






闲言碎语
最近公司要求检查公司网站首页是否被挂了暗链,网上查了下对应脚本较少且,于是就写了一个关于获取网站的链接的脚本,随着要求的不断增加,再加上一些天马行空的想象,最后写了一款URL采集器
前言
URL采集是一项重要的工作,它能帮我们快速的采集到符合需求的相关URL,但市面上大部分的URL采集软件的原理都是利用多个搜索引擎的接口,输入关键字,如:采集招聘网址URL,一般是输入求职/招聘等关键字,然后对每个接口进行最大化的采集网址,自定义黑名单URL,最后去重。
这意味着需要尽可能多的接口包括但不限于谷歌、百度等,然后传参对返回的页面提取网址基于黑名单过滤部分网址,最后迭代页数。
看上去没错,输入关键词获取相关的网址。但却隐藏着几个缺点:
1、采集网址都是被搜索引擎收录的,导致许多符合需求的URL无法采集到
2、过滤不细致,只靠去重+黑名单过滤,采集到的站点不能保证是需要的
3、采集URL每个人都可以用,关键词也差不多,导致最后采集的结果也差不多,这对于网安人员来说并不友好,因为这就意味着你好不容易找到一个漏洞站点可能已被许多人利用过
功能
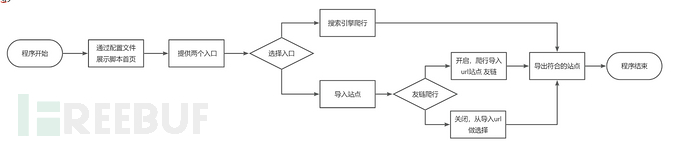
为了解决上诉缺点,我打算写一个URL深度采集脚本,前期构想的功能点:
1、提供两个入口,一个搜索引擎接口或导入采集好的网址
2、传入关键字爬取到符合需求网址再次自动进行友链爬行
3、导入的文本能先筛选掉不符合的站点,而后自定义是否进行友链爬取
4、用户可自定义URL黑白名单、URL网站标题黑白名单,URL网页内容黑白名单
简略流程图如下:
banner
title = '''
__ _______ __ __ .______ __
| | | ____| | | | | | _ \ | |
| | | |__ | | | | | |_) | | |
.--. | | | __| | | | | | / | |
| `--' | | | | `--' | | |\ \----.| `----.
\______/ |__| _____\______/ | _| `._____||_______|
|______|
Author:JF
Version:V1.0
'''
URL采集源码
友链采集
方式一:正则过滤
def GetLink(url):
UA = random.choice(headerss)
headers = {'User-Agent': UA, 'Connection': 'close'}
link_urls = []
try:
r = requests.get(url, headers=headers, verify=False, timeout=timeout)
encoing = requests.utils.get_encodings_from_content(r.text)[0]
content = r.content.decode(encoing)
urls = [f"{urlparse(url).scheme}://{urlparse(url).netloc}" for url in re.findall(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*,]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', content, re.I)]
for url in list(set(urls)):
url = url.replace('\')','')
link_urls.append(url)
#判断存活
# try:
# r = requests.get(url, timeout=5, verify=False)
# if b'Service Unavailable' not in r.content and b'The requested URL was not found on' not in r.content and b'The server encountered an internal error or miscon' not in r.content:
# if r.status_code == 200 or r.status_code == 301 or r.status_code == 302:
# link_urls.append(url)
# except Exception as error:
# pass
except:
pass
return list(set(link_urls))
方式二:bs4过滤
def GetLink(url):
UA = random.choice(headerss)
headers = {'User-Agent': UA, 'Connection': 'close'}
try:
r = requests.get(url, headers=headers, verify=False)
encoding = requests.utils.get_encodings_from_content(r.text)[0]
content = r.content.decode(encoding)
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(content, 'html.parser')
# 提取页面中可能包含URL的常见标签属性
bs4_urls = set()
for tag in ['a', 'img', 'script', 'link']:
for attr in ['href', 'src']:
for element in soup.find_all(tag):
if attr in element.attrs:
href = element.get(attr)
if href and (href.startswith('http://') or href.startswith('https://')):
parsed = urlparse(href)
url = f"{parsed.scheme}://{parsed.netloc}"
bs4_urls.add(url)
except Exception as e:
pass
#url存活加入
link_urls = []
for bs4_url in bs4_urls:
try:
r = requests.head(bs4_url, timeout=5, headers=headers, verify=False)
if r.status_code == 200 or r.status_code == 301 or r.status_code == 301:
link_urls.append(bs4_url)
except Exception as error:
pass
return link_urls
关键字采集
调用百度搜索接口对用户输入的关键字进行搜索并提取出前7页的url
def BDUrl(key):
cookie = input('请输入cookie:')
bd_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Referer": "https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=2&ch=&tn=baiduhome_pg&bar=&wd=123&oq=123&rsv_pq=896f886f000184f4&rsv_t=fdd2CqgBgjaepxfhicpCfrqeWVSXu9DOQY5WyyWqQYmsKOC%2Fl286S248elzxl%2BJhOKe2&rqlang=cn",
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7",
"Sec-Fetch-Mode": "navigate",
"Cookie": cookie,
"Connection": "Keep-Alive",
}
bd_url = []
for page in range(0, 8):
url = 'http://www.baidu.com/s?wd={}&pn={}0'
try:
r = requests.get(url.format(key, page), headers=bd_headers, verify=False)
encoing = requests.utils.get_encodings_from_content(r.text)[0]
