







 本文分析了2018年至2020年中国大学生计算机设计大赛的数据,包括各年奖项分布、得奖最多的Top10学校、参赛次数统计、学校层次划分以及作者和指导老师人数对获奖的影响。同时提到了网络安全相关的内容和学习资源分享。
本文分析了2018年至2020年中国大学生计算机设计大赛的数据,包括各年奖项分布、得奖最多的Top10学校、参赛次数统计、学校层次划分以及作者和指导老师人数对获奖的影响。同时提到了网络安全相关的内容和学习资源分享。
- 哪些学校多次进入得奖最多 Top10
- 各学校三年中参赛次数统计
- 各级别奖项中学校层次划分
- 参赛人数与奖项之间的关系
- 获奖作品名称热词
文中各部分中如果代码量较多的,为了阅读体验,就不进行展示,如需代码及相关文件可以私信我。
数据读取及描述
数据集是大赛官方提供的数据,2018、2019 年数据为.xlsx文件,2020 年数据为.pdf文件。先读取 2018 、2019 年数据,并观察一下数据集信息。
import pandas as pd
df_2018 = pd.read_excel('2018年决赛正式结果.xlsx', sheet_name='123等奖')
df_2019 = pd.read_excel('2019年大赛获奖作品名单公示20190907.xlsx')

df_2019.info()

通过上图中的信息可以看到,2018 年与 2019 年的数据集格式有挺大的差异,这些在之后合并时需要统一。
由于 2020 年的数据是 .pdf 文件,我们单独定义一个函数来读取。对于读取时的一些细节问题,都已在代码中以注释的形式标出。
import pdfplumber
def read\_pdf\_2020(read_path):
pdf_2020 = pdfplumber.open(read_path)
result_df = pd.DataFrame()
for page in pdf_2020.pages:
table = page.extract_table()
df_detail = pd.DataFrame(table[1:], columns=table[0])
# 合并每页的数据集
result_df = pd.concat([df_detail, result_df], ignore_index=True)
# 删除值全部是 NaN 的列
result_df.dropna(axis=1, how='all', inplace=True)
# 重置列名
result_df.columns = ['奖项', '作品编号', '作品名称', '参赛学校', '作者', '指导老师']
return result_df
df_2020 = read_pdf_2020('2020年中国大学生计算机设计大赛参赛作品获奖名单.pdf')

观察 2020 年的数据,相比于前两年的数据,它的各列都没有缺失值,但2020年的获奖信息中并没有包含作品类别这一列,所以我们处理数据集时要将前两年的类别列进行删除。这样,我们可以按照 2020 数据集的格式作为模板,将前两年的数据集转换为相同的格式,再进行合并。
数据预处理
各年数据集格式化
按照 2020 年格式,将 2018 年与 2019 年数据集中部分列进行合并,并更换列名,删除多余的列。并添加 “年份” 这一列。
下面是处理后的 2018 年与 2019 年数据。


对于 2020 年数据集的处理要注意,数据读取时是基于每页数据来读取的,如果在一页的最后一行数据较多,需要换行的话,那么下一页首行数据就会缺失,如下所示。

这种情况就需要先筛选出这些作品编号为空的行,在将数据添加到上一行中。
# 2020年数据集处理
clean_df_2020 = df_2020.copy()
# 部分信息过长导致在分页处被分割,分别出现在两页上,下面将奖项为空的数据添加到上一条数据的信息中。
clean_df_2020.iloc[609]['参赛学校'] += '医大学'
clean_df_2020.iloc[1330]['作品名称'] += '丹霞'
clean_df_2020.iloc[2121]['作品名称'] += '现'
clean_df_2020.iloc[2997]['作品名称'] += '云平台'
del_index = clean_df_2020.loc[clean_df_2020['奖项'] == ''].index
clean_df_2020.drop(del_index, inplace=True)
clean_df_2020.reset_index(drop=True, inplace=True)
clean_df_2020['年份'] = [2020 for _ in range(len(clean_df_2020))]
数据合并
现在合并三年的数据。合并后数据集如下。

数据清洗
现在我们要对合并后的数据集进行一些处理,以便更好地分析及可视化。由于之后我们要用到全国高校的一些基本信息,如学校层次(985 211等),所以需要导入 college_info.csv ,该数据是博主在 6月15日 爬取的,部分高职高专可能并未收录,对于这部分高校就将对应标签赋值为 “暂无数据” 。清除参赛学校和作品名称中的换行符“\n”,之后添加 参赛人数列 来记录 各作品作者人数 ,指导老师人数列 记录 该作品指导老师人数。
college_info = pd.read_csv('college\_info.csv')
college_name = college_info['学校名称'].values.tolist()
college_level = []
for college in all_df['参赛学校']:
if college not in college_name:
college_level.append('暂无数据')
else:
college_level.append(college_info['学校层次'][college_name.index(college)])
all_df['学校层次'] = college_level
all_df['参赛学校'] = all_df['参赛学校'].str.replace('\n|\r', '')
all_df['作品名称'] = all_df['作品名称'].str.replace('\n|\r', '')
# 删除作者为空的列
all_df.dropna(subset=['作者'], axis=0, inplace=True)
# 添加 参数人数 列来记录各作品作者人数
all_df['参赛人数'] = all_df['作者'].apply(lambda x: len(x.split('、')))
count_list = []
for index, row in all_df.iterrows():
try:
count_list.append(len(row['指导老师'].split('、')))
except:
count_list.append(0)
all_df['指导老师人数'] = count_list
all_df.to_csv('all\_df.csv', index=False)
all_df
处理后的数据集如下。

数据分析及可视化
各年奖项数量分布
统计三年中一等奖、二等奖、三等奖的占比,绘制层叠条形图。
'''
数据统计省略
'''
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.commons.utils import JsCode
from pyecharts.globals import ThemeType
c = Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
c.add_xaxis([2018, 2019, 2020])
c.add_yaxis("三等奖", list1, stack="stack1", category_gap="70%")
c.add_yaxis("二等奖", list2, stack="stack1", category_gap="70%")
c.add_yaxis("一等奖", list3, stack="stack1", category_gap="70%")
c.set_series_opts(label_opts=opts.LabelOpts(
position="right",
formatter=JsCode(
"function(x){return Number(x.data.percent \* 100).toFixed() + '%';}"
),
)
)
c.render("./images/各年奖项数量分布堆叠条形图.html")
c.render_notebook()

