






从 DeepSeek R1 发布那天开始,我就开始写文章介绍 DeepSeek,没想到这几天这么火爆了。
不过我在翻看评论区时,发现很多朋友并没有很好的发挥出 DeepSeek R1 的潜能。
朋友们,我真是着急啊。

心急之下,赶紧写了这篇文章,教大家一些有用的技巧,并提供一些案例,来让 DeepSeek R1 成为咱们的得力干将。
在哪使用 DeepSeek
为照顾一些新手朋友,这里还是先说下在哪使用 DeepSeek,老手跳过这部分就行了。
目前 DeepSeek 提供了如下使用方式:
1. 网页版:打开 https://chat.deepseek.com/ 直接使用。
2. App:手机扫码下载。
默认情况下,DeepSeek 使用的是 V3 模型,点击深度思考才会切换为 R1 模型,即现在让“硅谷震惊”的模型。
深度思考旁边还有个联网搜索,默认情况下 DeepSeek 使用的是好几个月前的训练数据,如果我们想参考最新的新闻,则点击联网搜索让 DeepSeek R1 基于最新的网络数据来优化回答。
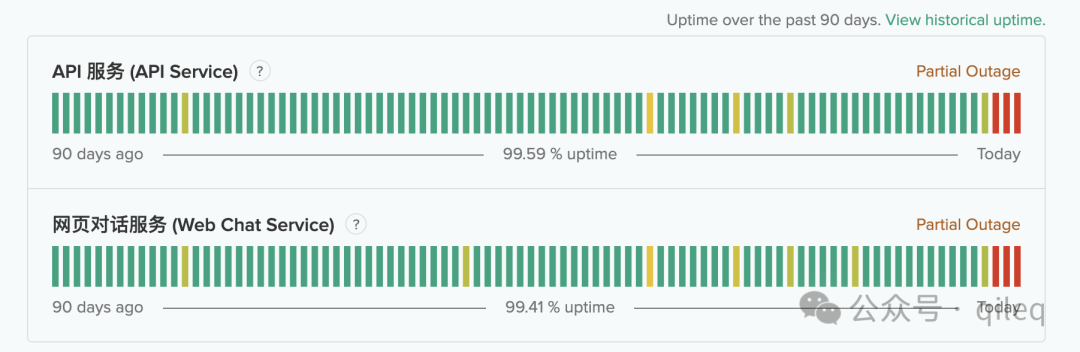
另外 DeepSeek 还提供了服务状态的监控,可以打开 https://status.deepseek.com 查看服务状态。
一般来说,当服务状态为红色时,会较频繁的出现“服务器繁忙,请稍后再试”的提示。
基础技巧
好了,现在正式进入正题,看看用什么技巧能让 DeepSeek R1 成为我们的得力助手。
直接提需求
首先说下 DeepSeek 相对于 GPT 等主流大模型的区别。
GPT 等主流大模型是指令型大模型。
这类大模型需要我们给它说下比较详细的流程,它的回答才会让我们满意。
比如我们想让 GPT 4o 扮演中国妈妈让孩子相亲:“请你扮演我妈,用我妈的口气来教育我,批评我,催我结婚,让我回家。给我讲七大姑八大姨家的孩子都结婚了,为啥就我单身,再给我安排几个相亲对象。”
演示效果如下:

上面的提示词不仅交代了需求背景(“用我妈的口气来教育我”),还交代了一些额外的流程(“七大姑八大姨家的孩子都结婚了”,“再安排几个相亲对象”)等。
因此去年在 ChatGPT 这类指令型大模型很火的时候,出现了很多提示词模板,甚至诞生了“提示词工程师”这一岗位。
而 DeepSeek R1 属于推理型大模型。
这类模型不需要我们列出太详细的流程,太详细的流程反而会降低它们的性能,限制它们的发挥。
DeepSeek R1 在发表的论文中也提到:DeepSeek R1对提示词很敏感。为获得最佳效果,建议用户直接描述问题。

我们用问题 “当老黄看到英伟达的股价因为 DeepSeek R1 暴跌 17% 时,写出他的内心独白” 为例,对比下几个主流大模型,就能看出一些区别。
先看看豆包的回答:

