







给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
需要体系化学习资料的朋友,可以加我V获取:vip204888 (备注网络安全)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
-1. 上传和解压两个软件包
[root@master ~]# cd /opt/software/
[root@master software]# tar -zxvf jdk-8u221-linux-x64.tar.gz -C /opt/apps/
[root@master software]# tar -zxvf hadoop-2.7.6.tar.gz -C /opt/apps/
-2. 进入apps里,给两个软件更名
[root@master software]# cd /opt/apps/
[root@master apps]# mv jdk1.8.0_221/ jdk
[root@master apps]# mv hadoop-2.7.6/ hadoop
-3. 配置环境变量
[hadoop@master apps]# vi /etc/profile
.....省略...........
#java environment
export JAVA_HOME=/opt/apps/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
#hadoop environment
export HADOOP_HOME=/opt/apps/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
5 Hadoop的配置文件
5.1 提取四个默认配置文件
第一步:将hadoop安装包解压到pc端的一个目录下,然后在hadoop-2.7.6目录下创建一个default目录,用于存储默认配置文件。 第二步:进入hadoop的share目录中的doc子目录,搜索default.xml。将以下四个默认的xml文件copy到default目录中,方便以后查看
5.2 $HADOOP_HOME/etc/hadoop/目录下的用户自定义配置文件
- core-site.xml
- hdfs-site.xml
- mapred-site.xml 复制mapred-site.xml.template而来
- yarn-site.xml
5.3 属性的优先级
代码中的属性>xxx-site.xml>xxx-default.xml
6 完全分布式文件配置(重点)
配置前说明:我们先在master机器节点上配置hadoop的相关属性。
6.1 配置core-site.xml文件
[root@master ~]# cd $HADOOP_HOME/etc/hadoop/
[root@master hadoop]# vi core-site.xml
<configuration>
<!-- hdfs的地址名称:schame,ip,port-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/apps/hadoop/tmp</value>
</property>
</configuration>
参考:core-default.xml
6.2 再配置hdfs-site.xml文件
[root@master hadoop]# vi core-site.xml
<configuration>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<!-- 块的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 块的大小-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:50090</value>
</property>
</configuration>
参考:hdfs-default.xml
6.3 然后配置mapred-site.xml文件
如果只是搭建hdfs,只需要配置core-site.xml和hdfs-site.xml文件就可以了,但是我们过两天要学习的MapReduce是需要YARN资源管理器的,因此,在这里,我们提前配置一下相关文件。
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml
<configuration>
<!-- 指定mapreduce使用yarn资源管理器-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置作业历史服务器的地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 配置作业历史服务器的http地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
参考:mapred-default.xml
6.4 配置yarn-site.xml文件
[root@master hadoop]# vi yarn-site.xml
<configuration>
<!-- 指定yarn的shuffle技术-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager的主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
参考:yarn-default.xml
6.5 配置hadoop-env.sh脚本文件
[root@master hadoop]# vi hadoop-env.sh
.........
# The java implementation to use.
export JAVA_HOME=/opt/apps/jdk
.........
6.6 配置slaves文件,此文件用于指定datanode守护进程所在的机器节点主机名
[root@master hadoop]# vi slaves
master
slave1
slave2
6.7 配置yarn-env.sh文件,此文件可以不配置,不过,最好还是修改一下yarn的jdk环境比较好
[root@master hadoop]# vi yarn-env.sh
........省略........
# some Java parameters
export JAVA_HOME=/opt/apps/jdk
........省略........
7 另外两台机器配置说明
当把master机器上的hadoop的相关文件配置完毕后,我们有以下两种方式来选择配置另外几台机器的hadoop.
