






给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
1.简介
1.1 简单介绍
Lept4J和Tess4J都是基于Tesseract OCR引擎的Java接口,可以用来识别图像中的文本:
- 前者是Leptonica图像处理库的Java封装,提供了图像的加载、处理、分析等功能。
- 后者是Tesseract OCR引擎的Java封装,提供了图像的OCR识别、PDF文档的生成等功能。
Lept4J和Tess4J的区别在于,Lept4J主要负责图像的预处理,而Tess4J主要负责图像的后处理,特点分别是:
- Lept4J支持多种图像格式,可以进行图像的缩放、旋转、裁剪、二值化、降噪等操作,提高图像的质量和识别率。
- Tess4J支持多种语言的识别,可以生成文本、HTML、PDF等格式的输出,提供了多种识别模式和参数设置,满足不同的需求。
根据具体场景和需求,可以选择使用Lept4J或Tess4J,或者结合使用两者,以达到最佳的效果。
1.2 官方说明
官网:https://tess4j.sourceforge.net/
描述:A Java JNA wrapper for Tesseract OCR API.Tess4J is released and distributed under the Apache License, v2.0 and is also available from Maven Central Repository.
特性:The library provides optical character recognition (OCR) support for:
- TIFF, JPEG, GIF, PNG, and BMP image formats
- Multi-page TIFF images
- PDF document format
2.使用举例
2.1 依赖及语言数据包
<!-- https://mvnrepository.com/artifact/net.sourceforge.tess4j/tess4j -->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.9.0</version>
</dependency>
语言数据包下载地址:https://github.com/tesseract-ocr/tessdata

