







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

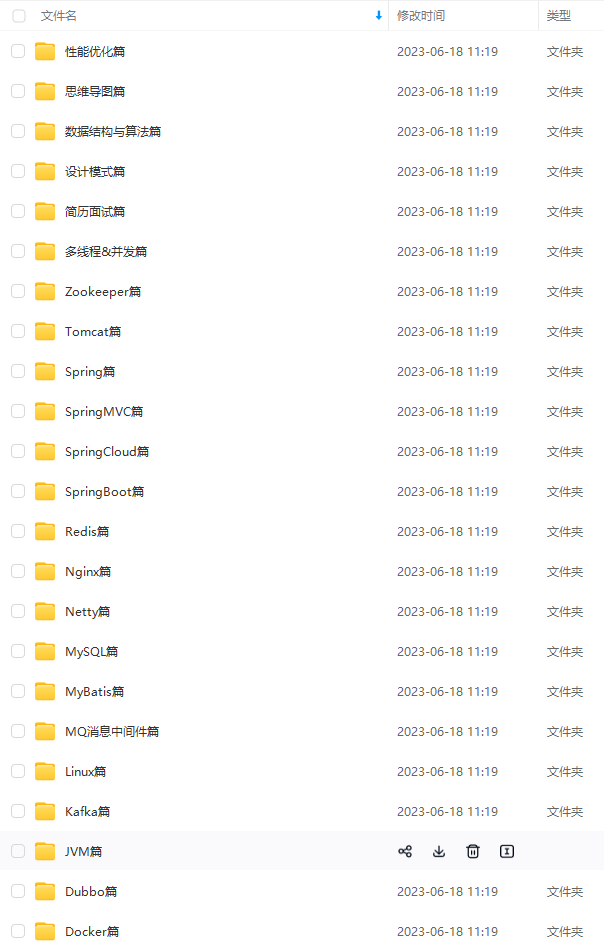
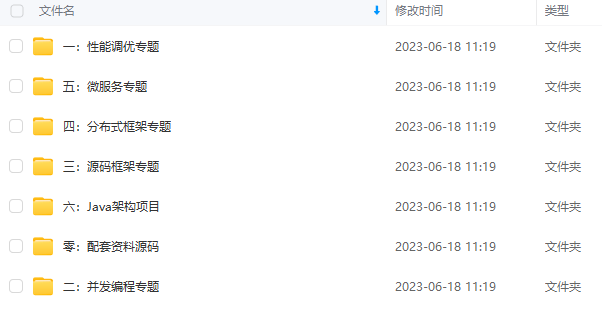
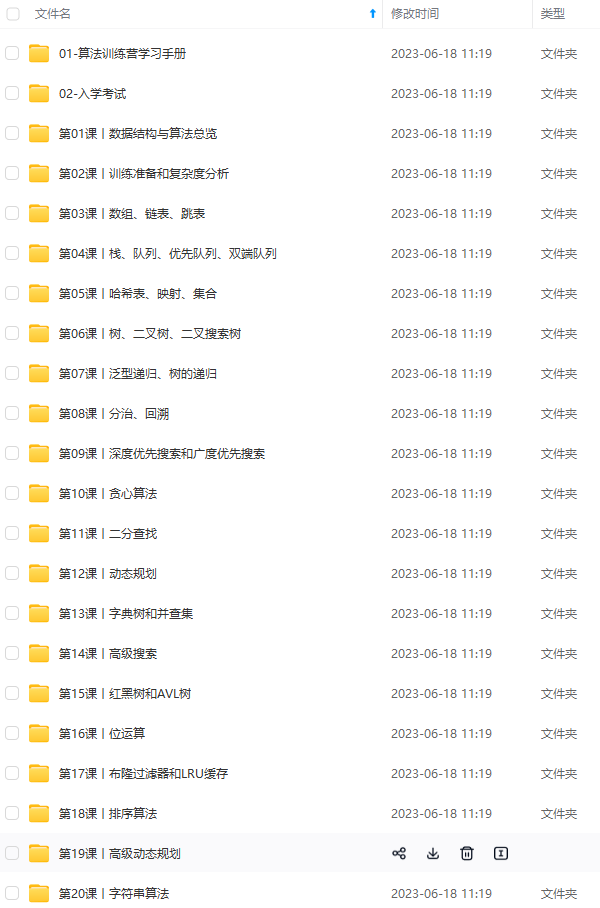
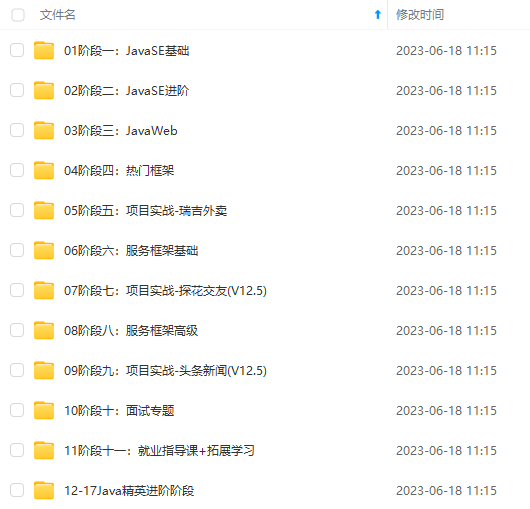
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
可以看见,第六次迭代之后,基本上质心的位置就不再改变了,生成的簇也变得稳定。此时我们的聚类就完成了,我们可以明显看出,KMeans按照数据的分布,将数据聚集成了我们规定的4类,接下来我们就可以按照我们的业务需求或者算法需求,对这四类数据进行不同的处理。
聚类算法聚出的类有什么含义呢?这些类有什么样的性质?
我们认为,被分在同一个簇中的数据是有相似性的,而不同簇中的数据是不同的,当聚类完毕之后,我们就要分别去研究每个簇中的样本都有什么样的性质,从而根据业务需求制定不同的商业或者科技策略。
这个听上去和评分卡案例中讲解的“分箱”概念有些类似,即我们分箱的目的是希望:一个箱内的人有着相似的信用风险,而不同箱的人的信用风险差异巨大,以此来区别不同信用度的人,因此我们追求“组内差异小,组间差异大”。
聚类算法也是同样的目的,我们追求“簇内差异小,簇外差异大”。而这个“差异“,由样本点到其所在簇的质心的距离来衡量。
对于一个簇来说,所有样本点到质心的距离之和越小,我们就认为这个簇中的样本越相似,簇内差异就越小。而距离的衡量方法有多种,
-
令 x x x表示簇中的一个样本点
-
μ \mu μ表示该簇中的质心
-
n表示每个样本点中的特征数目
-
i表示组成点 x x x的每个特征
则该样本点到质心的距离可以由以下距离来度量:
-