方法1:“scp”进行同步
提示:本方法适用于多台虚拟机已经提前搭建出来的场景。
--1. 同步hadoop到slave节点上
[root@master ~]# cd /opt/apps
[root@master apps]# scp -r ./hadoop slave1:/opt/apps/
[root@master apps]# scp -r ./hadoop slave2:/opt/apps/
--2. 同步/etc/profile到slave节点上
[root@master apps]# scp /etc/profile slave1:/etc/
[root@master apps]# scp /etc/profile slave2:/etc/
--3. 如果slave节点上的jdk也没有安装,别忘记同步jdk。
--4. 检查是否同步了/etc/hosts文件
**方法2:**克隆master虚拟机
提示:本方法适用于还没有安装slave虚拟机的场景。通过克隆master节点的方式,来克隆一个slave1和slave2机器节点,这种方式就不用重复安装环境和配置文件了,效率非常高,节省了大部分时间(免密认证的秘钥对都是相同的一套)。
--1. 打开一个新克隆出来的虚拟机,修改主机名
[root@master ~]# hostnamectl set-hostname slave1
--2. 修改ip地址
[root@master ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
.........省略.........
IPADDR=192.168.10.201 <==修改为slave1对应的ip地址
.........省略........
--3. 重启网络服务
[root@master ~]# systemctl restart network
--4. 其他新克隆的虚拟机重复以上1~3步
--5. 免密登陆的验证
从master机器上,连接其他的每一个节点,验证免密是否好使,同时去掉第一次的询问步骤
--6. 建议:每台机器在重启网络服务后,最好reboot一下。
8 格式化NameNode
**1)**在master机器上运行命令
[root@master ~]# hdfs namenode -format
注意,注意,注意: 如果你是从伪分布式过来的,最好先把伪分布式的相关守护进程关闭:stop-all.sh
**2)**格式化的相关信息解读
--1. 生成一个集群唯一标识符:clusterid
--2. 生成一个块池唯一标识符:BlockPoolId
--3. 生成namenode进程管理内容(fsimage)的存储路径:
默认配置文件属性hadoop.tmp.dir指定的路径下生成dfs/name目录
--4. 生成镜像文件fsimage,记录分布式文件系统根路径的元数据
--5. 其他信息都可以查看一下,比如块的副本数,集群的fsOwner等。
参考图片:
**3)**目录里的内容查看
9 启动集群
9.1 启动脚本和关闭脚本介绍
1. 启动脚本
-- start-dfs.sh :用于启动hdfs集群的脚本
-- start-yarn.sh :用于启动yarn守护进程
-- start-all.sh :用于启动hdfs和yarn
2. 关闭脚本
-- stop-dfs.sh :用于关闭hdfs集群的脚本
