






一、什么是Embedding
大模型(Large Language Models, LLMs)正以前所未有的速度改变着人类与机器交互的方式。而这些模型能够理解自然语言、生成创意内容,甚至进行复杂的推理决策,其背后就是一项核心技术——Embedding(嵌入)。它扮演着“神经中枢”的角色,像一座桥梁,将人类世界的离散符号(如文字、图像)转化为机器能够理解的连续向量,使大模型得以“思考”和“创作”。
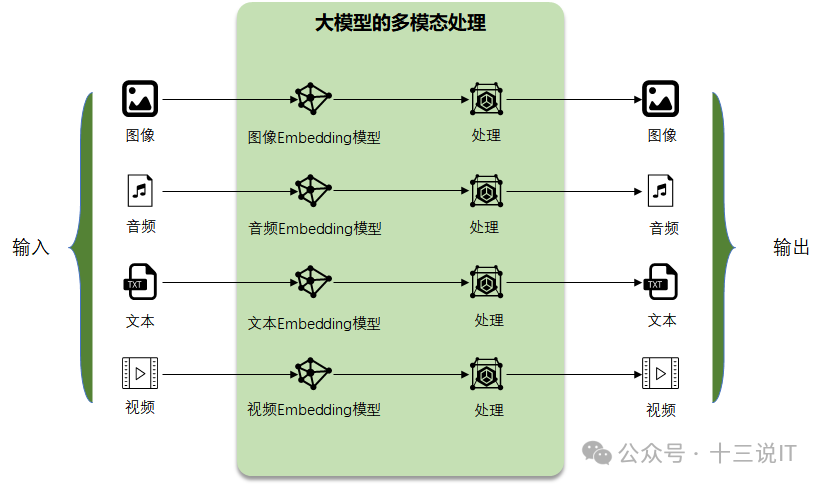
最简单的理解,Embedding就是大模型自己的语言,任何需要跟大模型沟通的文字、图像、视频都需要转换为大模型所能理解的语言:Embedding,它才能处理。处理完成后,它再翻译成人类能理解的文字、图像等。这也是大模型最强大的核心能力之一,多模态处理能力。
二、Embedding的起源与发展:从语言学理论到深度学习革命
1. 语言学根基:分布式语义理论的提出
Embedding的思想最早可追溯至1954年,语言学家Zellig Harris提出的分布式语义理论。该理论认为,单词的语义由其上下文分布决定——“You shall know a word by the company it keeps”(通过单词的上下文可以推断其含义)。例如,“猫”和“狗”经常出现在“宠物”“喂食”等相似上下文中,因此它们的语义应相近。这一理论为通过统计词频捕捉语义关系奠定了基础。
2. 深度学习突破:Word2Vec的崛起
2013年,Mikolov团队提出的Word2Vec算法成为Embedding发展的里程碑。它通过神经网络训练词向量,将每个单词映射为一个低维稠密向量,使语义相似的词在向量空间中距离接近。例如,“国王 - 男人 + 女人 ≈ 女王”的向量运算,直观体现了语义关系的捕捉。Word2Vec的开源实现推动了工业界对词嵌入技术的重视,开启了NLP任务的新纪元。
3. 动态嵌入的兴起:BERT与GPT的上下文感知
