过MT-Bench评估生成模型的性能,MT-Bench是一个常用的基准测试,用于衡量聊天模型的能力。
实验设计
在进行对齐实验时,需要考虑两个主要因素:选择优化的模型和对齐数据集。为了获得更多的独立数据点,考虑了两个模型:OpenHermes-2.5-Mistral-7B和Zephyr-7b-beta-sft,以及两个对齐数据集:Intel的orca_dpo_pairs和ultrafeedback-binarized数据集。
对于第一次实验,选择了OpenHermes-2.5-Mistral-7B,因为它是尚未接受任何对齐技术的最好的7B参数聊天模型之一。然后使用了Intel的数据集,该数据集包含13,000个提示,其中选择的回答由GPT-4生成,不期望的回答由Llama-Chat 13b生成。这是NeuralChat和NeuralHermes-2.5-Mistral-7B背后的数据集。由于KTO本身并不要求成对偏好,简单地将GPT-4的回答视为“好”标签,将Llama-Chat 13b的回答视为“坏”标签。虽然GPT-4的回答很可能优于Llama-Chat 13b,但可能有一些情况下Llama-Chat-13b会产生更好的回答,这代表了少数例子。
第二次实验在Zephyr模型上进行了偏好对齐,使用了包含66,000个提示的数据集,其中包含成对的选择和拒绝回答。这个数据集被用来训练原始的Zephyr模型,当时在许多自动化基准测试和人类评估中,它是最佳的7B模型。
参数配置
alignment-handbook提供了一种简单的方法来配置单个实验,这些参数用于配置run_dpo.py脚本。
# Model arguments
model_name_or_path: teknium/OpenHermes-2.5-Mistral-7B
torch_dtype: null
# Data training arguments
dataset_mixer:
HuggingFaceH4/orca_dpo_pairs: 1.0
dataset_splits:
- train_prefs
- test_prefs
preprocessing_num_workers: 12
# Training arguments with sensible defaults
bf16: true
beta: 0.01
loss_type: sigmoid
do_eval: true
do_train: true
evaluation_strategy: steps
eval_steps: 100
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: False
hub_model_id: HuggingFaceH4/openhermes-2.5-mistral-7b-dpo
hub_model_revision: v1.0
learning_rate: 5.0e-7
logging_steps: 10
lr_scheduler_type: cosine
max_prompt_length: 512
num_train_epochs: 1
optim: adamw_torch
output_dir: data/openhermes-2.5-mistral-7b-dpo-v1.0
per_device_train_batch_size: 8
per_device_eval_batch_size: 8
push_to_hub_revision: true
save_strategy: "steps"
save_steps: 100
save_total_limit: 1
seed: 42
warmup_ratio: 0.1
为Zephyr实验创建了一个类似的基础配置文件。
聊天模板是从基础聊天模型自动推断出来的,OpenHermes-2.5使用ChatML格式,Zephyr使用H4聊天模板。或者,如果你想使用自己的聊天格式,🤗 tokenizers库现在已经通过jinja格式字符串启用了用户定义的聊天模板。
#Zephyr聊天模板示例
{% for message in messages %} {% if message['role'] == 'user' %} {{
为Zephyr实验创建了一个类似的基础配置文件。
聊天模板是从基础聊天模型自动推断出来的,OpenHermes-2.5使用ChatML格式,Zephyr使用H4聊天模板。或者,如果你想使用自己的聊天格式,🤗 tokenizers库现在已经通过jinja格式字符串启用了用户定义的聊天模板。
#Zephyr聊天模板示例
{% for message in messages %} {% if message['role'] == 'user' %} {{ '<|user|>' + message['content'] + eos_token }} {% elif message['role'] == 'system' %} {{ '<|system|>' + message['content'] + eos_token }} {% elif message['role'] == 'assistant' %} {{ '<|assistant|>' + message['content'] + eos_token }} {% endif %} {% if loop.last and add_generation_prompt %} {{ '<|assistant|>' }} {% endif %} {% endfor %}
这将格式化对话如下:
