







REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
srijan/custom1 latest 634855a43331 About a minute ago 277.4 MB
srijan@vboxtest:~/kishore$
这里,你会发现映像在默认情况下会安装apache2。不妨反复核对一下:
docker run -t -i srijan/apache2:webserver /bin/bash
现在,你可以进入新容器,而apache2和12.04ubuntu已预装。
主机名称的更改
假设你想更改主机名称,或者你想有一个定制的主机名称,比如我这里的server1.example.com。
我会使用:
sudo docker run -h ‘server1.example.com’ -t -i srijan/custom1 /bin/bash
它会得出映像容器,如下所示:
root@server1:/# hostname -f
server1.example.com
root@server1:/#
Docker其它的实用命令集锦
•pull(pull用于从注册中心拉取映像或软件库)
docker pull ubuntu
•commit(commit用于保存容器)
docker commit 73527b8b4261 srijan/apache2 8ce0ea7a1528
•cp(将文件/文件夹从容器的文件系统拷贝到主机路径。路径相对于文件系统的根目录。)
docker cp CONTAINER:PATH HOSTPATH
其中的CONTAINER是容器,将文件/文件夹从PATH拷贝到HOSTPATH
•start和stop容器:
docker start 4386fb97867d
docker stop 4386fb97867d
其中的4386fb97867d是你的容器编号
•export(将文件系统的内容作为tar存档文件导出到STDOUT)
docker export 4386fb97867d > latest.tar
•import(创建一个空的文件系统映像,将打包文件[.tar、.tar.gz、.tgz、.bzip、.tar.xz或.txz]的内容导入到里面,然后以可选方式标记它。)
docker import http://example.com/exampleimage.tgz
从本地文件导入:
通过pipe和stdin导入到docker。
cat exampleimage.tgz | sudo docker import - exampleimagelocal:new
从本地目录导入:
sudo tar -c . | sudo docker import - exampleimagedir
•history(显示映像的历史记录)
docker history [OPTIONS] IMAGE
sudo docker history ea7d6801c538
•images(它会显示映像)
docker images [OPTIONS] [NAME]
它后面跟一些选项,如下所示:
-a, --all=false 显示所有映像(默认情况下,过滤掉中间映像层)
-f, --filter=[]: 提供过滤器值(即“dangling=true”)
–no-trunc=false 不截短输出
-q, --quiet=false 只显示数字编号
•info(显示整个系统的信息)
srijan@vboxtest:~$ sudo docker info
Containers: 20
Images: 65
Storage Driver: aufs
Root Dir: /var/lib/docker/aufs
Dirs: 105
Execution Driver: native-0.2
Kernel Version: 3.13.0-30-generic
WARNING: No swap limit support
•inspect(返回关于容器/映像的低级信息)
docker inspect CONTAINER|IMAGE [CONTAINER|IMAGE…]
•kill(终止运行中的容器/发送SIGKILL,即指定信号)
docker kill [OPTIONS] CONTAINER [CONTAINER…]
•login(注册或登录docker注册中心服务器,如果未指定任何服务器,https://index.docker.io/v1/为默认值。)
