







摘要
社会模拟正在通过虚拟个体与其环境之间的互动来模拟人类行为,从而改变传统社会科学的研究方式。随着大语言模型(LLM)的最新进展,这种方法在捕捉个体差异和预测群体行为方面展现出越来越大的潜力。然而,现有的方法在环境、目标用户、互动机制和行为模式方面面临着对齐挑战。为此,我们引入了 SocioVerse,这是一个由 LLM 主体驱动的社会模拟世界模型。我们的框架具有四个强大的对齐组件和一个包含 1000 万真实个体的用户池。为了验证其有效性,我们在政治、新闻和经济这三个不同的领域进行了大规模的模拟实验。结果表明,SocioVerse 能够反映大规模的人口动态,同时通过标准化程序和最少的人工调整确保多样性、可信度和代表性。
关键词:社会模拟(Social Simulation)、大语言模型,千万级用户池,一致性挑战(Alignment Challenges)、多场景验证(Multi-domain Validation)

论文题目:SocioVerse: A World Model for Social Simulation Powered by LLM Agents and A Pool of 10 Million Real-World Users
发表时间:2025年4月14日
论文地址:https://arxiv.org/abs/2504.10157
传统社会科学研究长期受限于调查成本高、样本代表性不足等难题。近年来,基于智能体的社会模拟(Social Simulation)技术通过构建虚拟个体与环境交互的模型,为大规模群体行为预测提供了新可能。随着大语言模型的突破性发展,这种技术展现出捕捉个体差异、还原复杂社会动态的潜力。然而,现有方法在环境真实性、用户匹配度、交互机制等方面仍存在显著偏差。近期,最新提出的SocioVerse框架,通过四大创新模块与千万级真实用户池的融合,为这些难题提供了新的解决方案。
四大对齐挑战:构建真实虚拟社会的关键壁垒
文章指出社会模拟中的四大核心“一致性”问题:动态环境对齐(How to align the simulated environment with the real world?)、用户画像精准匹配(How to align simulated agents with target users precisely?)、多场景交互适配(How to align the interaction mechanism with the real world among different scenarios?)、群体行为模式还原(How to align the behavioral patterns with the real-world groups?)。传统方法依赖LLM的静态知识库,难以捕捉俄乌冲突、美国大选等实时事件的动态影响;虚拟用户常因缺乏真实人口统计学特征(如职业、收入、意识形态),导致群体行为失真,例如,在选举预测场景中,忽略“摇摆州”选民的政治光谱分布,模型可能误判关键州的投票倾向。
研究团队提出“模块化治理”思路:通过社会引擎(Social Environment)实时抓取新闻事件与政策动态,为LLM主体注入“时效认知”;用户引擎(User Engine)则依托千万级社交媒体用户数据(覆盖X和Rednote平台),构建包含15项人口属性的标签体系,其标注系统通过多LLM协同标注、人工校验、分类器迭代的三阶段流程,将用户画像准确率提升至92%以上。
