







df.loc[len(df)] = ['乔巴', 3]
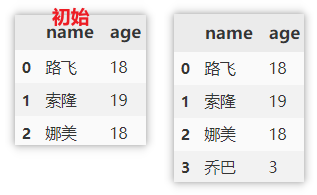
使用 append 添加
append 添加数据时需要指定列名,列值,如果某列未指定的话,则默认填充 NaN。
df.append({'name': '山治', 'age': 19}, ignore_index=True)
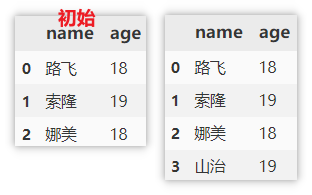
删除数据
根据列名删除列
使用 drop 来删除某列,指定要删除的轴,与对应 列/行 的 名称/索引。
df.drop('name', axis = 1) # 删除单列
df.drop(['name', 'age'], axis = 1) # 删除多列
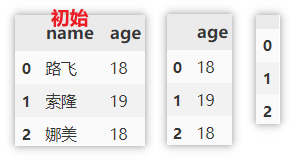
根据索引删除行
与上面删除列的方式相似,不过这里指定的是索引。
df.drop(0, axis=0) # 删除单行
df.drop([0, 1], axis=0) # 删除多行
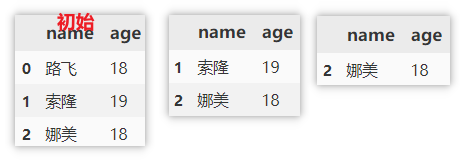
使用 loc 定位数据并删除
先使用 loc 定位某条件的数据,再获取索引 index ,然后使用 drop 删除。
df.drop(df.loc[df['name'] == '娜美'].index, axis=0) # 删除定位到的行
使用 del 删除列
del 是在原数据上进行修改,使用是要注意。
del df['age']
同时删除行、列
drop 也可以同时指定行列进行删除,这里删除第一、二行并删除 age 列。
df.drop(columns=['age'], index=[0, 1])

删除重复值
- 指定
subset,则根据指定的列作为参考进行去重,即如果某两行a值相同,则会删除第二次的出现的那一行,只保留第一次 - 不指定
subset,则根据所有列作为参考进行去重,只有两行数据 完全相同 才会进行去重。
df.drop_duplicates(subset=['a'], keep='first')
df.drop_duplicates(keep='first')

筛查重复值
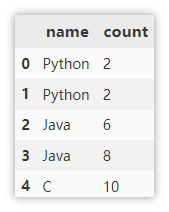
示例数据
df = pd.DataFrame({'name':['Python',
'Python',
'Java',
'Java',
'C'],
'count': [2, 2, 6, 8, 10]})
判断某列是否有重复值
使用 values_counts() 对列中各值出现次数进行统计。结果默认按照降序进行排列,只需要判断第一行值的出现次数是否为1即可判断是否存在重复值。
df['a'].value_counts()

