







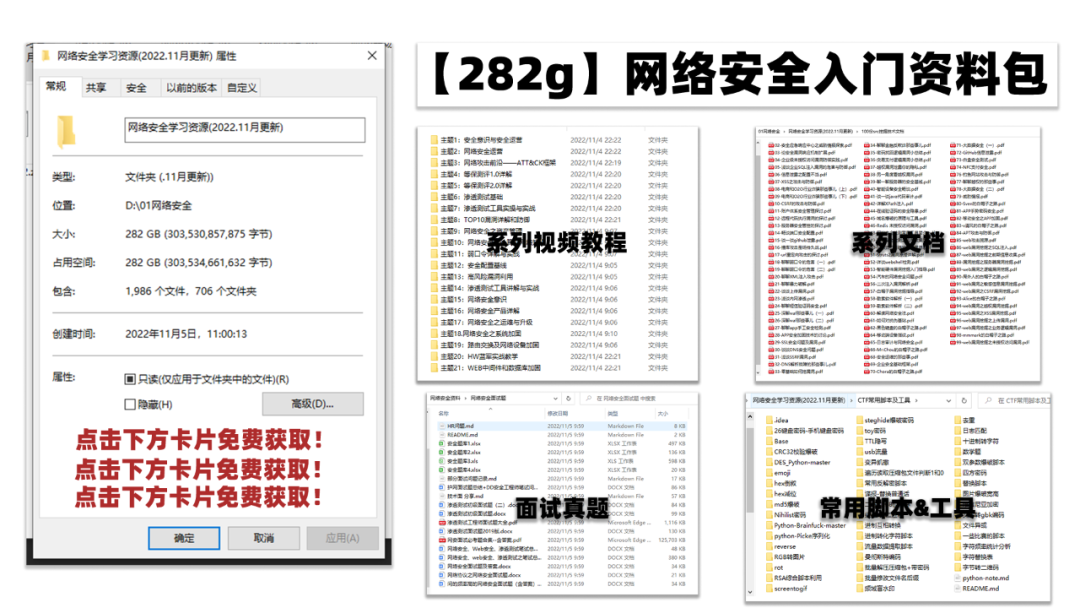
给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
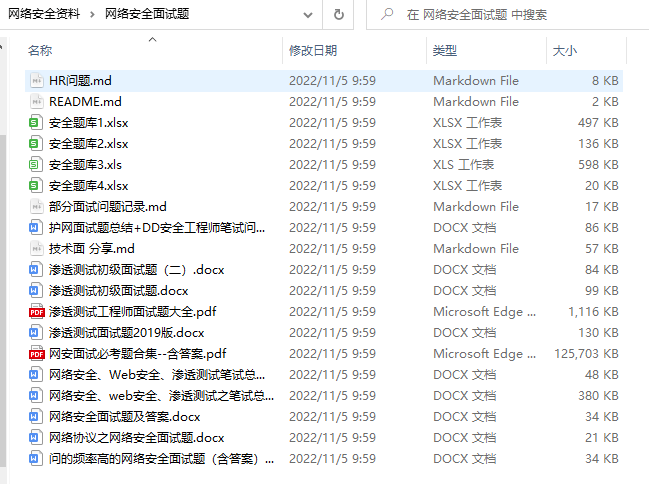
网络安全面试题
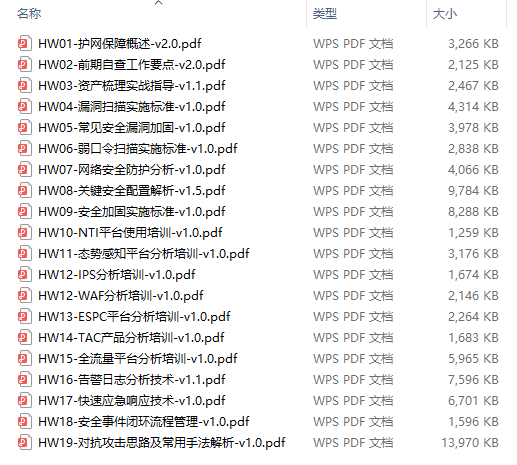
绿盟护网行动
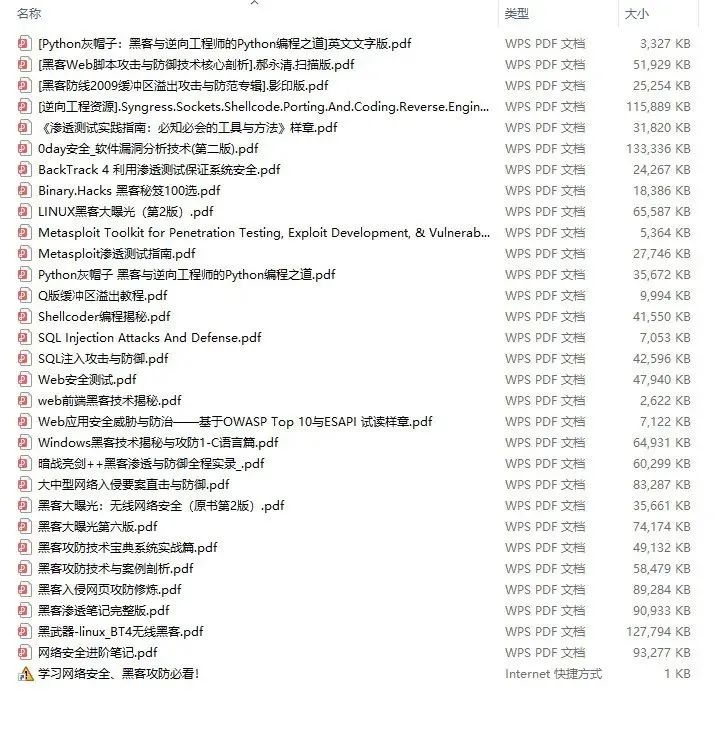
还有大家最喜欢的黑客技术
网络安全源码合集+工具包

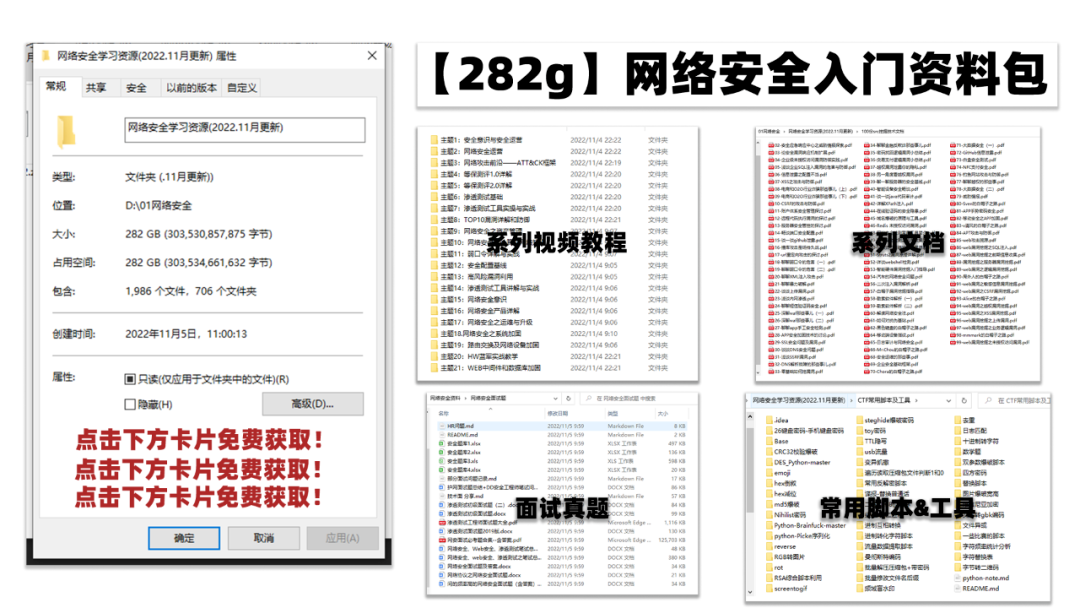
所有资料共282G,朋友们如果有需要全套《网络安全入门+黑客进阶学习资源包》,可以扫描下方二维码领取(如遇扫码问题,可以在评论区留言领取哦)~
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
本文会持续更新,如果对您有帮助的话可以点点关注,双击

本人2021年蓝桥杯C++B组国二,今年转战Java,并整理此文,希望能够对大家有所帮助,第一次写这么长的文章,可能有的地方写的不是很好,还请大家多多谅解,我会持续进行改进并且更新。
更新:2022年蓝桥杯JavaB组国二

第七届蓝桥杯国赛题解
第八届蓝桥杯国赛题解
第九届蓝桥杯国赛题解
第十届蓝桥杯国赛题解
第十一届蓝桥杯国赛题解
 注:内容为蓝桥杯来自蓝桥杯决赛特训营
注:内容为蓝桥杯来自蓝桥杯决赛特训营
蓝桥杯Jvav基础知识总结
输入和输出
输入
Scanner s = new Scanner(System.in); //声明一个从控制台中读入数据的对象
int x = s.nextInt();
double x = s.nextDouble();
String x = s.next(); //无法读入空格
String x = s.nextLine(); //可以读入空格,遇到换行停止
while(s.hasNext()) { //hasNext() 判断还有没有读入值 相当于while(scanf())
//如果有字符,返回true,否则阻塞
//hasNext()不会返回false
}
s.hasNextInt(); //判断输入是否为int,是则返回,否则阻塞
s.hasNextDouble(); //判断输入是否为double,是则返回,否则阻塞
输出
System.out.println();
System.out.print();
System.out.printf(); //格式化输出
prinf()函数与C++中的prinf相同
print()和println()的区别是println()换行
封装输入和输出
通过重写函数的形式来缩写输入和输出,具体情况如下所示
输入
static int gtInt() {
int x = sc.nextInt();
return x;
}
输出
static void print(int x) {
System.out.print(x);
}
static void println(int x) {
System.out.println(x);
}
快速读写
构造:
BufferedReader r = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter w = new BufferedWriter(new OutputStreamWriter(System.out));
int x = r.read(); //读取一个字符并将其转换为UTF-8的值
eg: 输入123213123,x只能读取到1
String x = r.readLine(); //读取一行的值
String[] x = r.readLine().split(' '); //分割字符形成字符串
需要注意的是 在windows中按一下回车键 一共有两个字符 “\n\r” 而read()只能读取一个字符所以如要要用read来达到吸收回车的目的,需要用两个read(); 如果用readLine()的话会将"\n\r"全部吸收 , 所以只需要一个readLine()来吸收回车
w.write(x);
w.write("\n");
w.flush();
w.write(Integer.toString(x)); //输出int型变量
需要注意的是 write() 不能直接输出int类型, 因为write(int a) 会输出其对应的ASCii码的字符
eg:write(65); => A
由于java是面向对象的语言,所以这里将快读和快写封装成类比较好用一些
快读类
StreamTokenizer读取字符类型,而BufferedReader读取字符串这里买呢StreamTokenizer也可以读取字符串,但是不会读取特殊符号和数字,所以我们最好用BufferedReader读取