静态词嵌入(如Word2Vec)无法解决一词多义问题(如“银行”既指金融机构,也指河岸)。2018年,BERT模型通过双向Transformer架构,生成上下文相关的Embedding,根据句子动态调整词向量。例如,在“我用苹果手机支付”和“我吃苹果”中,“苹果”的向量会因上下文不同而区分。这种动态嵌入显著提升了语义理解能力,成为大模型的标准配置。
4. 多模态扩展:图像、语音与图结构的嵌入
随着深度学习的发展,Embedding从文本扩展到多模态数据。例如:
图像嵌入:ResNet等模型将图像映射为向量,实现图像分类与检索。
语音嵌入:Wav2Vec 2.0将语音波形转换为语义向量,支持语音识别。
图嵌入:Node2Vec、DeepWalk等算法将社交网络中的节点(如用户)表示为向量,用于推荐系统。
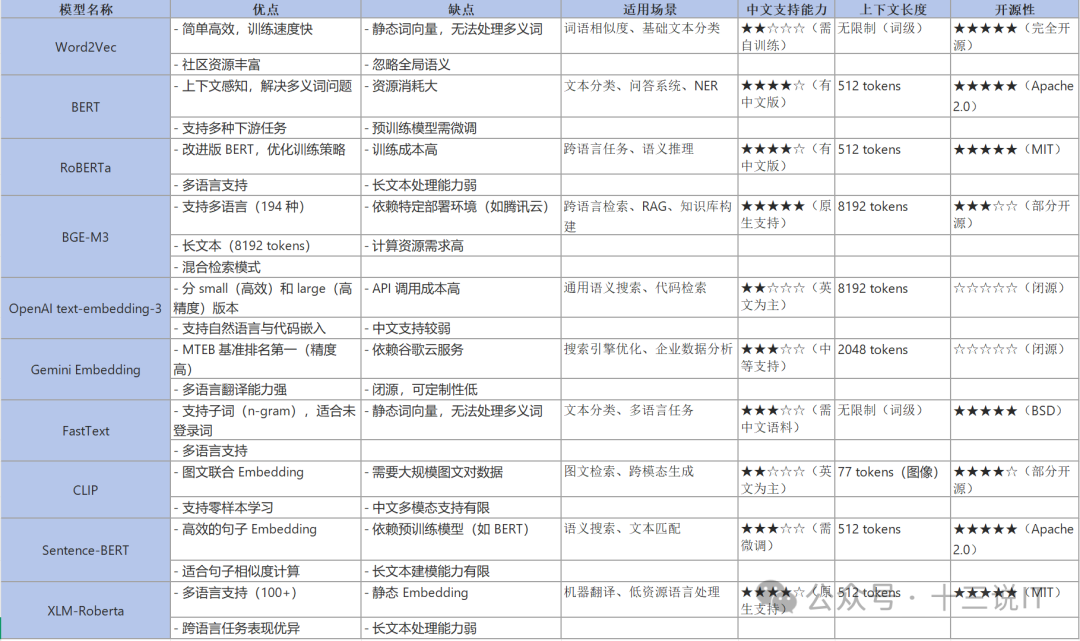
三、常见的Embedding模型:
已经有很多成熟的Embedding模型,下面是一些比较常见的模型:
四、进一步解读
从核心上来说,嵌入(embedding)是一种映射,它将诸如单词、图像甚至整篇文档等离散对象映射到连续向量空间中的点。嵌入的主要目的是将非数值数据转换为神经网络能够处理的格式。
虽然词嵌入(word embeddings)是最常见的文本嵌入形式,但还存在针对句子、段落或整篇文档的嵌入。句子或段落嵌入是检索增强生成(retrieval-augmented generation)的流行选择。检索增强生成将生成(如生成文本)与检索(如搜索外部知识库)相结合,以便在生成文本时提取相关信息。
当选择的embeddings为二维的时候,就是将词汇投影到二维空间,这时可以进行可视化绘制,从而观测出最直观的现象:相似的术语会聚集在一起。
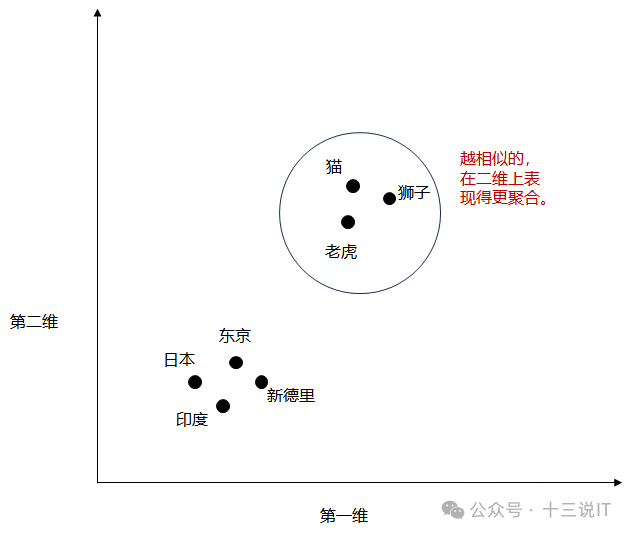
*如果词嵌入是二维的,将它们绘制成二维散点图以便可视化。在使用词嵌入技术(如Word2Vec)时,对应相似概念的单词在嵌入空间中通常会彼此靠近。例如,不同类型的动物在嵌入空间中彼此之间的距离,比它们与国家或城市之间的距离更近。词嵌入的维度可以从一维到数千维不等。更高的维度可能会捕捉到更细微的关系,但会牺牲计算效率。