content = r.content.decode(encoing)
result = [f"{urlparse(url).scheme}://{urlparse(url).netloc}" for url in re.findall('mu="(.*?)"', content)[1:]]
#result = [url.split('//')[1].split('/')[0] for url in re.findall('mu="(.*?)"', content)[1:]]
for res_url in list(set(result)):
bd_url.append(res_url)
#判断存活
# try:
# r = requests.get(res_url, timeout=5, verify=False)
# if b'Service Unavailable' not in r.content and b'The requested URL was not found on' not in r.content and b'The server encountered an internal error or miscon' not in r.content:
# if r.status_code == 200 or r.status_code == 301 or r.status_code == 302:
# bd_url.append(res_url)
# except Exception as error:
# pass
except:
pass
return list(set(bd_url))
ini配置文件
脚本核心:用户通过自定义配置文件的内容筛选出想要的url
[User]
# 程序的用户名
whoami = JF
#state友链爬行,0关闭,1开启
#其它:
#None不检测该关键词
#支持或(or)逻辑,即 |
#优先级:网址黑名单>网址白名单>标题黑名单>标题白名单>网页内容黑名单>网页内容白名单
[Config]
#友链爬行
state = 0
# 网址黑名单
black_url = None
# 网址白名单
white_url = None
# 标题黑名单
black_title = None
# 标题白名单
white_title = 安全狗
# 网页内容黑名单
black_content = None
# 网页内容白名单
white_content = None
# 连接超时5秒
timeout = 5
用户规则树
通过配置文件所写的函数
方式一:参数为url列表
def RuleUrl(urls):
ruleurls = []
UA = random.choice(headerss)
header = {'User-Agent': UA, 'Connection': 'close'}
# 第一步,URL黑名单限制,在黑名单内的全部排除
black_url_or = []
for url in urls:
if black_url == 'None':
black_url_or.append(url)
elif '|' in black_url:
black_url_key = black_url.split('|')
if all(key not in url for key in black_url_key):
black_url_or.append(url)
else:
black_url_key = black_url
if any(key not in url for key in black_url_key):
black_url_or.append(url)
# 第二步,URL白名单限制,出现在白名单的才保存
white_url_or = []
for url in black_url_or:
if white_url == 'None':
white_url_or.append(url)
elif '|' in white_url:
white_url_key = white_url.split('|')
if any(key in url for key in white_url_key):
white_url_or.append(url)
else:
white_url_key = white_url
if all(key in url for key in white_url_key):
white_url_or.append(url)
# 第三步,网站标题黑名单过滤,在黑名单内的全部排除
black_title_or = []
for url in white_url_or:
if black_title == 'None':
black_title_or.append(url)
elif '|' in black_title:
black_title_key = black_title.split('|')
try:
r = requests.get(url=url, headers=header, verify=False, timeout=timeout)
encoing = requests.utils.get_encodings_from_content(r.text)[0]
content = r.content.decode(encoing)
if r.status_code == 200 or r.status_code == 301 or r.status_code == 302:
title = re.findall('<title>(.*?)</title>', content, re.S)
if all(key not in title[0] for key in black_title_key):
black_title_or.append(url)
except:
pass
else:
black_title_key = black_title
try:
r = requests.get(url=url, headers=header, verify=False, timeout=timeout)
encoing = requests.utils.get_encodings_from_content(r.text)[0]
content = r.content.decode(encoing)
if r.status_code == 200 or r.status_code == 301 or r.status_code == 302:
title = re.findall('<title>(.*?)</title>', content, re.S)
if all(key not in title[0] for key in black_title_key):
black_title_or.append(url)
except:
pass
# 第四步,网站标题白名单过滤,出现在白名单的才保存
white_title_or = []
for url in black_title_or:
if white_title == 'None':
white_title_or.append(url)
elif '|' in white_title:
white_title_key = white_title.split('|')
try:
r = requests.get(url=url, headers=header, verify=False, timeout=timeout)
encoing = requests.utils.get_encodings_from_content(r.text)[0]
content = r.content.decode(encoing)
if r.status_code == 200 or r.status_code == 301 or r.status_code == 302:
title = re.findall('<title>(.*?)</title>', content, re.S)
if any(key in title[0] for key in white_title_key):
white_title_or.append(url)
except:
pass
else:
white_title_key = white_title
try:
r = requests.get(url=url, headers=header, verify=False, timeout=timeout)