static class FastRead {
StreamTokenizer streamTokenizer; //读取数字
BufferedReader bufferedReader; //读取字符串
public FastRead() {
streamTokenizer = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
br = new BufferedReader(new InputStreamReader(System.in));
}
int gtInt() throws IOException {
streamTokenizer.nextToken();
int x = (int) streamTokenizer.nval;
return x;
}
long gtLong() throws IOException {
streamTokenizer.nextToken();
long l = (long) streamTokenizer.nval;
return l;
}
double gtDouble() throws IOException {
streamTokenizer.nextToken();
double x = streamTokenizer.nval;
return x;
}
String gtString() throws IOException {
String s = bufferedReader.readLine();
return s;
}
}
快写类
快速输出这里我们选用的是printWriter
static class FastWrite {
PrintWriter printWriter;
public FastWrite() {
printWriter = new PrintWriter(new OutputStreamWriter(System.out));
}
void print(int x) {
printWriter.print(x);
}
void print(String sc) {
printWriter.print(sc);
}
void print(double x) {
printWriter.print(x);
}
void println(int x) {
printWriter.println(x);
}
void println(double x) {
printWriter.println(x);
}
}
计算运行时间
Java的运算速度比C++慢,所以我们可以计算一下运行时间来判断是否会超时
long startTime = System.currentTimeMillis(); //获取开始时间
yourcode(); //你的代码
long endTime = System.currentTimeMillis(); //获取结束时间
System.out.println("程序运行时间:" + (endTime - startTime) + "ms"); //输出程序运行时间
数组
数组定义
int arr[] = new int[100];
int arr[][] = new int[100][100];
int arr[] = {1,2,3,4,5};
数组常用函数
Arrays.fill(arr,0); //全部赋值为0
Arrays.fill(arr,1,10,0); //从第一个到第十个赋值为0
binarySearch(arr,5); //二分搜索法查找5
binarySearch(arr,1,10,5); //二分搜索法从第一个到第十个查找
newArr = copyOf(arr,10); //复制数组,从0到10
newArr = copyOfRange(arr,1,10); //复制数组,从1到10
sort(arr); //排序
sort(arr,1,10); //从1到10排序
浅拷贝与深拷贝
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
ArrayList<Integer> list1 = list;
ArrayList<Integer> list2 = (ArrayList<Integer>) list.clone();
list.set(0,2);
System.out.println(list1.get(0)); //答案为2
System.out.println(list2.get(0)); //答案为1
String StringBuilder StringBuffer
String类位于java.lang包下
String类
String类作为不可修改的对象,如果用String修改字符串会新建一个String对象,如果频繁修改,则会产生很多String对象,会产生很大的开销,效率也不是很高
