







 本文介绍了如何通过Python爬虫技术,利用网址规律和range函数遍历网页,结合字符串格式化和正则表达式从源码中提取所需信息,最后将数据存储到Excel。同时强调了系统化学习的重要性以及IT社群的价值。
本文介绍了如何通过Python爬虫技术,利用网址规律和range函数遍历网页,结合字符串格式化和正则表达式从源码中提取所需信息,最后将数据存储到Excel。同时强调了系统化学习的重要性以及IT社群的价值。
如果我们想访问多个页面的话需要找寻网站的网址规律是怎么样的
http://www.risfond.com/case/fmcg/26700 ,http://www.risfond.com/case/fmcg/26701,
点击网址下一条就可以发现网址的规律,网址后面的数字是发生了改变的,
所以可以采用字符串格式化跟range函数,for in来进行使用,基础知识附带使用讲解下。
range函数可以生成一个整数序列,里面只有一个参数默认从0开始,2个参数是含头不含尾,示例如下:

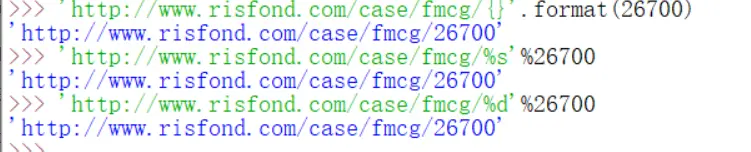
字符串格式化,%s代表字符串,%d代表数字,当不知道用什么的情况下可以用%s代替,format是用{}.format()的方式做到字符串格式化的。
发送请求
for i in range(26700,26716):
url = ‘http://www.risfond.com/case/fmcg/{}’.format(i)
html = urllib.request.urlopen(url).read().decode(‘utf-8’)#urlopen打开网址 read 读取源代码
print(html)
第二步:从源码解析所需要的数据
这里用的是re正则表达式,可以根据一定的规则从源码中匹配出相对应的内容,打个比方说,我去水果店买西瓜,西瓜的特征是果绿色的外壳,红色的果肉,椭圆形状,都是根据这个特征去寻找的,在网站中间也是如此,获取的内容有着共同的标签比如div,而且都是在一样的html布局中,就可以写一个正则,用findall去从源码html中匹配出来。
page_list = re.findall(r’
第三步:数据存储到excel
根据内容,我觉得存储到excel表格里面会比较好,所以对每行也写了一定的注释,大家可以参考下!
newTable = ‘test2019.xls’#表格名称
wb = xlwt.Workbook(encoding=‘utf-8’) #创建excel文件 设置编码
ws = wb.add_sheet(‘rsfd’)#表名称
headData = [‘职位名称’,‘职位地点’,‘时间’,‘行业’,‘招聘时间’,‘人数’,‘顾问’]
for colnum in range(0,7):
ws.write(0,colnum,heData[colnum],xlwt.easyxf(‘font:bold on’))
index = 1
for j in range(0,len(items)):#计算数据有多少条
for i in range(0,7):
print(items[j][i])
ws.write(index,i,items[j][i])#行数 列数 数据
index+=1
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2689
2689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









