






贝叶斯分类器是一类基于贝叶斯定理的概率分类模型,其核心思想是通过先验概率和样本数据计算后验概率,从而对未知数据进行分类。
1. 基本概念
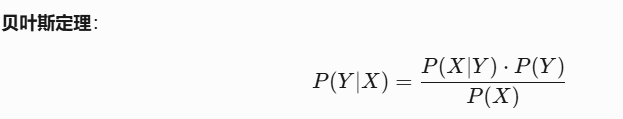
其中:
Y:类别标签(如垃圾邮件/非垃圾邮件)。X:特征向量(如文本中的单词)。P(Y∣X):给定特征 X 时类别 Y 的后验概率。P(X∣Y):似然(类别 Y 下特征 X 的条件概率)。P(Y):类别的先验概率朴素”假设:所有特征在给定类别下条件独立,即:
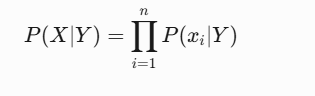
2. 算法步骤
(1) 数据准备
输入:带标签的训练数据,特征 X=(x1,x2,...,xn),类别 Y。特征处理:离散特征:直接统计概率(如单词出现次数)。连续特征:假设服从高斯分布,计算均值和方差(高斯朴素贝叶斯)。
(2) 计算先验概率 P(Y)
统计每个类别在训练集中的比例:P(Y=yk)=总样本数类别 yk 的样本数
(3) 计算似然 P(xi∣Y)

(4) 预测新样本

训练过程
- 计算先验概率:统计训练集中每个类别的频率。P(Y=yi)=总样本数类别 yi 的样本数
- 估计似然:
- 对离散特征:计算类别下特征值的条件概率。
- 对连续特征:拟合概率分布(如高斯分布的均值和方差)
数学示例
假设预测天气(Y∈{晴,雨})基于两个特征:温度(高/低)和湿度(高/低)。
训练数据统计如下:
先验概率:P(晴)=0.6,P(雨)=0.4。条件概率P(温度=高∣晴)=0.8,P(湿度=高∣晴)=0.1。P(温度=高∣雨)=0.3,P(湿度=高∣雨)=0.9。
对新样本 X=(温度=高,湿度=高):
P(晴∣X)∝0.6×0.8×0.1=0.048P(雨∣X)∝0.4×0.3×0.9=0.108
预测结果为 雨(后验概率更高)
案例分析:
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.460 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.774 | 0.376 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.634 | 0.264 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.608 | 0.318 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.556 | 0.215 | 是 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.403 | 0.237 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 0.481 | 0.149 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 0.437 | 0.211 | 是 |
| 9 | 乌黑 | 稍老 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.666 | 0.091 | 否 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 0.243 | 0.267 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 0.245 | 0.057 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 