







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
所以对于大表常见优化即是分库分表和读写分离了。
1.6.1 分库分表
方案
是分库还是分表呢?这要具体分析。
-
如果磁盘或网络有 IO 瓶颈,那就要分库和垂直分表。
-
如果是 CPU 瓶颈,即查询效率偏低,水平分表。
水平即切分数据,分散原有数据到更多的库表中。
垂直即按照业务对库,按字段对表切分。
工具方面有 sharding-sphere、TDDL、Mycat。动起手来需要先评估分库、表数,制定分片规则选 key,再开发和数据迁移,还要考虑扩容问题。
问题
实际运行中,写问题不大,主要问题在于唯一 ID 生成、非 partition key 查询、扩容。
-
唯一 ID 方法很多,DB 自增、Snowflake、号段、一大波GUID算法等。
-
非 partition key 查询常用映射法解决,映射表用到覆盖索引的话还是很快的。或者可以和其他 DB 组合。
-
扩容要根据分片时的策略确定,范围分片的话就很简单,而随机取模分片就要迁移数据了。也可以用范围 + 取模的模式分片,先取模再范围,可以避免一定程度的数据迁移。
当然,如果分库还会面临事务一致性和跨库 join 等问题。
1.6.2 读写分离
为什么要读写分离
分表针对大表解决 CPU 瓶颈,分库解决 IO 瓶颈,二者将存储压力解决了。但查询还不一定。
如果落到 DB 的 QPS 还是很高,且读远大于写,就可以考虑读写分离,基于主从模式将读的压力分摊,避免单机负载过高,同时也保证了高可用,实现了负载均衡。
问题
主要问题有过期读和分配机制。
-
过期读,也就是主从延时问题,这个对于。
-
分配机制,是走主还是从库。可以直接代码中根据语句类型切换或者使用中间件。
1.7 小结
以上列举了 MySQL 常见慢查询原因和处理方法,介绍了应对较大数据场景的常用方法。
分库分表和读写分离是针对大数据或并发场景的,同时也为了提高系统的稳定和拓展性。但也不是所有的问题都最适合这么解决。
2. 如何评价 ElasticSearch
前文有提到对于关键字查询可以使用 ES。那接着聊聊 ES 。
2.1 可以干什么
ES 是基于 Lucene 的近实时分布式搜索引擎。使用场景有全文搜索、NoSQL Json 文档数据库、监控日志、数据采集分析等。
对非数据开发来说,常用的应该就是全文检索和日志了。ES 的使用中,常和 Logstash, Kibana 结合,也成为 ELK 。先来瞧瞧日志怎么用的。
下面是我司日志系统某检索操作:打开 Kibana 在 Discover 页面输入格式如 “xxx” 查询。
该操作可以在 Dev Tools 的控制台替换为:
GET yourIndex/_search
{
“from” : 0, “size” : 10,
“query” : {
“match_phrase” : {
“log” : “xxx”
}
}
}
什么意思?Discover 中加上 “” 和 console 中的 match_phrase 都代表这是一个短语匹配,意味着只保留那些包含全部搜索词项,且位置与搜索词项相同的文档。
2.2 ES 的结构
在 ES 7.0 之前存储结构是 Index -> Type -> Document,按 MySQL 对比就是 database - table - id(实际这种对比不那么合理)。7.0 之后 Type 被废弃了,就暂把 index 当做 table 吧。
在 Dev Tools 的 Console 可以通过以下命令查看一些基本信息。也可以替换为 crul 命令。
-
GET /_cat/health?v&pretty:查看集群健康状态
-
GET /_cat/shards?v :查看分片状态
-
GET yourindex/_mapping :index mapping结构
-
GET yourindex/_settings :index setting结构
-
GET /_cat/indices?v :查看当前节点所有索引信息
重点是 mapping 和 setting ,mapping 可以理解为 MySQL 中表的结构定义,setting 负责控制如分片数量、副本数量。
以下是截取了某日志 index 下的部分 mapping 结构,ES 对字符串类型会默认定义成 text ,同时为它定义一个叫做 keyword 的子字段。这两的区别是:text 类型会进行分词, keyword 类型不会进行分词。
“******”: {
“mappings”: {
“doc”: {
“properties”: {
“appname”: {
“type”: “text”,
“fields”: {
“keyword”: {
“type”: “keyword”,
“ignore_above”: 256
}
}
2.3 ES 查询为什么快?
分词是什么意思?看完 ES 的索引原理你就 get 了。
ES 基于倒排索引。嘛意思?传统索引一般是以文档 ID 作索引,以内容作为记录。倒排索引相反,根据已有属性值,去找到相应的行所在的位置,也就是将单词或内容作为索引,将文档 ID 作为记录。
下图是 ES 倒排索引的示意图,由 Term index,Team Dictionary 和 Posting List 组成。
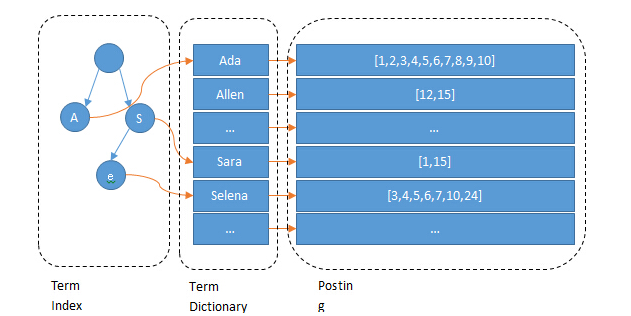
图片
图中的 Ada、Sara 被称作 term,其实就是分词后的词了。如果把图中的 Term Index 去掉,是不是有点像 MySQL 了?Term Dictionary 就像二级索引,但 MySQL 是保存在磁盘上的,检索一个 term 需要若干次的 random access 磁盘操作。
而 ES 在 Term Dictionary 基础上多了层 Term Index ,它以 FST 形式保存在内存中,保存着 term 的前缀,借此可以快速的定位到 Term dictionary 的本 term 的 offset 。而且 FST 形式和 Term dictionary 的 block 存储方式都很节省内存和磁盘空间。
到这就知道为啥快了,就是因为有了内存中的 Term Index , 它为 term 的索引 Term Dictionary 又做了一层索引。
不过,也不是说 ES 什么查询都比 MySQL 快。检索大致分为两类。
2.3.1 分词后检索
ES 的索引存储的就是分词排序后的结果。比如图中的 Ada,在 MySQL 中 %da% 就扫全表了,但对 ES 来说可以快速定位
2.3.2 精确检索
该情况其实相差是不大的,因为 Term Index 的优势没了,却还要借此找到在 term dictionary 中的位置。也许由于 MySQL 覆盖索引无需回表会更快一点。
2.4 什么时候用 ES
如前所述,对于业务中的查询场景什么时候适合使用 ES ?我觉得有两种。
2.4.1 全文检索
在 MySQL 中字符串类型根据关键字模糊查询就是一场灾难,对 ES 来说却是小菜一碟。具体场景,比如消息表对消息内容的模糊查询,即聊天记录查询。
但要注意,如果需要的是类似广大搜索引擎的关键字查询而非日志的短语匹配查询,就需要对中文进行分词处理,最广泛使用的是 ik 。Ik 分词器的安装这里不再细说。
什么意思呢?
分词
开头对日志的查询,键入 “我可真是个机灵鬼” 时,只会得到完全匹配的信息。
而倘若去掉 “”,又会得到按照 “我”、“可”,“真”….分词匹配到的所有信息,这明显会返回很多信息,也是不符合中文语义的。实际期望的分词效果大概是“我”、“可”、“真是”,“机灵鬼”,之后再按照这种分词结果去匹配查询。
这是 ES 默认的分词策略对中文的支持不友善导致的,按照英语单词字母来了,可英语单词间是带有空格的。这也是不少国外软件中文搜索效果不 nice 的原因之一。
对于该问题,你可以在 console 使用下方命令,测试当前 index 的分词效果。
POST yourindex/_analyze
{
“field”:“yourfield”,
“text”:“我可真是个机灵鬼”
}
2.4.2 组合查询
如果数据量够大,表字段又够多。把所有字段信息丢到 ES 里创建索引是不合理的。使用 MySQL 的话那就只能按前文提到的分库分表、读写分离来了。何不组合下。
1. ES + MySQL
将要参与查询的字段信息加上 id,放入 ES,做好分词。将全量信息放入 MySQL,通过 id 快速检索。
2. ES + HBASE
如果要省去分库分表什么的,或许可以抛弃 MySQL ,选择分布式数据库,比如 HBASE , 对于这种 NOSQL 来说,存储能力海量,扩容 easy ,根据 rowkey 查询也很快。
以上思路都是经典的索引与数据存储隔离的方案了。
当然,摊子越大越容易出事,也会面临更多的问题。使用 ES 作索引层,数据同步、时序性、mapping 设计、高可用等都需要考虑。
毕竟和单纯做日志系统对比,日志可以等待,用户不能。
2.5 小结
本节简单介绍了 ES 为啥快,和这个快能用在哪。现在你可以打开 Kibana 的控制台试一试了。
如果想在 Java 项目中接入的话,有 SpringBoot 加持,在 ES 环境 OK 的前提下,完全是开箱即用,就差一个依赖了。基本的 CRUD 支持都是完全 OK 的。
3. HBASE
前面有提到 HBASE , 什么是 HBASE ,鉴于篇幅这里简单说说。
3.1 存储结构
关系型数据库如 MySQL 是按行来的。