2.2 核心代码
/\*\*
\* 识别图片字符信息
\*
\* @param imagePath 图片路径
\*/
private static String recognitionString(String imagePath) {
File imageFile = new File(imagePath);
ITesseract instance = new Tesseract();
// 1.语言数据包路径
instance.setDatapath("tessdata");
// 2.加载语言文件名称
instance.setLanguage("chi\_sim");
String result = "";
try {
result = instance.doOCR(imageFile);
} catch (TesseractException e) {
e.printStackTrace();
}
return result;
}
2.3 识别身份证信息
2.3.1 核心代码
/\*\*
\* 识别身份证信息
\*
\* @param imagePath 图片路径
\*/
private static Map<String, Object> recognitionIdentityCardInfo(String imagePath) {
Map<String, Object> res = new HashMap<>(2);
// 识别图片
File imageFile = new File(imagePath);
BufferedImage bufferedImage = null;
try {
bufferedImage = ImageIO.read(imageFile);
} catch (IOException e) {
e.printStackTrace();
}
ITesseract instance = new Tesseract();
instance.setDatapath("tessdata");
instance.setLanguage("chi\_sim");
List<Word> words = instance.getWords(bufferedImage, 1);
// 获取姓名
int nameLineIndex = 0;
if (words.size() > nameLineIndex) {
res.put("name", getStringByIndex(words.get(0).getText(), 2));
}
// 获取性别和民族
int genderAndNationLineIndex = 1;
if (words.size() > genderAndNationLineIndex) {
res.put("gender", getStringByIndex(words.get(1).getText(), 2, 1));
res.put("nation", removeNonChinese(getStringByIndex(words.get(1).getText(), 5, -1)));
}
// 获取出生日期
int birthLineIndex = 2;
if (words.size() > birthLineIndex) {
res.put("birth", extractBirthDate(getStringByIndex(words.get(2).getText(), 2)));
}
// 获取住址
int addressLineIndex = 3;
if (words.size() > addressLineIndex) {
res.put("address", getStringByIndex(words.get(3).getText(), 2).replace("/", ""));
}
// 获取身份证号码
int noLineIndex = 4;
if (words.size() > noLineIndex) {
res.put("no", getStringByIndex(words.get(4).getText(), 7));
}
return res;
}
2.3.2 截取指定字符
/\*\*
\* 截取指定字符
\*
\* @param inputString 字符串
\* @param indexStart 开始Index
\* @return 截取的字符串
\*/
private static String getStringByIndex(String inputString, int indexStart) {
return getStringByIndex(inputString, indexStart, -1);
}
/\*\*
\* 截取指定字符
\*
\* @param inputString 字符串
\* @param indexStart 开始Index
\* @param size 截取的字符个数
\* @return 截取的字符串
\*/
private static String getStringByIndex(String inputString, int indexStart, int size) {
// 去除字符串两端的空白字符
String trimmedString = inputString.trim();
// 将字符串以空白字符分割
StringBuilder res = new StringBuilder();
String[] words = trimmedString.split("\\s+");
int length = words.length;
int contentSize = indexStart + size;
if (length > indexStart) {
int index = length;
if (size > 0 && length > contentSize) {
### 如何自学黑客&网络安全
#### 黑客零基础入门学习路线&规划
**初级黑客**
**1、网络安全理论知识(2天)**
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
**2、渗透测试基础(一周)**
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
**3、操作系统基础(一周)**
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
**4、计算机网络基础(一周)**
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
**5、数据库基础操作(2天)**
①数据库基础
②SQL语言基础
③数据库安全加固
**6、Web渗透(1周)**
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:282G全网最全的网络安全资料包评论区留言即可领取!
**7、脚本编程(初级/中级/高级)**
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
如果你零基础入门,笔者建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习;搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime;·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完;·用Python编写漏洞的exp,然后写一个简单的网络爬虫;·PHP基本语法学习并书写一个简单的博客系统;熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选);·了解Bootstrap的布局或者CSS。
**8、超级黑客**
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,附上学习路线。
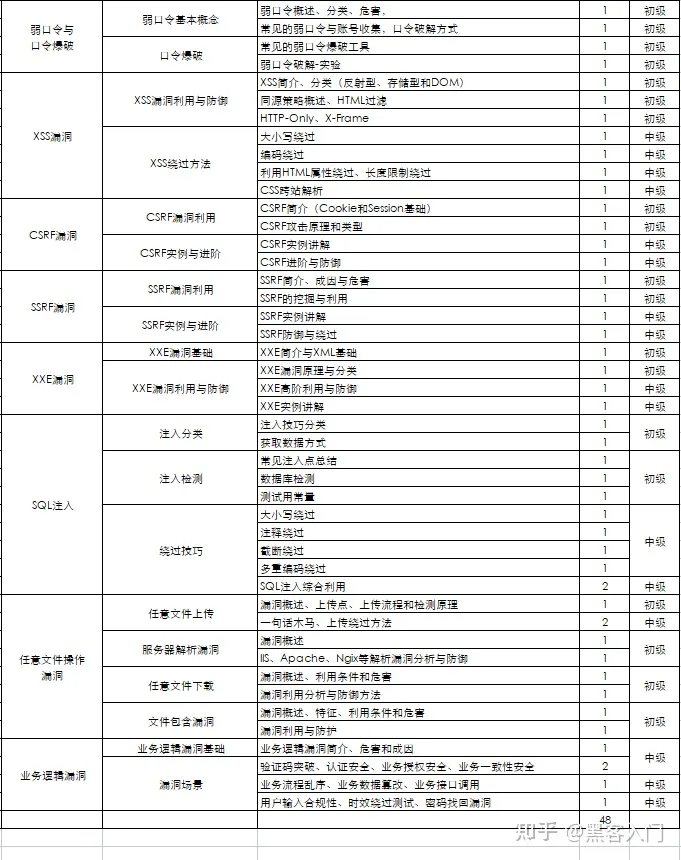
#### 网络安全工程师企业级学习路线

如图片过大被平台压缩导致看不清的话,评论区点赞和评论区留言获取吧。我都会回复的
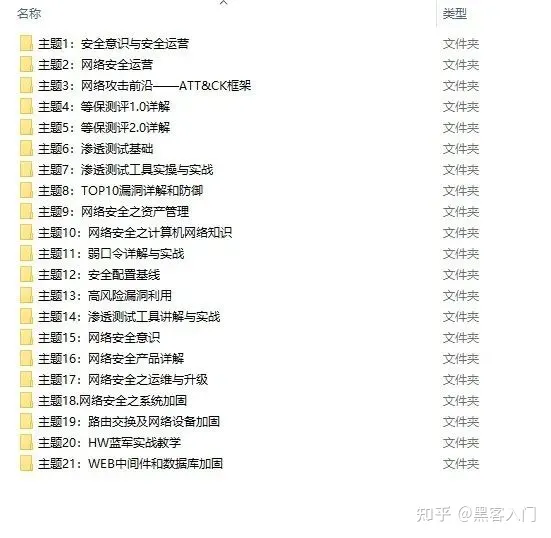
视频配套资料&国内外网安书籍、文档&工具
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

一些笔者自己买的、其他平台白嫖不到的视频教程。
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 797
797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