提供了字符串的比较,查找,截取,大小写转换等操作
String类被final所修饰,不能被继承
//构造方法
String()构造空串
String(String)构造为String的串
String(Byte[],offset,length) //用byte子数组构造String
String(char[]) //构造一个内容为char[]的字符串
String(char[],offset,count) //取char[]的子数组
//常用方法
String.length() //求长度
String.substring(begin) //从begin处截取字串
String.substring(begin,end) //从[begin,end)处截取字串
String.startwith(String) //是否以该字串开始
String.endwith(String) //是否以该字串结束
String.toString() //返回该字符串本身
String.equals(String) //比较相等
String.equalsIgnoreCase(String) //比较是否相等,忽略大小写
StringBuffer类和StringBulider类(字符串缓冲区)
StringBuffer类(StringBuilder类同理,下同)作为可以修改的对象,如果是构造一个需要改变的String的话建议先使用StringBuffer,当String类不需要改变的时候再将其转换到String类
StringBuffer底层维护了一个字符数组,存储字符时实际上时往该字符数组中存储,初始化容量为16,当容量不够用时,自动增长一倍
StringBuffer类也具有String类的方法
//构造方法
string=stringBuffer.toString(); //将stringBuffer类转换为String类
stringBuffer() //空stringBuffer串
stringBuffer(String) //一个内容为String的stringBuffer类
//常用方法
stringBuffer.append(String) //增加到字符串末尾
stringBuffer.append(char)
stringBuffer.length() //返回长度
stringBuffer.replace(start, end, str) //从Start到end区间被str替代
stringBuffer.reverse() //反转形式取代
stringBuffer.insert(i,String) //在i后插入String串
stringBuffer.delete(start,end) //删除[start,end)处的字串
stringBuffer.indexOf(String) //返回字串的第一次索引
stringBuffer.indexOf(String,fromIndex) //返回从fromIndex处开始的第一次索引
stringBuffer.charAt(index) //返回这个索引下的序列值
stringBuffer.setCharAt(index, char) //将下标为index的值修改为char
StringBuffer与StringBuilder的区别
StringBuffer类所提供的方法都是同步的方法,属于安全的线程操作
StringBuilder类中的大多方法都是异步方法,属于线程安全的操作
如果多线程环境下涉及到大量修改的操作的话,则首先选择StringBuffer
如果非多线程环境下涉及到大量修改的操作的话,则首先选择StringBuilder
总的来说,执行速度的比较 StringBuilder>StringBuffer>String
Java数据结构
Java一共有 种数据结构时我们常用的,分别是以下几种
| 集合类型 | 描述 |
|---|---|
| ArrayList | 可以动态增长和缩减的序列,类似于C++的vector |
| LinkedList | 可以在任何位置高效插入和删除的有序序列,链表 |
| ArrayDeque | 实现为循环数组的一个双端队列 |
| HashSet | 没有重复元素的无序集合 |
| TreeSet | 没有重复元素的有序集合 |
| LinkedHashSet | 记住元素插入次序的集合 |
| PriorityQueue | 优先队列 |
| HashMap | <K,V>型无序集合 |
| TreeMap | <K,V>型有序集合 |
| LinkedHashMap | 记住添加次序的<K,V>型集合 |
以上所有数据结构都有以下这几种方法,需要记牢
boolean add(E e)
//确保此集合包含指定的元素(可选操作)
boolean addAll(Collection<? extends E> c)
//将指定集合中的所有元素添加到此集合(可选操作)