encoing = requests.utils.get_encodings_from_content(r.text)[0]
content = r.content.decode(encoing)
if r.status_code == 200 or r.status_code == 301 or r.status_code == 302:
title = re.findall('<title>(.*?)</title>', content, re.S)
if all(key in title[0] for key in white_title_key):
white_title_or.append(url)
except:
pass
# 第五步,网页内容黑名单过滤,出现在黑名单的全排除
black_content_or = []
for url in white_title_or:
if black_content == 'None':
black_content_or.append(url)
elif '|' in black_content:
black_content_key = black_content.split('|')
try:
r = requests.get(url=url, headers=header, verify=False, timeout=timeout)
encoing = requests.utils.get_encodings_from_content(r.text)[0]
content = r.content.decode(encoing)
if r.status_code == 200 or r.status_code == 301 or r.status_code == 302:
if all(key not in content for key in black_content_key):
black_content_or.append(url)
except:
pass
else:
black_content_key = black_content
try:
r = requests.get(url=url, headers=header, verify=False, timeout=timeout)
encoing = requests.utils.get_encodings_from_content(r.text)[0]
content = r.content.decode(encoing)
if r.status_code == 200 or r.status_code == 301 or r.status_code == 302:
if any(key not in content for key in black_content_key):
black_content_or.append(url)
except:
pass
# 第六步,网页内容白名单过滤,只保存出现在白名单内的url
white_content_or = []
for url in black_content_or:
if white_content == 'None':
white_content_or.append(url)
elif '|' in white_content:
white_content_key = white_content.split('|')
try:
r = requests.get(url=url, headers=header, verify=False, timeout=timeout)
encoing = requests.utils.get_encodings_from_content(r.text)[0]
content = r.content.decode(encoing)
if r.status_code == 200 or r.status_code == 301 or r.status_code == 302:
if any(key in content for key in white_content_key):
white_content_or.append(url)
except:
pass
else:
white_content_key = white_content
try:
r = requests.get(url=url, headers=header, verify=False, timeout=timeout)
encoing = requests.utils.get_encodings_from_content(r.text)[0]
content = r.content.decode(encoing)
if r.status_code == 200 or r.status_code == 301 or r.status_code == 302:
if all(key in content for key in white_content_key):
white_content_or.append(url)
except:
pass
return white_content_or
方式二:接收参数改为单个url
第一版的整体逻辑虽然实现了,但效率太慢了,这一版改了整体逻辑
把接收参数改为单个url,用true/false判断传入url是否满足条件,而后实现并发
def rule_url(url):
# 第一步,URL黑名单限制,在黑名单内的全部排除
if black_url != 'None' and (any(key in url for key in black_url.split('|'))):
return False
# 第二步,URL白名单限制,出现在白名单的才保存
if white_url != 'None' and(all(key not in url for key in white_url.split('|'))):
return False
try:
UA = random.choice(headerss)
header = {'User-Agent': UA, 'Connection': 'close'}
r = requests.get(url=url, headers=header, verify=False, timeout=timeout)
if r.status_code == 200 or r.status_code == 301 or r.status_code == 302:
encoing = requests.utils.get_encodings_from_content(r.text)[0]
content = r.content.decode(encoing)
title = re.findall('<title>(.*?)</title>', content, re.S)[0]
# 第三步,网站标题黑名单过滤,在黑名单内的全部排除
if black_title != 'None' and (any(key in title for key in black_title.split('|'))):
return False
# 第四步,网站标题白名单过滤,出现在白名单的才保存
if white_title != 'None' and (all(key not in title for key in white_title.split('|'))):
return False
# 第五步,网页内容黑名单过滤,出现在黑名单的全排除
if black_content != 'None' and (any(key in content for key in black_content.split('|'))):
return False
# 第六步,网页内容白名单过滤,只保存出现在白名单内的url
if white_content != 'None' and (all(key not in content for key in white_content.split('|'))):
return False
return url
else:
return False
except:
return False
return False
入口函数
# 程序入口
def Result():
print(f'当前用户:{whoami}')
if state == '0':
print(f'[-]友链爬行:关闭')
elif state == '1':
print(f'[+]友链爬行:开启')
else:
print(f'[x]友链爬行:输入0/1!')