-- stop-yarn.sh :用于关闭yarn守护进程
-- stop-all.sh :用于关闭hdfs和yarn
3. 单个守护进程脚本
-- hadoop-daemons.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
-- hadoop-daemon.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
reg:
hadoop-daemon.sh [start|stop] [namenode|datanode|secondarynamenode]
-- yarn-daemons.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
-- yarn-daemon.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
reg:
yarn-daemon.sh [start|stop] [resourcemanager|nodemanager]
9.2 启动hdfs
**1)**使用start-dfs.sh,启动 hdfs。参考图片
**2)**启动过程解析:
- 启动集群中的各个机器节点上的分布式文件系统的守护进程
一个namenode和resourcemanager以及secondarynamenode
多个datanode和nodemanager
- 在namenode守护进程管理内容的目录下生成edit日志文件
- 在每个datanode所在节点下生成${hadoop.tmp.dir}/dfs/data目录,参考下图:
注意,注意,注意
如果哪台机器的相关守护进程没有开启,那么,就查看哪台机器上的守护进程对应的日志log文件,注意,启动脚本运行时提醒的日志后缀是*.out,而我们查看的是*.log文件。此文件的位置:${HADOOP_HOME}/logs/里
**3)**jps查看进程
--1. 在master上运行jps指令,会有如下进程
namenode
datanode
--2. 在slave1上运行jps指令,会有如下进程
secondarynamenode
datanode
--3. 在slave2上运行jps指令,会有如下进程
datanode
9.3 启动yarn
**1)**使用start-yarn.sh脚本,参考图片
**2)**jps查看
--1. 在master上运行jps指令,会多出有如下进程
resoucemanager
nodemanager
--2. 在slave1上运行jps指令,会多出有如下进程
nodemanager
--3. 在slave2上运行jps指令,会多出有如下进程
nodemanager
9.4 webui查看
1. http://192.168.10.200:50070
2. http://192.168.10.200:8088
10 程序案例演示:wordcount
1) 准备要统计的两个文件,存储到~/data/下
--1. 创建data目录
[root@master hadoop]# mkdir ~/data
--2. 将以下两个文件上传到data目录下
- poetry1.txt
- poetry2.txt
2) 在hdfs上创建存储目录