void clear()
//从此集合中删除所有元素(可选操作)
boolean contains(Object o)
//如果此集合包含指定的元素,则返回 true
boolean containsAll(Collection<?> c)
//如果此集合包含指定 集合中的所有元素,则返回true
boolean equals(Object o)
//将指定的对象与此集合进行比较以获得相等性
int hashCode()
//返回此集合的哈希码值
boolean isEmpty()
//如果此集合不包含元素,则返回 true
Iterator<E> iterator()
//返回此集合中的元素的迭代器
default Stream<E> parallelStream()
//返回可能并行的 Stream与此集合作为其来源
boolean remove(Object o)
//从该集合中删除指定元素的单个实例(如果存在)(可选操作)
boolean removeAll(Collection<?> c)
//删除指定集合中包含的所有此集合的元素(可选操作)
default boolean removeIf(Predicate<? super E> filter)
//删除满足给定谓词的此集合的所有元素
boolean retainAll(Collection<?> c)
//仅保留此集合中包含在指定集合中的元素(可选操作)
int size()
//返回此集合中的元素数
default Spliterator<E> spliterator()
//创建一个Spliterator在这个集合中的元素
default Stream<E> stream()
//返回以此集合作为源的顺序 Stream
Object[] toArray()
//返回一个包含此集合中所有元素的数组
<T> T[] toArray(T[] a)
//返回包含此集合中所有元素的数组; 返回的数组的运行时类型是指定数组的运行时类型
ArrayList
ArrayList<Integer> list = new ArrayList<>(); //创建一个ArrayList
list.add(1); //向ArrayList中添加元素
list.addAll(list1); //向ArrayList中插入新的ArrayList
try {
list.add(1,2); //将2插入到第一个元素中,第一个元素到最后一个元素依次往后移
list.addAll(1,list1) //将list1中所有元素插入到list的第一个里面
} catch (IndexOutOfBoundsException e) {
//如果第一个数字 > list.size() 则会抛出异常
}
list.get(0); //向ArrayList中获取第0个元素
list.set(0,2); //将第0个元素设置为2
list.clear(); //清空list
boolean b = list.contains(1); //判断list中是否含有1
boolean b = list.isEmpty(); //判断list是否为空
int i = list.indexOf(1); //查询list中第一次出现1的位置下标,没有则返回-1
int i = list.lastIndexOf(1); //查询list中最后出现1的位置下标,没有则返回-1
int x = list.remove(0); //删除第0号元素,同时将第0号元素的值返回
boolean b = list.remove(new Integer(3)); //删除list中第一个出现3的元素
/*
* 当list为Integer类型是,list.remove(0)会被认为删除第0号元素而不是删除第一个出现0的元素
*/
System.out.prinltn(list.size()); //输出list的size大小
LinkedList
LinkedList的操作和ArrayList差不多,这里记录一些ArrayList中没有的一些API
void addFirst(E e)
在该列表开头插入指定的元素
void addLast(E e)
将指定的元素追加到此列表的末尾
boolean contains(Object o)
如果此列表包含指定的元素,则返回 true
Iterator<E> descendingIterator()
以相反的顺序返回此deque中的元素的迭代器
E getFirst()
返回此列表中的第一个元素
E getLast()
返回此列表中的最后一个元素
LinkedList和ArrayList的区别
LinkedList就是链表,ArrayList就是数组
LinkedList插入和删除中间的元素十分方便,但是随机访问的能力很弱
ArrayList插入和删除中间的元素开销大,但是随机访问的能力很强
Stack