docker login localhost:8080
它会登录到自托管注册中心。
•logs(读取容器的日志)
docker logs CONTAINER
•ps(列出容器)
docker ps [OPTIONS]
它有下列选项:
-a, --all=false 显示所有容器。默认情况下只显示运行中的容器。
–before=“” 只显示编号或名称之前创建的容器,包括非运行中的容器。
-l, --latest=false 只显示最近创建的容器,包括非运行中的容器。
-n=-1 显示n个最近创建的容器,包括非运行中的容器。
–no-trunc=false 不截短输出。
-q, --quiet=false 只显示数字编号。
-s, --size=false 显示大小。
–since=“” 只显示自编号或名称以来创建的容器,包括非运行中的容器。
•push(将映像或软件库推送到注册中心)
docker push NAME[:TAG]
•restart(它将重启运行中的容器)
docker restart [OPTIONS] CONTAINER [CONTAINER…]
•rm(它将删除一个或多个容器)
docker rm [OPTIONS] CONTAINER [CONTAINER…]
•rmi(它将删除一个或多个映像)
docker rmi IMAGE [IMAGE…]
•run(在新容器中运行命令)
docker run [OPTIONS] IMAGE [COMMAND] [ARG…]
它有下列选项:
-a, --attach=[] 连接到stdin、stdout或stderr
-c, --cpu-shares=0 处理器共享(相对权重)
–cidfile=“” 将容器编号写入到文件
-d, --detach=false 分离模式:在后台运行容器,输出新的容器编号
–dns=[] 设置自定义DNS服务器
–dns-search=[] 设置自定义DNS搜索域
-e, --env=[] 设置环境变量
–entrypoint=“” 覆盖映像的默认入口点
–env-file=[] 在行分隔的文件中读取ENV变量
–expose=[] 暴露来自容器的端口,又不将端口发布到你的主机
-h, --hostname=“” 容器主机名称
-i, --interactive=false 让stdin保持开放,即便没有连接
–link=[] 将链接添加到另一个容器(名称:别名)
–lxc-conf=[] (lxc exec-driver only)添加自定义lxc选项–lxc-conf=“lxc.cgroup.cpuset.cpus = 0,1”
-m, --memory=“” 内存限制(格式:,其中unit = b, k, m or g)
–name=“” 为容器赋予名称
–net=“bridge” 为容器设置网络模式
‘bridge’:为docker网桥上的容器创建新的网络堆栈
‘none’:不为该容器创建任何网络机制
‘container:<name|id>’:重复使用另一个容器的网络堆栈
‘host’:使用容器里面的主机网络堆栈
-p, --publish=[] 将容器的端口发布到主机
格式:ip:hostPort:containerPort | ip::containerPort | hostPort:containerPort
(使用“docker port”即可看到实际映射)
-P, --publish-all=false 将所有暴露的端口发布到主机接口
–privileged=false 为该容器赋予扩展后的权限
–rm=false 容器退出后,自动删除容器(与-d不兼容)
–sig-proxy=true 将所有收到的信号代理输出到进程(即便处于非-tty模式下)
-t, --tty=false 分配伪终端
-u, --user=“” 用户名称或UID
-v, --volume=[] 绑定挂载卷(比如来自host:-v /host:/container,来自docker: -v /container)
–volumes-from=[] 从指定的一个或多个容器挂载卷
-w, --workdir=“” 容器里面的工作目录
•save(将映像保存到tar存档文件,默认情况下流式传输到stdout)
docker save IMAGE
•search(搜索docker索引,寻找映像)
docker search TERM
•tag(将映像标记到软件库)