从上图中观察发现,随着时间的推移,一等奖、二等奖的比例开始减少,三等奖比例增加,在 2020 年三等奖比例达到68%,不难看出赛方想要增加一等奖的含金量。
各年得奖最多的学校Top10
统计各年得奖最多的前 10 名学校的各项奖的数目,绘制图形。
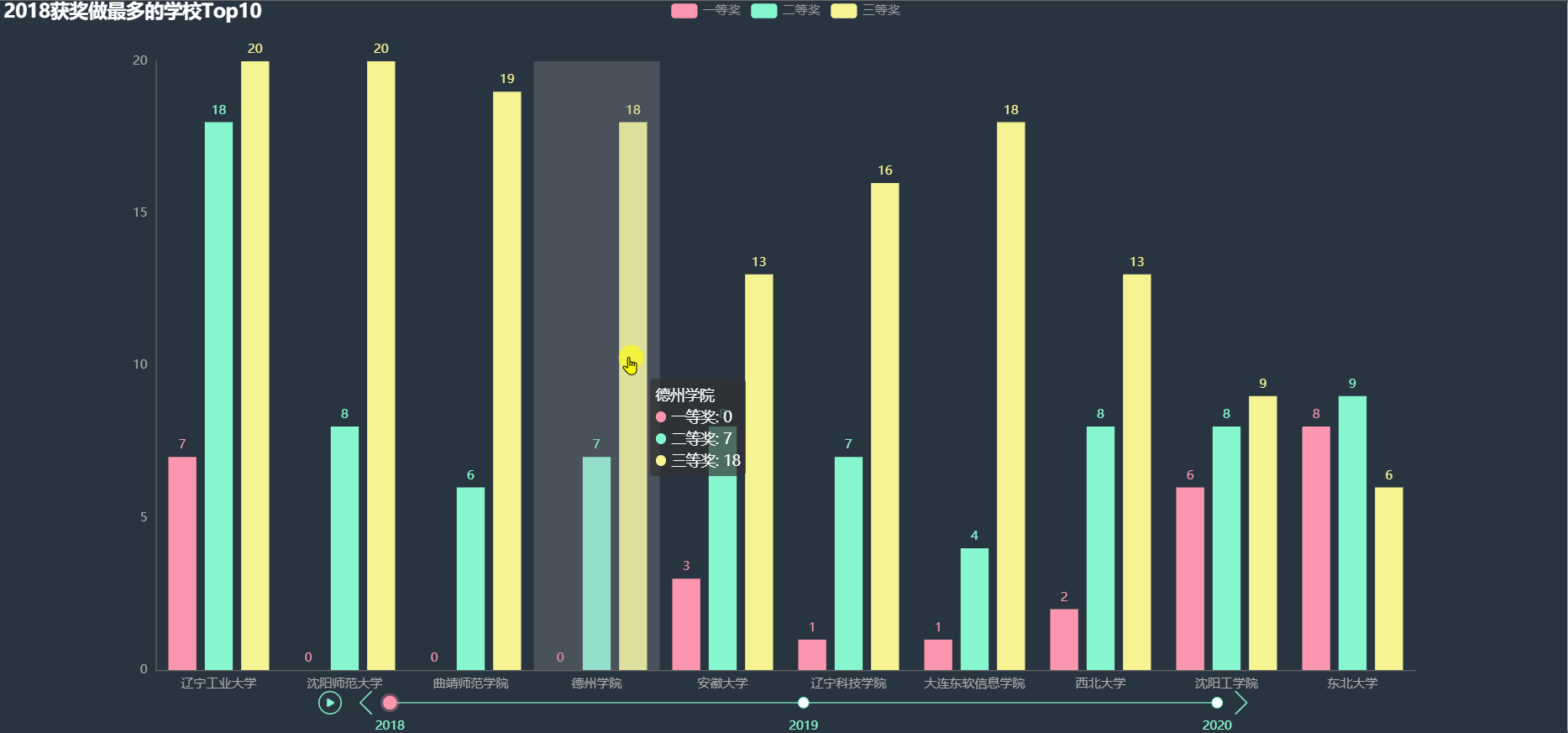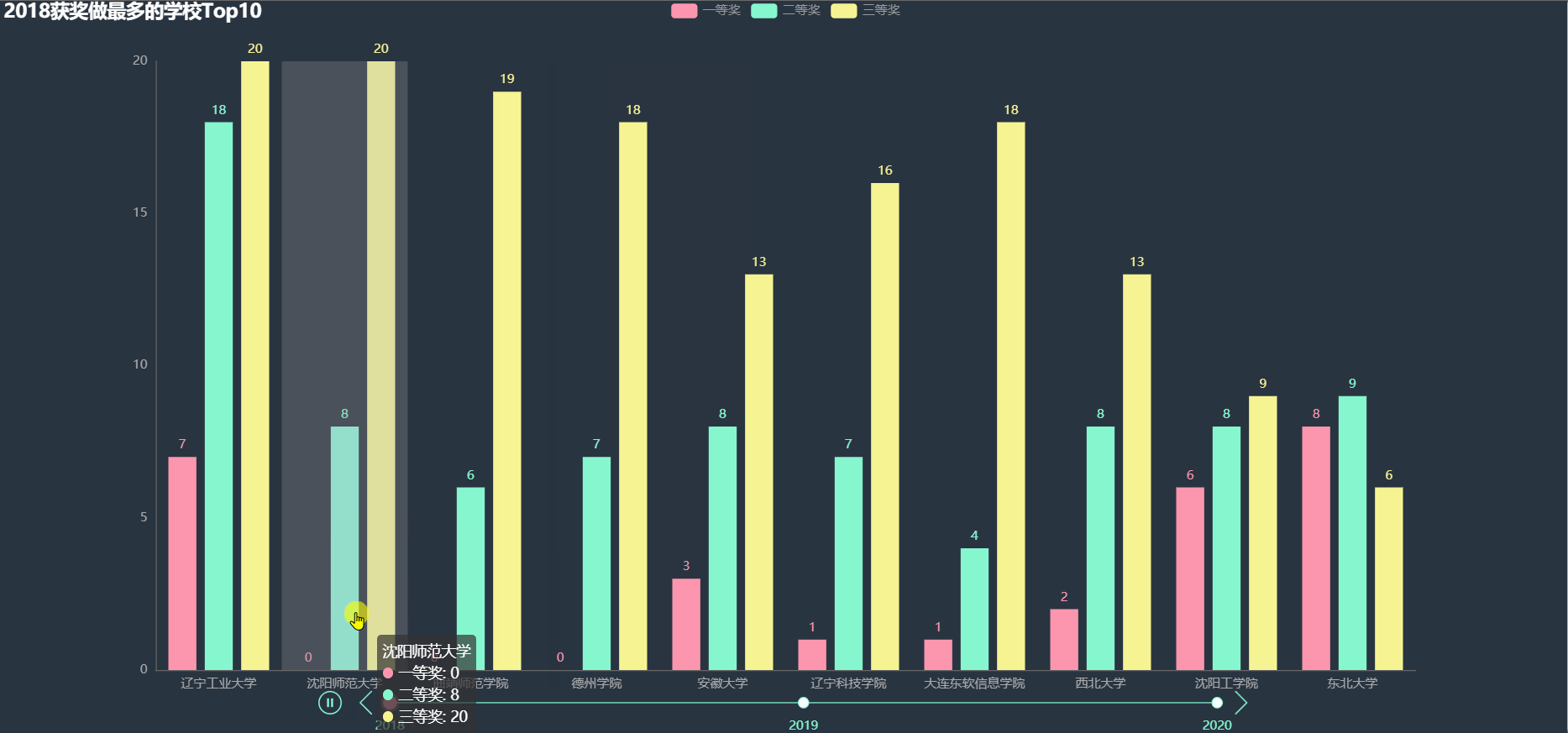