Stack<Integer> stack = new Stack<>(); //创建一个新stack
stack.push(1); //将1压入到stack中
int x = stack.peek(); //获取栈顶元素并且不使栈顶元素出栈
int x = stack.pop(); //获取栈顶元素并且使得栈顶元素出栈
int x = stack.search(1); //查找离栈顶元素最近的1离栈顶的位置
eg: 1 2 3 4 5 1 2 3 4 5
stack.search(1); //返回值为3
stack.search(5); //返回值为5
eg: 1 2 3 4 5
stack.search(5); //返回值为-1
boolean empty()
//测试此堆栈是否为空
E peek()
//查看此堆栈顶部的对象,而不从堆栈中删除它
E pop()
//删除此堆栈顶部的对象,并将该对象作为此函数的值返回
E push(E item)
//将项目推送到此堆栈的顶部
int search(Object o)
//返回一个对象在此堆栈上的基于1的位置
Set
set可以先不声明自己的泛型,这样的set可以插入不同的类,如下所示
HashSet s = new HashSet();
s.add("Polaris111");
s.add(123456);
s.add(new BigDecimal(123.456));
System.out.println(s);
打印出来的结果如下所示

Java的set一共分为两类,不能排序HashSet和能够排序的TreeSet,接下来让我分别介绍这两个类
HashSet
基本操作
HashSet<String> s = new HashSet<>();
s.add("str1"); //添加
s.add("str2");
s.add("str3");
System.out.println(s.isEmpty()); //判空
System.out.println(s.contains("str1")); //判断集合是否包含元素
System.out.println(s.size()); //集合中元素个数
System.out.println(s.remove("str1")); //删除元素
s.clear(); //清空所有元素
输出结果如下所示

遍历
//第一种
Iterator it = s.iterator();
while(it.hasNext()) {
if(it.next().equals("str2")) {
it.remove();
}
}
//第二种
for(String str : s) {
System.out.println(s);
}
TreeSet
TreeSet的内部实现是红黑树,基本操作方式和HashSet相同基本相同
TreeSet<String> s = new TreeSet<>();
s.add("str1"); //添加
s.add("str2");
s.add("str3");
System.out.println(s.isEmpty()); //判空
System.out.println(s.contains("str1")); //判断集合是否包含元素
System.out.println(s.size()); //集合中元素个数
System.out.println(s.remove("str1")); //删除元素
s.clear(); //清空所有元素
输出结果如下所示
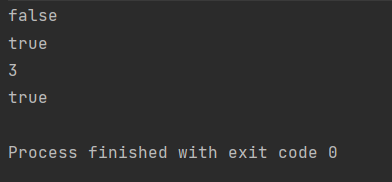
遍历
//第一种
Iterator it = s.iterator();
while(it.hasNext()) {
if(it.next().equals("str2")) {
it.remove();
}
}
//第二种
for(String str : s) {
System.out.println(s);
}
HashMap
HashMap<Integer, String> hashMap = new HashMap<>(); //创建元素
hashMap.put(1, "test1"); //插入元素
hashMap.put(2, "test2");
hashMap.put(3, "test3");
System.out.println(hashMap.get(1)); //取元素
System.out.println(hashMap.isEmpty()); //判空
System.out.println(hashMap.size()); //输出元素数量
//判断键是否存在
if(hashMap.containsKey(1)) {
System.out.println("1存在");
}
//判断值是否存在
if(hashMap.containsValue("test1")) {