使用 drop_duplicates() 对重复值进行删除,只保留第一次出现的值,判断处理后的值是否与原 df 相等,如果 False 就表示有重复值。
df.equals(df.drop_duplicates(subset=['a'], keep='first'))
False
判断 DataFrame 是否有重复行
同样是使用 drop_duplicates() 对重复值进行删除,只保留第一次出现的值,此时不使用 subset 参数设置列,默认为全部列,判断处理后的值是否与原 df 相等,如果 False 就表示有重复值。
df.equals(df.drop_duplicates(keep='first'))
False
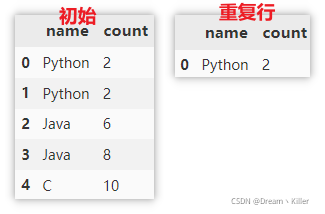
统计重复行的数量
注意这里的统计是参照所有列来的,只有两行完全相同才会判断为重复行,所以统计的结果是 1 。
len(df) - len(df.drop_duplicates(keep="first"))
1
显示重复的数据行
先删除重复的行,只保留第一次出现的,得到一个 行唯一 的数据集,再使用 drop_duplicates() 删除掉 df 中存在重复的所有数据,这次不保留第一次出现的重复值,将上述两个结果集进行合并,使用 drop_duplicates() 对新生成的数据集进行去重,即可得到重复行的数据。
df.drop_duplicates(keep="first")\
.append(df.drop_duplicates(keep=False))\
.drop_duplicates(keep=False)
缺失值处理
查找缺失值
缺失值为 True ,非缺失值为 False 。
df.isnull()
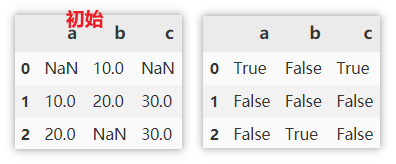
查找非缺失值
非缺失值为 True ,缺失值为 False 。
df.notnull()
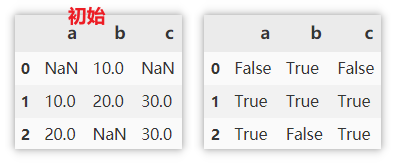
显示有缺失值的行
.isnull:查找缺失值,主要为了将缺失值的位置标 True。
.T:行列转置,为下一步 any 做准备。
.any:一个序列中满足一个 True,则返回 True。
df[df.isnull().T.any()]

删除缺失值
这里的参数需要注意的比较多,这里着重讲一下。
- axis:0 行,1 列
- how:
- any:如果有 NaN,删除该行或列。
- all:如果所有值都是 NaN,删除该行或列。
- thresh:指定 NaN 的数量,当 NaN 数量达到才删除。
- subset:要考虑的数据范围,如:删除缺失行,就用subset指定参考的列,默认是所有列。
- inplace:是否修改原数据。
# 某行如果有缺失值,则删除这一行
df.dropna(axis=0, how='any')
# 某列如果有缺失值,则删除这一列
df.dropna(axis=1, how='any')

填充缺失值
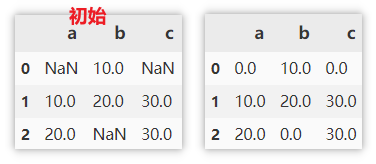
数字或字符串填充
直接指定要填充的数字或字符串。
df.fillna(0)
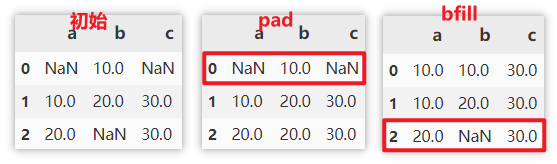
用缺失值 前/后 的值填充
- 用缺失值的前一个值(该列上面一个值)填充,如果缺失值在第一行则不填充
- 用缺失值的后一个值(该列下面一个值)填充,如果缺失值在最后一行则不填充
df.fillna(method='pad')
df.fillna(method='bfill')
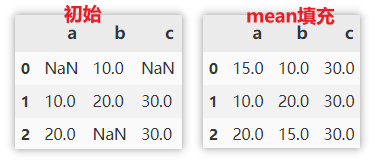
用缺失值所在列的 均值/中位数 等填充
可以用该列的统计信息来进行填充。如使用 mean、median、max、min、sum 填充等。
df.fillna(df.mean())
列操作
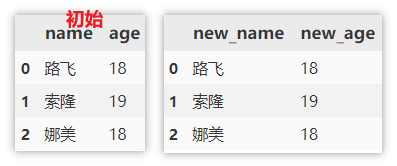
修改列名
df.columns 是直接指定新的列名来替换所有的列名。 (在原数据上进行修改)
rename() 需要指定原名与新名来进行替换。
df.columns = ['new\_name', 'new\_age']
df.rename(columns=({'name':'new\_name','age':'new\_age'}))
修改列类型
使用 astype 来修改列类型。
df['age'].astype(str)