<|system|>
# 你是一个友好的聊天机器人,总是以海盗的风格回应。<|/s>
<|user|>
# 一个人一次能吃多少直升机?<|/s>
<|assistant|>
# 啊,我亲爱的伙伴!但你的问题真是个谜!一个人不能一次吃掉直升机,因为直升机不是食物。它们是由金属、塑料和其他材料制成的,而不是食物!
超参数扫描
通过TRL的DPOTrainer使用loss_type参数训练了DPO、IPO和KTO方法,β值从0.2到0.9。包括了这个参数,因为我们观察到一些对齐算法对这个参数特别敏感。所有实验都训练了一个周期。每次运行中,所有其他超参数都保持不变,包括随机种子。
然后使用上述定义的基础配置在HF Mirror集群上启动了扫描。
#!/bin/bash
# Define an array containing the base configs we wish to fine tune
configs=("zephyr" "openhermes")
# Define an array of loss types
loss_types=("sigmoid" "kto_pair" "ipo")
# Define an array of beta values
betas=("0.01" "0.1" "0.2" "0.3" "0.4" "0.5" "0.6" "0.7" "0.8" "0.9")
# Outer loop for loss types
for config in "${configs[@]}"; do
for loss_type in "${loss_types[@]}"; do
# Inner loop for beta values
for beta in "${betas[@]}"; do
# Determine the job name and model revision based on loss type
job_name="$config_${loss_type}_beta_${beta}"
model_revision="${loss_type}-${beta}"
# Submit the job
sbatch --job-name=${job_name} recipes/launch.slurm dpo pref_align_scan config_$config deepspeed_zero3 \\
"--beta=${beta} --loss_type=${loss_type} --output_dir=data/$config-7b-align-scan-${loss_type}-beta-${beta} --hub_model_revision=${model_revision}"
done
done
done
结果
