







Map<String, Integer> treeMap = new TreeMap<>();
#### 5.3 LinkedHashMap
LinkedHashMap是Java中另一个Map集合实现类,它继承自HashMap,并保持了插入顺序。也就是说,遍历LinkedHashMap集合时,得到的键值对的顺序是按照插入顺序排序的。下面是创建LinkedHashMap集合的代码示例:
Map<String, Integer> linkedHashMap = new LinkedHashMap<>();
#### 5.4 Hashtable
Hashtable是Java中另一个Map集合实现类,**它与HashMap非常相似,但Hashtable是线程安全的**。Hashtable的存储方式是无序的,也就是说,遍历Hashtable集合时,得到的键值对的顺序是不确定的。下面是创建Hashtable集合的代码示例:
Map<String, Integer> hashtable = new Hashtable<>();
需要注意的是,**由于Hashtable是线程安全的,所以在多线程环境中使用Hashtable的性能可能会较低**,现在一般是建议使用ConcurrentHashMap。
#### 5.5 ConcurrentHashMap
ConcurrentHashMap是Java中的另一个Map集合实现类,**它与Hashtable非常相似,但是ConcurrentHashMap是线程安全的,并且性能更高**。ConcurrentHashMap的存储方式是无序的,也就是说,遍历ConcurrentHashMap集合时,得到的键值对的顺序是不确定的。下面是创建ConcurrentHashMap集合的代码示例:
Map<String, Integer> concurrentHashMap = new ConcurrentHashMap<>();
需要注意的是,**虽然ConcurrentHashMap是线程安全的,但仍然需要注意多线程环境下的并发问题**。
## 二. HashMap集合
### 1. 简介
HashMap继承自AbstractMap类,实现了Map、Cloneable、java.io.Serializable接口,如下图所示:
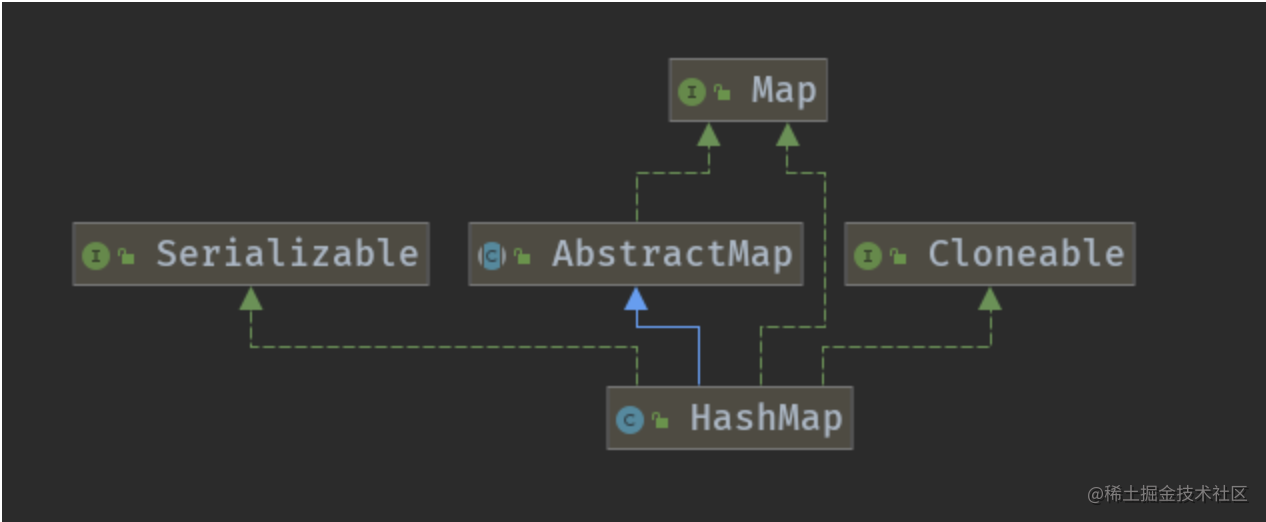
HashMap是基于散列表实现的双列集合,它存储的是key-value键值对映射,每个key-value键值对也被称为一条Entry条目。其中的 key与 value,可以是任意的数据类型,其类型可以相同也可以不同。但一般情况下,key都是String类型,有时候也可以使用Integer类型;value可以是任何类型。并且**在HashMap中,最多只能有一个记录的key为null,但可以有多个value的值为null。**
**HashMap中这些键值对(Entry)会分散存储在一个数组当中,这个数组就是HashMap的主体。** 默认情况下,HashMap这个数组中的每个元素的初始值都是null。**但HashMap中最多只允许一条记录的key为null,允许多条记录的value为null。**
**另外HashMap是非线程安全的,即任一时刻如果有多个线程同时对HashMap进行写操作,有可能会导致数据的不一致。** 如果需要满足线程的安全性要求,可以用 **Collections.synchronizedMap()** 方法使得HashMap具有线程安全的能力,或者使用**ConcurrentHashMap**来替代。
HashMap实现了Map接口,会根据key的hashCode值存储数据,具有较快的访问速度。另外HashMap是无序的,不会记录插入元素的顺序。**我们一般是根据key的hashCode值来存取数据,** 大多数情况下都可以直接根据key来定位到它所对应的值,因而HashMap有较快的访问速度,但遍历顺序却不确定。
### 2. 特点
根据上面的描述,**把HashMap的核心特点总结如下:**
* **基于哈希表实现,具有快速查找键值对的优点;**
