







 本文介绍了如何在Python环境下使用多线程爬虫,包括HTTP协议、threading模块、Queue队列、getopt模块、hashlib和json等技术。同时强调了系统化学习的重要性,提供了丰富的学习资源和社群支持,帮助读者避免浅尝辄止,实现技术提升。
本文介绍了如何在Python环境下使用多线程爬虫,包括HTTP协议、threading模块、Queue队列、getopt模块、hashlib和json等技术。同时强调了系统化学习的重要性,提供了丰富的学习资源和社群支持,帮助读者避免浅尝辄止,实现技术提升。
最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
代码在Windows7 64bit,python 2.7 64bit(安装mysqldb扩展)以及centos 6.5,python 2.7(带mysqldb扩展)环境下测试通过
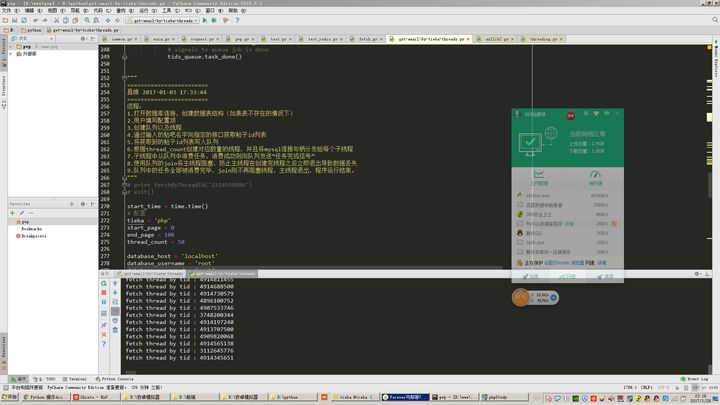
github:https://github.com/cw1997/get-email-by-tieba/blob/master/get-email-by-tieba-multithreading.py
环境准备:
工欲善其事必先利其器,大家可以从截图看出我的环境是Windows 7 + PyCharm。我的Python环境是Python 2.7 64bit。这是比较适合新手使用的开发环境。然后我再建议大家安装一个easy_install,听名字就知道这是一个安装器,它是用来安装一些扩展包的,比如说在python中如果我们要操作mysql数据库的话,python原生是不支持的,我们必须安装mysqldb包来让python可以操作mysql数据库,如果有easy_install的话我们只需要一行命令就可以快速安装号mysqldb扩展包,他就像php中的composer,centos中的yum,Ubuntu中的apt-get一样方便。
相关工具可在我的github中找到:cw1997/python-tools,其中easy_install的安装只需要在python命令行下运行那个py脚本然后稍等片刻即可,他会自动加入Windows的环境变量,在Windows命令行下如果输入easy_install有回显说明安装成功。
环境选择的细节说明:
至于电脑硬件当然是越快越好,内存起码8G起步,因为爬虫本身需要大量存储和解析中间数据,尤其是多线程爬虫,在碰到抓取带有分页的列表和详情页,并且抓取数据量很大的情况下使用queue队列分配抓取任务会非常占内存。包括有的时候我们抓取的数据是使用json,如果使用mongodb等nosql数据库存储,也会很占内存。
网络连接建议使用有线网,因为市面上一些劣质的无线路由器和普通的民用无线网卡在线程开的比较大的情况下会出现间歇性断网或者数据丢失,掉包等情况,这个我亲有体会。
至于操作系统和python当然肯定是选择64位。如果你使用的是32位的操作系统,那么无法使用大内存。如果你使用的是32位的python,可能在小规模抓取数据的时候感觉不出有什么问题,但是当数据量变大的时候,比如说某个列表,队列,字典里面存储了大量数据,导致python的内存占用超过2g的时候会报内存溢出错误。原因在我曾经segmentfault上提过的问题中依云的回答有解释(java - python只要占用内存达到1.9G之后httplib模块就开始报内存溢出错误 - SegmentFault)
如果你准备使用mysql存储数据,建议使用mysql5.5以后的版本,因为mysql5.5版本支持json数据类型,这样的话可以抛弃mongodb了。(有人说mysql会比mongodb稳定一点,这个我不确定。)
至于现在python都已经出了3.x版本了,为什么我这里还使用的是python2.7?我个人选择2.7版本的原因是自己当初很早以前买的python核心编程这本书是第二版的,仍然以2.7为示例版本。并且目前网上仍然有大量的教程资料是以2.7为版本讲解,2.7在某些方面与3.x还是有很大差别,如果我们没有学过2.7,可能对于一些细微的语法差别不是很懂会导致我们理解上出现偏差,或者看不懂demo代码。而且现在还是有部分依赖包只兼容2.7版本。我的建议是如果你是准备急着学python然后去公司工作,并且公司没有老代码需要维护,那么可以考虑直接上手3.x,如果你有比较充裕的时间,并且没有很系统的大牛带,只能依靠网上零零散散的博客文章来学习,那么还是先学2.7在学3.x,毕竟学会了2.7之后3.x上手也很快。
多线程爬虫涉及到的知识点:
其实对于任何软件项目而言,我们凡是想知道编写这个项目需要什么知识点,我们都可以观察一下这个项目的主要入口文件都导入了哪些包。
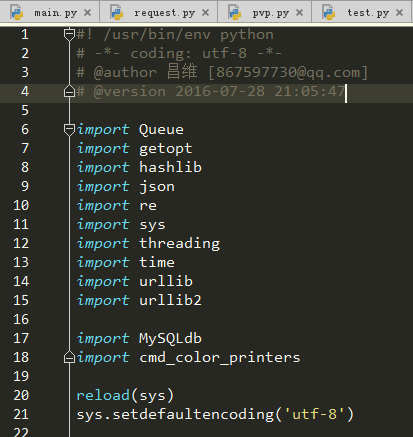