System.out.println("test1存在");
}
hashMap.remove(1); //删除Key为1的元素
hashMap.remove(2,"test2"); //删除Key为2且值为test2的元素
hashMap.replace(3, "test4"); //将Key为3的元素的Value替换为"test4"
hashMap.replace(3, "test4", "test5"); //将Key为3且Value为"test4"的值替换为"test5"
Set<Map.Entry<Integer, String>> set = hashMap.entrySet(); //获取键
Iterator iterator = set.iterator();
while(iterator.hasNext()) {
Map.Entry<Integer, String> it = (Entry<Integer, String>) iterator.next();
System.out.println(it.getKey()); //取键
System.out.println(it.getValue()); //取值
System.out.println(it.setValue("null")); //重新设置值
}
TreeMap
TreeMap的操作与HashMap差不多,这里我写几个TreeMap特有的操作
TreeMap<Integer, String> treeMap = new TreeMap<>(); //创建元素
treeMap.put(1, "test1"); //插入元素
treeMap.put(2, "test2");
treeMap.put(3, "test3");
Integer integer = treeMap.ceilingKey(3); // 返回大于或等于给定键的键,如果没有此键,则返回null
System.out.println(integer);
Map.Entry<Integer, String> entry = treeMap.ceilingEntry(3); // 返回与大于或等于给定键的最小键相关联的键值映射,如果没有此键,则返回null
System.out.println(entry.getKey()); //取键
System.out.println(entry.getValue()); //取值
TreeMap在寻找值除了上述的操作外还有以下的操作:
Map.Entry<K,V> ceilingEntry(K key)
//返回与大于或等于给定键的最小键相关联的键值映射,如果没有此键,则 null
K ceilingKey(K key)
//返回大于或等于给定键的 null键,如果没有此键,则返回 null
Map.Entry<K,V> firstEntry()
//返回与该地图中的最小键相关联的键值映射,如果地图为空,则返回 null
K firstKey()
//返回此地图中当前的第一个(最低)键
Map.Entry<K,V> floorEntry(K key)
//返回与小于或等于给定键的最大键相关联的键值映射,如果没有此键,则 null
K floorKey(K key)
//返回小于或等于给定键的最大键,如果没有这样的键,则返回 null
SortedMap<K,V> headMap(K toKey)
//返回此地图部分的视图,其密钥严格小于 toKey
NavigableMap<K,V> headMap(K toKey, boolean inclusive)
//返回此地图部分的视图,其键值小于(或等于,如果 inclusive为真) toKey
Map.Entry<K,V> higherEntry(K key)
//返回与最小密钥相关联的密钥值映射严格大于给定密钥,如果没有这样的密钥则 null
K higherKey(K key)
//返回严格大于给定键的最小键,如果没有这样的键,则返回 null
Map.Entry<K,V> lastEntry()
//返回与该地图中最大关键字关联的键值映射,如果地图为空,则返回 null
K lastKey()
//返回当前在此地图中的最后(最高)键
Map.Entry<K,V> lowerEntry(K key)
//返回与最大密钥相关联的密钥值映射严格小于给定密钥,如果没有这样的密钥,则 null
K lowerKey(K key)
//返回严格小于给定键的最大键,如果没有这样的键,则返回 null
Map.Entry<K,V> pollFirstEntry()
//删除并返回与该地图中的最小键相关联的键值映射,如果地图为空,则返回 null
Map.Entry<K,V> pollLastEntry()
//删除并返回与该地图中最大密钥相关联的键值映射,如果地图为空,则返回 null
NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive)