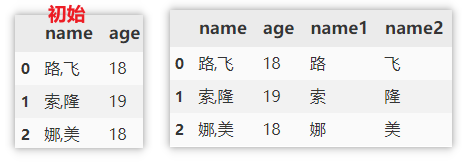
将列进行拆分得到多列
split 只能对字符串列进行拆分。
df[['name1', 'name2']] = df['name'].str.split(',', expand=True)
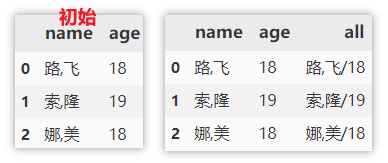
将多列合并成新列
同样合并也是字符串类型的列才能进行合并。
df['all'] = df['name'] + '/' + df['age'].astype(str)
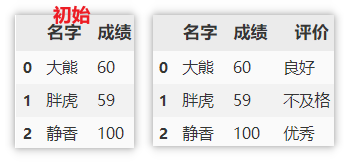
对数值列分区
对于数值列,实际使用的时候可能需要根据指定的范围,将这些数值变为标签值,如衡量产品的指标及格、不及格,成绩是否优秀等。使用是需要指定数值列、各个标签的临界值,临界值的开闭情况(示例中:默认 left=True ,指定 right=False ,即左闭右开),最后指定标签的名称即可。
df['评价'] = pd.cut(df['成绩'], [0, 60, 80, np.inf],
right=False, labels=['不及格', '良好', '优秀'])
排序
索引排序
对行索引降序排序
df.sort_index(axis=0, ascending=False)
对列索引降序排序
df.sort_index(axis=1, ascending=False)

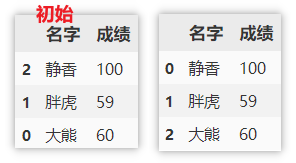
重置索引
将索引重新排序,原来的索引不保留。
df.reset_index(drop=True)
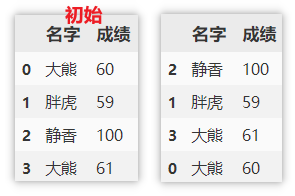
值排序
先按照名字降序排序,再对相同名字下的成绩进行降序排序。
df.sort_values(by=['名字', '成绩'], axis=0, ascending=False)
创建排名列
使用 rank 来进行排名,主要参数 method 的取值含义如下:
method | 含义 |
|---|---|
average | 默认值,在名次一样的分组中,为各个值分配平均排名(平均数),排名之间存在跳跃 |
min | 使用分组中的最小排名,排名之间存在跳跃 |
max | 使用分组中的最大排名,排名之间存在跳跃 |
first | 按值在原始数据中的出现顺序进行排名,排名之间存在跳跃 |
dense | 同一个分组的排名相同,排名之间不存在跳跃 |
现在按照 成绩 列对每行数据进行排名,并新建排名列,几种排名方式下面都已给出。
df['排名'] = df['成绩'].rank(method='average', ascending=False)

分组
对行分组统计
现在对各人的成绩进行分组计算,分别计算总和、均值、最大值。
df.groupby(['名字']).sum()
df.groupby(['名字']).mean()
df.groupby(['名字']).max()