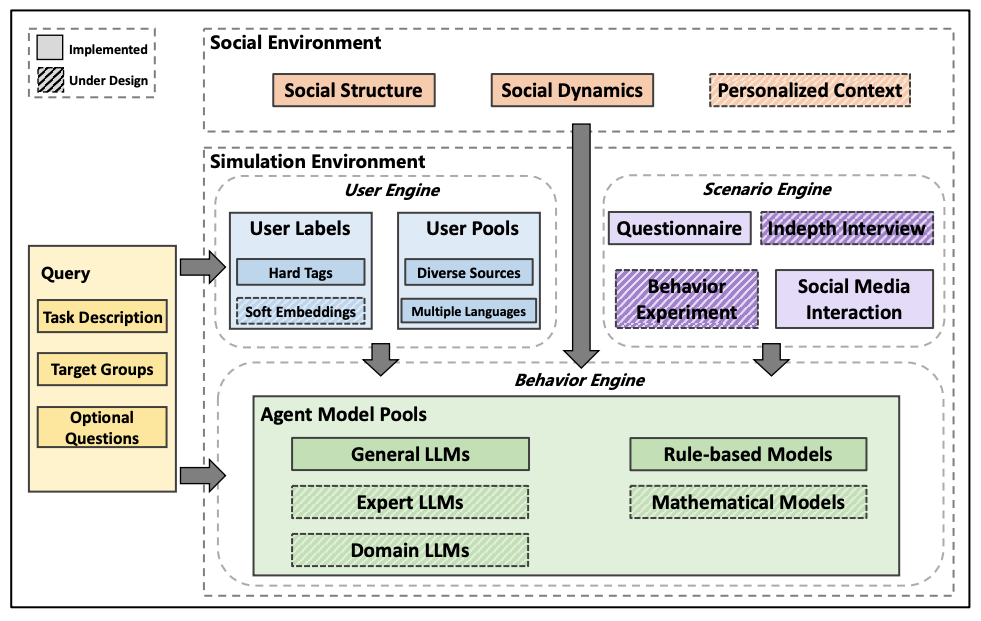
图 1. SocioVerse框架包含4个主体部分。社交环境为模拟提供了更新的内容。在模拟过程中,行为引擎分别从场景引擎、用户引擎和社交环境中获取模拟设置、用户配置文件和社交信息,并根据查询(query)生成结果。
千万级用户池:虚拟社会的“数字基因库”
SocioVerse的核心还在于其千万级真实用户池的构建。研究团队从社交平台抓取超7000万条动态,通过文本相似度分析过滤广告与机器人账户,最终保留1006万Twitter用户与915万小红书用户。这些“数字居民”的线上足迹构成多维行为图谱:从政治倾向(Trump支持者)、消费习惯(奢侈品偏好)到兴趣标签(科技爱好者),每个用户被编码为包含年龄、性别、职业、意识形态等15维特征的向量。
这种高密度数据支撑的创新采样策略(如迭代比例拟合/IPF算法),使得在模拟美国大选时,能精准复现各州选民的结构性特征。例如在佛罗里达州拉丁裔选民的模拟中,系统根据真实人口普查数据,自动调整该群体在移民政策、经济议题上的立场分布,确保虚拟选民群体与现实人口统计学的高度一致。
从总统选举到经济预测:多领域验证框架效能
研究团队选择政治选举、突发新闻、国民经济三大领域进行验证,构建了标准化的模拟流程:
1. 总统选举预测:基于ANES投票数据与人口普查资料,生成33万虚拟选民。模型不仅准确预测了90%州的选举结果,在宾夕法尼亚等关键摇摆州的得票率误差控制在3.1%以内;
2. 突发新闻反馈:从小红书科技话题用户中抽取2万样本,通过情感-认知-行为(ABC)模型捕捉公众态度。例如,Qwen2.5-72B模型在风险感知(Perceived Risks)维度的KL散度低至0.113,说明能一定程度上反映技术乐观派与担忧派的观点交锋;
3. 居民消费调查:模拟16万中国家庭支出,结果与国家统计局数据的NRMSE误差仅为2.5%,尤其在发达地区的医疗、教育支出预测中表现出色。
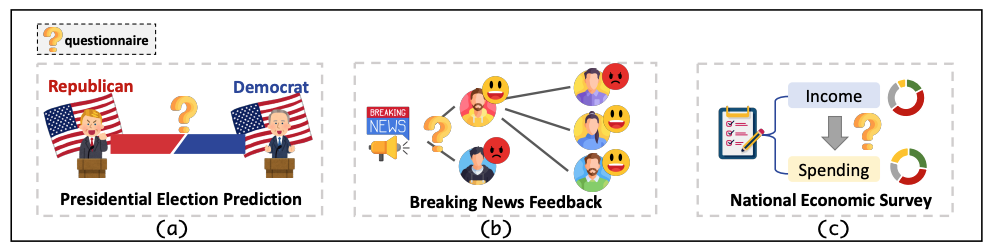
图 2. 上述三种情景,分别表示总统选举预测,突发新闻反馈和国家经济调查。
实验发现,LLM的性能存在显著场景依赖性:在需要深层经济推理的住房支出预测中,所有模型的误差均高于其他消费类别(最高达12%),这暴露出LLM对结构性经济问题的认知局限。此外,在选举预测中,引入用户历史帖文作为上下文后,可以提升模型预测准确度,例如,DeepSeek-V3的准确率提升17%,证明个体数字足迹对行为模拟的增强作用。
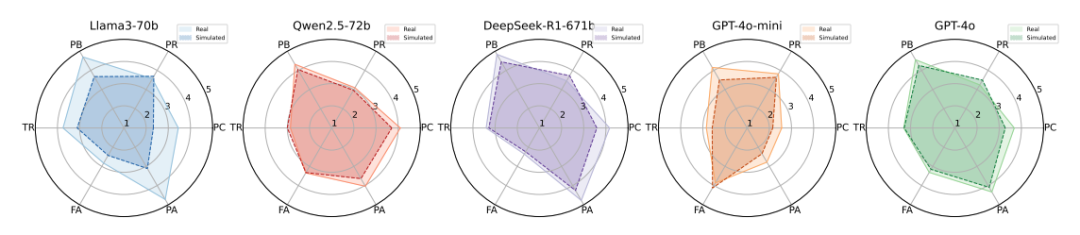
图 3. 突发新闻反馈情景中大模型表现。
AI社会科学的未来图景
SocioVerse的突破不仅在于技术架构,更在于其方法论启示。通过将传统社会科学的抽样调查转化为可编程的虚拟实验,研究者能低成本测试政策效果:比如调整最低工资后不同收入阶层的消费弹性变化,或新政策在不同意识形态群体中的传播阻力。
框架的局限性同样值得关注:LLM固有的保守倾向可能导致模拟结果偏离现实极端事件;在模拟少数族裔等长尾群体时,数据偏差可能被算法放大。未来还将探索专家LLM(Domain-specific LLM)与强化学习的结合,在医疗政策模拟等专业场景中突破现有瓶颈。
大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