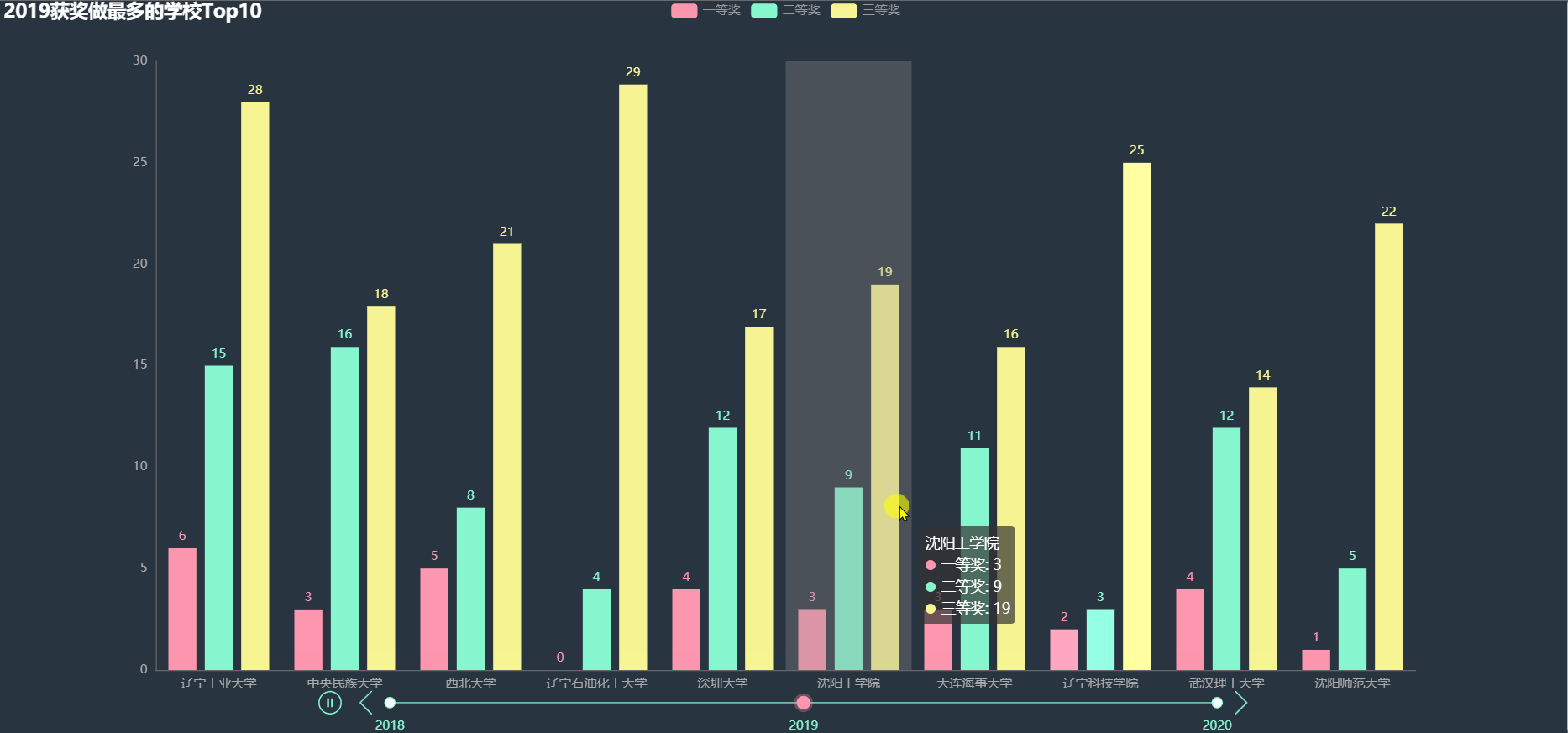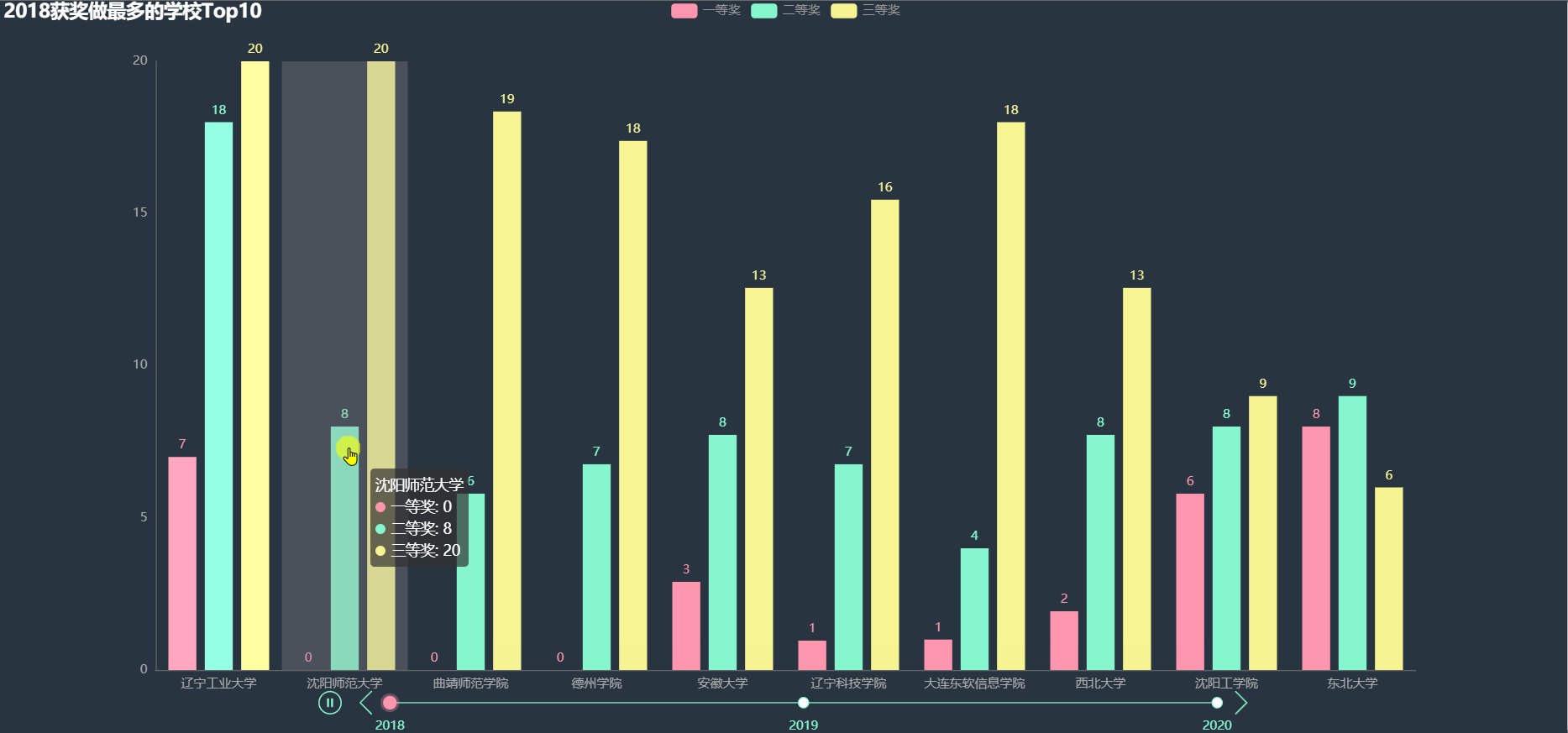
从上图中大致可以看到很多大学不止一次出现在 Top10 当中,在这些学校中,一部分可能是因为学校比较重视该比赛。
下面使用韦恩图详细看一下,哪些学校多次进入得奖最多 Top10。