if black_url == 'None':
print(f'[-]网址黑名单:关闭', end='')
else:
print(f'[+]网址黑名单:开启', end='')
if white_url == 'None':
print(f' [-]网址白名单:关闭')
else:
print(f' [+]网址白名单:开启')
if black_title == 'None':
print(f'[-]标题黑名单:关闭', end='')
else:
print(f'[+]标题黑名单:开启', end='')
if white_title == 'None':
print(f' [-]标题白名单:关闭')
else:
print(f' [+]标题白名单:开启')
if black_content == 'None':
print(f'[-]网页黑名单:关闭', end='')
else:
print(f'[+]网页黑名单:开启', end='')
if black_content == 'None':
print(f' [-]网页白名单:关闭')
else:
print(f' [+]网页白名单:开启')
print('='*50)
print('0:关键字扫描 1:导入文本扫描')
try:
num = int(input('请选择启动方式(0/1):'))
if num == 0:
rurls = set()
keywor = input('请输入关键字:')
t1 = time.time()
bd = bd_urls(keywor,num)
rule_bd_urls = set()
with ThreadPoolExecutor(max_workers=10) as executor:
results_bd = executor.map(rule_url, bd)
with lock:
for url in results_bd:
if url:
rule_bd_urls.add(url)
# 每个url再进行友链检查
l_urls = set()
rule_link_urls = set()
for url in rule_bd_urls:
link_urls = get_links(url)
l_urls.update(link_urls)
with ThreadPoolExecutor(max_workers=10) as executor:
results_link = executor.map(rule_url, l_urls)
with lock:
for url in results_link:
if url:
rule_link_urls.add(url)
# #可以直接保存集合或列表,减少IO
with open(f'{keywor}_url.txt', 'a+', encoding='utf-8') as a:
a.write('\n'.join(rule_link_urls))
t2 = time.time()
print(f'扫描结束,耗时:{t2-t1},结果已保存至【{keywor}_url.txt】中')
elif num == 1:
print('提示:文本中的网址需带有协议类型,如:http/https')
urls = set([url.strip() for url in open(input('将需要扫描的url拖到此窗口:'),'r',encoding='utf-8')])
print(f'文本内共发现{len(urls)}个站点,扫描中。。。')
result = set()
if state == '0':
t1 = time.time()
with ThreadPoolExecutor(max_workers=10) as executor:
results_link = executor.map(rule_url, urls)
with lock:
for url in results_link:
if url:
result.add(url)
elif state == '1':
t1 = time.time()
l_url = set()
for url in urls:
l = get_links(url)
l_url.update(l)
with ThreadPoolExecutor(max_workers=10) as executor:
results_link = executor.map(rule_url, l_url)
with lock:
for url in results_link:
if url:
result.add(url)
with open(filename, 'a+', encoding='utf-8') as a:
a.write('\n'.join(result))
t2 = time.time()
t = str(t2-t1).split('.')[0]
print(f'扫描结束,耗时:{t}s,结果已保存至【{filename}】中')
else:
print('输入有误,程序结束!')