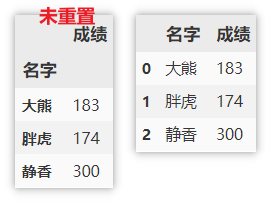
注意:此时的索引为 名字,如果想要重置索引,可以使用如下方式。
df.groupby(['名字']).sum().reset_index()
对不同列使用不同的统计函数
agg() 是指定函数使用在某个数列上,然后返回标量值。
apply() 是先将数据拆分 >>> 再应用 >>> 最后汇总的过程(只能应用单个函数)。返回多维的数据。
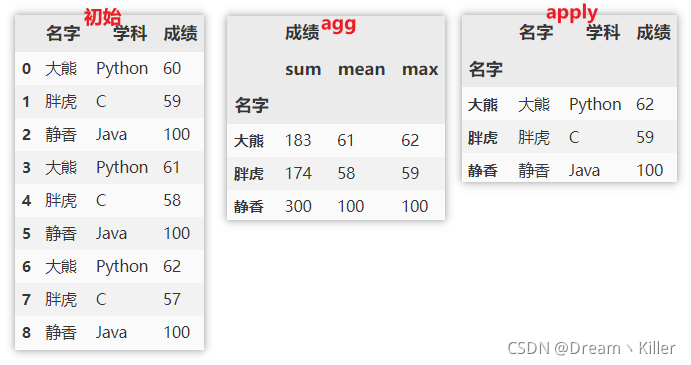
df.groupby(['名字']).agg({'成绩':['sum','mean','max']})
df.groupby(['名字']).apply(max)
DataFrame合并
pandas中的合并函数主要是:merge()、concat()、append(),一般用来连接两个及以上 DataFrame 。其中,concat(), append() 用来纵向连接 DataFrame 对象, merge() 用来横向连接 DataFrame 对象。
三者对比:
concat()
- 连接多个DataFrame
- 设置特定的键(key)
append()
- 连接多个DataFrame
merge()
- 指定列来连接DataFrame
merge()
on 若指定则该列必须同时出现在这两个 DataFrame 中,默认值为两个 DataFrame 列中的交集,在本例中即使不指定 on ,实际默认值也会按照 name 列来进行合并。
how 参数详解:
- inner:根据
on指定的列取交集。 - outer:根据
on指定的列取并集。 - left:根据
on指定的列并以左连接的方式合并。 - right:根据
on指定的列并以右连接的方式合并。
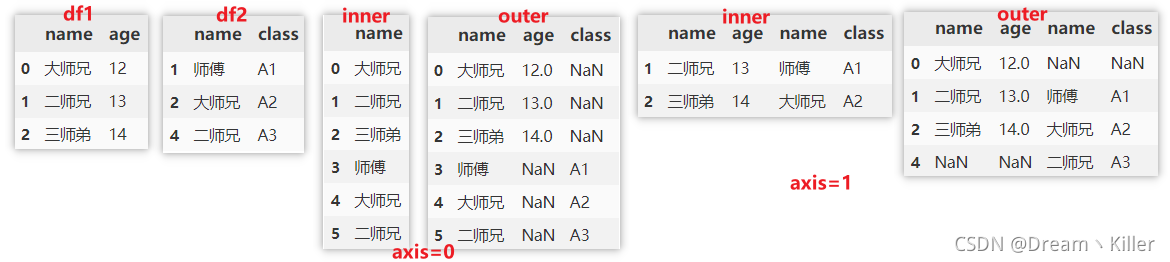
pd.merge(df1, df2, on='name', how = "inner")
pd.merge(df1, df2, on='name', how = "outer")
pd.merge(df1, df2, on='name', how = "left")
pd.merge(df1, df2, on='name', how = "right")

concat()
concat() 可以多个 DataFrame 进行合并,根据实际情况可以选择纵向合并还是横向合并。具体看下面的示例。
# 多个DataFrame纵向合并取交集
pd.concat([df1, df2], ignore_index=True, join='inner',axis=0)
# 多个DataFrame纵向合并取并集
pd.concat([df1, df2], ignore_index=True, join='outer',axis=0)
# 多个DataFrame横向合并取交集
pd.concat([df1, df2], ignore_index=False, join='inner',axis=1)
# 多个DataFrame横向合并取并集
pd.concat([df1, df2], ignore_index=False, join='outer',axis=1)
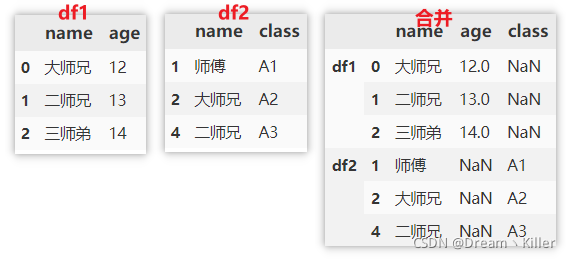
另外还可以指定 key ,在索引的位置添加原数据的名称。
pd.concat([df1, df2], ignore_index=False, join='outer', keys=['df1', 'df2'])
append()
append() 常用于纵向合并,也可以多个 DataFrame 进行合并。
df1.append(df2, ignore_index=True)
df1.append([df1, df2], ignore_index=True)

