







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
- 消息体中存储业务数据,例如如果是一个Dubbo协议,那消息体中可能会包含请求参数、调用的服务名等,而且字符串类的存储通常会采取字段长度、字段内容的组织方式。
为了有一个更直观的展示,我以一个简单的RPC通信场景为例,实现类似Dubbo服务的远程服务调用,其通信协议可以简单设置成下图所示:

基于 Header + Boby 的通信协议设计模式后,通信接受方就能很好的从二进制流中非常容易的解码出一条一条原始的请求数据包,解码的基本套路如下(在面试中面试官非常喜欢问的“粘包”问题的破解之道)
-
首先判断累积缓存区中是否存在一个完整的Head头部,例如上述示例中,一个包的Header的长度为6个字节,那首先判断累积缓存中可读字节数是否大于等于6,如果不足6个字节,跳过本次处理,等待更多数据到达累积缓存区。
-
尝试将头部6个字节读取,并且提取长度字段中存储的数值,即包长度,然后判断累积缓存区中可读字节数大于等于整个包的长度,如果累积缓存区不包含一个完整的数据包,则跳过本次处理,等待更多数据到达累积缓存区。
-
如果包含一个完整的包,则按照通信协议的格式按序读取相关的内容。
正是因为这种设计理念非常通用,Netty 对上述协议设计进行了统一封装:LengthFieldBasedFrameDecoder 闪亮登场了,接下来我们来看看Netty是如何进行封装的,揭晓更多的实现细节,让大家做到理论与实践相结合。
2、LengthFieldBasedFrameDecoder 详解
2.1 概述

接下来对其核心属性进行一个详细的解读:
- ByteOrder byteOrder
字节序列,Netty默认使用大端序列(主要是针对int、long等数值类型),所谓的大端序列,通常可以这样理解,接收端收到的字节流的顺序是从数值类型的高字节。
- int maxFrameLength
一条消息最大的长度。
- int lengthFieldOffset
代表长度字段的开始偏移量。
- int lengthFieldLength
代表长度字段占用的字节长度。
- int lengthFieldEndOffset
代表长度字段的结束偏移量,等于lengthFieldOffset + lengthFieldLength。
- int lengthAdjustment
长度适配适配值。该值表示协议中长度字段与消息体字段直接的距离。
- int initialBytesToStrip
跳过一个包中前面多少个字节不处理,通常是将协议头部跳过,只将消息体中内容传输到下游时使用。
- boolean failFast
是否快速失败。
- boolean discardingTooLongFrame
是否吞没(跳过)大帧包。
- long tooLongFrameLength
当前在处理吞没大包的实际大小。
- long bytesToDiscard
下一次解码之前,需要先忽略的字节数,当遇到超过maxFrameLength的包时使用。
上面的属性如果不太好理解,没关系,因为本节的最后会有两张图勾画出协议的全貌(用图示的方式勾画出各个属性的位置与含义)。
2.2 decode 方法详解
接下来我们来看一下其decode方法,通过阅读源码的方法来理解其内部的工作原理。
LengthFieldBasedFrameDecoder#decode
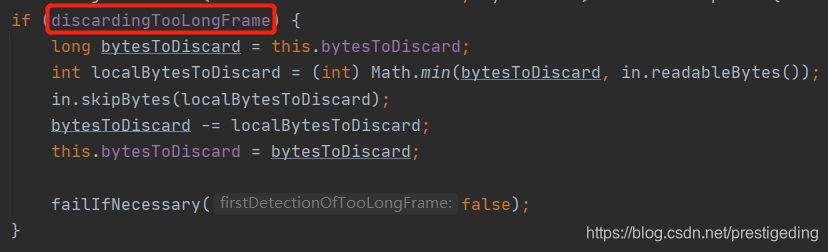
Step1:跳过无效数据包的处理逻辑。如果discardingTooLongFrame为true,表示正在处理大于****maxFrameLength的包,需要跳过这个超长的包,不对其解码,由于数据是陆续到达累积缓存区,并不能一次跳过整个无效包,故需引入 bytesToDiscard 变量,用于记录本次能跳过的字节,当 bytesToDiscard 为 0后表示一个无效包已全部跳过,需要处理正常数据包,此时discardingTooLongFrame 会重置为 false。