现在来看一下我们这个项目,作为一个刚接触python的人,可能有一些包几乎都没有用过,那么我们在本小节就来简单的说说这些包起什么作用,要掌握他们分别会涉及到什么知识点,这些知识点的关键词是什么。这篇文章并不会花费长篇大论来从基础讲起,因此我们要学会善用百度,搜索这些知识点的关键词来自学。下面就来一一分析一下这些知识点。
HTTP协议:
我们的爬虫抓取数据本质上就是不停的发起http请求,获取http响应,将其存入我们的电脑中。了解http协议有助于我们在抓取数据的时候对一些能够加速抓取速度的参数能够精准的控制,比如说keep-alive等。
threading模块(多线程):
我们平时编写的程序都是单线程程序,我们写的代码都在主线程里面运行,这个主线程又运行在python进程中。关于线程和进程的解释可以参考阮一峰的博客:进程与线程的一个简单解释 - 阮一峰的网络日志
在python中实现多线程是通过一个名字叫做threading的模块来实现。之前还有thread模块,但是threading对于线程的控制更强,因此我们后来都改用threading来实现多线程编程了。
关于threading多线程的一些用法,我觉得这篇文章不错:[python] 专题八.多线程编程之thread和threading 大家可以参考参考。
简单来说,使用threading模块编写多线程程序,就是先自己定义一个类,然后这个类要继承threading.Thread,并且把每个线程要做的工作代码写到一个类的run方法中,当然如果线程本身在创建的时候如果要做一些初始化工作,那么就要在他的__init__方法中编写好初始化工作所要执行的代码,这个方法就像php,java中的构造方法一样。
这里还要额外讲的一点就是线程安全这个概念。通常情况下我们单线程情况下每个时刻只有一个线程在对资源(文件,变量)操作,所以不可能会出现冲突。但是当多线程的情况下,可能会出现同一个时刻两个线程在操作同一个资源,导致资源损坏,所以我们需要一种机制来解决这种冲突带来的破坏,通常有加锁等操作,比如说mysql数据库的innodb表引擎有行级锁等,文件操作有读取锁等等,这些都是他们的程序底层帮我们完成了。所以我们通常只要知道那些操作,或者那些程序对于线程安全问题做了处理,然后就可以在多线程编程中去使用它们了。而这种考虑到线程安全问题的程序一般就叫做“线程安全版本”,比如说php就有TS版本,这个TS就是Thread Safety线程安全的意思。下面我们要讲到的Queue模块就是一种线程安全的队列数据结构,所以我们可以放心的在多线程编程中使用它。
最后我们就要来讲讲至关重要的线程阻塞这个概念了。当我们详细学习完threading模块之后,大概就知道如何创建和启动线程了。但是如果我们把线程创建好了,然后调用了start方法,那么我们会发现好像整个程序立马就结束了,这是怎么回事呢?其实这是因为我们在主线程中只有负责启动子线程的代码,也就意味着主线程只有启动子线程的功能,至于子线程执行的那些代码,他们本质上只是写在类里面的一个方法,并没在主线程里面真正去执行他,所以主线程启动完子线程之后他的本职工作就已经全部完成了,已经光荣退场了。既然主线程都退场了,那么python进程就跟着结束了,那么其他线程也就没有内存空间继续执行了。所以我们应该是要让主线程大哥等到所有的子线程小弟全部执行完毕再光荣退场,那么在线程对象中有什么方法能够把主线程卡住呢?thread.sleep嘛?这确实是个办法,但是究竟应该让主线程sleep多久呢?我们并不能准确知道执行完一个任务要多久时间,肯定不能用这个办法。所以我们这个时候应该上网查询一下有什么办法能够让子线程“卡住”主线程呢?“卡住”这个词好像太粗鄙了,其实说专业一点,应该叫做“阻塞”,所以我们可以查询“python 子线程阻塞主线程”,如果我们会正确使用搜索引擎的话,应该会查到一个方法叫做join(),没错,这个join()方法就是子线程用于阻塞主线程的方法,当子线程还未执行完毕的时候,主线程运行到含有join()方法的这一行就会卡在那里,直到所有线程都执行完毕才会执行join()方法后面的代码。
Queue模块(队列):
假设有一个这样的场景,我们需要抓取一个人的博客,我们知道这个人的博客有两个页面,一个list.php页面显示的是此博客的所有文章链接,还有一个view.php页面显示的是一篇文章的具体内容。
如果我们要把这个人的博客里面所有文章内容抓取下来,编写单线程爬虫的思路是:先用正则表达式把这个list.php页面的所有链接a标签的href属性抓取下来,存入一个名字叫做article_list的数组(在python中不叫数组,叫做list,中文名列表),然后再用一个for循环遍历这个article_list数组,用各种抓取网页内容的函数把内容抓取下来然后存入数据库。