0.343 | 0.099 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 0.639 | 0.161 | 否 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 0.657 | 0.198 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.360 | 0.370 | 否 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 0.593 | 0.042 | 否 |
| 17 | 青绿 | 硬挺 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.719 | 0.103 | 否 |
首先,计算类别的先验概率。好瓜是8/17 =0.471 坏瓜是 9/18=0.529
对于离散特征(如色泽、根蒂、敲声等),计算在类别 YY 下特征 XX 取某个值 xx 的条件概率:
P(X=x∣Y=yi)=类别 yi 中特征 X 取值为 x 的样本数类别 yi 的总样本数P(X=x∣Y=yi)=类别 yi 的总样本数类别 yi 中特征 X 取值为 x 的样本数
以 色泽 为例:
色泽取值:青绿、乌黑、浅白
P(色泽=青绿∣Y=是)=83=0.375P(色泽=乌黑∣Y=是)=48=0.5P(色泽=乌黑∣Y=是)=84=0.5P(色泽=浅白∣Y=是)=18=0.125P(色泽=浅白∣Y=是)=81=0.125
P(色泽=青绿∣Y=否)=93≈0.333P(色泽=乌黑∣Y=否)=29≈0.222P(色泽=乌黑∣Y=否)=92≈0.222P(色泽=浅白∣Y=否)=49≈0.444P(色泽=浅白∣Y=否)=94≈0.444
密度(密度)
在“好瓜”(是)中:
密度值:0.697, 0.774, 0.634, 0.608, 0.556, 0.403, 0.481, 0.437
μ密度=≈0.574
σ密度2=≈0.016
在“非好瓜”(否)中:μ密度≈0.496σ密度2≈0.033σ密度2≈0.033
在“好瓜”(是)中:
含糖率:0.460, 0.376, 0.264, 0.318, 0.215, 0.237, 0.149, 0.211
计算:
μ含糖率≈0.279μ含糖率≈0.279σ含糖率2≈0.008σ含糖率2≈0.008
在“非好瓜”(否)中:
含糖率:0.091, 0.267, 0.057, 0.099, 0.161, 0.198, 0.370, 0.042, 0.103
计算:
μ含糖率≈0.154μ含糖率≈0.154σ含糖率2≈0.009σ含糖率2≈0.009
| 特征 | 特征值 | 好瓜=是 (计数/总数) | 好瓜=否 (计数/总数) |
|---|---|---|---|
| 色泽 | 青绿 | 3/8 | 3/9 |
| 乌黑 | 3/8 | 4/9 | |
| 浅白 | 2/8 | 2/9 | |
| 根蒂 | 蜷缩 | 5/8 | 2/9 |
| 稍蜷 | 3/8 | 5/9 | |
| 稍老 | 0/8 | 2/9 | |
| 敲声 | 浊响 | 6/8 | 5/9 |
| 沉闷 | 2/8 | 3/9 | |
| 清脆 | 0/8 | 1/9 | |
| 纹理 | 清晰 | 6/8 | 2/9 |
| 稍糊 | 2/8 | 6/9 | |
| 模糊 | 0/8 | 1/9 | |
| 脐部 | 凹陷 | 5/8 | 2/9 |
| 稍凹 | 3/8 | 5/9 | |
| 平坦 | 0/8 | 2/9 | |
| 触感 | 硬滑 | 5/8 | 5/9 |
| 软粘 | 3/8 | 4/9 |

