







一、先了解用户获取网络数据的方式
1、用户使用浏览器:浏览器提交请求—>下载网页代码—>解析成页面
2、代码自动获取:模拟浏览器发送请求(获取网页代码html、css、javascript)->提取有用的数据->存放于数据库或文件中
python爬虫 便是使用代码自动获取,具体流程为:
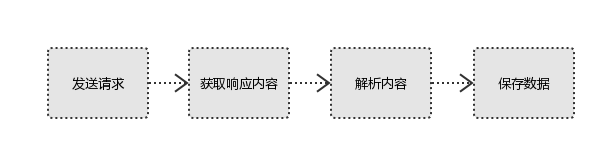
二、简单了解网页源代码的组成
1、web基本的编程语言
简单了解可以上菜鸟教程
1)HTML、CSS、JavaScript 是 web 开发人员必须学习的 3 门语言,他们互相配合构成各类丰富的网站
(1)HTML 定义了网页的内容
(2)CSS 描述了网页的布局
(3)JavaScript 控制了网页的行为
2)html5简单例子

3)javaScript在html里

4)CSS在html里

2、使用浏览器查看网页源代码
1)网页右击查看源代码(也就是我们要获取的内容)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1256
1256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