[root@master hadoop]# hdfs dfs -mkdir /input
3) 将本地文件系统上的上传到hdfs上,并在web上查看一下
[root@master hadoop]$ hdfs dfs -put ~/data/poetry* /input/
4) 运行自带的单词统计程序wordcount
[root@master hadoop]# cd $HADOOP_HOME
[root@master hadoop]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /input /out
效果如下:
5) 查看webui
6) 查看part-r-00000文件
[root@master hadoop]# hdfs dfs -cat /out/part-r-00000
11 集群守护进程不能开启的情况
1. 格式化集群时,报错原因
- 当前用户使用不当
- /etc/hosts里的映射关系填写错误
- 免密登录认证异常
- jdk环境变量配置错误
- 防火墙没有关闭
2. namenode进程没有启动的原因:
还有兄弟不知道网络安全面试可以提前刷题吗?费时一周整理的160+网络安全面试题,金九银十,做网络安全面试里的显眼包!
王岚嵚工程师面试题(附答案),只能帮兄弟们到这儿了!如果你能答对70%,找一个安全工作,问题不大。
对于有1-3年工作经验,想要跳槽的朋友来说,也是很好的温习资料!
【完整版领取方式在文末!!】
***93道网络安全面试题***
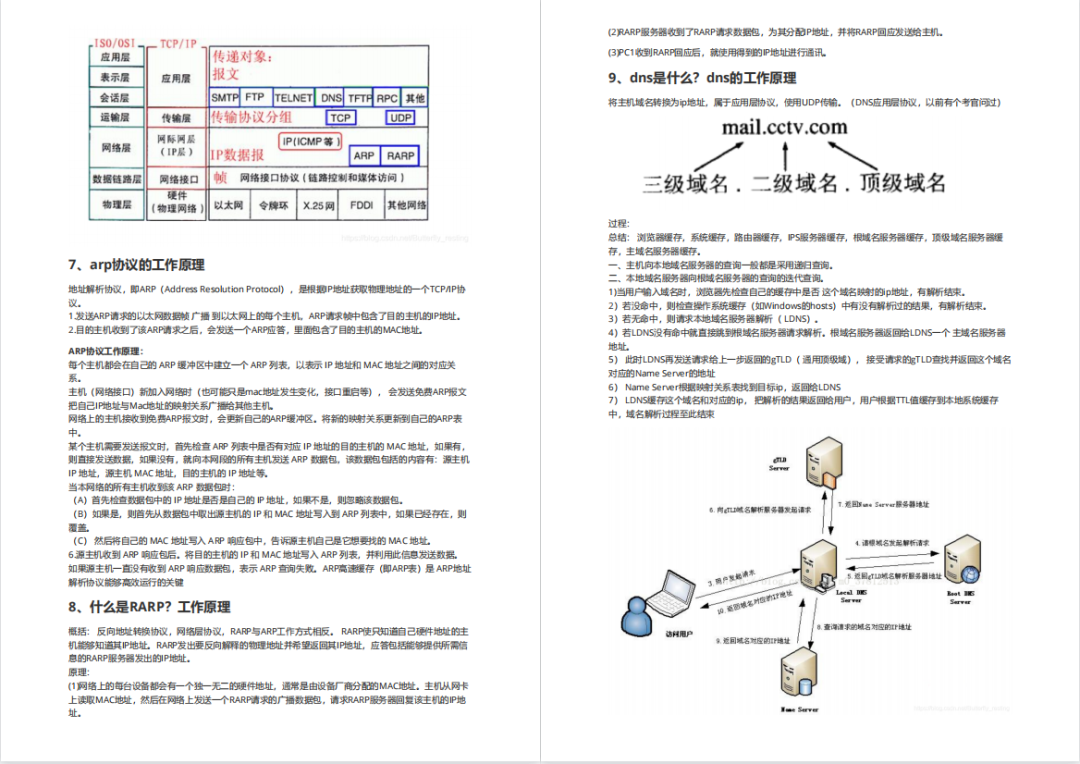


**需要体系化学习资料的朋友,可以加我V获取:vip204888 (备注网络安全)**
内容实在太多,不一一截图了