样本1的预测结果: 是 准确率: 82.35%
import numpy as np
import pandas as pd
from collections import defaultdict
class NaiveBayesClassifier:
def __init__(self):
self.class_probs = {}
self.feature_probs = {}
self.discrete_features = [] # 存储离散特征名
self.continuous_features = [] # 存储连续特征名
def fit(self, X, y):
# 自动识别特征类型
self.discrete_features = [col for col in X.columns if X[col].dtype == 'object']
self.continuous_features = [col for col in X.columns if X[col].dtype != 'object']
# 计算类别的先验概率
classes, counts = np.unique(y, return_counts=True)
total_samples = len(y)
self.class_probs = {c: (count + 1) / (total_samples + len(classes)) for c, count in
zip(classes, counts)} # 拉普拉斯平滑
# 对每个类别计算特征的条件概率
for c in self.class_probs:
class_samples = X[y == c]
feature_prob = {}
# 处理离散特征
for feature in self.discrete_features:
value_counts = class_samples[feature].value_counts()
# 拉普拉斯平滑
prob_dict = {val: (count + 1) / (len(class_samples) + len(value_counts))
for val, count in value_counts.items()}
feature_prob[feature] = prob_dict
# 处理连续特征
for feature in self.continuous_features:
mean = class_samples[feature].mean()
std = class_samples[feature].std()
# 防止标准差为0
if std < 1e-6:
std = 1e-6
feature_prob[feature] = {'mean': mean, 'std': std}
self.feature_probs[c] = feature_prob
def _calculate_likelihood(self, feature, value, class_label):
# 离散特征
if feature in self.discrete_features:
prob_dict = self.feature_probs[class_label].get(feature, {})
# 如果值未见过,使用最小概率
return prob_dict.get(value, 1 / (len(prob_dict) + 1)) if prob_dict else 1e-6
# 连续特征
else:
params = self.feature_probs[class_label].get(feature, {'mean': 0, 'std': 1})
mean = params['mean']
std = params['std']
if std < 1e-6:
std = 1e-6
exponent = np.exp(-0.5 * ((value - mean) / std) ** 2)
return (1.0 / (np.sqrt(2 * np.pi) * std)) * exponent
def predict(self, X):
predictions = []
for _, sample in X.iterrows():
max_prob = -np.inf
best_class = None
for class_label in self.class_probs:
# 使用对数概率防止下溢
prob = np.log(self.class_probs[class_label])
for feature in X.columns:
value = sample[feature]
likelihood = self._calculate_likelihood(feature, value, class_label)
prob += np.log(likelihood + 1e-10) # 防止log(0)
if prob > max_prob:
max_prob = prob
best_class = class_label
predictions.append(best_class)
return predictions
def evaluate(self, X, y):
predictions = self.predict(X)
accuracy = np.mean(np.array(predictions) == np.array(y))
return accuracy
# 准备数据
data = {
'编号': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17],
'色泽': ['青绿', '乌黑', '乌黑', '青绿', '浅白', '青绿', '乌黑', '乌黑', '乌黑', '青绿', '浅白', '浅白', '青绿', '浅白', '乌黑', '浅白', '青绿'],
'根蒂': ['蜷缩', '蜷缩', '蜷缩', '蜷缩', '蜷缩', '稍蜷', '稍蜷', '稍蜷', '稍老', '硬挺', '硬挺', '蜷缩', '稍蜷', '稍蜷', '稍蜷', '蜷缩', '硬挺'],
'敲声': ['浊响', '沉闷', '浊响', '沉闷', '浊响', '浊响', '浊响', '浊响', '沉闷', '清脆', '清脆', '浊响', '浊响', '沉闷', '浊响', '浊响', '沉闷'],
'纹理': ['清晰', '清晰', '清晰', '清晰', '清晰', '清晰', '稍糊', '清晰', '稍糊', '清晰', '模糊', '模糊', '稍糊', '稍糊', '清晰', '模糊', '稍糊'],
'脐部': ['凹陷', '凹陷', '凹陷', '凹陷', '凹陷', '稍凹', '稍凹', '稍凹', '稍凹', '平坦', '平坦', '平坦', '凹陷', '凹陷', '稍凹', '平坦', '稍凹'],
'触感': ['硬滑', '硬滑', '硬滑', '硬滑', '硬滑', '软粘', '软粘', '硬滑', '硬滑', '软粘', '硬滑', '软粘', '硬滑', '硬滑', '软粘', '硬滑', '硬滑'],
'密度': [0.697, 0.774, 0.634, 0.608, 0.556, 0.403, 0.481, 0.437, 0.666, 0.243, 0.245, 0.343, 0.639, 0.657, 0.360,
0.593, 0.719],
'含糖率': [0.460, 0.376, 0.264, 0.318, 0.215, 0.237, 0.149, 0.211, 0.091, 0.267, 0.057, 0.099, 0.161, 0.198, 0.370,
0.042, 0.103],
'好瓜': ['是', '是', '是', '是', '是', '是', '是', '是', '否', '否', '否', '否', '否', '否', '否', '否', '否']
}
df = pd.DataFrame(data)
# 准备特征和目标变量
features = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率']
X = df[features]
y = df['好瓜']
# 创建并训练分类器
nb_classifier = NaiveBayesClassifier()
nb_classifier.fit(X, y)
# 评估分类器
accuracy = nb_classifier.evaluate(X, y)
print(f"模型在训练集上的准确率: {accuracy:.2%}")
# 预测新样本
new_samples = pd.DataFrame([
{'色泽': '青绿', '根蒂': '蜷缩', '敲声': '浊响', '纹理': '清晰', '脐部': '凹陷', '触感': '硬滑', '密度': 0.697, '含糖率': 0.460},
])
predictions = nb_classifier.predict(new_samples)
for i, pred in enumerate(predictions):
print(f"样本{i + 1}的预测结果: {'是' if pred == '是' else '否'}")

















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









