






大家好,我是程序员寒山。
在传统RAG系统中,每个查询都被视为独立事件。但在实际应用场景中,用户提问往往具有连续性特征。
我们在搭建RAG本地知识库的时候也发现,RAG没有记忆能力,没法多轮问答,每次都要输入完整的问题,才能够检索出合适的内容来。
其实不只是知识库,大模型也是没有记忆能力的,如果大家直接使用api调用模型就是发现这个问题,那么很多人会问我们平时使用的大模型问答是有记忆能力的啊?

那是因为我们使用的工具在大模型上层加了一层的问答历史记录,在多轮问答的时候,会从历史问答中提取内容,作为上下文和新的问题一起送给大模型,这大模型的回答就具备了多轮对话能力。
那么RAG怎么实现呢?
下面是我们今天的主要内容:
- RAG为什么需要记忆
- 如何实现RAG的记忆
- 怎么对问题分词和主体追踪
- 问题意图理解,问题重构
- Python实现记忆
- Dify演示如何实现RAG多轮问答
一、为什么RAG需要记忆?
在烹饪相关的问答场景中,用户通常会进行多轮对话,但传统RAG系统缺乏对上下文的持续追踪能力。例如:
- 第一轮提问:“如何做麻婆豆腐?” → 系统回答:“需要豆腐、牛肉末、豆瓣酱…步骤1…步骤2…”
- 第二轮提问:“可以用鸡肉代替牛肉吗?” → 系统可能错误地返回“宫保鸡丁的鸡肉处理方法”(上下文丢失)
问题根源:
- 实体漂移:未跟踪核心实体(如“麻婆豆腐”)
- 属性失联:未关联菜谱的食材、步骤、替代方案等结构化信息
- 短期记忆缺失:无法继承前序对话的上下文
二、如何实现RAG的记忆
核心架构
用户提问
│
▼
实体识别(NER) → 更新当前实体焦点
│
▼
结构化记忆查询 → 存在? → 返回属性值
│ 否
▼
问题意图分析 → 存在? → 返回属性值
│ 否
▼
问题重构 → 生成新问题
│
▼
原始RAG检索 → 生成答案
│
▼
上下文更新与确认
三、中文分词技术实现与选型
3.1 主流分词工具对比
jieba 介绍
jieba 是一个 Python 实现的中文分词工具,具有简单易用、功能丰富等特点,开源且免费使用,
支持精确模式、全模式、搜索引擎模式等多种分词模式,可以实现基本的中文分词、词性标注、关键词提取等功能,还支持自定义词典,方便用户根据特定领域或需求进行个性化分词。
HanLP 介绍
HanLP 是由一系列模型与算法组成的 NLP 工具包,支持 Java、Python 等多种编程语言,涵盖了中文分词、词性标注、命名实体识别、依存句法分析、文本分类等多个自然语言处理任务。
两者对比
HanLP 的功能更为全面,除了基本的分词功能外,还涵盖了命名实体识别、依存句法分析等多种高级 NLP 任务;而 jieba 主要侧重于中文分词及相关的基础功能,如关键词提取等。
jieba 的运行速度较快,占用资源相对较少,适合处理大规模文本数据的分词任务;HanLP 由于功能复杂,涉及多种模型计算,尤其是在处理大规模数据时,运行时间可能会更长。
3.2 菜谱场景分词优化
创建领域词典(recipe_lexicon.txt):
麻婆豆腐 3 n
宫保鸡丁 3 n
郫县豆瓣酱 4 n
焯水 2 v
炝锅 2 v
代码实现:
import jieba
jieba.load_userdict("recipe_lexicon.txt")
def recipe_segment(text):
words = jieba.lcut(text, use_paddle=True)
return [(w, flag) for w, flag in posseg.lcut(text)]
3.3 实体追踪算法
class EntityTracker:
def __init__(self, max_memory=3):
self.history = deque(maxlen=max_memory)
self.current_focus = None
def update(self, entities):
weights = {}
for ent in entities:
weights[ent] = weights.get(ent, 0) + 1
if ent in self.history:
weights[ent] *= 1.5
self.current_focus = max(weights, key=weights.get, default=None)
self.history.append(self.current_focus)
三、问题意图理解技术实现
问题意图理解是指分析用户输入问题的目的和需求,确定其背后所表达的真实意图。在多轮问答场景中,准确理解问题意图至关重要,它能帮助模型更好地把握用户需求,提供更准确、更相关的回答,使对话更加流畅和自然。