docker tag [OPTIONS] IMAGE [REGISTRYHOST/][USERNAME/]NAME[:TAG]
•top(查询容器的运行中进程)
docker top CONTAINER [ps OPTIONS]
•version(显示docker版本信息)
srijan@vboxtest:~$ sudo docker version
[sudo] password for srijan:
Client version: 1.0.1
Client API version: 1.12
Go version (client): go1.2.1
Git commit (client): 990021a
Server version: 1.0.1
Server API version: 1.12
Go version (server): go1.2.1
Git commit (server): 990021a
如果系统中还不存在 Fedora Docker 镜像,这个命令会自动下载它,然后启动这个 Fedora 的 Docker 容器。
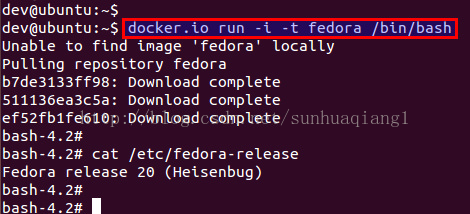
上面的命令会立即启动 Ubuntu container 容器(这是一个完美的容器!),然后它会提供一个 shell 提示符运行环境给你。现在开始你可以通过这个沙箱环境访问一个完整的 Ubuntu 系统了。
输入“exit”命令退出 Docker 容器。
导出镜像
sudo docker save IMAGENAME | bzip2 -9 -c>img.tar.bz2
导入镜像
sudo bzip2 -d -c <img.tar.bz2 | docker load
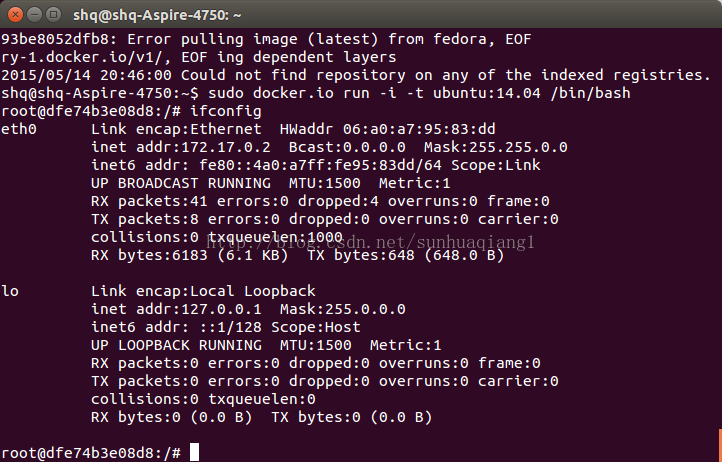
在主机节点上部署了Docker容器中,接着就需要虚拟出多个客户端容器。
3.Container 容器网络设置
Docker 使用 Linux 桥接技术与其他容器通信,以及连通外网。安装完 Docker 后你应该可以看到 docker0 这个网桥,这是 Docker 默认创建的。你创建的每个容器都会通过这个网桥连接到网络。
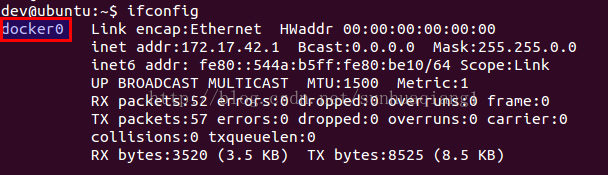
4.自定义 Linux 网桥
如果你想自定义网桥,你可以执行以下步骤。你可以在这个网桥后面分配一个子网,并为这个子网分配地址。下面的命令会为 Docker 子网分配 10.0.0.0/24 地址段:
sudo apt-get install bridge-utils
sudo brctl addbr br0
sudo ifconfig br0 10.0.0.1 netmask 255.255.255.0
然后在 /etc/default/docker.io 文件的 DOCKER_OPTS 变量里添加“-b=br0”选项,并重启 Docker 服务:
sudo service docker.io restart
到目前为止,任何创建的容器都会连上 br0 网桥,它们的 IP 地址会从 10.0.0.0/24 中自动分配(译注:在10.0.0.2到10.0.0.254之间随机分配)。
其他自定义设置
你可以通过 /etc/default/docker.io 文件的 DOCKER_OPTS 变量设置其他一些属性:
“-dns 8.8.8.8 -dns 8.8.4.4”: 为容器指定 DNS 服务器。
“-icc=false”: 将容器与其他容器隔离出来
我试着让大家更加熟悉docker,但愿本文会帮助各位进一步了解docker,并在自己的测试/生产环境中充分利用docker。
web浏览器中的javascript
- 客户端javascript
- 在html里嵌入javascript
- javascript程序的执行
- 兼容性和互用性
- 可访问性
- 安全性
- 客户端框架
- 开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】

window对象
-
计时器
-
浏览器定位和导航
-
浏览历史
-
浏览器和屏幕信息
-
对话框
-
错误处理
-
作为window对象属性的文档元素















 3982
3982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