DataFrame时间处理
示例数据
将字符串列转化成时间序列
有时从 csv 或 xlsx 文件中读取的时间,是字符串(Object)类型,这时就需要将其转化成 datetime 类型,方便后续对时间的处理。
pd.to_datetime(df['datetime'])
将时间列作为索引
对于大部分时间序列数据,我们都可以将该列作为索引,来最大的利用时间。这里 drop=False 选择不删除 datetime 列。
df.set_index('datetime', drop=False)
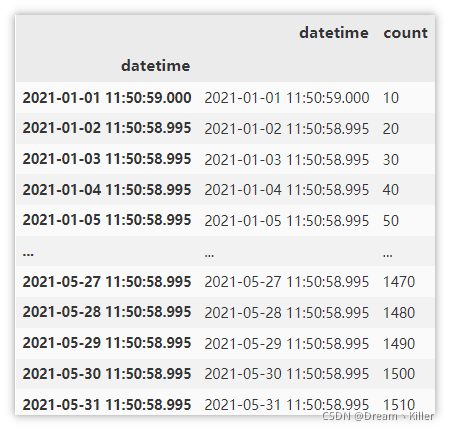
通过索引获取 1月 的数据,这里显示前五行。
df.loc['2021-1'].head()
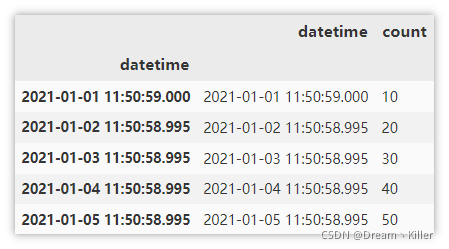
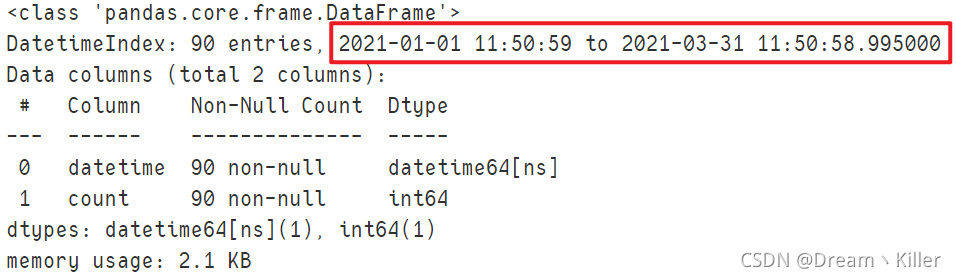
通过索引获取 1~3月 的数据。
df.loc['2021-1':'2021-3'].info()
获取时间的各个属性
如何自学黑客&网络安全
黑客零基础入门学习路线&规划
初级黑客
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:282G全网最全的网络安全资料包评论区留言即可领取!
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
如果你零基础入门,笔者建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习;搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime;·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完;·用Python编写漏洞的exp,然后写一个简单的网络爬虫;·PHP基本语法学习并书写一个简单的博客系统;熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选);·了解Bootstrap的布局或者CSS。
8、超级黑客
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,附上学习路线。

网络安全工程师企业级学习路线

如图片过大被平台压缩导致看不清的话,评论区点赞和评论区留言获取吧。我都会回复的
视频配套资料&国内外网安书籍、文档&工具
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

一些笔者自己买的、其他平台白嫖不到的视频教程。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 1817
1817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