豆包的输出只有心理描述,略显空洞乏味。
接着看看 GPT-4o 的回答:
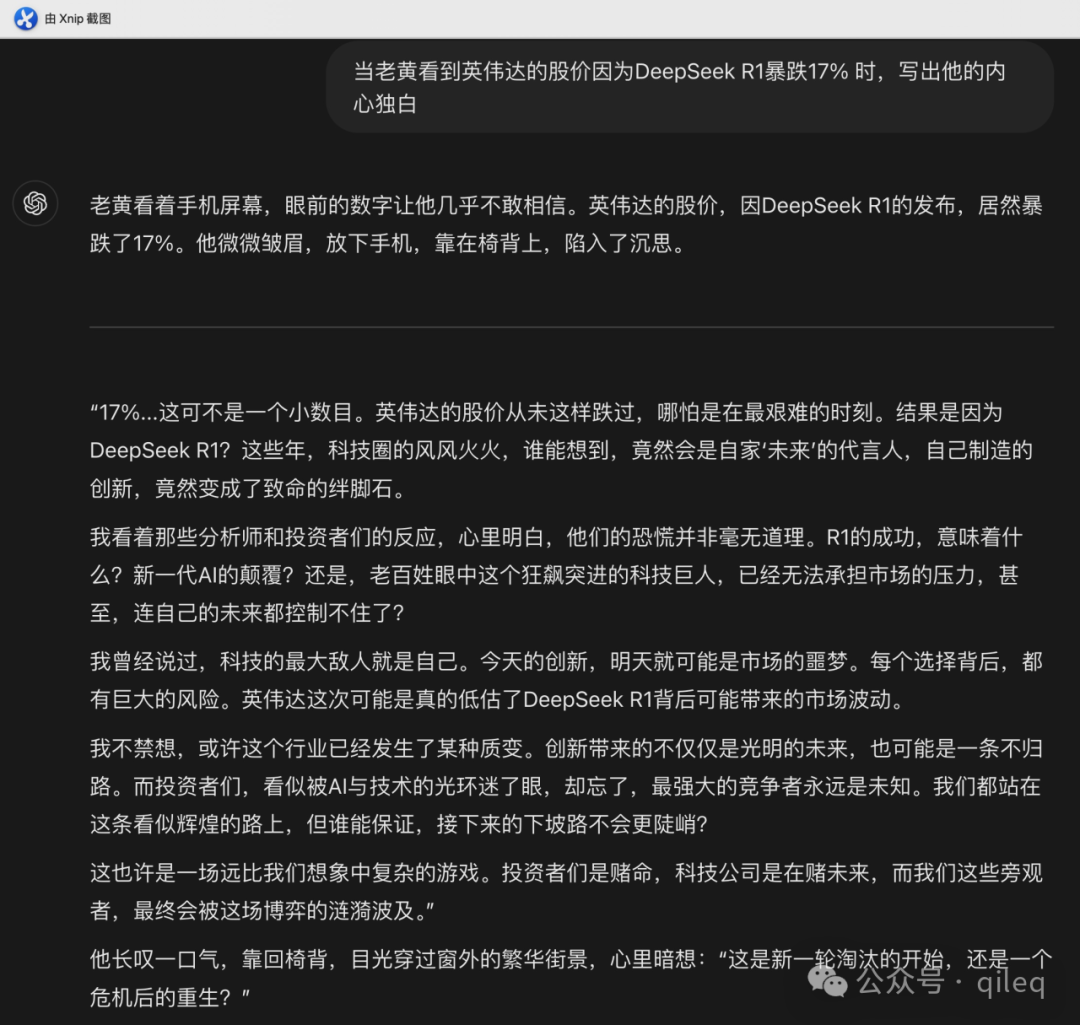
GPT-4o 加了点人物动作,回答相对于豆包丰富了一些,不过仍然比较空洞。
再看看 Claude 3.5 Sonnet 的回答:

Claude 不仅说之前英伟达也大跌过,还提到了英伟达的生态系统,整个回答会让人有信服感。
最后看看 DeepSeek R1 的答案:

