







结合常量提取得到混淆结果:
var _0x9d2b = [‘\x68\x65\x6c\x6c\x6f’];
var _0xb7de = function (_0x4c7513) {
_0x4c7513 = _0x4c7513 - 0x0;
var _0x96ade5 = _0x9d2b[_0x4c7513];
return _0x96ade5;
};
var test = _0xb7de(‘0x0’);
当然,除了JS特性自带的Unicode自动解析以外,也可以自定义一些加解密算法,比如对常量进行base64编码,或者其他的什么rc4等等,只需要使用的时候解密就OK,比如上面的代码用base64编码后:
var _0x9d2b = [‘aGVsbG8=’]; // base64编码后的字符串
var _0xaf421 = function (_0xab132) {
// base64解码函数
var _0x75aed = function(_0x2cf82) {
// TODO: 解码
};
return _0x75aed(_0xab132);
}
var _0xb7de = function (_0x4c7513) {
_0x4c7513 = _0x4c7513 - 0x0;
var _0x96ade5 = _0xaf421(_0x9d2b[_0x4c7513]);
return _0x96ade5;
};
var test = _0xb7de(‘0x0’);
#### 运算混淆
将所有的逻辑运算符、二元运算符都变成函数,目的也是增加代码阅读难度,让其无法直接通过静态分析得到结果。如下:
var i = 1 + 2;
var j = i * 2;
var k = j || i;
混淆后:
var _0x62fae = {
_0xeca4f: function(_0x3c412, _0xae362) {
return _0x3c412 + _0xae362;
},
_0xe82ae: function(_0x63aec, _0x678ec) {
return _0x63aec * _0x678ec;
},
_0x2374a: function(_0x32487, _0x3a461) {
return _0x32487 || _0x3a461;
}
};
var i = _0x62fae._0e8ca4f(1, 2);
var j = _0x62fae._0xe82ae(p1, 2);
var k = _0x62fae._0x2374a(i, j);
当然除了逻辑运算符和二元运算符以外,还可以将函数调用、静态字符串进行类似的混淆,如下:
var fun1 = function(name) {
console.log(‘hello, ’ + name);
};
var fun2 = function(name, age) {
console.log(name + ’ is ’ + age + ’ years old’);
}
var name = ‘xiao.ming’;
fun1(name);
fun2(name, 8);
var _0x62fae = {
_0xe82ae: function(_0x63aec, _0x678ec) {
return _0x63aec(_0x678ec);
},
_0xeca4f: function(_0x92352, _0x3c412, _0xae362) {
return _0x92352(_0x3c412, _0xae362)
},
_0x2374a: ‘xiao.ming’,
_0x5482a: 'hello, ',
_0x837ce: ’ is ‘,
_0x3226e: ’ years old’
};
var fun1 = function(name) {
console.log(_0x62fae._0x5482a + name);
};
var fun2 = function(name, age) {
console.log(name + _0x62fae._0x837ce + age + _0x62fae._0x3226e);
}
var name = _0x62fae._0x2374a;
_0x62fae._0xe82ae(name);
_0x62fae._0x2374a(name, 0x8);
上面的例子中,fun1和fun2内的字符串相加也会被混淆走,静态字符串也会被前面提到的`字符串提取`抽取到数组中(我就是懒,这部分代码就不写了)。
需要注意的是,我们每次遇到相同的运算符,需不需要重新生成函数进行替换,这就按个人需求了。
#### 语法丑化
将我们常用的语法混淆成我们不常用的语法,前提是不改变代码的功能。例如for换成do/while,如下:
for (i = 0; i < n; i++) {
// TODO: do something
}
var i = 0;
do {
if (i >= n) break;
// TODO: do something
i++;
} while (true)
#### 动态执行
将静态执行代码添加动态判断,运行时动态决定运算符,干扰静态分析。
如下:
var c = 1 + 2;
混淆过后:
function _0x513fa(_0x534f6, _0x85766) { return _0x534f6 + _0x85766; }
function _0x3f632(_0x534f6, _0x534f6) { return _0x534f6 - _0x534f6; }
// 动态判定函数
function _0x3fa24() {
return true;
}
var c = _0x3fa24() ? : _0x513fa(1, 2) : _0x3f632(1, 2);
#### 流程混淆
对执行流程进行混淆,又称控制流扁平化,为什么要做混淆执行流程呢?因为在代码开发的过程中,为了使代码逻辑清晰,便于维护和扩展,会把代码编写的逻辑非常清晰。一段代码从输入,经过各种if/else分支,顺序执行之后得到不同的结果,而我们需要将这些执行流程和判定流程进行混淆,让攻击者没那么容易摸清楚我们的执行逻辑。
控制流扁平化又分顺序扁平化、条件扁平化,
顺序扁平化
顾名思义,将按顺序、自上而下执行的代码,分解成数个分支进行执行,如下代码:
(function () {
console.log(1);
console.log(2);