沈阳师范大学、沈阳工学院、辽宁工业大学在三年中都进入 Top10,还有一些其他两次进入 Top10 的学校, 其中东北部的大学明显较多。
各学校参加次数统计
现在统计各个学校的参赛次数,并计算各次数的学校数量。
from collections import Counter
all_school = []
for year in [2018, 2019, 2020]:
school_set = set(all_df.loc[all_df['年份'] == year, '参赛学校'].values.tolist())
all_school += list(school_set)
value_count = Counter(all_school)
count_list = ['参赛' + str(n) + '次' for n in value_count.values()]
counter = Counter(count_list)
from pyecharts.charts import Pie
c = Pie(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
c.add("", [list(z) for z in zip(counter.keys(), counter.values())])
c.set_global_opts(title_opts=opts.TitleOpts(title="Pie-基本示例"))
c.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
c.render("./images/各学校参加次数统计饼图.html")
c.render_notebook()

在这三年的参赛学校中,三次参赛的占了一半左右,参赛一次和参赛两次的各占 25% 左右,这么说,参加比赛的学校还是愿意继续下一届继续去参加,说明该比赛是有吸引学校的地方。
各年参赛学校层次划分
统计各年参赛学校的层次,观察参加比赛学校的层次分布。

三年中,绝大多数的参赛者来自普通本科,其次为211,并且各层次的学校参赛人数在逐年上升。普通本科最为显著。可以看到,随着大赛的宣传和计算机的普及,越来越多的人关注计算机方面的比赛。(对于暂无数据的那一列部分原因是因为学校的信息没有收录,还有可能是参赛选手填写学校时出现失误造成)
参赛人数与奖项分布
根据作者和指导老师的人数进行组合,统计各奖项中出现的次数,绘制如下图形。
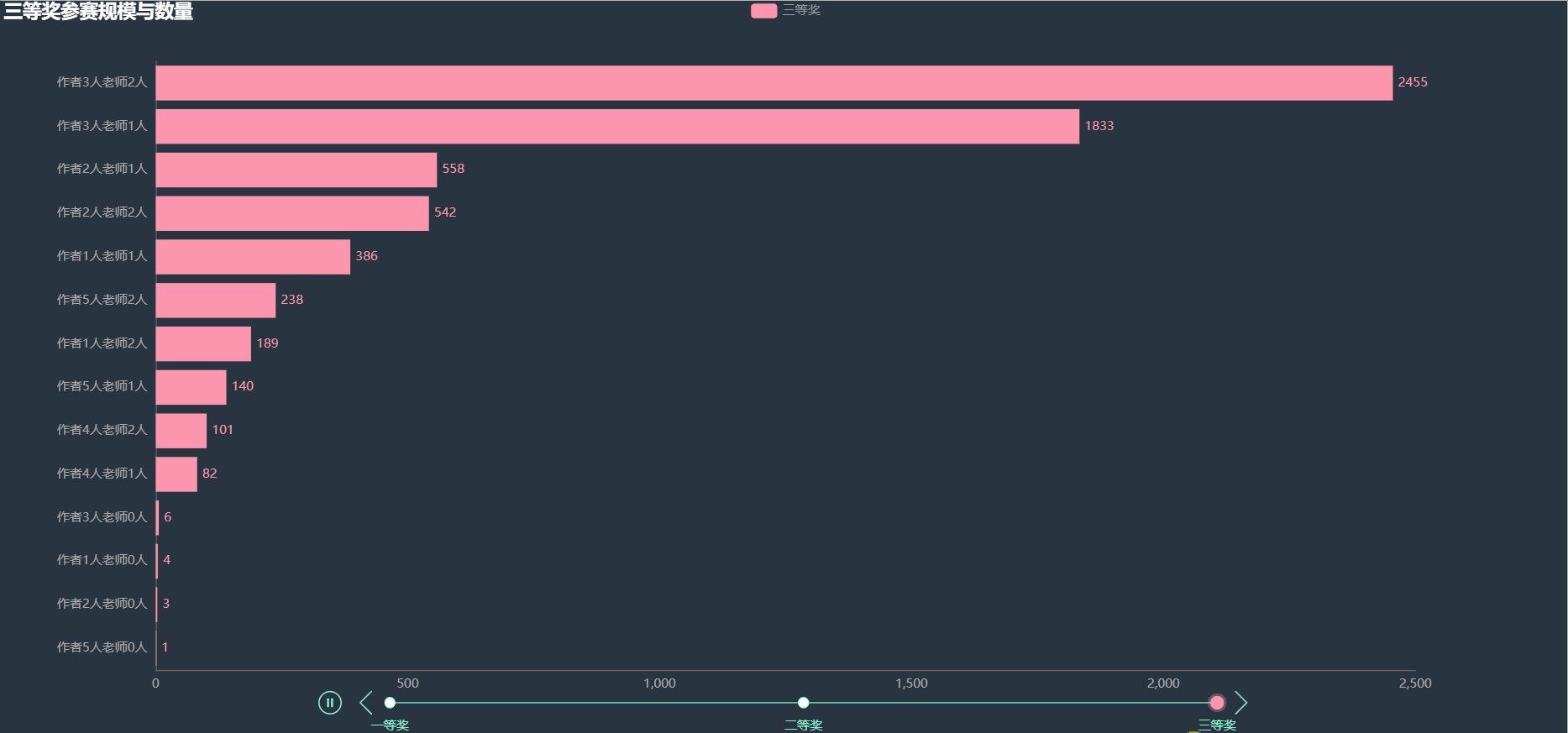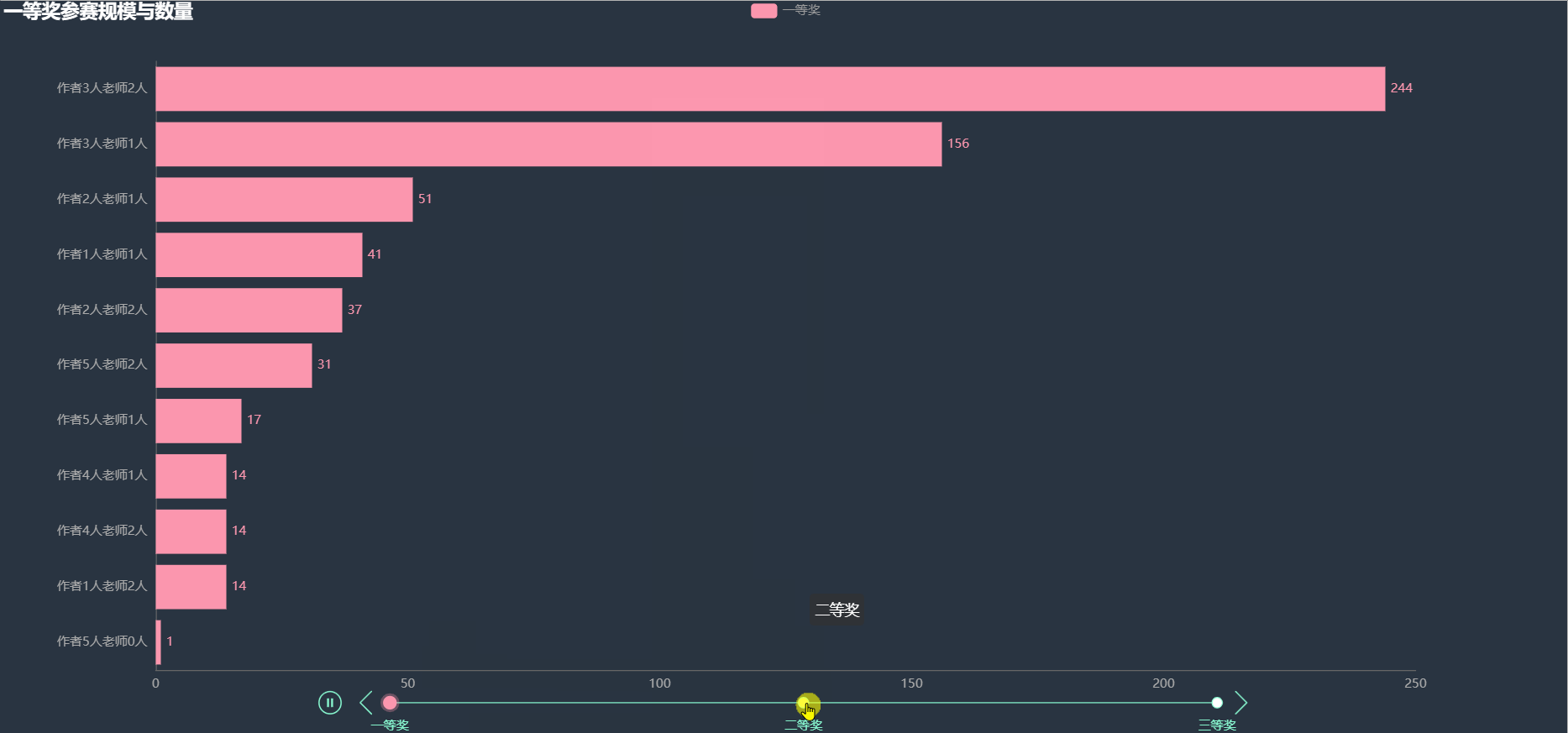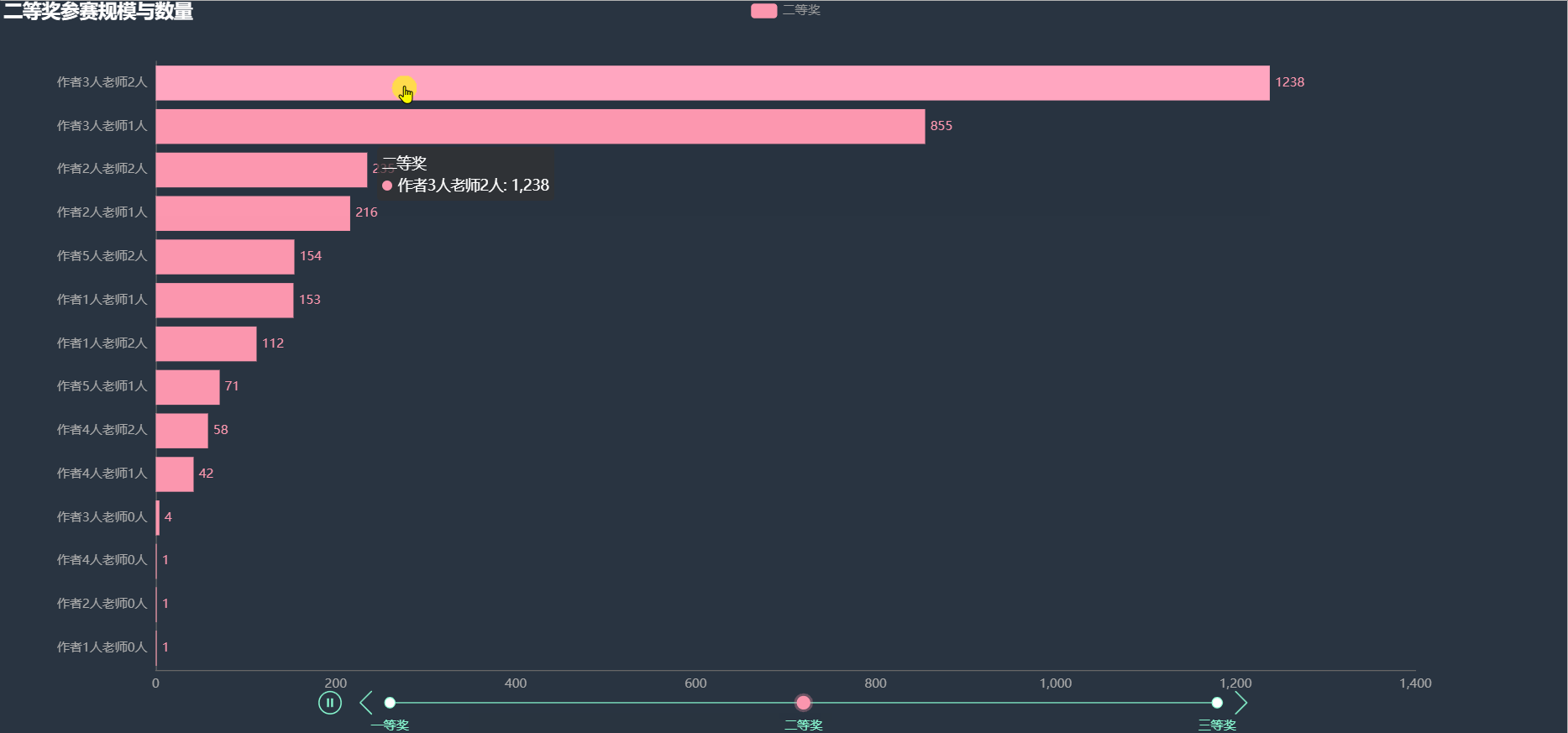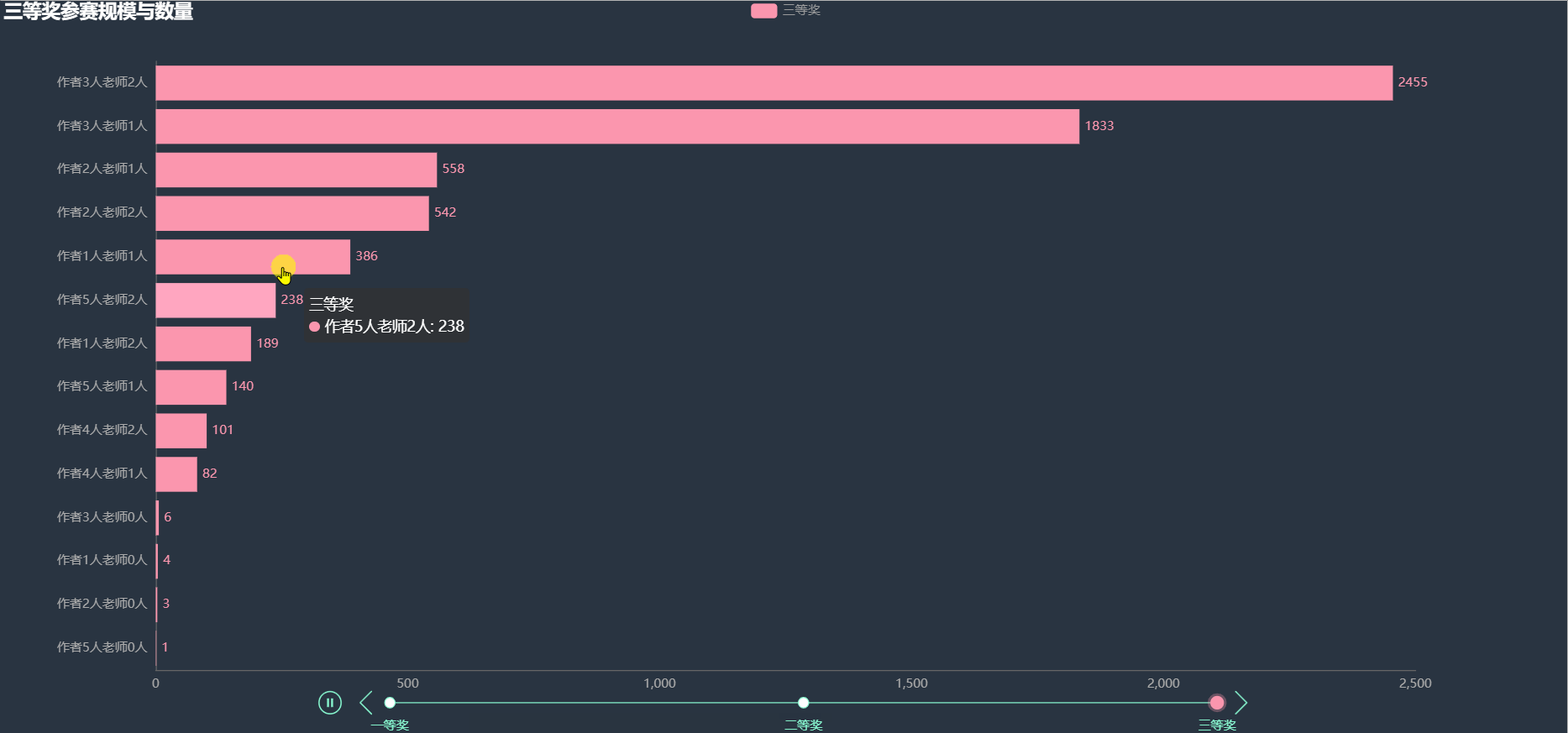
在各项奖项中,获奖比例最多的都是3名作者2名老师的阵容,其次就是3名作者1名老师。其余的阵容获奖人数就比较少了。看样子也不是人数越多获奖几率越大。
