







文末有福利领取哦~
👉一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉二、Python必备开发工具

👉三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末领读者福利)

👉五、Python练习题
检查学习结果。

👉六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
# 1、变量名与值内存地址的关联关系存放于栈区
# 2、变量值存放于堆区,内存管理回收的则是堆区的内容,
定义了两个变量x = 10、y = 20,详解如下图:
 当我们执行x=y时,内存中的栈区与堆区变化如下
当我们执行x=y时,内存中的栈区与堆区变化如下

三、直接引用和循环引用
直接引用指的是从栈区出发直接引用到的内存地址
间接引用指的是从栈区出发引用到堆区后,再通过进一步引用才能到达的内存地址。
直接引用,例如:
x = 10
y = '吴晋丞'
z = [1,'haha']
上述都是直接引用的实例。
间接引用,例如:
l2 = [20, 30] # 列表本身被变量名l2直接引用,包含的元素被列表间接引用
x = 10 # 值10被变量名x直接引用
l1 = [x, l2] # 列表本身被变量名l1直接引用,包含的元素被列表间接引用
间接引用只存在于容器中。容器的变量名存储着整个容器的内存地址,容器中又存储的是每个元素的内存地址。
 易错点:
易错点:
x = 10
y = ['a',x]
x = 230
print(y)
print(x)
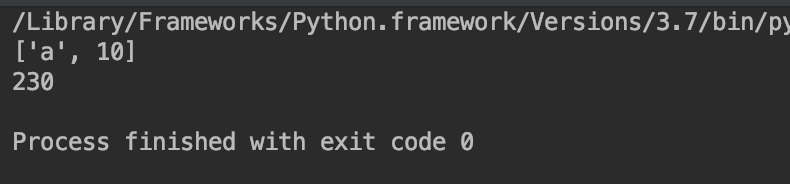 这个程序大家很可能误会y中的x会变成230,我当时认为y中存储的是x的地址,其实y中存储的地址追根溯源是10的内存地址,所以它不变。想下内存图解,10其实有两个引用,x重新赋值了,只是少一个引用罢了,对y没有影响。
这个程序大家很可能误会y中的x会变成230,我当时认为y中存储的是x的地址,其实y中存储的地址追根溯源是10的内存地址,所以它不变。想下内存图解,10其实有两个引用,x重新赋值了,只是少一个引用罢了,对y没有影响。
四、垃圾回收机制原理分析
Python的GC模块主要运用了“引用计数”(reference counting)来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用的问题,并且通过“分代回收”(generation collection)以空间换取时间的方式来进一步提高垃圾回收的效率。
五、引用计数
引用计数:内存中的值被引用的次数,当计数为0时,该变量值就成为了垃圾,就会被回收。
下述情况计数会加1:
对象被创建 a=14
对象被引用 b=a
对象被作为参数,传到函数中 func(a)
对象作为一个元素,存储在容器(比如数组、列表、元组)中 List={a,“a”,“b”,2}
与上述情况相对应,当发生以下四种情况时,计数器-1
当该对象的别名被显式销毁时 del a
当该对象的引别名被赋予新的对象 a=26
一个对象离开它的作用域,例如 func函数执行完毕时,函数里面的局部变量的引用计数器就会减一(但是全局变量不会)
将该元素从容器中删除时,或者容器被销毁时。
六、标记清除
1、循环引用问题
引用计数机制存在着一个致命的弱点,即循环引用(也称交叉引用)
# 如下我们定义了两个列表,简称列表1与列表2,变量名l1指向列表1,变量名l2指向列表2
>>> l1=['xxx'] # 列表1被引用一次,列表1的引用计数变为1
>>> l2=['yyy'] # 列表2被引用一次,列表2的引用计数变为1
>>> l1.append(l2) # 把列表2追加到l1中作为第二个元素,列表2的引用计数变为2
>>> l2.append(l1) # 把列表1追加到l2中作为第二个元素,列表1的引用计数变为2
# l1与l2之间有相互引用
# l1 = ['xxx'的内存地址,列表2的内存地址]
# l2 = ['yyy'的内存地址,列表1的内存地址]
>>> l1