*高维Embedding对可视化提出了挑战,因为感官感知和常见的图形表示本质上局限于三维或更少,这就是为什么在二维散点图中展示二维嵌入的原因。然而,在使用LLMs时,我们通常会使用维度高得多的嵌入。对于GPT-2和GPT-3,Embedding大小(通常称为模型隐藏状态的维度)因模型的具体变种和大小而异。这是性能与效率之间的权衡。最小的GPT-2模型(117M和125M参数)使用768维的嵌入大小来提供具体的示例。最大的GPT-3模型(175B参数)使用12288维的嵌入大小。
五、大模型处理的高阶流程
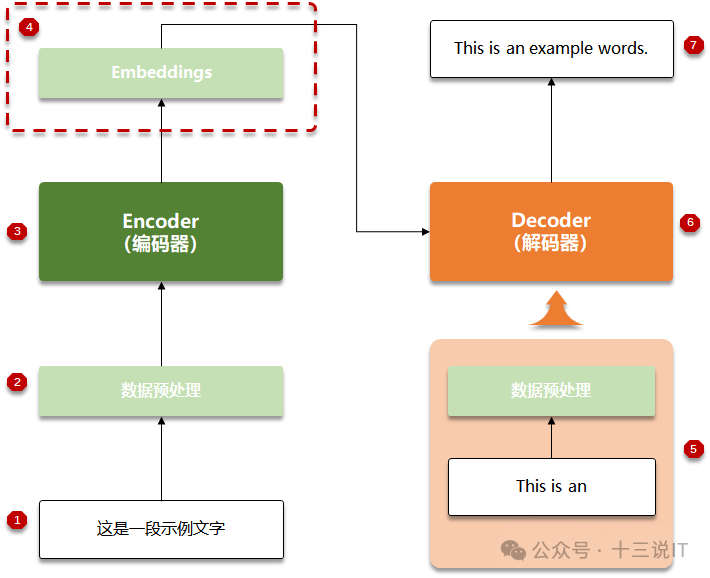
图中所示的步骤是使用Transformer作为语言翻译的典型流程图。
-
待翻译的文字;
-
在进入Encoder前的预处理;
-
Encoder对文字进行Encoding处理;
-
Embeddings就是Encoder的结果,是原来文字的向量化表示;
-
Decoder的部分输出,每次执行翻译一个单词;
-
Decoder一次仅生成一次翻译;
-
最后翻译的结果。
总结下来,就只有两个关键步骤:
-
使用Encoder将输入转换为Embeddings;
-
使用Decoder对Embeddings进行处理,并将Embeddings表示的结果转换为输出结果。
六、一个示例:将文本转换为Embedding
这里给出一个最简单的Embedding示例,不采用任何已有的Embedding模型框架。其主体流程如下:
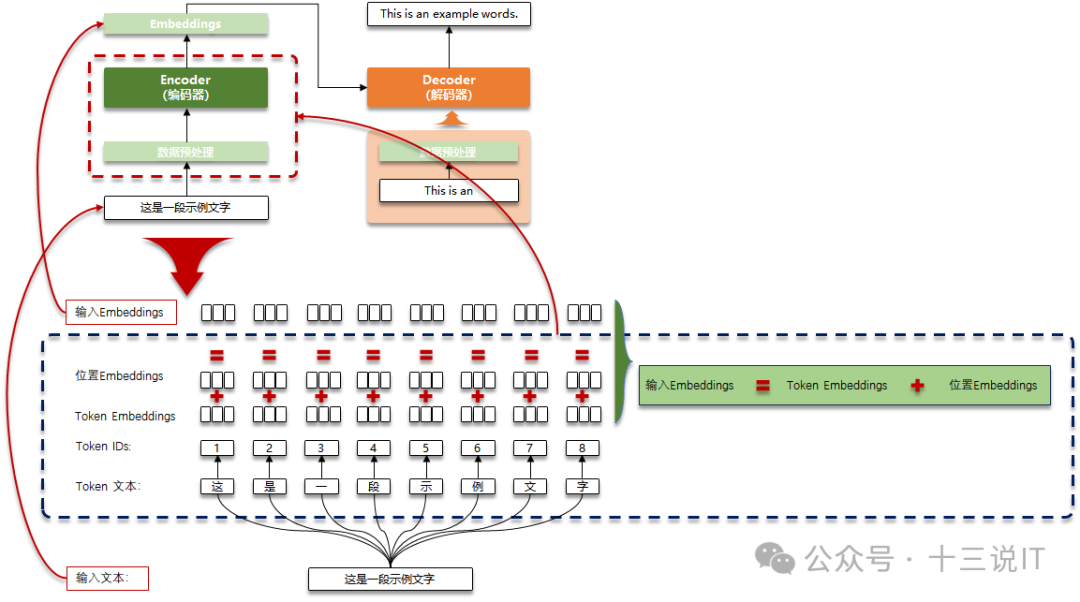
*这里加入了位置Embeddings,这是LLM自注意力机制的关键点之一,这里不对此展开。
示例代码:
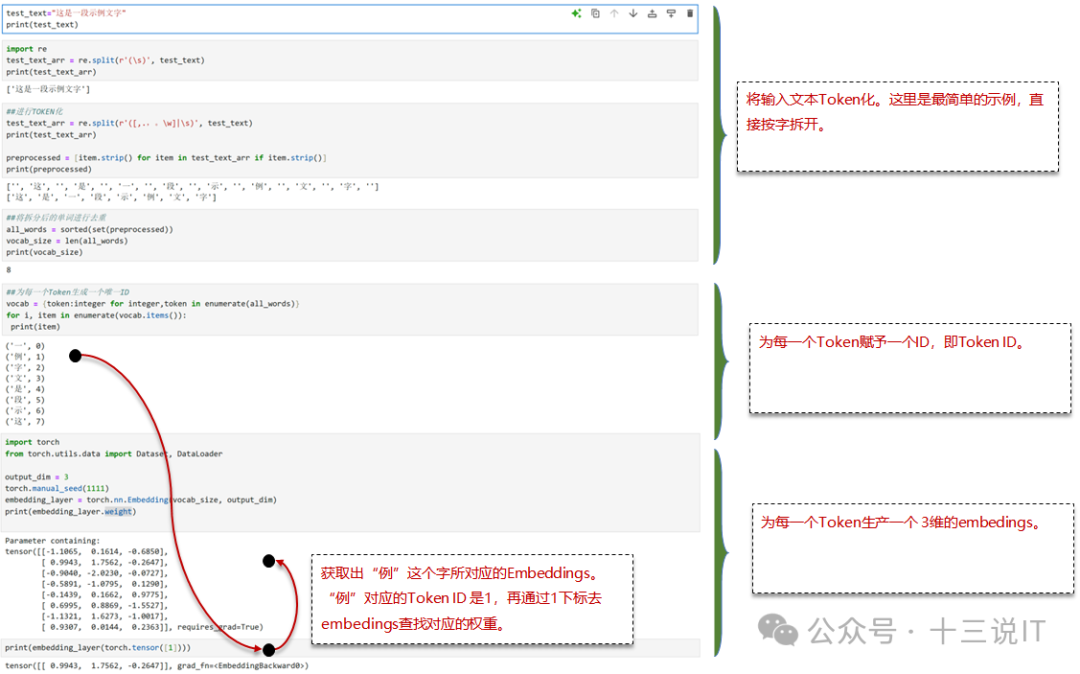
test_text="这是一段示例文字"print(test_text)import retest_text_arr = re.split(r'(\s)', test_text)print(test_text_arr)##进行TOKEN化test_text_arr = re.split(r'([,.,。\w]|\s)', test_text)print(test_text_arr)preprocessed = [item.strip() for item in test_text_arr if item.strip()]print(preprocessed)##将拆分后的单词进行去重all_words = sorted(set(preprocessed))vocab_size = len(all_words)print(vocab_size)##为每一个Token生成一个唯一IDvocab = {token:integer for integer,token in enumerate(all_words)}for i, item in enumerate(vocab.items()):print(item)import torchfrom torch.utils.data import Dataset, DataLoader##生成3维的embeddingoutput_dim = 3##使用制定的种子,确保可以复现torch.manual_seed(1111)embedding_layer = torch.nn.Embedding(vocab_size, output_dim)print(embedding_layer.weight)#取第2个Token的embedding,python是从0开始。前面每一个TokenID都可以作为下标从而Embedings矩阵中获取。print(embedding_layer(torch.tensor([1])))
七、后记
每天学习和理解一点点大模型。但是这玩意好难。好好学习,天天向上吧。
八、参考资料


大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