如果我们要编写一个多线程爬虫来完成这个任务的话,就假设我们的程序用10个线程把,那么我们就要想办法把之前抓取的article_list平均分成10份,分别把每一份分配给其中一个子线程。
但是问题来了,如果我们的article_list数组长度不是10的倍数,也就是文章数量并不是10的整数倍,那么最后一个线程就会比别的线程少分配到一些任务,那么它将会更快的结束。
如果仅仅是抓取这种只有几千字的博客文章这看似没什么问题,但是如果我们一个任务(不一定是抓取网页的任务,有可能是数学计算,或者图形渲染等等耗时任务)的运行时间很长,那么这将造成极大地资源和时间浪费。我们多线程的目的就是尽可能的利用一切计算资源并且计算时间,所以我们要想办法让任务能够更加科学合理的分配。
并且我还要考虑一种情况,就是文章数量很大的情况下,我们要既能快速抓取到文章内容,又能尽快的看到我们已经抓取到的内容,这种需求在很多CMS采集站上经常会体现出来。
比如说我们现在要抓取的目标博客,有几千万篇文章,通常这种情况下博客都会做分页处理,那么我们如果按照上面的传统思路先抓取完list.php的所有页面起码就要几个小时甚至几天,老板如果希望你能够尽快显示出抓取内容,并且尽快将已经抓取到的内容展现到我们的CMS采集站上,那么我们就要实现一边抓取list.php并且把已经抓取到的数据丢入一个article_list数组,一边用另一个线程从article_list数组中提取已经抓取到的文章URL地址,然后这个线程再去对应的URL地址中用正则表达式取到博客文章内容。如何实现这个功能呢?
我们就需要同时开启两类线程,一类线程专门负责抓取list.php中的url然后丢入article_list数组,另外一类线程专门负责从article_list中提取出url然后从对应的view.php页面中抓取出对应的博客内容。
但是我们是否还记得前面提到过线程安全这个概念?前一类线程一边往article_list数组中写入数据,另外那一类的线程从article_list中读取数据并且删除已经读取完毕的数据。但是python中list并不是线程安全版本的数据结构,因此这样操作会导致不可预料的错误。所以我们可以尝试使用一个更加方便且线程安全的数据结构,这就是我们的子标题中所提到的Queue队列数据结构。
同样Queue也有一个join()方法,这个join()方法其实和上一个小节所讲到的threading中join()方法差不多,只不过在Queue中,join()的阻塞条件是当队列不为空空的时候才阻塞,否则继续执行join()后面的代码。在这个爬虫中我便使用了这种方法来阻塞主线程而不是直接通过线程的join方式来阻塞主线程,这样的好处是可以不用写一个死循环来判断当前任务队列中是否还有未执行完的任务,让程序运行更加高效,也让代码更加优雅。
还有一个细节就是在python2.7中队列模块的名字是Queue,而在python3.x中已经改名为queue,就是首字母大小写的区别,大家如果是复制网上的代码,要记得这个小区别。
getopt模块:
如果大家学过c语言的话,对这个模块应该会很熟悉,他就是一个负责从命令行中的命令里面提取出附带参数的模块。比如说我们通常在命令行中操作mysql数据库,就是输入mysql -h127.0.0.1 -uroot -p,其中mysql后面的“-h127.0.0.1 -uroot -p”就是可以获取的参数部分。
我们平时在编写爬虫的时候,有一些参数是需要用户自己手动输入的,比如说mysql的主机IP,用户名密码等等。为了让我们的程序更加友好通用,有一些配置项是不需要硬编码在代码里面,而是在执行他的时候我们动态传入,结合getopt模块我们就可以实现这个功能。
hashlib(哈希):
哈希本质上就是一类数学算法的集合,这种数学算法有个特性就是你给定一个参数,他能够输出另外一个结果,虽然这个结果很短,但是他可以近似认为是独一无二的。比如说我们平时听过的md5,sha-1等等,他们都属于哈希算法。他们可以把一些文件,文字经过一系列的数学运算之后变成短短不到一百位的一段数字英文混合的字符串。
python中的hashlib模块就为我们封装好了这些数学运算函数,我们只需要简单的调用它就可以完成哈希运算。
为什么在我这个爬虫中用到了这个包呢?因为在一些接口请求中,服务器需要带上一些校验码,保证接口请求的数据没有被篡改或者丢失,这些校验码一般都是hash算法,所以我们需要用到这个模块来完成这种运算。
json:
很多时候我们抓取到的数据不是html,而是一些json数据,json本质上只是一段含有键值对的字符串,如果我们需要提取出其中特定的字符串,那么我们需要json这个模块来将这个json字符串转换为dict类型方便我们操作。

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