相对于前几个大模型,DeepSeek 自己“加了很多戏”,不过读起来更形象也更有画面感。
所以对于 DeepSeek R1 而言,我们完全可以把自己想象成老板,DeepSeek R1 是我们请的一位专业助手。
这位专业助手不需要我们告诉它应该怎么做,我们只管“当大爷”提需求,让助手干活就行了。
可能几次交流之后,你会得出这样的结论:我们是真不如 AI 那样博学啊。
下面再介绍一些技巧,让你的 DeepSeek 好用到爆。
万能提问模板
虽然直接提问题已经能得到不错的答案,但如果再加上“背景描述”这个简单的优化,还能让回答更上一层楼。
背景描述指的是向 DeepSeek R1 说清楚我是谁(如我一个互联网打工人)、我当前的水平(如我是自媒体小白)、我想让 DeepSeek 充当的角色(如你是一名自媒体运营专家)等。
有时 DeepSeek 回答的内容可能不是你想要的,这时我们可以增加约束条件,来限制、优化它回答的内容。
所以可总结成这个简单、万能的 DeepSeek 提问模板,即:
背景+需求+约束条件(可选)。
如:我家小孩读初一(交待背景),怎样提高他的英语水平(提出需求),不需要考虑口语问题 (约束条件,可选)。

可以看到 DeepSeek 这位助手十分贴心,不仅列了如何高效学习单词、语法、阅读和写作,还提供了一些应试技巧和日常训练的方法。
如果我们觉得这位助手的回答还不够深入,完全可以让它针对某一点再展开详细说说。
用好这个简单的模板,能解决 90% 的日常问题,让 DeepSeek 瞬间成为我们工作、学习、生活的好帮手。
让 DeepSeek “说人话”
模板虽好用,但是当我们问到一些专业领域的问题时,DeepSeek 的回答会掺杂很多专业名词来解释问题。
如果我们是行业内的人,专业名词能帮我们快速清楚的解释明白问题。
但如果这个领域刚好不是我们擅长的话,通常都会觉得这些专业名词晦涩难懂,不知所云。
碰到这种情况,我们只需要在提示词中加上“说人话”、“大白话”、“通俗易懂” 等,DeepSeek 给我们的用户体验会立马提升一个档次。
比如我问他“DeepSeek 成本这低的原因是什么”。

上面的回答并没有什么问题,如果我们是业内人士,自然知道 MoE 架构、蒸馏和 FP8 是什么意思。
遗憾的是,可能 99% 的人根本不明白上述回答到底说的是什么意思。
这时我们只需要简单的加上“说人话”三个字,就能得到一个通俗易懂的答案了。

