







 本文概述了机器学习中的几种关键算法,包括LDA的统计表示,决策树、朴素贝叶斯、K近邻、学习矢量量化、支持向量机、随机森林和Boosting/AdaBoost。这些技术在分类和预测建模中有广泛应用,尽管它们各有特点,如朴素贝叶斯的独立性假设和SVM的强大分离能力。
本文概述了机器学习中的几种关键算法,包括LDA的统计表示,决策树、朴素贝叶斯、K近邻、学习矢量量化、支持向量机、随机森林和Boosting/AdaBoost。这些技术在分类和预测建模中有广泛应用,尽管它们各有特点,如朴素贝叶斯的独立性假设和SVM的强大分离能力。
LDA的表示非常简单。它由你的数据的统计属性组成,根据每个类别进行计算。对于单个输入变量,这包括:
- 每类的平均值。
- 跨所有类别计算的方差。
LDA通过计算每个类的判别值并对具有最大值的类进行预测来进行。该技术假定数据具有高斯分布(钟形曲线),因此最好先手动从数据中移除异常值。这是分类预测建模问题中的一种简单而强大的方法。
04 分类和回归树
决策树是机器学习的一种重要算法。
决策树模型可用二叉树表示。对,就是来自算法和数据结构的二叉树,没什么特别。每个节点代表单个输入变量(x)和该变量上的左右孩子(假定变量是数字)。
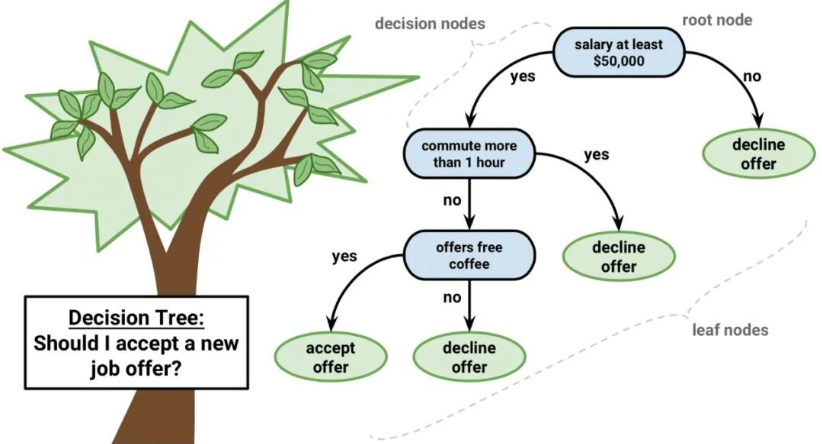
树的叶节点包含用于进行预测的输出变量(y)。预测是通过遍历树进行的,当达到某一叶节点时停止,并输出该叶节点的类值。
决策树学习速度快,预测速度快。对于许多问题也经常预测准确,并且你不需要为数据做任何特殊准备。
05 朴素贝叶斯
朴素贝叶斯是一种简单但极为强大的预测建模算法。
该模型由两种类型的概率组成,可以直接从你的训练数据中计算出来:1)每个类别的概率; 2)给定的每个x值的类别的条件概率。一旦计算出来,概率模型就可以用于使用贝叶斯定理对新数据进行预测。当你的数据是数值时,通常假设高斯分布(钟形曲线),以便可以轻松估计
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