获奖作品名称热词
首先定义一个加载停用词的函数,用于加载本地停用词。
def load\_stopwords(read_path):
'''
读取文件每行内容并保存到列表中
:param read\_path: 待读取文件的路径
:return: 保存文件每行信息的列表
'''
result = []
with open(read_path, "r", encoding='utf-8') as f:
for line in f.readlines():
line = line.strip('\n') # 去掉列表中每一个元素的换行符
result.append(line)
return result
# 加载中文停用词
stopwords = load_stopwords('wordcloud\_stopwords.txt')
统计所有作品名称中去除停用词后的词汇,保存到列表中。
还有兄弟不知道网络安全面试可以提前刷题吗?费时一周整理的160+网络安全面试题,金九银十,做网络安全面试里的显眼包!
王岚嵚工程师面试题(附答案),只能帮兄弟们到这儿了!如果你能答对70%,找一个安全工作,问题不大。
对于有1-3年工作经验,想要跳槽的朋友来说,也是很好的温习资料!
【完整版领取方式在文末!!】
93道网络安全面试题
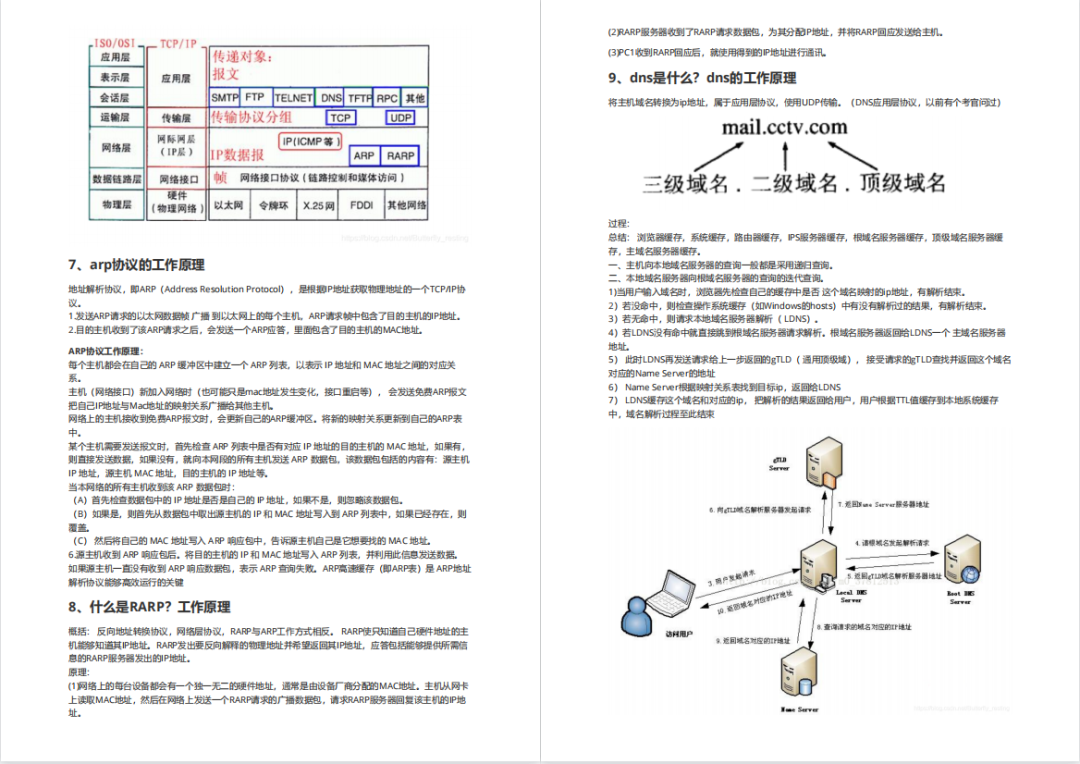