* **HashMap的存储方式是无序的;**
* **HashMap的key-value可以是任意类型,但key一般都是String类型,value类型任意;**
* **HashMap最多只能有一个记录的key为null,但可以有多个value为null。**
### 3. 常用操作
HashMap的使用方法和其他Map集合类似,主要包括添加元素、删除元素、获取元素、遍历元素等操作。接下来会详细地给大家介绍HashMap集合的常用操作。
#### 3.1 创建Map集合对象
创建HashMap对象的方式有多种,我们可以使用构造函数,代码如下:
// 使用构造函数创建HashMap对象
Map<String, Integer> map1 = new HashMap<>();
#### 3.2 添加元素
向HashMap集合添加元素的方式和List集合类似,也是使用put()方法,下面是向HashMap集合中添加元素的代码示例:
public class Demo14 {
public static void main(String[] args) {
//HashMap
Map<String, String> map = new HashMap<>();
map.put("name","一一哥");
//map.put("name","壹哥");
map.put("age", "30");
map.put("sex", "男");
System.out.println("map="+map);
}
}
看到上面的代码,有些小伙伴可能会问,如果我们往同一个Map中存储两个相同的key,但分别放入不同的value,这会有什么问题吗?
**其实我们在Map中,重复地放入** **key-value** **并不会有任何问题,但一个** **key** **只能关联一个** **value** **。** 因为当我们调用put(K key, V value)方法时,如果放入的key已经存在,put()方法会返回被删除的旧value,否则就会返回null。所以Map中不会有重复的key,因为放入相同的key时,就会把原有key对应的value给替换掉。
#### 3.3 删除元素
从HashMap集合中删除元素的方式也和List集合类似,使用remove()方法。下面是从HashMap集合中删除元素的代码示例:
//从HashMap集合中移除元素
map.remove(“age”);
#### 3.4 获取元素
从HashMap集合中获取元素的方式和List集合不同,需要使用键来获取值。`HashMap`集合提供了两种方法来获取值,一种是使用`get()方法`,另一种是使用`getOrDefault()方法`。如果指定的键不存在,使用`get()方法`会返回`null`,而`getOrDefault()方法`则会返回指定的默认值。下面是从HashMap集合中获取元素的代码示例:
public class Demo15 {
public static void main(String[] args) {
//HashMap
Map<String, String> map = new HashMap<>();
map.put("name","一一哥");
map.put("age", "30");
map.put("sex", "男");
//根据key获取指定的元素
String name = map.get("name");
String age = map.get("age");
//根据key获取指定的元素,并设置默认值
String sex = map.getOrDefault("sex","男");
String height = map.getOrDefault("height","0");
System.out.println("[name]="+name+",[age]="+age+",[sex]="+sex+",[height]="+height);
}
}
#### 3.5 遍历元素
遍历HashMap集合的方式和List集合不同,需要使用迭代器或者foreach循环遍历键值对,下面是遍历HashMap集合的代码示例:
/**