//返回此地图部分的视图,其关键范围为 fromKey至 toKey
SortedMap<K,V> subMap(K fromKey, K toKey)
//返回此地图部分的视图,其关键字范围从 fromKey (含)到 toKey ,独占
SortedMap<K,V> tailMap(K fromKey)
//返回此地图部分的视图,其键大于等于 fromKey
NavigableMap<K,V> tailMap(K fromKey, boolean inclusive)
//返回此地图部分的视图,其键大于(或等于,如果 inclusive为真) fromKey
PriorityQueue
PriorityQueue默认小根堆,要想生成大根堆,可以按照如下方式生成。
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>((x,y) -> (y-x));
基本操作
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
priorityQueue.offer(1); //插入元素
priorityQueue.offer(2);
priorityQueue.offer(3);
priorityQueue.offer(4);
priorityQueue.offer(5);
System.out.println(priorityQueue.poll()); //查找队头并删除队头
System.out.println(priorityQueue.peek()); //查找队头
System.out.println(priorityQueue.size()); //输出元素数量
priorityQueue.remove(4); //删除元素如果存在
自定义排序
HashSet可以自定义排序函数,也可以让HashSet排序的类里面重载compareTo函数,操作如下所示
public int compare(String o1, String o2):比较其两个参数的顺序
static class MyClass {
public int f;
public int s;
}
static class MyComparator implements Comparator<MyClass> {
@Override
public int compare(MyClass o1, MyClass o2) {
if(o1.f != o2.f) {
if(o1.f > o2.f) {
return 1;
} else {
return -1;
}
} else {
if(o1.s > o2.s) {
return 1;
} else {
return -1;
}
}
}
}
两个对象比较的结果有三种:大于,等于,小于
如果要按照升序排序,
则o1 小于o2,返回(负数),相等返回0,01大于02返回(正数)
如果要按照降序排序
则o1 小于o2,返回(正数),相等返回0,01大于02返回(负数)
做如下测试,可以看到TreeSet按照我们给提供的接口去进行排序的
TreeSet<MyClass> treeSet = new TreeSet<>(new MyComparator());
treeSet.add(new MyClass(1, 2));
treeSet.add(new MyClass(2, 2));
treeSet.add(new MyClass(2, 3));
treeSet.add(new MyClass(4, 3));
treeSet.add(new MyClass(5, 6));
treeSet.add(new MyClass(7, 3));
Iterator it = treeSet.iterator();
while(it.hasNext()) {
System.out.println(it.next().toString());
}

也可以在声明类的时候继承Comparable接口来自定义排序方法,这样TreeSet这种排序集合在排序的时候就会执行我们自定义类中的方法
static class MyClass implements Comparable<MyClass> {
public int f;
public int s;
@Override
public int compareTo(MyClass o) {
if(this.f != o.f) {
if(this.f > o.f) {
return 1;
} else {
return -1;
}
} else {
if(this.s > o.s) {
return 1;
} else {
return -1;
}
}
}
}
同样是进行和上面一样的测试,可以发现结果是一样的,TreeSet这种排序集合在排序的时候就会执行类中的compareTo方法
