







 本文详细探讨了 Vue3 模板编译的过程,包括解析、属性处理、AST 节点定义以及 Transform 阶段的 cacheHandlers、hoistStatic 等选项。内容涉及 AST 结构、属性解析、双花插值处理,以及 PatchFlags 在 diff 过程中的作用。此外,还讨论了代码生成阶段和不同类型的节点转换。
本文详细探讨了 Vue3 模板编译的过程,包括解析、属性处理、AST 节点定义以及 Transform 阶段的 cacheHandlers、hoistStatic 等选项。内容涉及 AST 结构、属性解析、双花插值处理,以及 PatchFlags 在 diff 过程中的作用。此外,还讨论了代码生成阶段和不同类型的节点转换。
首先解析 <div,然后执行 advanceBy(context, 4) 进行截断操作(内部执行的是 s = s.slice(4)),变成:
name=“test”>
再解析属性,并截断,变成:
同理,后面的截断情况为:
AST 节点
所有的 AST 节点定义都在 compiler-core/ast.ts 文件中,下面是一个元素节点的定义:
export interface BaseElementNode extends Node {
type: NodeTypes.ELEMENT // 类型
ns: Namespace // 命名空间 默认为 HTML,即 0
tag: string // 标签名
tagType: ElementTypes // 元素类型
isSelfClosing: boolean // 是否是自闭合标签 例如
props: Array<AttributeNode | DirectiveNode> // props 属性,包含 HTML 属性和指令
children: TemplateChildNode[] // 字节点
}
一些简单的要点已经讲完了,下面我们再从一个比较复杂的例子来详细讲解一下 parse 的处理过程。
{{ test }}
一个文本节点
上面的模板字符串假设为 s,第一个字符 s[0] 是 < 开头,那说明它只能是刚才所说的四种情况之一。这时需要再看一下 s[1] 的字符是什么:
1.如果是 !,则调用字符串原生方法 startsWith() 看看是以 '<!--' 开头还是以 '<!DOCTYPE' 开头。虽然这两者对应的处理函数不一样,但它们最终都是解析为注释节点。2.如果是 /,则按结束标签处理。3.如果不是 /,则按开始标签处理。
从我们的示例来看,这是一个 <div> 开始标签。
这里还有一点要提一下,Vue 会用一个栈 stack 来保存解析到的元素标签。当它遇到开始标签时,会将这个标签推入栈,遇到结束标签时,将刚才的标签弹出栈。它的作用是保存当前已经解析了,但还没解析完的元素标签。这个栈还有另一个作用,在解析到某个字节点时,通过 stack[stack.length - 1] 可以获取它的父元素。
从我们的示例来看,它的出入栈顺序是这样的:
-
[div] // div 入栈
-
[div, p] // p 入栈
-
[div] // p 出栈
-
[div, div] // div 入栈
-
[div] // div 出栈
-
[] // 最后一个 div 出栈,模板字符串已解析完,这时栈为空
接着上文继续分析我们的示例,这时已经知道是 div 标签了,接下来会把已经解析完的 <div 字符串截断,然后解析它的属性。
Vue 的属性有两种情况:
1.HTML 普通属性2.Vue 指令
根据属性的不同生成的节点不同,HTML 普通属性节点 type 为 6,Vue 指令节点 type 为 7。
所有的节点类型值如下:
ROOT, // 根节点 0
ELEMENT, // 元素节点 1
TEXT, // 文本节点 2
COMMENT, // 注释节点 3
SIMPLE_EXPRESSION, // 表达式 4
INTERPOLATION, // 双花插值 {{ }} 5
ATTRIBUTE, // 属性 6
DIRECTIVE, // 指令 7
属性解析完后,div 开始标签也就解析完了,<div name="test"> 这一行字符串已经被截断。现在剩下的字符串如下:
{{ test }}
一个文本节点
注释文本和普通文本节点解析规则都很简单,直接截断,生成节点。注释文本调用 parseComment() 函数处理,文本节点调用 parseText() 处理。
双花插值的字符串处理逻辑稍微复杂点,例如示例中的 {{ test }}:
1.先将双花括号中的内容提取出来,即 test,再对它执行 trim(),去除空格。2.然后会生成两个节点,一个节点是 INTERPOLATION,type 为 5,表示它是双花插值。3.第二个节点是它的内容,即 test,它会生成一个 SIMPLE_EXPRESSION 节点,type 为 4。
return {
type: NodeTypes.INTERPOLATION, // 双花插值类型
content: {
type: NodeTypes.SIMPLE_EXPRESSION,
isStatic: false, // 非静态节点
isConstant: false,
content,
loc: getSelection(context, innerStart, innerEnd)
},
loc: getSelection(context, start)
}
剩下的字符串解析逻辑和上文的差不多,就不解释了,最后这个示例解析出来的 AST 如下所示:
从 AST 上,我们还能看到某些节点上有一些别的属性:
1.ns,命名空间,一般为 HTML,值为 0。2.loc,它是一个位置信息,表明这个节点在源 HTML 字符串中的位置,包含行,列,偏移量等信息。3.{{ test }} 解析出来的节点会有一个 isStatic 属性,值为 false,表示这是一个动态节点。如果是静态节点,则只会生成一次,并且在后面的阶段一直复用同一个,不用进行 diff 比较。
另外还有一个 tagType 属性,它有 4 个值:
export const enum ElementTypes {
ELEMENT, // 0 元素节点
COMPONENT, // 1 组件
SLOT, // 2 插槽
TEMPLATE // 3 模板
}
主要用于区分上述四种类型节点。
Transform
在 transform 阶段,Vue 会对 AST 进行一些转换操作,主要是根据不同的 AST 节点添加不同的选项参数,这些参数在 codegen 阶段会用到。下面列举一些比较重要的选项:
cacheHandlers
如果 cacheHandlers 的值为 true,则表示开启事件函数缓存。例如 @click="foo" 默认编译为 { onClick: foo },如果开启了这个选项,则编译为
{ onClick: _cache[0] || (_cache[0] = e => _ctx.foo(e)) }
hoistStatic
hoistStatic 是一个标识符,表示要不要开启静态节点提升。如果值为 true,静态节点将被提升到 render() 函数外面生成,并被命名为 _hoisted_x 变量。
例如 一个文本节点 生成的代码为 const _hoisted_2 = /*#__PURE__*/_createTextVNode(" 一个文本节点 ")。
下面两张图,前者是 hoistStatic = false,后面是 hoistStatic = true。大家可以在网站[1]上自己试一下。


prefixIdentifiers
这个参数的作用是用于代码生成。例如 {{ foo }} 在 module 模式下生成的代码为 _ctx.foo,而在 function 模式下是 with (this) { ... }。因为在 module 模式下,默认为严格模式,不能使用 with 语句。
PatchFlags
transform 在对 AST 节点进行转换时,会打上 patchflag 参数,这个参数主要用于 diff 比较过程。当 DOM 节点有这个标志并且大于 0,就代表要更新,没有就跳过。
我们来看一下 patchflag 的取值范围:
export const enum PatchFlags {
// 动态文本节点
TEXT = 1,
// 动态 class
CLASS = 1 << 1, // 2
// 动态 style
STYLE = 1 << 2, // 4
// 动态属性,但不包含类名和样式
// 如果是组件,则可以包含类名和样式
PROPS = 1 << 3, // 8
// 具有动态 key 属性,当 key 改变时,需要进行完整的 diff 比较。
FULL_PROPS = 1 << 4, // 16
// 带有监听事件的节点
HYDRATE_EVENTS = 1 << 5, // 32
// 一个不会改变子节点顺序的 fragment
STABLE_FRAGMENT = 1 << 6, // 64
// 带有 key 属性的 fragment 或部分子字节有 key