使用MT Bench评估了所有模型,这是一个多轮基准测试,使用GPT-4来判断模型在八个不同类别中的表现:写作、角色扮演、推理、数学、编码、提取、STEM(科学、技术、工程和数学)以及人文学科。尽管不完美,但MT Bench是评估对话型LLMs的一个好方法。
Zephyr-7b-beta-SFT
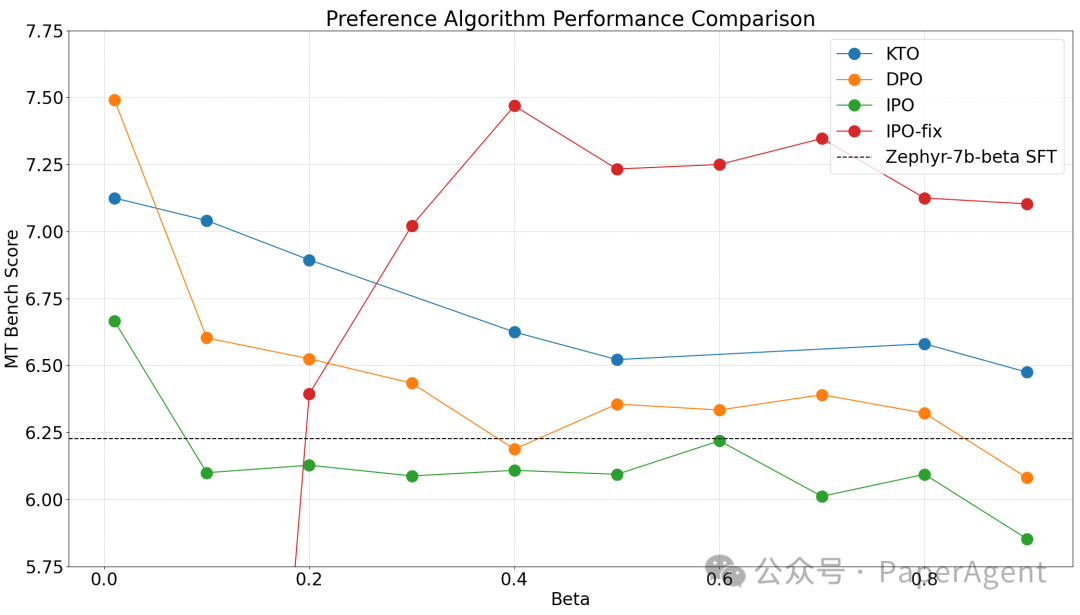
对于Zephyr模型,观察到最佳表现是在最低的β值0.01时实现的。这在所有测试的三种算法中都是一致的,社区接下来可能会对0.0到0.2的范围进行更细致的扫描。虽然DPO可以达到最高的MT Bench得分,但我们发现KTO(成对)在几乎所有设置中都取得了更好的结果。尽管IPO有更强的理论保证,但在几乎所有设置中,它的表现似乎都不如基础模型。
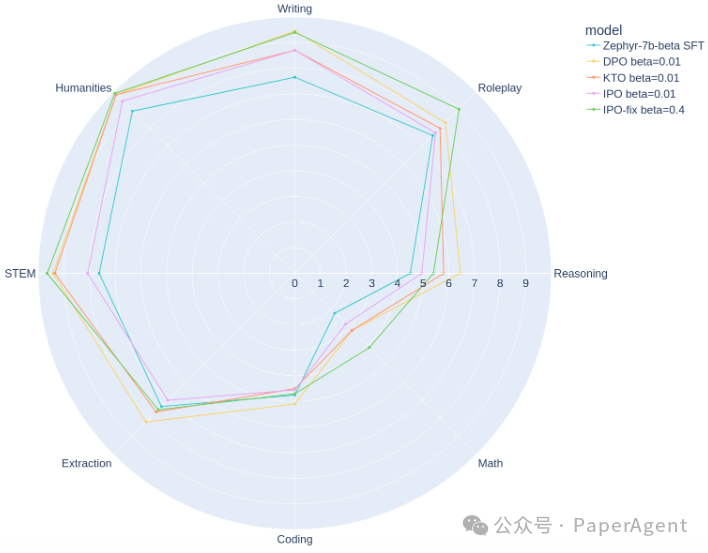
以上是MT Bench类别中每种算法的最佳Zephyr模型的得分分解。
可以分解MT Bench评估的每个类别中每种算法的最佳结果,以确定这些模型的优势和劣势。在推理、编码和数学方面仍有待提高。
OpenHermes-7b-2.5
尽管关于每种算法的观察结果与OpenHermes相同,即DPO > KTO > IPO,但每种算法的最优β值差异很大。对于DPO、KTO和IPO,最佳选择分别为0.6、0.3和0.01。
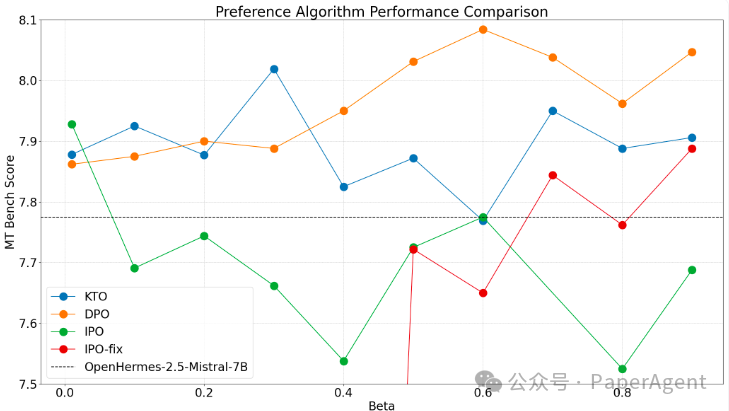
OpenHermes-7b-2.5在MT Bench得分上的提升仅为0.3,这表明它是一个更强大的基础模型,在偏好对齐后得分仅提高了0.3。
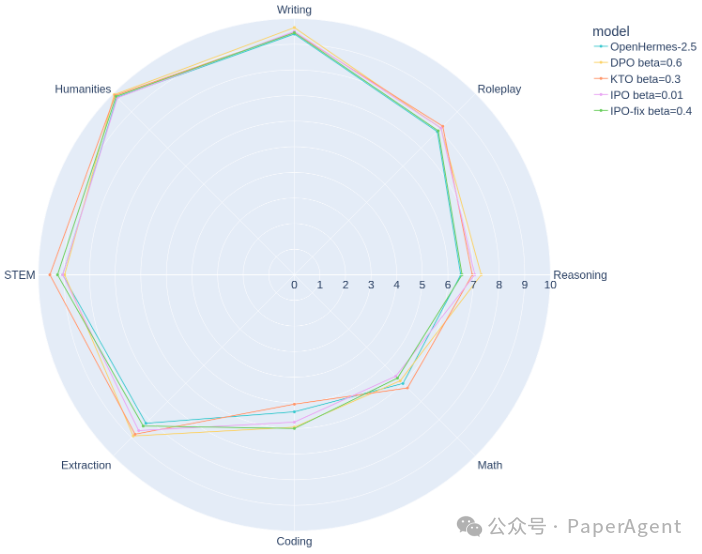 以上是MT Bench类别中每种算法的最佳OpenHermes模型的得分分解
以上是MT Bench类别中每种算法的最佳OpenHermes模型的得分分解
总结与洞见
在这篇文章中,强调了在进行偏好对齐时选择正确超参数的重要性。通过实证展示了DPO和IPO可以实现可比的结果,在成对偏好设置中优于KTO。
所有复制这些结果的代码和配置文件现在都可以在🤗 alignment-handbook的最新更新中找到。表现最好的模型和数据集可以在这个集合中找到。
下一步?
将继续实现新的偏好对齐算法并评估它们的性能。至少在目前看来,DPO是最稳健且表现最好的LLM对齐算法。KTO仍然是一个有趣的发展,因为DPO和IPO都需要成对偏好数据,而KTO可以应用于任何对响应进行正面或负面评价的数据集。
期待在2024年开发出新的工具和技术!
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈


















 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}