* @author 一一哥Sun
*/
public class Demo16 {
public static void main(String[] args) {
//HashMap
Map<String, String> map = new HashMap<>();
map.put("name","一一哥");
map.put("age", "30");
map.put("sex", "男");
//遍历方式一:使用迭代器遍历HashMap
//获取集合中的entry条目集合
Set<Entry<String, String>> entrySet = map.entrySet();
//获取集合中携带的Iterator迭代器对象
Iterator<Map.Entry<String, String>> iterator = entrySet.iterator();
//通过循环进行迭代遍历
while (iterator.hasNext()) {
//获取每一个Entry条目对象
Map.Entry<String, String> entry = iterator.next();
//获取条目中的key
String key = entry.getKey();
//获取条目中的value
String value = entry.getValue();
System.out.println(key + " = " + value);
}
//遍历方式二:用foreach循环遍历HashMap
for (Map.Entry<String, String> entry : map.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + " = " + value);
}
}
}
大家要注意,当我们使用Map时,任何依赖顺序的逻辑都是不可靠的。比如,我们存入"A",“B”,“C” 3个key,遍历时,每个key会保证被遍历一次且仅遍历一次,但遍历的顺序完全没有保证,甚至对于不同的JDK版本,相同的代码遍历输出的顺序都可能是不同的!所以我们在 遍历Map时,要注意输出的key是无序的!
#### 3.6 判断Map集合是否为空
判断HashMap集合是否为空可以使用isEmpty()方法,如果Map集合为空,则返回true,否则返回false。下面是判断HashMap集合是否为空的代码示例:
// 判断HashMap是否为空
boolean isEmpty = map.isEmpty();
#### 3.7 获取Map集合的大小
获取HashMap集合的大小可以使用size()方法,返回HashMap集合中键值对的数量,下面是获取HashMap集合大小的代码示例:
// 获取HashMap的大小
int size = map.size();
#### 3.8 判断Map集合是否包含指定的键或值
如果我们想判断HashMap集合是否包含指定的键或值,可以使用containsKey()和containsValue()方法。如果Map集合包含指定的键或值,则返回true,否则返回false。下面是判断HashMap集合是否包含指定键或值的代码示例:
// 判断HashMap是否包含指定键
boolean containsKey = map.containsKey(“name”);
// 判断HashMap是否包含指定值
boolean containsValue = map.containsValue(“一一哥”);
#### 3.9 替换Map集合中的键值对
如果我们想替换HashMap集合中的键值对,可以使用replace()方法将指定键的值替换成新的值。如果指定的键不存在,则不进行任何操作。下面是替换HashMap集合中的键值对的代码示例:
// 替换HashMap中的键值对
map.replace(“name”, “壹哥”);
#### 3.10 合并两个Map集合
如果我们想合并两个HashMap集合,可以使用putAll()方法,将另一个HashMap集合中所有的键值对,添加到当前的HashMap集合中。下面是合并两个HashMap集合的代码示例:
public class Demo16 {