KEYED_FRAGMENT = 1 << 7, // 128
// 子节点没有 key 的 fragment
UNKEYED_FRAGMENT = 1 << 8, // 256
// 一个节点只会进行非 props 比较
NEED_PATCH = 1 << 9, // 512
// 动态 slot
DYNAMIC_SLOTS = 1 << 10, // 1024
// 静态节点
HOISTED = -1,
// 指示在 diff 过程应该要退出优化模式
BAIL = -2
}
从上述代码可以看出 patchflag 使用一个 11 位的位图来表示不同的值,每个值都有不同的含义。Vue 在 diff 过程会根据不同的 patchflag 使用不同的 patch 方法。
下图是经过 transform 后的 AST:

可以看到 codegenNode、helpers 和 hoists 已经被填充上了相应的值。codegenNode 是生成代码要用到的数据,hoists 存储的是静态节点,helpers 存储的是创建 VNode 的函数名称(其实是 Symbol)。
在正式开始 transform 前,需要创建一个 transformContext,即 transform 上下文。和这三个属性有关的数据和方法如下:
helpers: new Set(),
hoists: [],
// methods
helper(name) {
context.helpers.add(name)
return name
},
helperString(name) {
return _${helperNameMap[context.helper(name)]}
},
hoist(exp) {
context.hoists.push(exp)
const identifier = createSimpleExpression(
_hoisted_${context.hoists.length},
false,
exp.loc,
true
)
identifier.hoisted = exp
return identifier
},
我们来看一下具体的 transform 过程是怎样的,用 <p>{{ test }}</p> 来做示例。
这个节点对应的是 transformElement() 转换函数,由于 p 没有绑定动态属性,没有绑定指令,所以重点不在它,而是在 {{ test }} 上。{{ test }} 是一个双花插值表达式,所以将它的 patchFlag 设为 1(动态文本节点),对应的执行代码是 patchFlag |= 1。然后再执行 createVNodeCall() 函数,它的返回值就是这个节点的 codegenNode 值。
node.codegenNode = createVNodeCall(
context,
vnodeTag,
vnodeProps,
vnodeChildren,
vnodePatchFlag,
vnodeDynamicProps,
vnodeDirectives,
!!shouldUseBlock,
false /* disableTracking */,
node.loc
)
createVNodeCall() 根据这个节点添加了一个 createVNode Symbol 符号,它放在 helpers 里。其实就是要在代码生成阶段引入的帮助函数。
// createVNodeCall() 内部执行过程,已删除多余的代码
context.helper(CREATE_VNODE)
return {
type: NodeTypes.VNODE_CALL,
tag,
props,
children,
patchFlag,
dynamicProps,
directives,
isBlock,
disableTracking,
loc
}
hoists
一个节点是否添加到 hoists 中,主要看它是不是静态节点,并且需要将 hoistStatic 设为 true。
{{ test }}
一个文本节点 // 静态节点
可以看到,上面有三个静态节点,所以 hoists 数组有 3 个值。并且无论静态节点嵌套有多深,都会被提升到 hoists 中。
type 变化

从上图可以看到,最外层的 div 的 type 原来为 1,经过 transform 生成的 codegenNode 中的 type 变成了 13。这个 13 是代码生成对应的类型 VNODE_CALL。另外还有:
// codegen