内容实在太多,不一一截图了
黑客学习资源推荐
最后给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
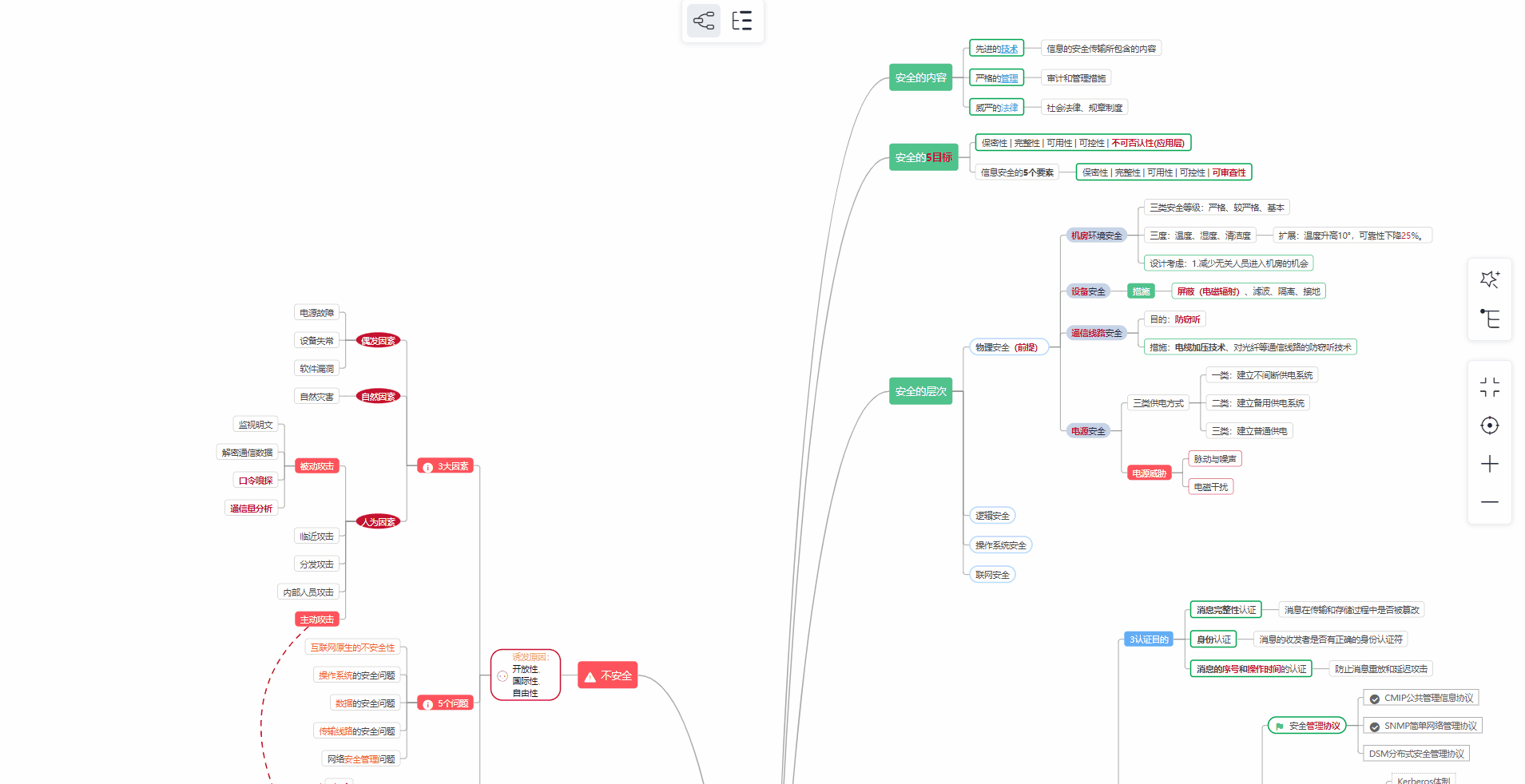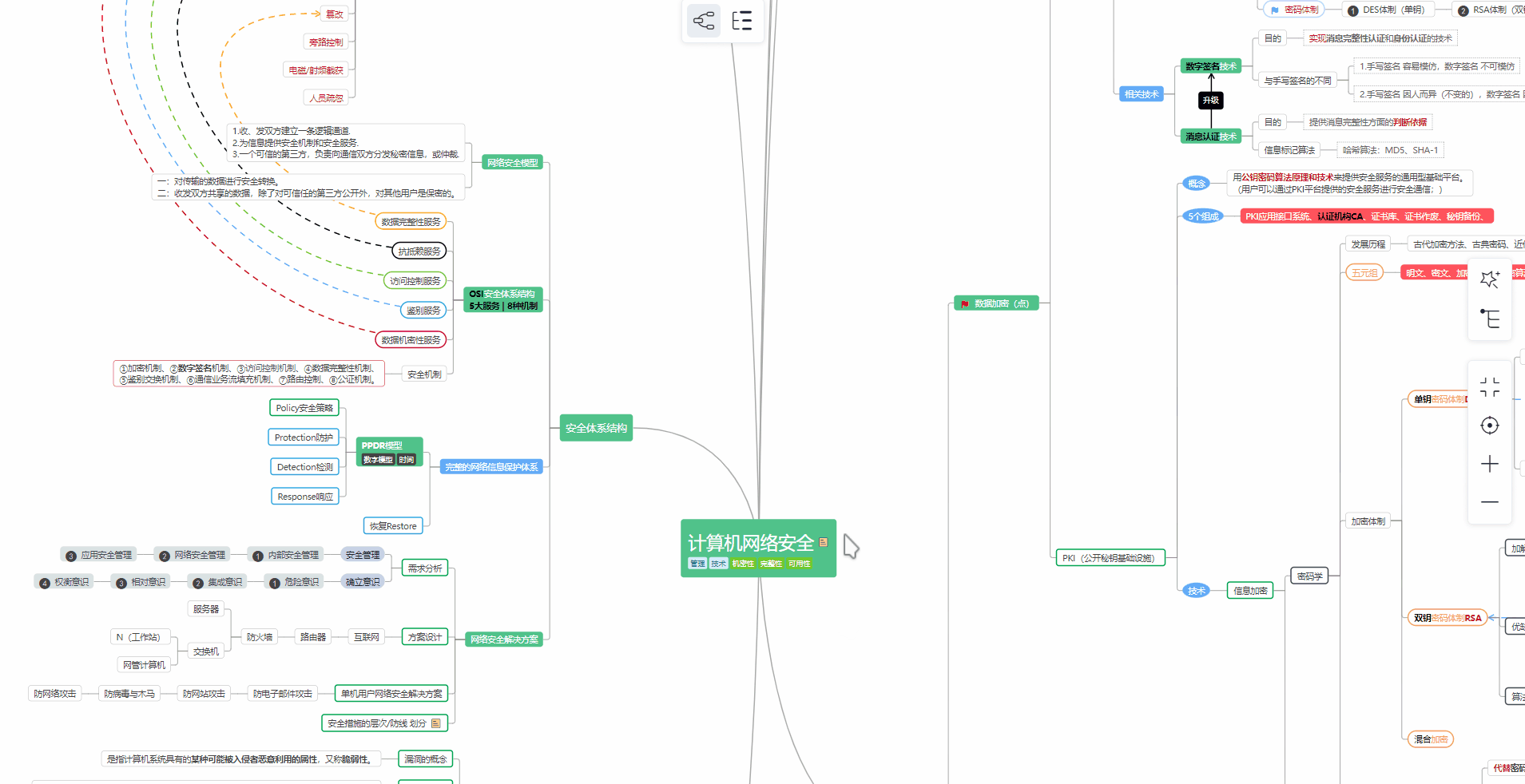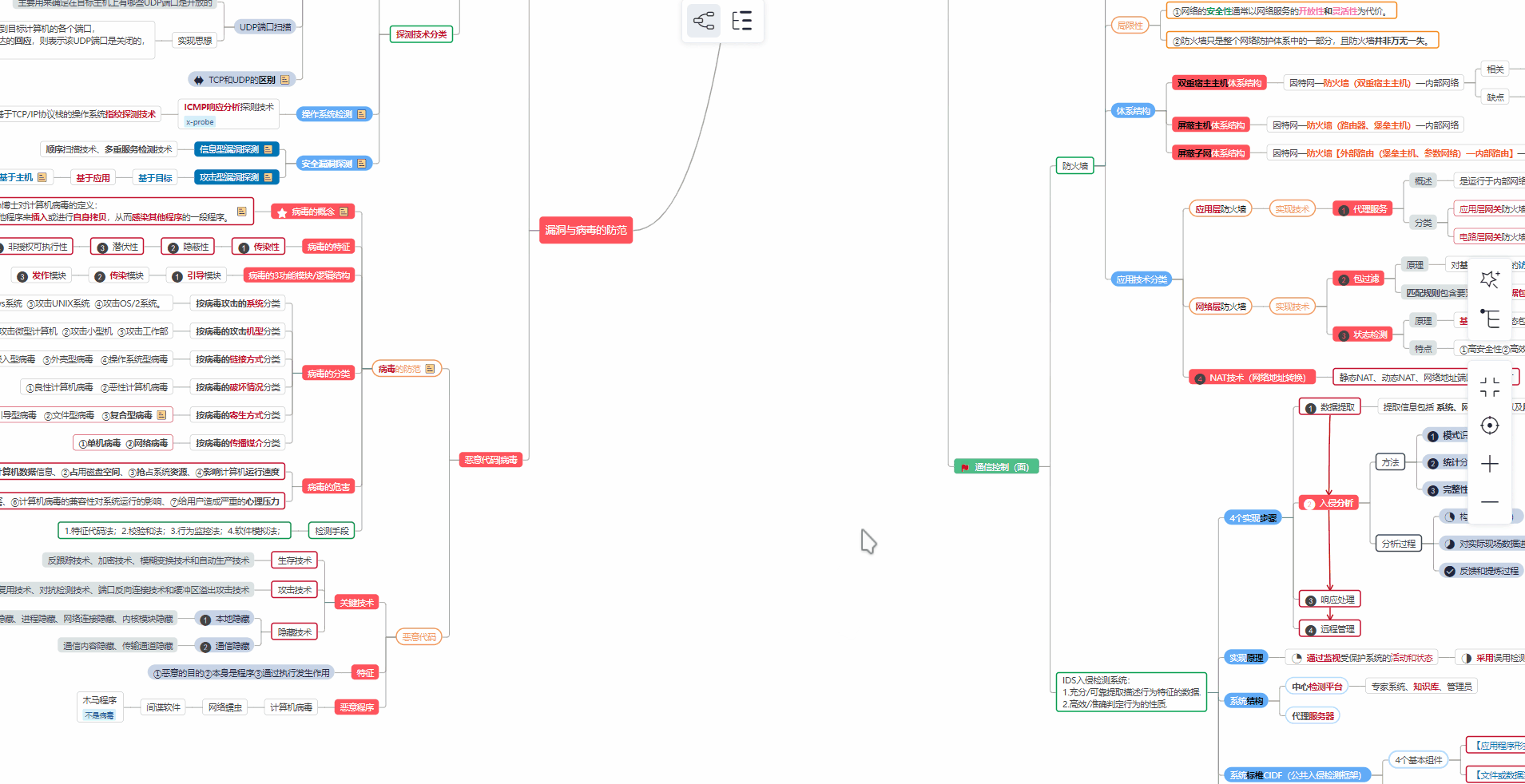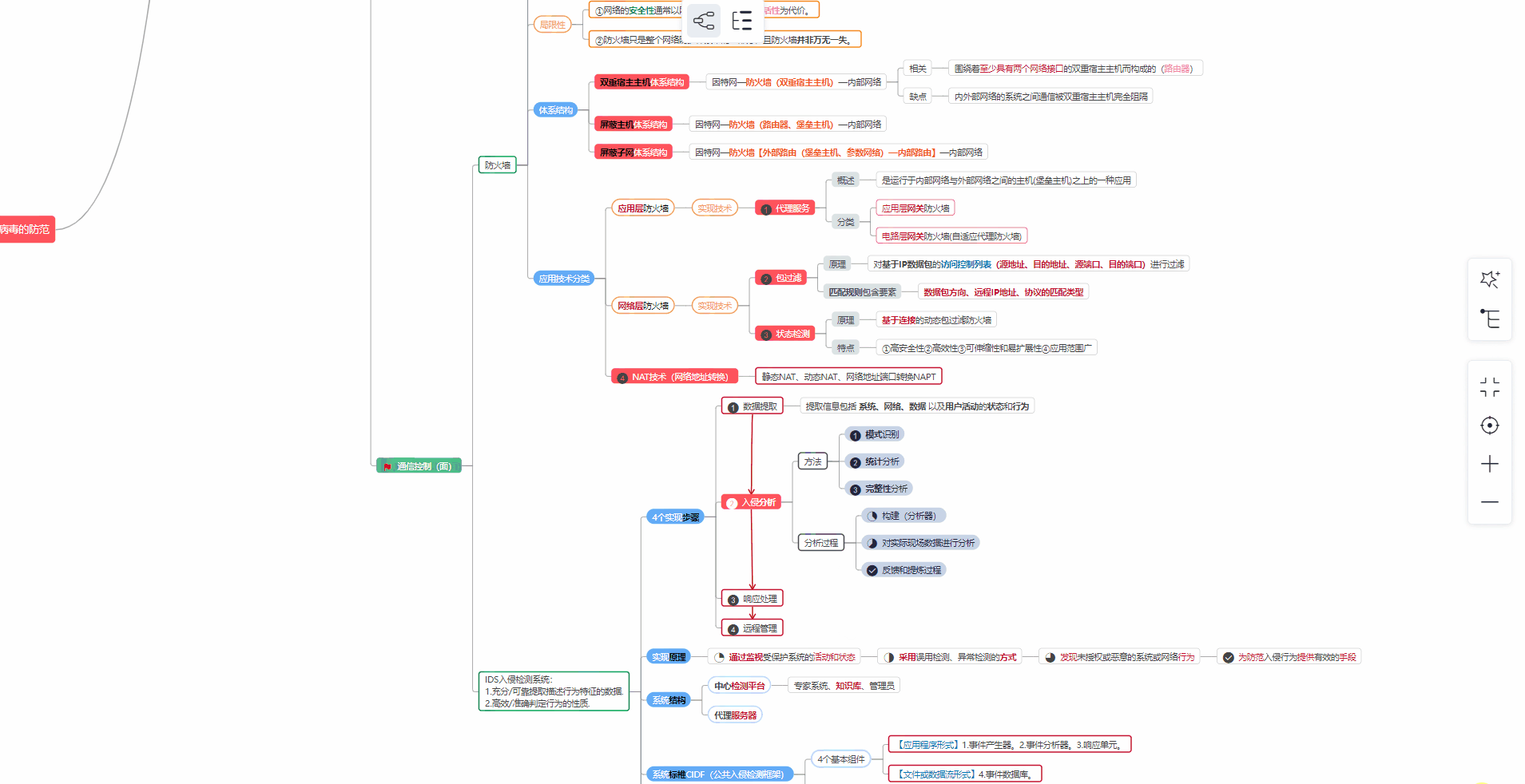
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
😝朋友们如果有需要的话,可以联系领取~
1️⃣零基础入门
① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:

2️⃣视频配套工具&国内外网安书籍、文档
① 工具

② 视频
③ 书籍
资源较为敏感,未展示全面,需要的最下面获取

② 简历模板
因篇幅有限,资料较为敏感仅展示部分资料,添加上方即可获取👆
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 6635
6635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