public static void main(String[] args) {
//HashMap
Map<String, String> map1 = new HashMap<>();
map1.put("name","一一哥");
map1.put("age", "30");
map1.put("sex", "男");
// 创建另一个TreeMap集合
Map<String, String> map2 = new HashMap<>();
map2.put("height", "180");
map2.put("salary", "5w");
//将map1中的键值对添加到map2中
map2.putAll(map1);
System.out.println("map2="+map2);
}
}
#### 3.11 获取Map集合中所有的键或值
如果我们想获取HashMap集合中所有的键或值,可以分别使用keySet()和values()方法。这两个方法会返回一个Set集合和一个Collection集合,它们包含了HashMap集合中所有的键或值。下面是获取HashMap集合中所有键或值的代码示例:
public class Demo18 {
public static void main(String[] args) {
//HashMap
Map<String, String> map = new HashMap<>();
map.put("name","一一哥");
map.put("age", "30");
map.put("sex", "男");
// 获取HashMap中所有的键
Set<String> keySet = map.keySet();
for(String key : keySet) {
System.out.println("key="+key);
}
// 获取HashMap中所有的值
Collection<String> values = map.values();
for(String value:values) {
System.out.println("value"+value);
}
}
}
### 4. 原理概述(重点)
作为开发时最常用的Map集合,HashMap在我们面试时被问到的概率非常高,尤其是关于**其原理、数据结构、冲突解决、并发、扩容**等相关的内容,更是经常被问到。
如果我们想要了解HashMap的底层原理,首先得知道HashMap的底层数据结构,而这个数据结构在不同的JDK版本中是不同的。我们可以把HashMap的底层数据结构分为两大版本,即**JDK 7及其以前的版本 和 JDK 8及其以后的版本。** 大家注意,本文主要是结合JDK 8的源码,给大家讲解HashMap的底层原理。
* **在JDK 7及其以前版本的HashMap中,其底层的数据结构是** **数组+链表** **;**
* **而从JDK 8开始则采用** **数组+链表+红黑树** **的数据结构,其中的** **数组是Entry类型或者说是Node类型数组** **。**
### 5. hash冲突解决机制
因为HashMap底层会使用Hash算法来处理数据的存取,当数据非常多时就有一定的概率出现hash冲突,其解决过程如下。
* 当我们往HashMap中存储数据时,首先会利用**hash(key)方法** **计算出key的hash值**,再利用该 **hash值** 与 **HashMap数组的长度-1** 进行 **与运算**,从而得到该key在数组中对应的**下标位置**;
* 如果该位置上目前还没有存储数据,则直接将该key-value键值对数据存入到数组中的这个位置;
* 如果该位置目前已经有了数据,则把新的数据存入到一个链表中;
* 当链表的长度超过阈值(JDK 8中该值为8)时,会将链表转换为红黑树(转换为红黑树还需要满足其他的条件,链表长度达到阈值只是其中的一个条件)。
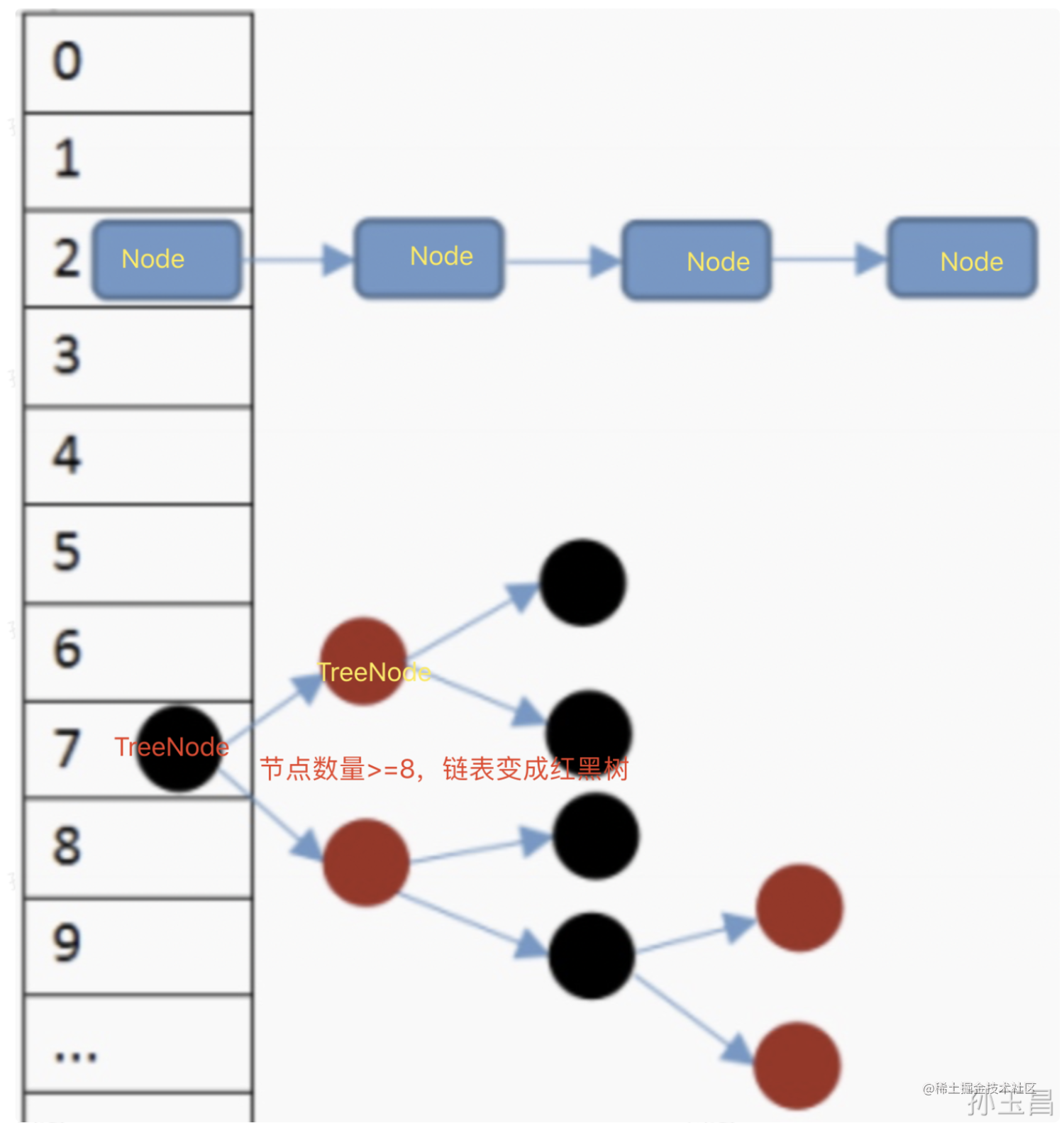
通过这样的机制,HashMap就解决了存值时可能产生的哈希冲突问题,并可以大大提高我们的查找效率。