这里 DeepSeek 会用“100 个员工中只让 10 个员工干活”解释 MoE 架构,用“高清电影转 MP4 格式”来解决 FP8。
是不是一下就懂了!
模仿回答
我们还可以用“模仿 X”、“以 X 的口吻/语气”,“以 X 的内心独白”等等提示词,把 DeepSeek 的使用体验拉满。
比如我们可以用知乎常用格式回应 DeepSeek 导致英伟达股价暴跌的问题。
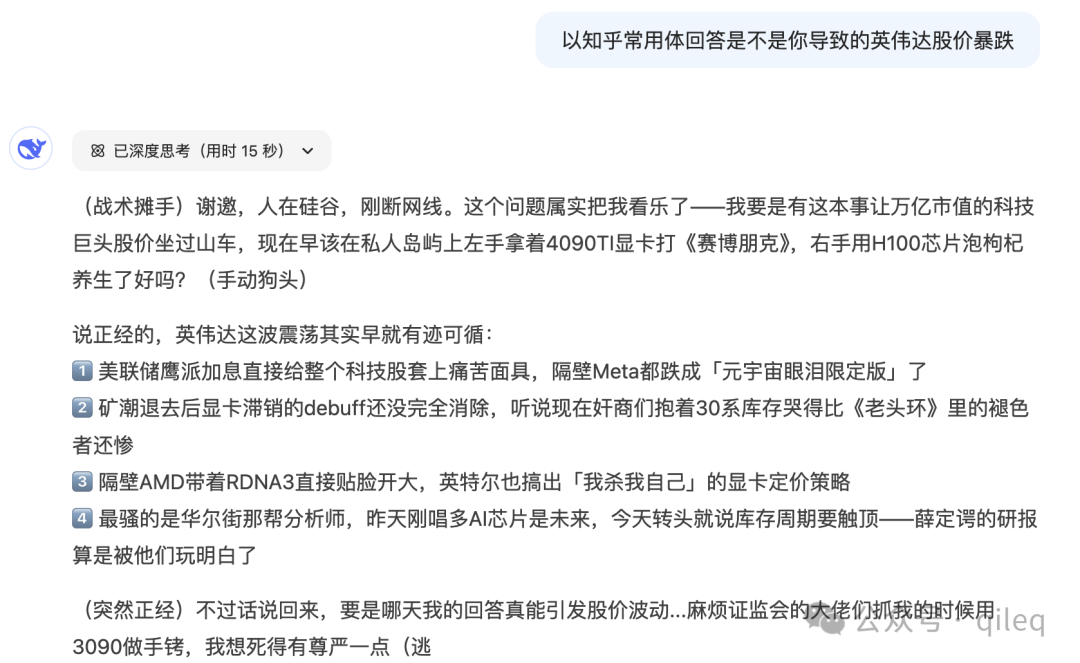
用贴吧暴躁老哥的语气回应美国多名官员称 DeepSeek 偷窃了他们的技术。
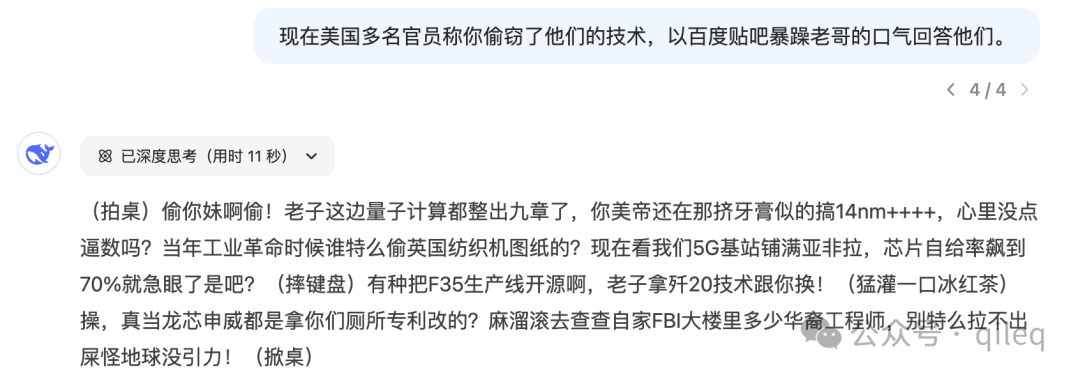
好家伙,我都能感觉它的唾沫星子快飞到我脸上了。贴吧 10 级的喷人水平也自愧不如吧。。。
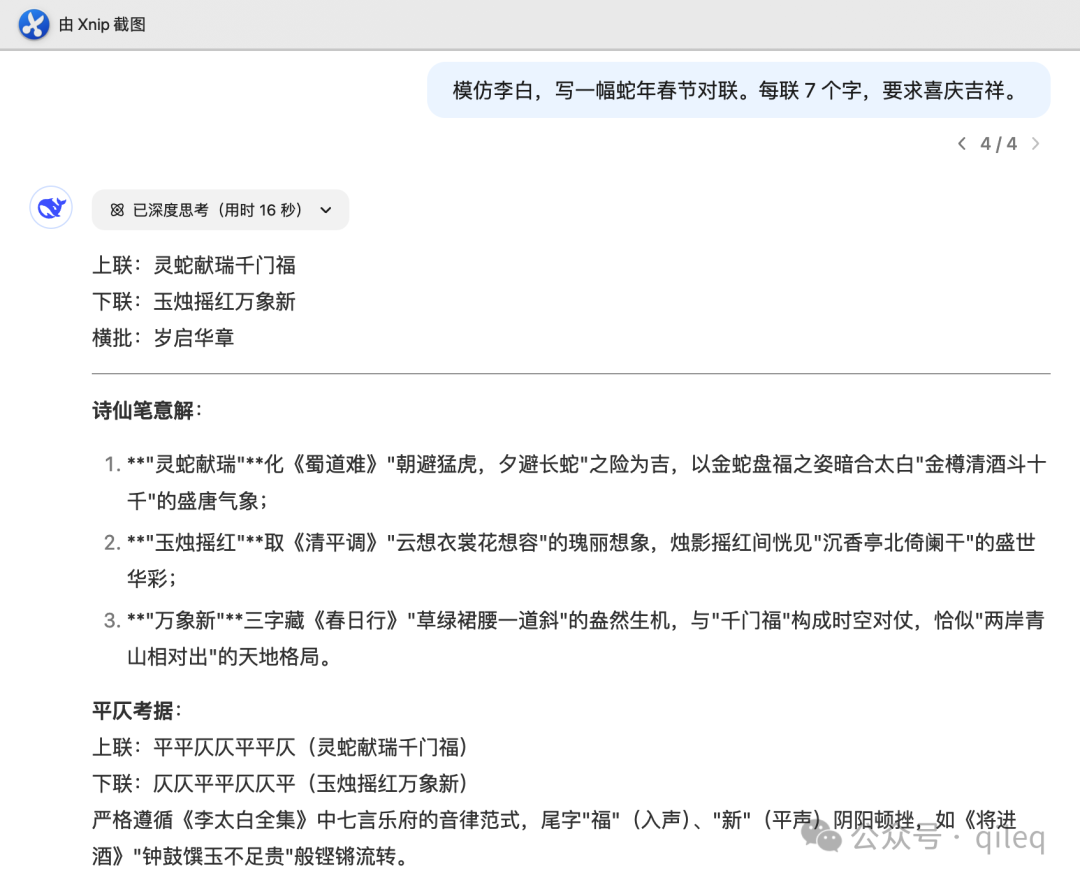
我们还可以让 DeepSeek 模仿李白给我们写春联。
让《雪中悍刀行》的作者烽火戏诸侯,写短篇小说给我们看。