VNODE_CALL, // 13
JS_CALL_EXPRESSION, // 14
JS_OBJECT_EXPRESSION, // 15
JS_PROPERTY, // 16
JS_ARRAY_EXPRESSION, // 17
JS_FUNCTION_EXPRESSION, // 18
JS_CONDITIONAL_EXPRESSION, // 19
JS_CACHE_EXPRESSION, // 20
刚才提到的例子 {{ test }},它的 codegenNode 就是通过调用 createVNodeCall() 生成的:
return {
type: NodeTypes.VNODE_CALL,
tag,
props,
children,
patchFlag,
dynamicProps,
directives,
isBlock,
disableTracking,
loc
}
可以从上述代码看到,type 被设置为 NodeTypes.VNODE_CALL,即 13。
每个不同的节点都由不同的 transform 函数来处理,由于篇幅有限,具体代码请自行查阅。
Codegen
代码生成阶段最后生成了一个字符串,我们把字符串的双引号去掉,看一下具体的内容是什么:
const _Vue = Vue
const { createVNode: _createVNode, createCommentVNode: _createCommentVNode, createTextVNode: _createTextVNode } = _Vue
css
1,盒模型
2,如何实现一个最大的正方形
3,一行水平居中,多行居左
4,水平垂直居中
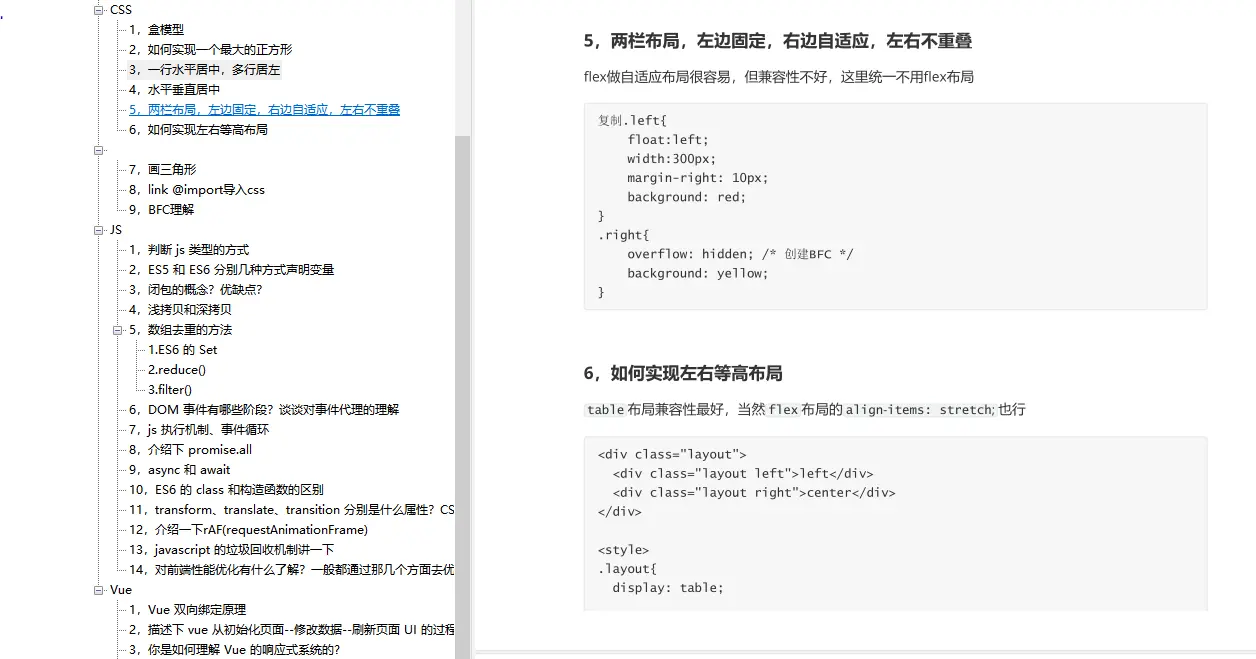
5,两栏布局,左边固定,右边自适应,左右不重叠
6,如何实现左右等高布局
7,画三角形
8,link @import导入css
9,BFC理解
js
1,判断 js 类型的方式
2,ES5 和 ES6 分别几种方式声明变量
3,闭包的概念?优缺点?
4,浅拷贝和深拷贝
5,数组去重的方法
6,DOM 事件有哪些阶段?谈谈对事件代理的理解
7,js 执行机制、事件循环
8,介绍下 promise.all
9,async 和 await,
10,ES6 的 class 和构造函数的区别
11,transform、translate、transition 分别是什么属性?CSS 中常用的实现动画方式,
12,介绍一下rAF(requestAnimationFrame)
13,javascript 的垃圾回收机制讲一下,
14,对前端性能优化有什么了解?一般都通过那几个方面去优化的?

ransform 函数来处理,由于篇幅有限,具体代码请自行查阅。
Codegen
代码生成阶段最后生成了一个字符串,我们把字符串的双引号去掉,看一下具体的内容是什么:
const _Vue = Vue
const { createVNode: _createVNode, createCommentVNode: _createCommentVNode, createTextVNode: _createTextVNode } = _Vue
css
1,盒模型
2,如何实现一个最大的正方形
3,一行水平居中,多行居左
4,水平垂直居中
5,两栏布局,左边固定,右边自适应,左右不重叠
6,如何实现左右等高布局
7,画三角形
8,link @import导入css
9,BFC理解
[外链图片转存中…(img-g6KxSfjM-1714727218774)]
js
1,判断 js 类型的方式
2,ES5 和 ES6 分别几种方式声明变量
3,闭包的概念?优缺点?
4,浅拷贝和深拷贝
5,数组去重的方法
6,DOM 事件有哪些阶段?谈谈对事件代理的理解
7,js 执行机制、事件循环
8,介绍下 promise.all
9,async 和 await,
10,ES6 的 class 和构造函数的区别
11,transform、translate、transition 分别是什么属性?CSS 中常用的实现动画方式,
12,介绍一下rAF(requestAnimationFrame)
13,javascript 的垃圾回收机制讲一下,
14,对前端性能优化有什么了解?一般都通过那几个方面去优化的?
[外链图片转存中…(img-fhegejcH-1714727218775)]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