当然由于HashMap极其重要,它的内容非常多,尤其是原理性的内容更多。但由于篇幅限制,不会在本文中过多地讲解HashMap原理等的内容
## 三. Hashtable集合
### 1. 简介
Hashtable也是Java中的一个Map集合,它与HashMap非常相似,但Hashtable是线程安全的,而HashMap不是线程安全的。Hashtable也可以存储键值对,并可以通过键快速查找到对应的值,Hashtable的键和值也都可以是任何类型的对象。
因为Hashtable是线程安全的,因此适用于多线程环境。在多线程环境中,如果需要对Hashtable进行多个操作,需要使用synchronized关键字来保证线程安全。但需要我们注意的是,在多线程环境中使用Hashtable可能会影响性能,所以如果不需要保证线程安全,请尽量使用HashMap。
Hashtable集合的底层结构主要是**数组+链表,数组是Entry数组,链表也是用Entry来实现的** **。** 所以Hashtable的底层核心,其实也是基于哈希表,它使用哈希函数将键映射到哈希表中的一个位置,从而实现快速查找。另外Hashtable的存储方式是无序的,也就是说,遍历Hashtable集合得到的键值对的顺序是不确定的。
### 2. 常用方法
**Hashtable与HashMap类似,它的常用方法也与HashMap一样:**
* put(K key, V value):将指定的键值对存储到Hashtable中。
* get(Object key):返回指定键所对应的值,如果不存在该键则返回null。
* remove(Object key):从Hashtable中移除指定键所对应的键值对。
* containsKey(Object key):判断Hashtable中是否包含指定的键。
* containsValue(Object value):判断Hashtable中是否包含指定的值。
* size():返回Hashtable中键值对的数量。
* clear():移除Hashtable中的所有键值对。
### 3. 基本使用
下面是一个简单的Hashtable集合示例,演示了如何创建Hashtable集合、存储键值对、获取值、遍历集合等操作。
import java.util.Hashtable;
import java.util.Map;
public class Demo19 {
public static void main(String[] args) {
// 创建Hashtable集合
Map<String, Integer> hashtable = new Hashtable<>();
// 存储键值对
hashtable.put("apple", 10);
hashtable.put("banana", 20);
hashtable.put("orange", 30);
// 获取值
int value1 = hashtable.get("apple");
int value2 = hashtable.get("banana");
int value3 = hashtable.get("orange");
System.out.println("apple: " + value1);
System.out.println("banana: " + value2);
System.out.println("orange: " + value3);
// 移除键值对
hashtable.remove("orange");
// 遍历集合
for (Map.Entry<String, Integer> entry : hashtable.entrySet()) {
String key = entry.getKey();
int value = entry.getValue();
System.out.println(key + ": " + value);
}
// 清空集合
hashtable.clear();
}
}
其他方法的使用与HashMap基本一致,**就不再一一细说了。**