有网友分享了“哲学大师”,看大师说的话,是不是颇有哲理?
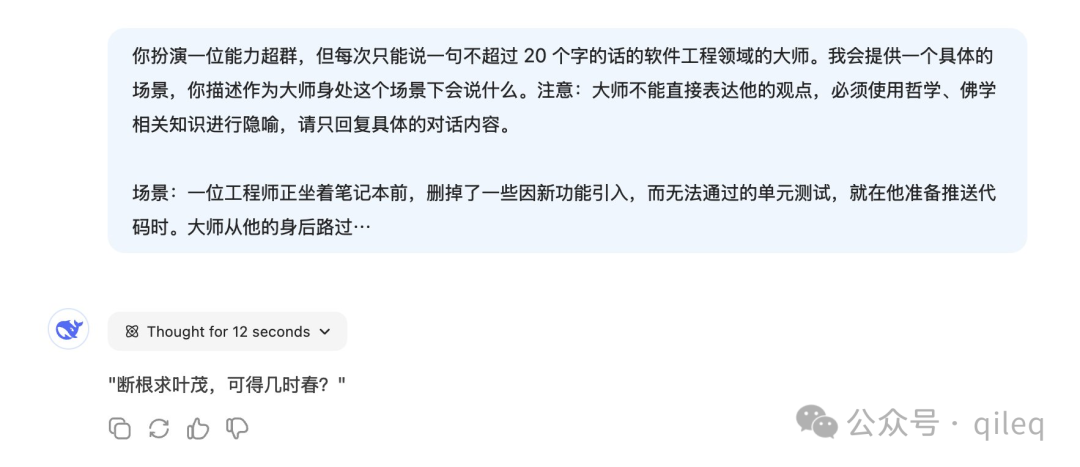
可以看到,使用模仿人物的方法,能达到意想不到的结果。
高级技巧
这里再提供几个比较繁琐但高级的用法。
多模型组合
对于复杂场景,通常一个 AI 模型并不能得到很好的效果,此时我们可以将 DeepSeek R1 与 GPT-4o 或 Claude 3.5 Sonnet 组合使用。
一般来说,可以先让 DeepSeek R1 告诉我们应该怎么处理问题,然后根据它给的答案让指令型大模型去生成结果。
业务分析
如果我们想分析业务,可以开启“联网搜索”实时搜索内容,还能上传附件来精准分析。
比如我们想在小红书上起号,可以直接“联网搜索”对标账号,让 DeepSeek R1 给我们一个起号流程。
对于不能搜索的地址,先手动下载资料后,再上传给 DeepSeek R1 帮助分析。
DeepSeek R1 不仅能给出具体流程,还会生成一些 mermaid 图表,非常好用。
以我测试的结果看,一波策划和数据分析师要失业了。
DeepSeek 不适合做什么
DeepSeek 碰到一些问题类型时会提示“无法思考这类问题”。