except Exception as e:
print(f'输入有误,程序结束,错误类型:{e}')
if __name__ == '__main__':
title = '''
_ ______ _ _ _____ _
| | ____| | | | | __ \| |
| | |__ | | | | |__) | |
_ | | __| | | | | _ /| |
| |__| | | | |__| | | \ \| |____
\____/|_| \____/|_| \_\______|
'''
#print(title)
Result()
使用测试
脚本测试了1w+站点,目前运行正常
配置文件config.ini
-
None不检测该关键词,只支持或逻辑,即符号|
-
不检测可用None,字段不可放空,否则脚本无法正常运行
-
state只支持0/1,0关闭导入文本的友链爬行,1开启导入文本的友链爬行
-
关键字优先级:网址黑 > 网址白 > 标题黑 > 标题白 > 网页内容黑 > 网页内容白
演示:
注:爬取结束后结果以txt格式保存在当前目录下
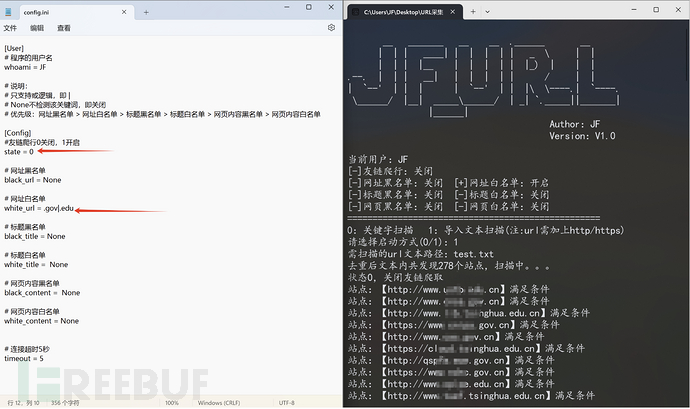
1、通过搜索引擎进行爬取教育类站点
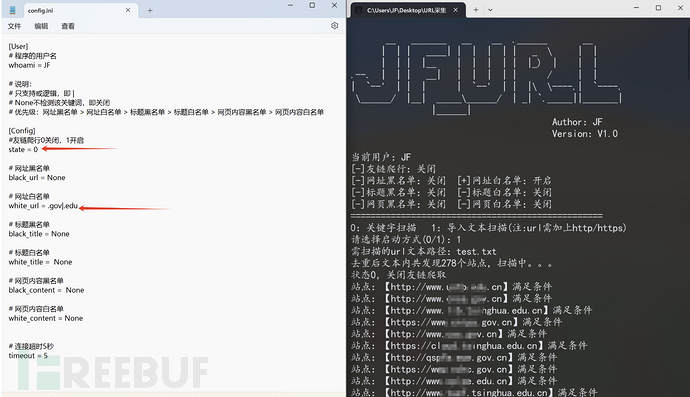
2、通过导入的文本先筛选出教育类站点,不进行友链爬取
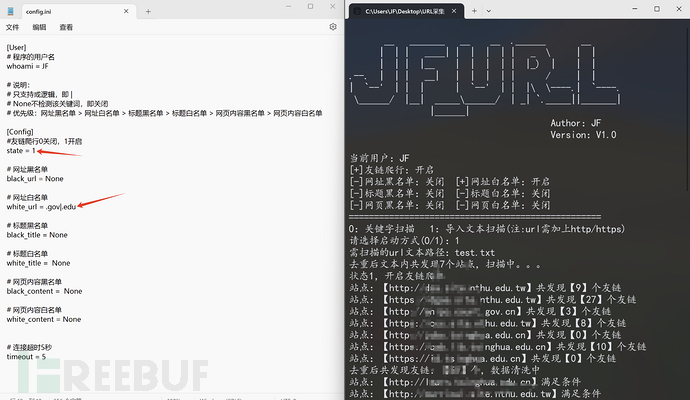
3、通过导入的文本先筛选出教育类站点,再进行友链爬取
题外话
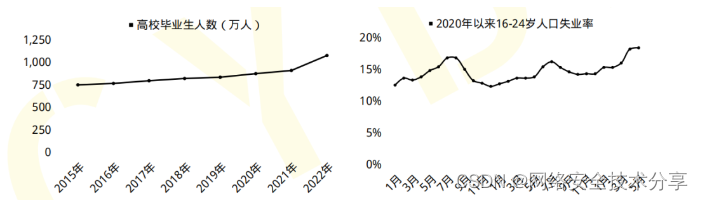
初入计算机行业的人或者大学计算机相关专业毕业生,很多因缺少实战经验,就业处处碰壁。下面我们来看两组数据:
- 2023届全国高校毕业生预计达到1158万人,就业形势严峻;
- 国家网络安全宣传周公布的数据显示,到2027年我国网络安全人员缺口将达327万。
一方面是每年应届毕业生就业形势严峻,一方面是网络安全人才百万缺口。
6月9日,麦可思研究2023年版就业蓝皮书(包括《2023年中国本科生就业报告》《2023年中国高职生就业报告》)正式发布。
2022届大学毕业生月收入较高的前10个专业
本科计算机类、高职自动化类专业月收入较高。2022届本科计算机类、高职自动化类专业月收入分别为6863元、5339元。其中,本科计算机类专业起薪与2021届基本持平,高职自动化类月收入增长明显,2022届反超铁道运输类专业(5295元)排在第一位。
具体看专业,2022届本科月收入较高的专业是信息安全(7579元)。对比2018届,电子科学与技术、自动化等与人工智能相关的本科专业表现不俗,较五年前起薪涨幅均达到了19%。数据科学与大数据技术虽是近年新增专业但表现亮眼,已跻身2022届本科毕业生毕业半年后月收入较高专业前三。五年前唯一进入本科高薪榜前10的人文社科类专业——法语已退出前10之列。