Step2:如果累积缓冲区的可读字节大小小于length字段的结束偏移量,返回null,结束解码,说明该累积缓存区中的数据还不完整。
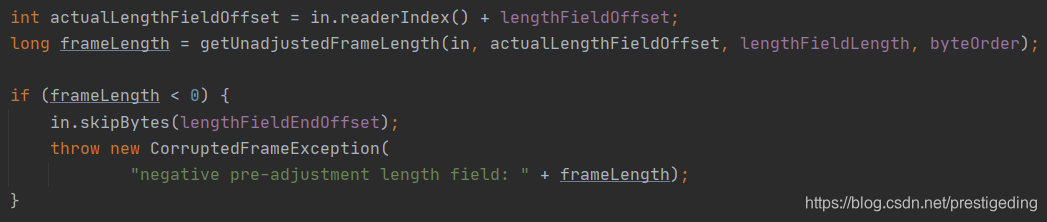
Step3:尝试从累积缓存区中获取包的长度。其中表示 lengthFiedlOffset 表示长度字段的其实偏移量,在结合长度字段的长度 lengthFieldLength ,再结合字节序列**(大端序列、小端序列)**。
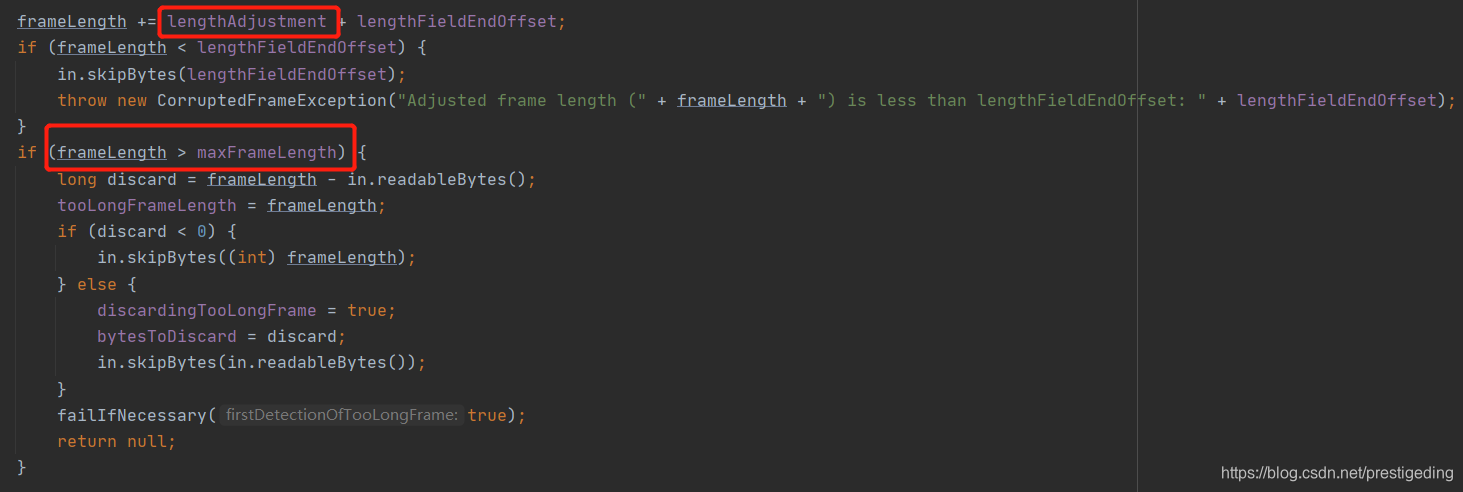
Step4:这里是包长度超过协议允许的最大包长度时的处理逻辑,再这里大家先姑且跳过 lengthAdjustment 属性的含义。
-
如果当前累积缓存区中的可读字节大于 frameLength,大于当前包的长度,可以通过调用 skipBytes 方法跳过这包。
-
如果当前累积缓存区的可读自己小于 frmaeLength,需要分多次跳过,故先将累积区中的数据全部跳过,然后通过 bytesToDiscard 记录还需要跳过的字节数。
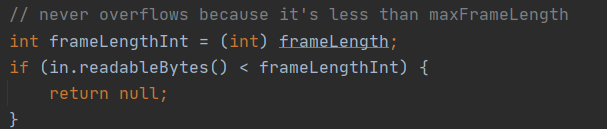
Step5:如果累积缓存区中的数据不包含一个完整的包,返回null,结束本次解码,等待更多的数据包到到来。

最近我根据上述的技术体系图搜集了几十套腾讯、头条、阿里、美团等公司21年的面试题,把技术点整理成了视频(实际上比预期多花了不少精力),包含知识脉络 + 诸多细节,由于篇幅有限,这里以图片的形式给大家展示一部分

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
ip1024b (备注Java)**
[外链图片转存中…(img-GnxdzzdA-1713544515525)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 489
489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