HBASE 是按列的(实际是列族)。列式存储上表就会变成:

下图是一个 HBASE 实际的表模型结构。

图片
Row key 是主键,按照字典序排序。TimeStamp 是版本号。info 和 area 都是列簇(column Family),列簇将表进行横向切割。name、age 叫做列,属于某一个列簇,可进行动态添加。Cell 是具体的 Value 。
3.2 OLTP 和 OLAP
数据处理大致可分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。
-
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理。
-
OLAP是数据仓库系统的主要应用,支持复杂分析,侧重决策支持,提供直观易懂的查询结果。
面向列的适合做 OLAP,面向行的适用于联机事务处理(OLTP)。不过 HBASE 并不是 OLAP ,他没有 transaction,实际上也是面向 CF 的。一般也没多少人用 HBASE 做 OLAP 。
3.3 RowKey
HBASE 表设计的好不好,就看 RowKey 设计。这是因为 HBASE 只支持三种查询方式
最后
由于篇幅有限,这里就不一一罗列了,20道常见面试题(含答案)+21条MySQL性能调优经验小编已整理成Word文档或PDF文档

还有更多面试复习笔记分享如下

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
3.3 RowKey
HBASE 表设计的好不好,就看 RowKey 设计。这是因为 HBASE 只支持三种查询方式
最后
由于篇幅有限,这里就不一一罗列了,20道常见面试题(含答案)+21条MySQL性能调优经验小编已整理成Word文档或PDF文档
[外链图片转存中…(img-IvF3Nwcz-1713684444717)]
还有更多面试复习笔记分享如下
[外链图片转存中…(img-JURjqPNp-1713684444717)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-r0TQb1Kf-1713684444718)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 892
892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