欧几里得距离 : d ( x , μ ) = ∑ i = 1 n ( x i − x μ ) 2 d(x, \mu) = \sqrt{\sum_{i=1} ^n (x_i - x_\mu)^2} d(x,μ)=i=1∑n(xi−xμ)2
-
曼哈顿距离: d ( x , μ ) = ∑ i = 1 n ( ∣ x i − μ ∣ ) d(x, \mu) = \sum_{i=1}^{n}(|x_i - \mu|) d(x,μ)=i=1∑n(∣xi−μ∣)
-
余弦距离: c o s θ = ∑ 1 n ( x i ∗ μ ) ∑ 1 n ( x i ) 2 ∗ ∑ 1 n ( μ ) 2 cos\theta = \frac { \sum _1^n(x_i * \mu)} {\sqrt {\sum_1n(x_i)2} * \sqrt{\sum_1n(\mu)2}} cosθ=∑1n(xi)2 ∗∑1n(μ)2 ∑1n(xi∗μ)
如我们采用欧几里得距离,则一个簇中所有样本点到质心的距离的平方和为:

其中,m为一个簇中样本的个数,j是每个样本的编号。
这个公式被称为簇内平方和(cluster Sum of Square),又叫做Inertia。而将一个数据集中的所有簇的簇内平方和相加,就得到了整体平方和(Total Cluster Sum ofSquare),又叫做total inertia。Total Inertia越小,代表着每个簇内样本越相似,聚类的效果就越好。因此KMeans追求的是:求解能够让Inertia最小化的质心。
实际上,在质心不断变化不断迭代的过程中,总体平方和是越来越小的。我们可以使用数学来证明,当整体平方和最小的时候,质心就不再发生变化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3218
3218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