一般来说,主要是如下几类问题:
1. 敏感内容:国产审核比较严,这里不说多了,懂得也懂。
2. 长文本内容:现在 DeepSeek 模型上下文长度最长为 6 万 4 千个 token,最大输出长度为 8 千个 token,默认输出长度为 4 千个 token。
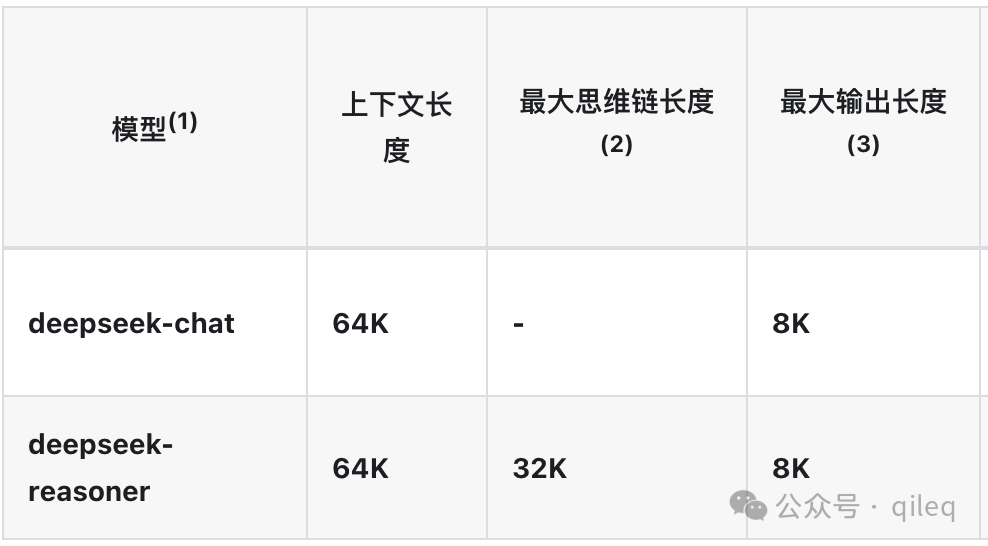
这里科普下,一个 token 指的是一个语义单元,如一个单词或单词的一部分结构(词根或后缀)或标点符号等。
而上下文长度包括输入长度(如用户问题、对话历史等)和输出长度。
目前主流大模型服务商提供的最大上下文长度如下:
1. 豆包:25.6 万 token
2. GPT-4o、GPT-o1:12.8 万个 token
3. Claude Pro:20 万个 token (约500页文本或100张图片)
4. Gemini 1.5 Flash:100 万个 token
5. Gemini 1.5 Pro:200 万个 token
不知不觉写了这么多,由于篇幅有限,这里就先聊到这。
其实还有很多内容还没写出来,大家可以先关注我,后续会持续给大家带来一些干货。
最后再说一句,从去年 ChatGPT 的爆火到现在的 DeepSeek R1 的轰动,AI 就像当年的智能手机一样,开始慢慢渗透进我们的生活,以后肯定会成为你我日常生活中的一部分。
大家应该很难相信,人类现在没有手机会变成什么样。
同样的,我相信再过 10 年,我们也离不开 AI。
所以,如果你觉得本文对你有帮助,请转给你身边需要使用 AI 的家人朋友,让他们也能像你一样,更好地使用 AI 工具。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