TreeSet<MyClass> treeSet = new TreeSet<>();
treeSet.add(new MyClass(1, 2));
treeSet.add(new MyClass(2, 2));
treeSet.add(new MyClass(2, 3));
treeSet.add(new MyClass(4, 3));
treeSet.add(new MyClass(5, 6));
treeSet.add(new MyClass(7, 3));
Iterator it = treeSet.iterator();
while(it.hasNext()) {
System.out.println(it.next().toString());
}
结果如下所示
![]
](https://img-blog.csdnimg.cn/4ee167da70c24362a9ca070719535c52.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5peg562W56aB6Iqx6aOO,size_11,color_FFFFFF,t_70,g_se,x_16)
如果二者都不定义直接排序呢?答案是不可以的,编译器会报如下的错误:

Java API
大数类
大数类一共有两个,分别是BigInteger和BigDecimal,大数整形变量以及大数浮点数,理论上可以存储无线长的数字(只要你计算机的内存足够),接下来我将会分别介绍这两个类。
BigInteger
构造函数
BigInteger一共有六个构造方法,分别是以下六个,个人认为最常用的应该是第五个将字符串转换为BigInteger。
BigInteger b = BigInteger(byte[] val)
//将包含BigInteger的二进制补码二进制表达式的字节数组转换为BigInteger。
BigInteger b = BigInteger(int signum, byte[] magnitude)
//将BigInteger的符号大小表示形式转换为BigInteger。
BigInteger b = BigInteger(int bitLength, int certainty, Random rnd)
//构造一个随机生成的正BigInteger,它可能是素数,具有指定的bitLength。
BigInteger b = BigInteger(int numBits, Random rnd)
//构造一个随机生成的BigInteger,均匀分布在0到(2 numBits - 1)的范围内。
BigInteger b = BigInteger(String val)
//将BigInteger的十进制字符串表示形式转换为BigInteger。
BigInteger b = BigInteger(String val, int radix)
//将指定基数中的BigInteger的String表示形式转换为BigInteger。
输入
BigInteger类是可以直接读入的,当然你也可以选择先读入字符串然后再转到BigInteger。
Scanner s = new Scanner(System.in);
while (sc.hasNextBigInteger()) {
BigInteger b = s.nextBigInteger(); //读取BigInteger
输出
BigInteger类是可以直接输出的
System.out.println(b);
四则运算
BigInteger的四则运算不能用基础的四个符号进行操作,而是需要用BigInteger的方法来实现。
BigInteger b1 = new BigInteger("1000000");
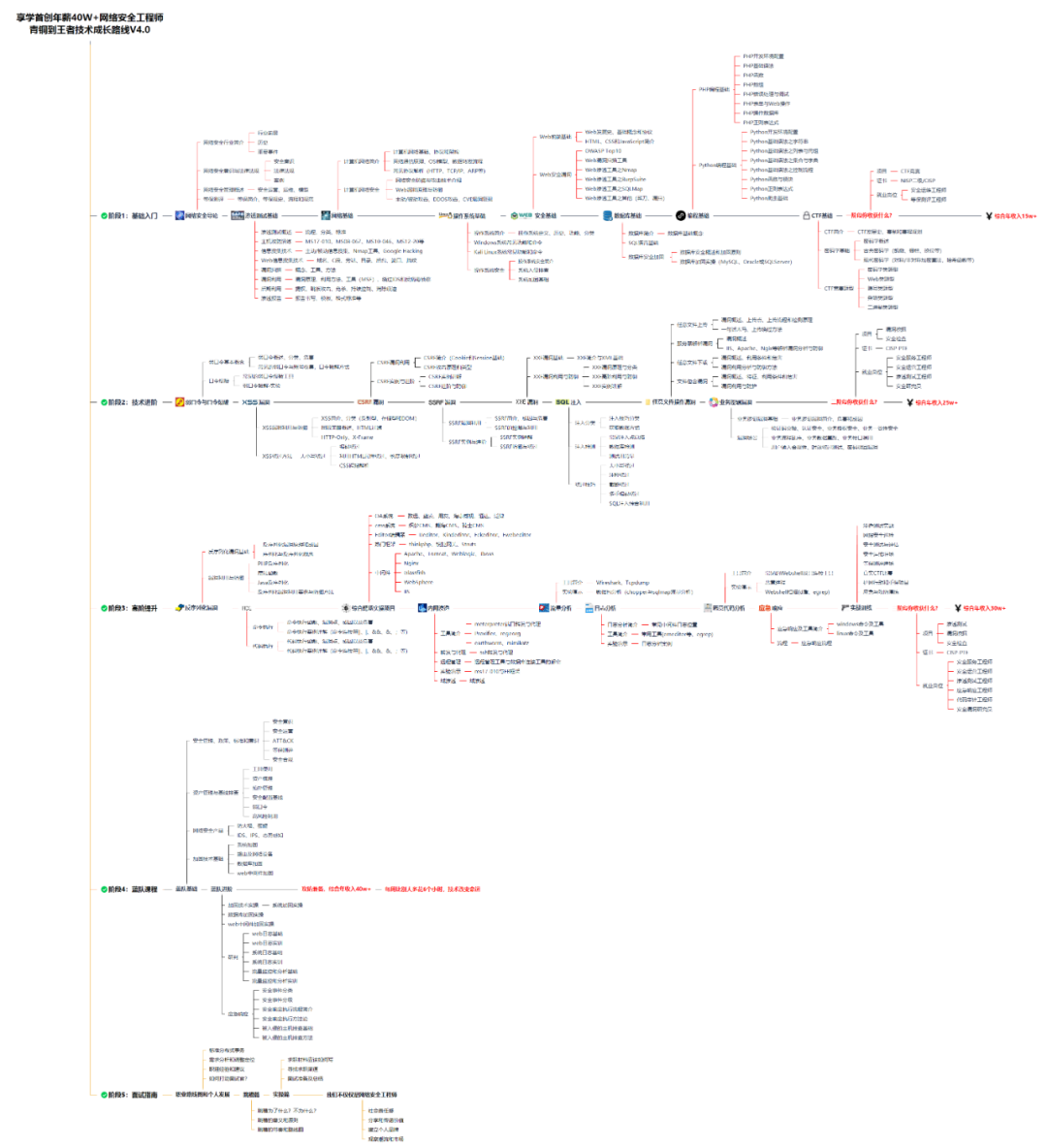
### 一、网安学习成长路线图
网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
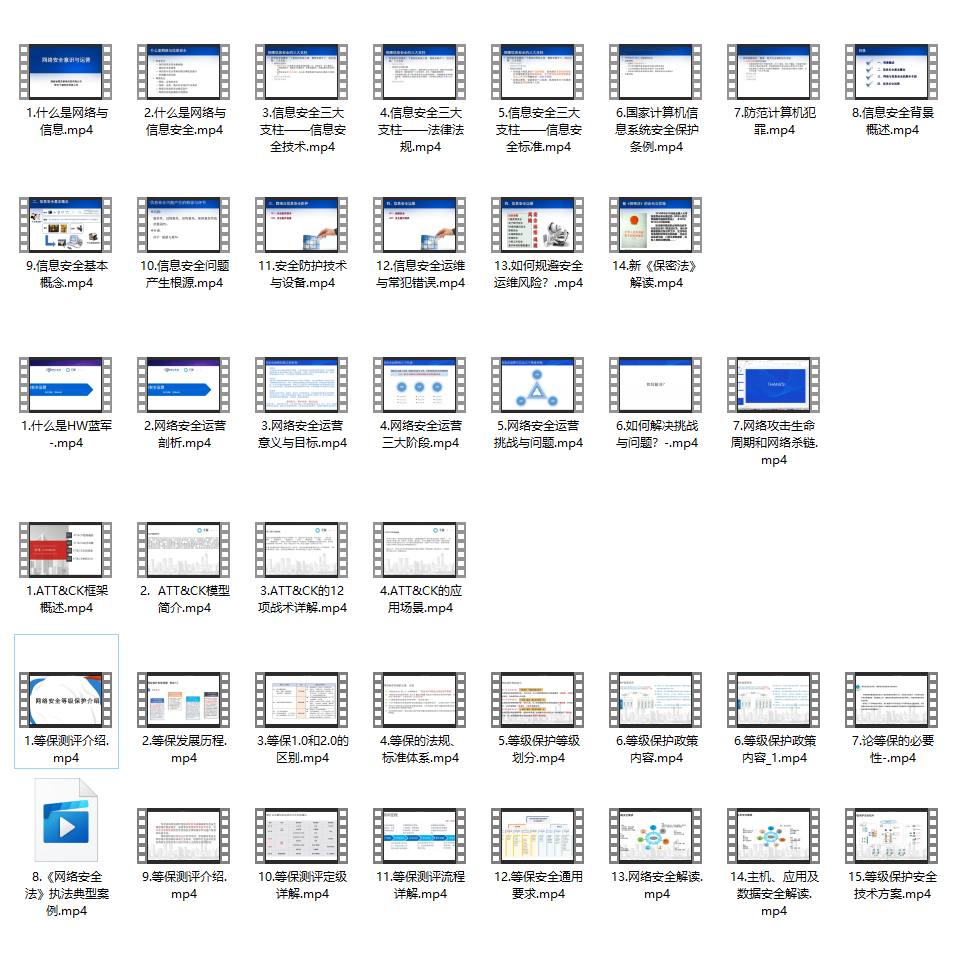
### 二、网安视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
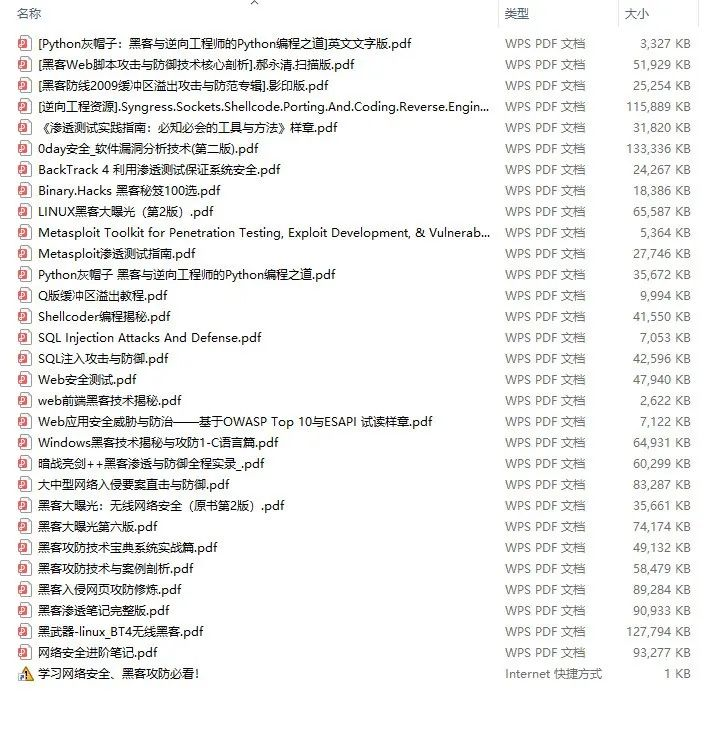
### 三、精品网安学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
### 四、网络安全源码合集+工具包
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

### 五、网络安全面试题
最后就是大家最关心的网络安全面试题板块
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