['xxx', ['yyy', [...]]]
>>> l2
['yyy', ['xxx', [...]]]
>>> l1[1][1][0]
'xxx'
 循环引用会导致:值不再被任何名字关联,但是值的引用计数并不会为0,应该被回收但不能被回收,什么意思呢?试想一下,请看如下操作
循环引用会导致:值不再被任何名字关联,但是值的引用计数并不会为0,应该被回收但不能被回收,什么意思呢?试想一下,请看如下操作
>>> del l1 # 列表1的引用计数减1,列表1的引用计数变为1
>>> del l2 # 列表2的引用计数减1,列表2的引用计数变为1
此时,只剩下列表1与列表2之间的相互引用
 但此时两个列表的引用计数均不为0,但两个列表不再被任何其他对象关联,没有任何人可以再引用到它们,所以它俩占用内存空间应该被回收,但由于相互引用的存在,每一个对象的引用计数都不为0,因此这些对象所占用的内存永远不会被释放,所以循环引用是致命的,这与手动进行内存管理所产生的内存泄露毫无区别。 所以Python引入了“标记-清除” 与“分代回收”来分别解决引用计数的循环引用与效率低的问题
但此时两个列表的引用计数均不为0,但两个列表不再被任何其他对象关联,没有任何人可以再引用到它们,所以它俩占用内存空间应该被回收,但由于相互引用的存在,每一个对象的引用计数都不为0,因此这些对象所占用的内存永远不会被释放,所以循环引用是致命的,这与手动进行内存管理所产生的内存泄露毫无区别。 所以Python引入了“标记-清除” 与“分代回收”来分别解决引用计数的循环引用与效率低的问题
2、解决方案(标记清除)
容器对象(比如:list,set,dict,class,instance)都可以包含对其他对象的引用,所以都可能产生循环引用。而“标记-清除”计数就是为了解决循环引用的问题。
标记/清除算法的做法是当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后进行两项工作,第一项则是标记,第二项则是清除
#1、标记
通俗地讲就是:
栈区相当于“根”,凡是从根出发可以访达(直接或间接引用)的,都称之为“有根之人”,有根之人当活,无根之人当死。
具体地:标记的过程其实就是,遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象,其余的均为非存活对象,应该被清除。
#2、清除
清除的过程将遍历堆中所有的对象,将没有标记的对象全部清除掉。
基于上例的循环引用,当我们同时删除l1与l2时,会清理到栈区中l1与l2的内容以及直接引用关系
 这样在启用标记清除算法时,从栈区出发,没有任何一条直接或间接引用可以访达l1与l2,即l1与l2成了“无根之人”,于是l1与l2都没有被标记为存活,二者会被清理掉,这样就解决了循环引用带来的内存泄漏问题。
这样在启用标记清除算法时,从栈区出发,没有任何一条直接或间接引用可以访达l1与l2,即l1与l2成了“无根之人”,于是l1与l2都没有被标记为存活,二者会被清理掉,这样就解决了循环引用带来的内存泄漏问题。
七、分代回收
1、效率问题
基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍,这是非常消耗时间的,于是引入了分代回收来提高回收效率,分代回收采用的是用“空间换时间”的策略。
2、解决方案(分代回收)
分代:
分代回收的核心思想是:在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc对其扫描的频率会降低,具体实现原理如下:
分代指的是根据存活时间来为变量划分不同等级(也就是不同的代)
回收:
回收依然是使用引用计数作为回收的依据
 虽然分代回收可以起到提升效率的效果,但也存在一定的缺点:
虽然分代回收可以起到提升效率的效果,但也存在一定的缺点:
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 998
998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