“没有网络安全就没有国家安全”。当前,网络安全已被提升到国家战略的高度,成为影响国家安全、社会稳定至关重要的因素之一。
网络安全行业特点
1、就业薪资非常高,涨薪快 2021年猎聘网发布网络安全行业就业薪资行业最高人均33.77万!
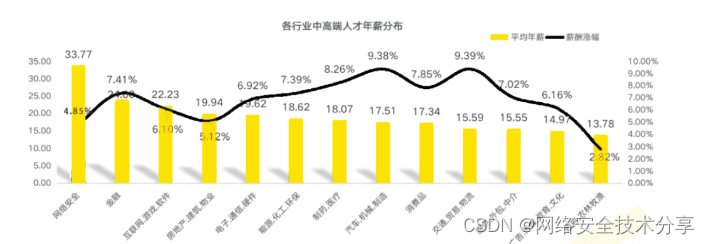
2、人才缺口大,就业机会多
2019年9月18日《中华人民共和国中央人民政府》官方网站发表:我国网络空间安全人才 需求140万人,而全国各大学校每年培养的人员不到1.5W人。猎聘网《2021年上半年网络安全报告》预测2027年网安人才需求300W,现在从事网络安全行业的从业人员只有10W人。
行业发展空间大,岗位非常多
网络安全行业产业以来,随即新增加了几十个网络安全行业岗位︰网络安全专家、网络安全分析师、安全咨询师、网络安全工程师、安全架构师、安全运维工程师、渗透工程师、信息安全管理员、数据安全工程师、网络安全运营工程师、网络安全应急响应工程师、数据鉴定师、网络安全产品经理、网络安全服务工程师、网络安全培训师、网络安全审计员、威胁情报分析工程师、灾难恢复专业人员、实战攻防专业人员…
职业增值潜力大
网络安全专业具有很强的技术特性,尤其是掌握工作中的核心网络架构、安全技术,在职业发展上具有不可替代的竞争优势。
随着个人能力的不断提升,所从事工作的职业价值也会随着自身经验的丰富以及项目运作的成熟,升值空间一路看涨,这也是为什么受大家欢迎的主要原因。
从某种程度来讲,在网络安全领域,跟医生职业一样,越老越吃香,因为技术愈加成熟,自然工作会受到重视,升职加薪则是水到渠成之事。
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图 
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。

2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要保存下方图片,微信扫码即可前往获取

3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要保存下方图片,微信扫码即可前往获取

4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
因篇幅有限,仅展示部分资料,需要保存下方图片,微信扫码即可前往获取

最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要保存下方图片,微信扫码即可前往获取
















 29
29

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