预训练模型的强大表征能力:transformers 架构的预训练模型,如 BERT、GPT 等,在大规模语料上进行预训练,学习到了丰富的语言知识和语义信息,能够很好地捕捉问题中的语义特征和意图线索。
灵活的微调机制:可以基于预训练模型,通过在特定的问题意图理解数据集上进行微调,使模型适应具体的任务和领域,从而提高意图理解的准确性。
四、问题重构与记忆管理
4.1 上下文感知的问题重构算法
def reconstruct_question(self, current_question):
if not current_question or not isinstance(current_question, str):
raise ValueError("问题不能为空且必须是字符串")
if not self.context:
current_tokens = self.track_question(current_question)
self.original_subject = self.get_subject(current_tokens)
self.context.append(current_question)
return current_question
current_tokens = self.track_question(current_question)
current_subject = self.get_subject(current_tokens)
last_reconstructed_question = self.context[-1]
4.2 记忆存储结构设计
class MultiRoundQuestionMemory:
def __init__(self, memory_rounds=3):
self.memory_rounds = memory_rounds
self.context = []
self.original_subject = None
def reset_memory(self):
self.context = []
self.original_subject = None
def set_memory_rounds(self, rounds):
self.memory_rounds = rounds
def track_question(self, question):
return jieba.lcut(question)
五、记忆功能给Dify提供接口
由于代码比较复杂和第三方库的原因,代码不能直接在dify运行,需要提供http的接口供Dify调用。
@app.route('/reconstruct', methods=['POST'])
def reconstruct():
data = request.get_json()
if not data or 'question' not in data:
return jsonify({'error': 'Invalid request, question is required'}), 400
question = data['question']
try:
reconstructed = memory.reconstruct_question(question)
return jsonify({
'original_question': question,
'reconstructed_question': reconstructed
})
except ValueError as e:
return jsonify({'error': str(e)}), 400
@app.route('/reset', methods=['POST'])
def reset():
memory.reset_memory()
return jsonify({'status': 'memory reset successfully'})
六、Dify工作流集成
通过Http请求实现多轮问答的功能,后面的流程就和我们之前讲的类似了。
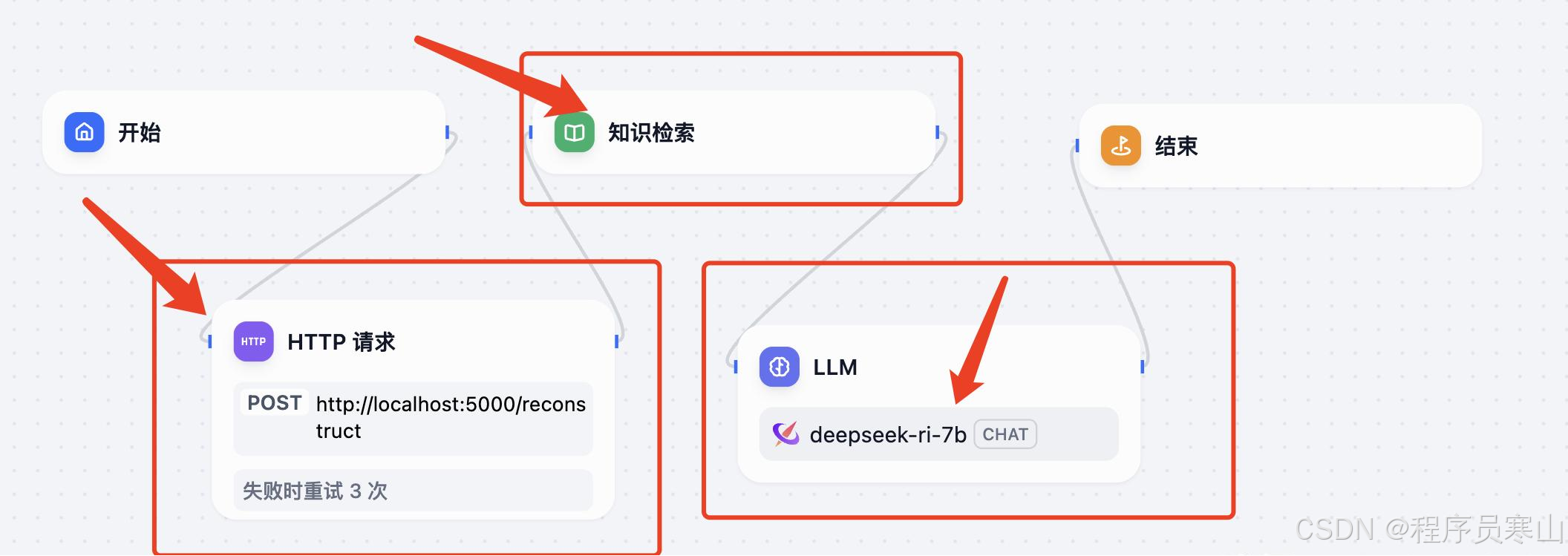
结语
本文通过菜谱问答场景,详细阐述了如何给RAG增加多轮问答的记忆功能。
在加入记忆模块后,系统在测试集上的准确率会有一个明显的提升。大家可以通过文中原型系统来提升自己的私有RAG的能力。
有问题欢迎留言,只有看到都会给大家回复的,有想深入了解的问题也请评论留言。

















 515
515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