console.log(3);
console.log(4);
console.log(5);
})();
流程图如下:
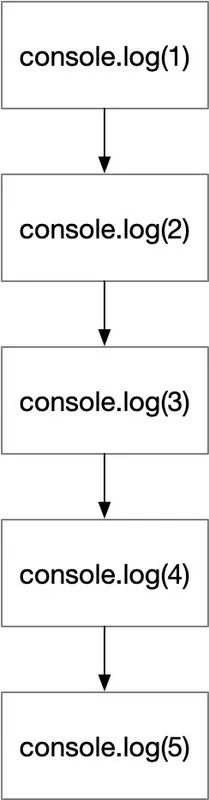
控制流扁平化3
混淆过后代码如下:
(function () {
var flow = ‘3|4|0|1|2’.split(‘|’), index = 0;
while (!![]) {
switch (flow[index++]) {
case ‘0’:
console.log(3);
continue;
case ‘1’:
console.log(4);
continue;
case ‘2’:
console.log(5);
continue;
case ‘3’:
console.log(1);
continue;
case ‘4’:
console.log(2);
continue;
}
break;
}
}());
混淆过后的流程图如下:

控制流扁平化4
流程看起来`扁`了。
条件扁平化
条件扁平化的作用是把所有if/else分支的流程,全部扁平到一个流程中,在流程图中拥有相同的入口和出口。
如下面的代码:
function modexp(y, x, w, n) {
var R, L;
var k = 0;
var s = 1;
while(k < w) {
if (x[k] == 1) {
R = (s * y) % n;
}
else {
R = s;
}
s = R * R % n;
L = R;
k++;
}
return L;
}
如上代码,流程图是这样的

控制流扁平化1
控制流扁平化后代码如下:
function modexp(y, x, w, n) {
var R, L, s, k;
var next = 0;
for(;😉 {
switch(next) {
case 0: k = 0; s = 1; next = 1; break;
case 1: if (k < w) next = 2; else next = 6; break;
case 2: if (x[k] == 1) next = 3; else next = 4; break;
case 3: R = (s * y) % n; next = 5; break;
case 4: R = s; next = 5; break;
case 5: s = R * R % n; L = R; k++; next = 1; break;
case 6: return L;
}
}
}
混淆后的流程图如下:

控制流扁平化2
直观的感觉就是代码变`扁`了,所有的代码都挤到了一层当中,这样做的好处在于在让攻击者无法直观,或通过静态分析的方法判断哪些代码先执行哪些后执行,必须要通过动态运行才能记录执行顺序,从而加重了分析的负担。
需要注意的是,在我们的流程中,无论是顺序流程还是条件流程,如果出现了块作用域的变量声明(const/let),那么上面的流程扁平化将会出现错误,因为switch/case内部为块作用域,表达式被分到case内部之后,其他case无法取到const/let的变量声明,自然会报错。
不透明谓词
上面的switch/case的判断是通过数字(也就是谓词)的形式判断的,而且是透明的,可以看到的,为了更加的混淆视听,可以将case判断设定为表达式,让其无法直接判断,比如利用上面代码,改为不透明谓词:
function modexp(y, x, w, n) {
var a = 0, b = 1, c = 2 * b + a;
var R, L, s, k;
var next = 0;
for(;😉 {
switch(next) {
case (a * b): k = 0; s = 1; next = 1; break;
case (2 * a + b): if (k < w) next = 2; else next = 6; break;
case (2 * b - a): if (x[k] == 1) next = 3; else next = 4; break;
case (3 * a + b + c): R = (s * y) % n; next = 5; break;
case (2 * b + c): R = s; next = 5; break;
case (2 * c + b): s = R * R % n; L = R; k++; next = 1; break;
case (4 * c - 2 * b): return L;
}
}
}
谓词用a、b、c三个变量组成,甚至可以把这三个变量隐藏到全局中定义,或者隐藏在某个数组中,让攻击者不能那么轻易找到。
#### 脚本加壳
将脚本进行编码,运行时 解码 再 eval 执行如:
eval (…………………………………………. ……………. !@#$%^&* ……………. .…………………………………………. )
但是实际上这样意义并不大,因为攻击者只需要把alert或者console.log就原形毕露了
改进方案:利用`Function / (function(){}).constructor`将代码当做字符串传入,然后执行,如下:
var code = ‘console.log(“hellow”)’;
(new Function(code))();
如上代码,可以对code进行加密混淆,例如aaencode,原理也是如此,我们举个例子
alert(“Hello, JavaScript”);
利用aaencode混淆过后,代码如下:
゚ω゚ノ= /`m´)ノ ~┻━┻ //´∇`/ [‘']; o=(゚ー゚) ==3; c=(゚Θ゚) =(゚ー゚)-(゚ー゚); (゚Д゚) =(゚Θ゚)= (o_o)/ (o_o);(゚Д゚)={゚Θ゚: ‘’ ,゚ω゚ノ : ((゚ω゚ノ==3) +'’) [゚Θ゚] ,゚ー゚ノ :(゚ω゚ノ+ ‘‘)[o_o -(゚Θ゚)] ,゚Д゚ノ:((゚ー゚==3) +’’)[゚ー゚] }; (゚Д゚) [゚Θ゚] =((゚ω゚ノ3) +‘‘) [c_o];(゚Д゚) [‘c’] = ((゚Д゚)+’’) [ (゚ー゚)+(゚ー゚)-(゚Θ゚) ];(゚Д゚) [‘o’] = ((゚Д゚)+‘‘) [゚Θ゚];(゚o゚)=(゚Д゚) [‘c’]+(゚Д゚) [‘o’]+(゚ω゚ノ +’’)[゚Θ゚]+ ((゚ω゚ノ3) +’‘) [゚ー゚] + ((゚Д゚) +’‘) [(゚ー゚)+(゚ー゚)]+ ((゚ー゚3) +‘_’) [゚Θ゚]+((゚ー゚3) +’‘) [(゚ー゚) - (゚Θ゚)]+(゚Д゚) [‘c’]+((゚Д゚)+’‘) [(゚ー゚)+(゚ー゚)]+ (゚Д゚) [‘o’]+((゚ー゚3) +‘‘) [゚Θ゚];(゚Д゚) [’’] =(o_o) [゚o゚] [゚o゚];(゚ε゚)=((゚ー゚3) +’‘) [゚Θ゚]+ (゚Д゚) .゚Д゚ノ+((゚Д゚)+’‘) [(゚ー゚) + (゚ー゚)]+((゚ー゚3) +‘_’) [o_o -゚Θ゚]+((゚ー゚3) +’‘) [゚Θ゚]+ (゚ω゚ノ +’‘) [゚Θ゚]; (゚ー゚)+=(゚Θ゚); (゚Д゚)[゚ε゚]=’\‘; (゚Д゚).゚Θ゚ノ=(゚Д゚+ ゚ー゚)[o_o -(゚Θ゚)];(o゚ー゚o)=(゚ω゚ノ +’‘)[c_o];(゚Д゚) [゚o゚]=’"‘;(゚Д゚) [’‘] ( (゚Д゚) [’‘] (゚ε゚+(゚Д゚)[゚o゚]+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o_o) +(o_o))+ ((o_o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o_o) +(o_o))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (c_o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ ((o_o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚Θ゚)+ (c_o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ ((゚ー゚) + (o_o))+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c_o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚Θ゚)+ ((o_o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o_o) +(o_o))+ ((o_o) +(o_o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o_o) - (゚Θ゚))+ (o_o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (o_o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o_o) +(o_o))+ ((o_o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o_o) +(o_o))+ (c_o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o_o) +(o_o))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ ((o_o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (゚Θ゚)+ (゚Д゚)[゚o゚]) (゚Θ゚)) (’');
这段代码看起来很奇怪,不像是JavaScript代码,但是实际上这段代码是用一些看似表情的符号,声明了一个16位的数组(用来表示16进制位置),然后将code当做字符串遍历,把每个代码符号通过`string.charCodeAt`取这个16位的数组下标,拼接成代码。大概的意思就是把代码当做字符串,然后使用这些符号的拼接代替这一段代码(可以看到代码里有很多加号),最后,通过`(new Function(code))('_')`执行。
仔细观察上面这一段代码,把代码最后的`('_')`去掉,在运行,你会直接看到源代码,然后`Function.constructor`存在`(゚Д゚)`变量中,感兴趣的同学可以自行查看。
除了aaencode,jjencode原理也是差不多,就不做解释了,其他更霸气的jsfuck,这些都是对代码进行加密的,这里就不详细介绍了。
### 反调试
由于JavaScript自带`debugger`语法,我们可以利用死循环性的`debugger`,当页面打开调试面板的时候,无限进入调试状态。
#### 定时执行
在代码开始执行的时候,使用`setInterval`定时触发我们的反调试函数。
#### 随机执行
在代码生成阶段,随机在部分函数体中注入我们的反调试函数,当代码执行到特定逻辑的时候,如果调试面板在打开状态,则无限进入调试状态。
### 内容监测
由于我们的代码可能已经反调试了,攻击者可以会将代码拷贝到自己本地,然后修改,调试,执行,这个时候就需要添加一些检测进行判定,如果不是正常的环境执行,那让代码自行失败。
#### 代码自检
在代码生成的时候,为函数生成一份Hash,在代码执行之前,通过函数 toString 方法,检测代码是否被篡改
function module() {
// 篡改校验
if (Hash(module.toString()) != ‘JkYxnHlxHbqKowiuy’) {
// 代码被篡改!
}
}
#### 环境自检
检查当前脚本的执行环境,例如当前的URL是否在允许的白名单内、当前环境是否正常的浏览器。
如果为Nodejs环境,如果出现异常环境,甚至我们可以启动木马,长期跟踪。
### 废代码注入
插入一些永远不会发生的代码,让攻击者在分析代码的时候被这些无用的废代码混淆视听,增加阅读难度。
#### 废逻辑注入
与废代码相对立的就是有用的代码,这些有用的代码代表着被执行代码的逻辑,这个时候我们可以收集这些逻辑,增加一段判定来决定执行真逻辑还是假逻辑,如下:
(function(){
if (true) {
最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1213
1213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