### 黑客学习资源推荐
最后给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
😝朋友们如果有需要的话,可以联系领取~
#### 1️⃣零基础入门
##### ① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的**学习成长路线图**。可以说是**最科学最系统的学习路线**,大家跟着这个大的方向学习准没问题。
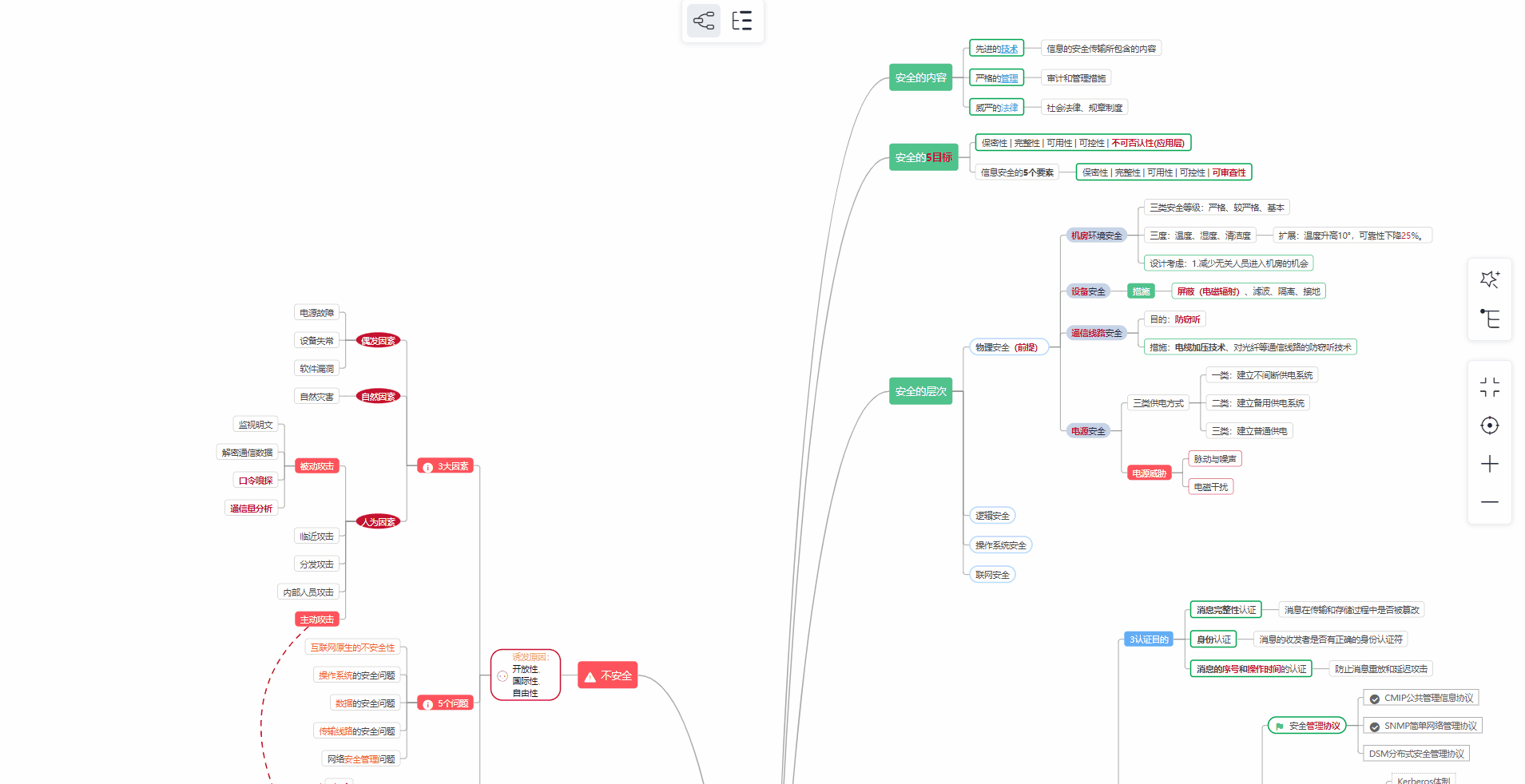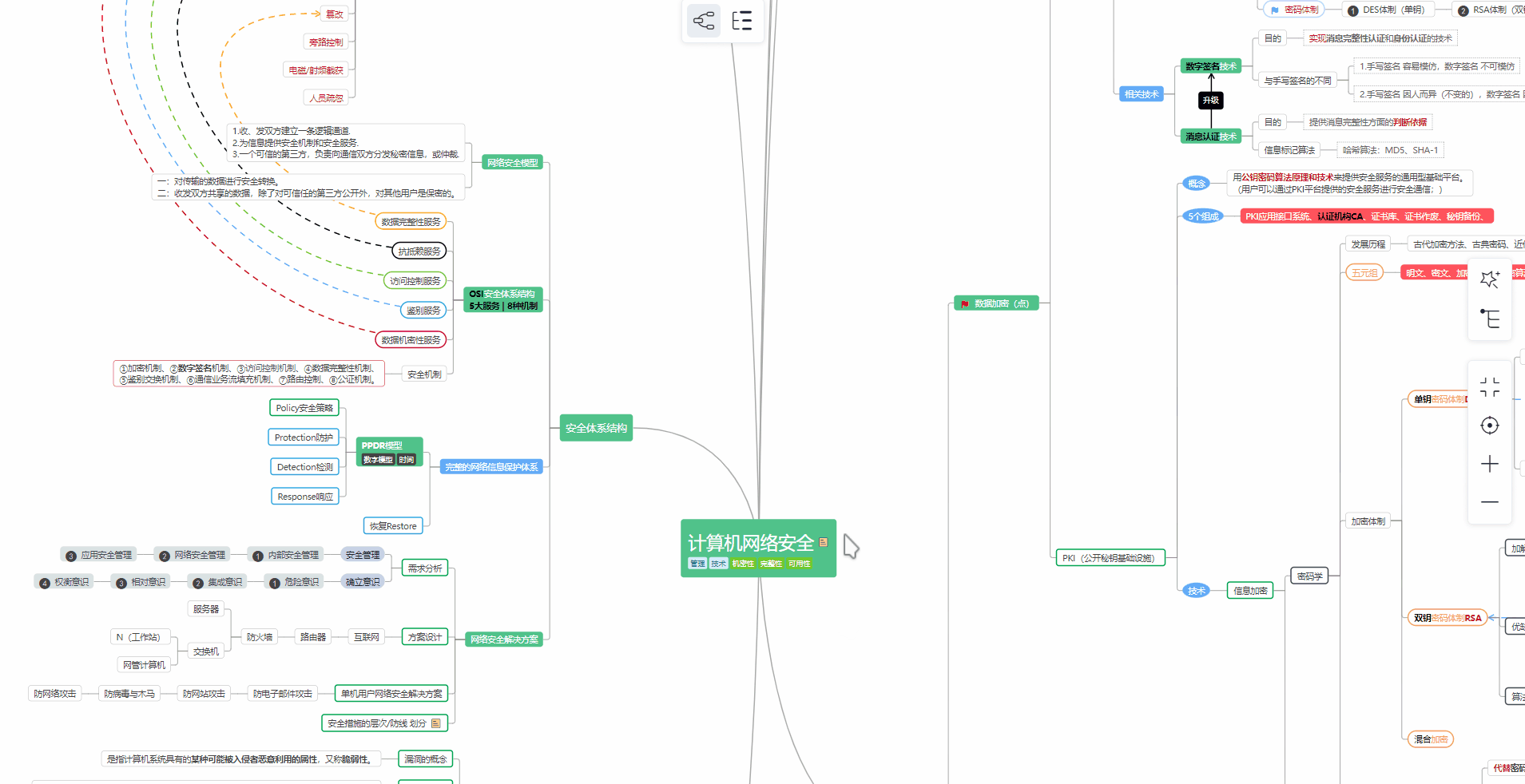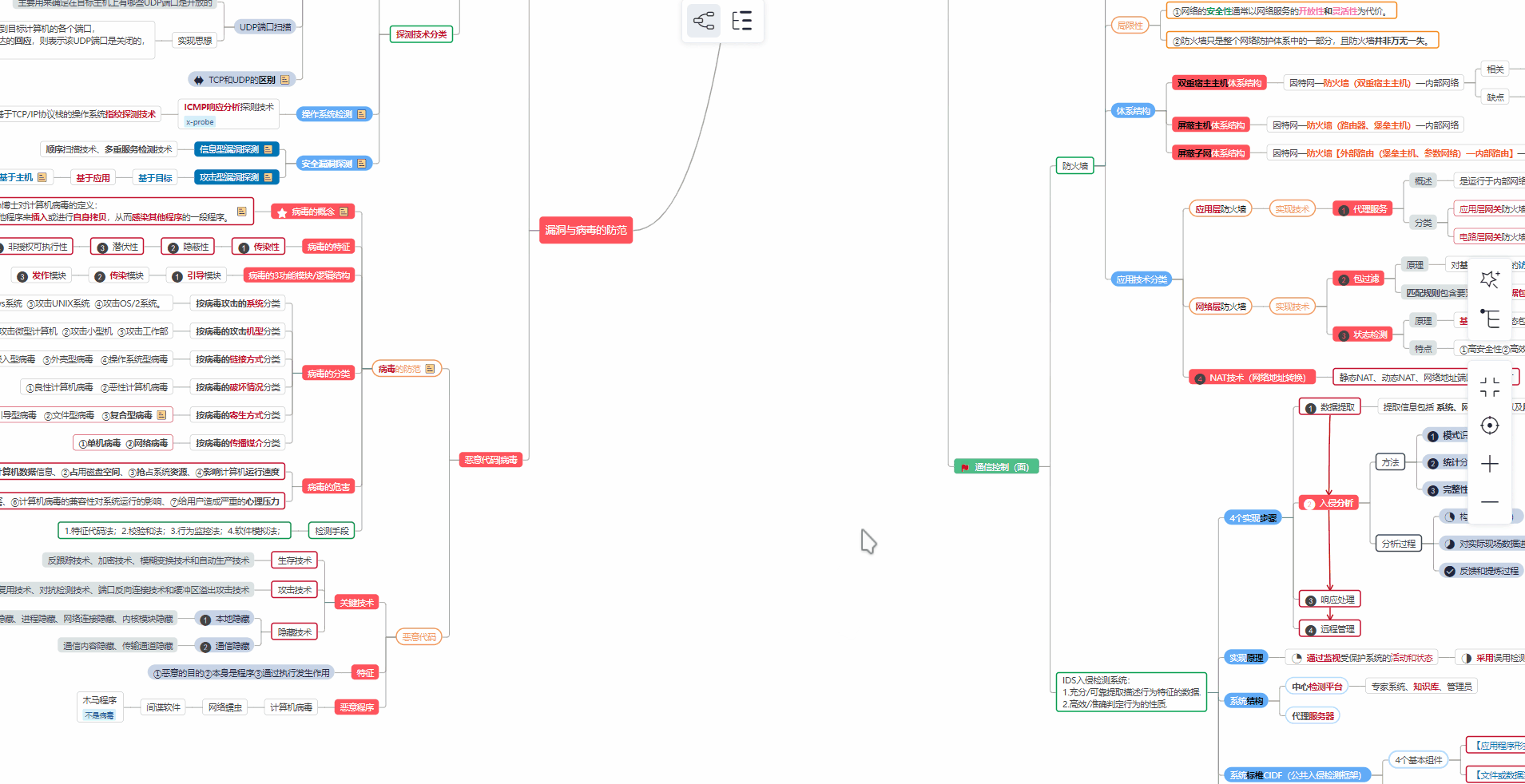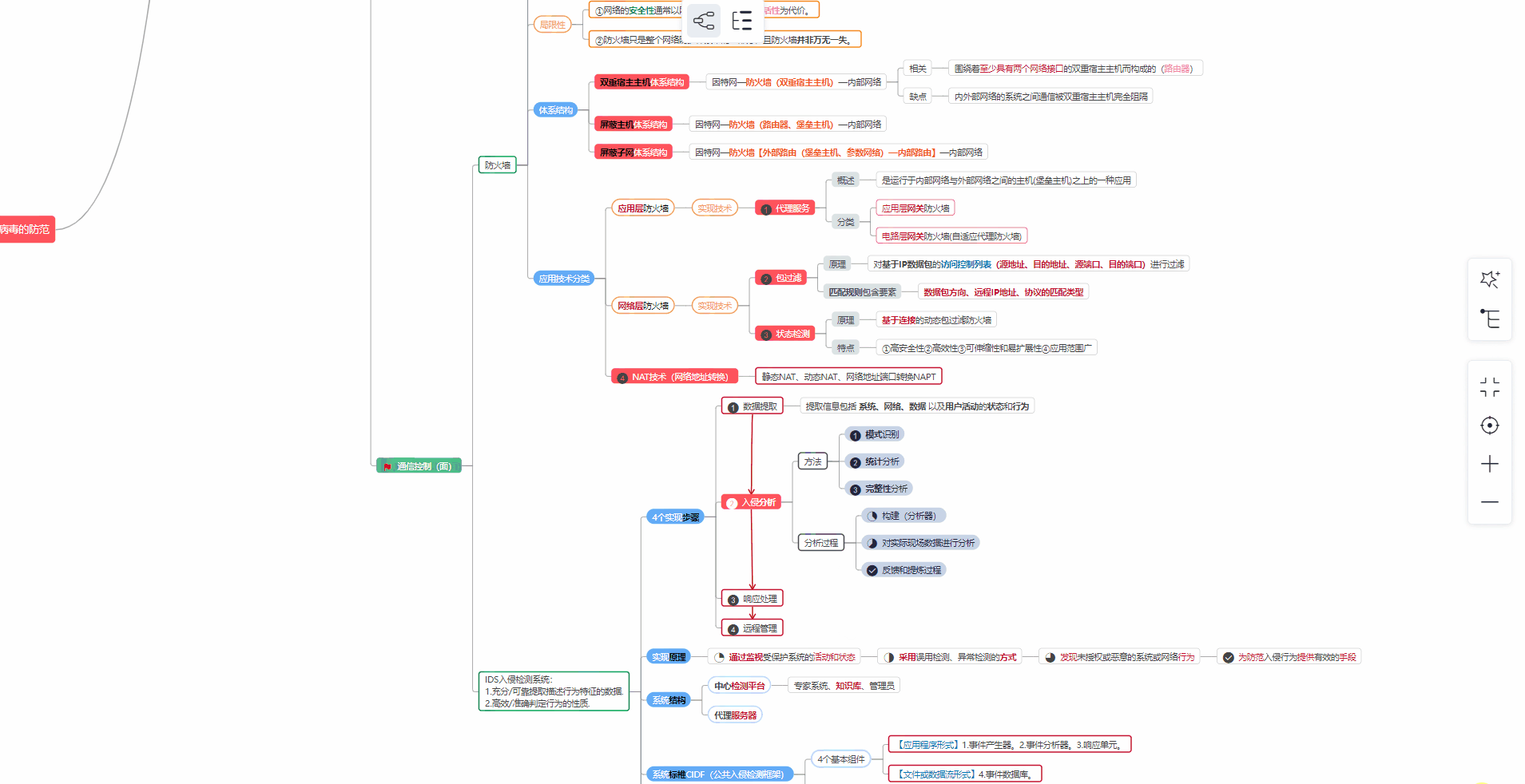
##### ② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:

#### 2️⃣视频配套工具&国内外网安书籍、文档
##### ① 工具

##### ② 视频
##### ③ 书籍
资源较为敏感,未展示全面,需要的最下面获取
##### ② 简历模板
**因篇幅有限,资料较为敏感仅展示部分资料,添加上方即可获取👆**
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/topics/618540462)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