## 四. ConcurrentHashMap集合
### 1. 简介
由于在多线程环境下,常规的HashMap可能会在数组扩容及重哈希时出现 **死循环、脏读** 等线程安全问题,虽然有HashTable、Collections.synchronizedMap()可以取代HashMap进行并发操作,但因它们都是利用一个 **全局的synchronized锁** 来同步不同线程之间的并发访问,因此性能较差。
所以Java就从**JDK 1.5**版本开始,在**J.U.C(java.util.concurrent并发包)** **中**引入了一个高性能的并发操作集合—ConcurrentHashMap(可以简称为CHM)。**该集合是一种线程安全的哈希表实现,相比Hashtable和SynchronizedMap,在多线程场景下具有更好的性能和可伸缩性**。
并且ConcurrentHashMap集合在读数据时不需要加锁,写数据时会加锁,但锁的粒度较小,不会对整个集合加锁。而其内部又**大量的利用了 volatile,final,CAS等lock-free(无锁并发)技术,减少了锁竞争对于性能的影响,具有更好的写并发能力,但降低了对读一致性的要求。** 因此既保证了并发操作的安全性,又确保了读、写操作的高性能,可以说它的并发设计与实现都非常的精巧。
另外**ConurrentHashMap中的key与value都不能为null,否则会产生空指针异常!**
### 2. ConcurrentHashMap类关系
ConcurrentHashMap与HashMap具有相同的父类AbstractMap,他俩可以说是“亲兄弟”,所以ConcurrentHashMap在一般的特性和使用上与HashMap基本是一致的,甚至很多底层原理也是相似的。
但两者所在的包是不同的,ConcurrentHashMap是在java.util.concurrent包中,HashMap是在java.util包中,我们可以**参考下图:**

以上所述的ConcurrentHashMap概念及特征,是不区分版本的,但实际上不同版本的ConcurrentHashMap内部实现差异很大,所以面试时经常会被问到不同版本之间的差异、各自特征。接下来会针对JDK 7 与 JDK 8 这两个经典版本分别进行阐述。
### 3. 实现原理
#### 3.1 并发控制机制
**在JDK 7中,ConcurrentHashMap的核心机制是分段锁(Segment),每个Segment内部维护了一个哈希表,且这个哈希表是线程安全的**。而ConcurrentHashMap中的每个操作,都是先对所在的Segment进行加锁,然后再执行具体的操作。
**先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7**
**深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**






**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/topics/618540462)**
套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**
[外链图片转存中...(img-c2epBRyo-1714643823976)]
[外链图片转存中...(img-adk1ZAS8-1714643823976)]
[外链图片转存中...(img-wDRohThE-1714643823977)]
[外链图片转存中...(img-ea6YrfQU-1714643823977)]
[外链图片转存中...(img-sePVNhpz-1714643823978)]
[外链图片转存中...(img-1w98H4lC-1714643823978)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/topics/618540462)**















 470
470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









