









既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
total_error = 0
for i in range(len(x_data)):
total_error += (y_data[i] - (k \* x_data[i] + b)) \*\* 2
# 为方便求导:乘以1/2
mse_ = total_error / len(x_data) / 2
return mse_
---
## ④梯度下降
分别对上述的MSE表达式(乘以1/2后)中的k,b求偏导,
∂
1
2
M
S
E
∂
b
=
∑
i
=
1
m
(
k
x
i
+
b
−
y
i
)
m
\frac{∂ \frac{1}{2}MSE}{∂b}=\sum\_{i=1}^m\frac{(kx\_i+b-y\_i)}{m}
∂b∂21MSE=∑i=1mm(kxi+b−yi)
∂
1
2
M
S
E
∂
k
=
∑
i
=
1
m
(
k
x
i
+
b
−
y
i
)
x
i
m
\frac{∂ \frac{1}{2}MSE}{∂k}=\sum\_{i=1}^m\frac{(kx\_i+b-y\_i)x\_i}{m}
∂k∂21MSE=∑i=1mm(kxi+b−yi)xi
更新b和k时,使用原来的b,k值分别减去关于b、k的偏导数与学习率的乘积即可。至于为什么使用减号,可以这么理解:以斜率k为例,当其导数大于零的时候,则表示均方误差随着斜率的增大而增大,为了使均方误差减小,则不应该使斜率继续增大,所以需要使其减小,反之当偏导大于零的时候也是同理。其次,因为这个导数衡量的是均方误差的变化,而不是斜率和截距的变化,所以这里需要引入一个学习率,使得其与偏导数的乘积能够在一定程度上起到控制截距和斜率变化的作用。
def gradient_descent(x_data, y_data, b, k, learning_rate, n_iterables):
m = len(x_data)
# 迭代
for i in range(n_iterables):
# 初始化b、k的偏导
b_grad = 0
k_grad = 0
# 遍历m次
for j in range(m):
# 对b,k求偏导
b_grad += (1 / m) \* ((k \* x_data[j] + b) - y_data[j])
k_grad += (1 / m) \* ((k \* x_data[j] + b) - y_data[j]) \* x_data[j]
# 更新 b 和 k 减去偏导乘以学习率
b = b - (learning_rate \* b_grad)
k = k - (learning_rate \* k_grad)
# 每迭代 5 次 输出一次图形
if i % 5 == 0:
print(f"当前第{i}次迭代")
print("b\_gard:", b_grad, "k\_gard:", k_grad)
print("b:", b, "k:", k)
plt.scatter(x_data, y_data, color="maroon", marker="x")
plt.plot(x_data, k \* x_data + b)
plt.show()
return b, k
## ⑤执行
print(f"开始:截距b={b},斜率k={k},损失={compute_mse(b,k,x_data,y_data)}“)
print(“开始迭代”)
b, k = gradient_descent(x_data, y_data, b, k, learning_rate, n_iterables)
print(f"迭代{n_iterables}次后:截距b={b},斜率k={k},损失={compute_mse(b,k,x_data,y_data)}”)
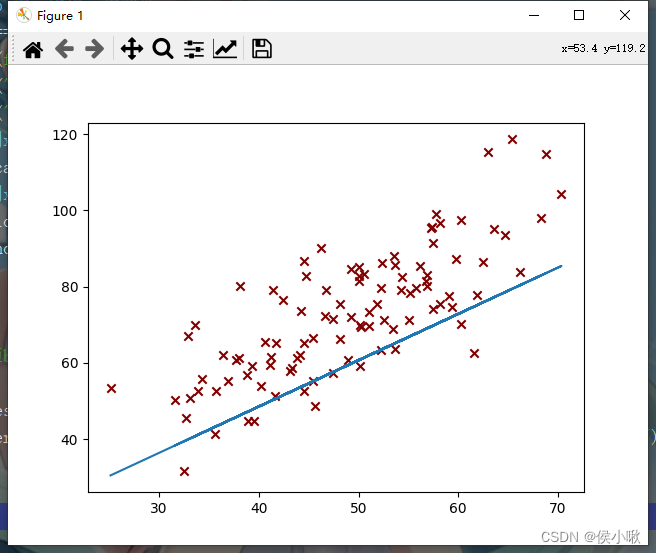
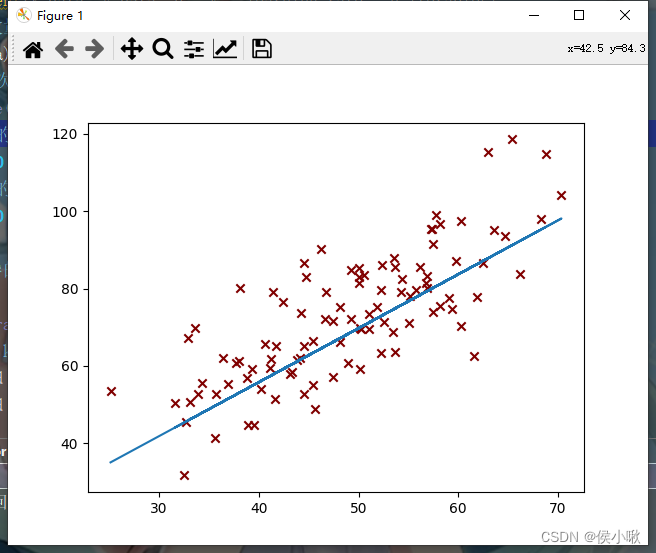
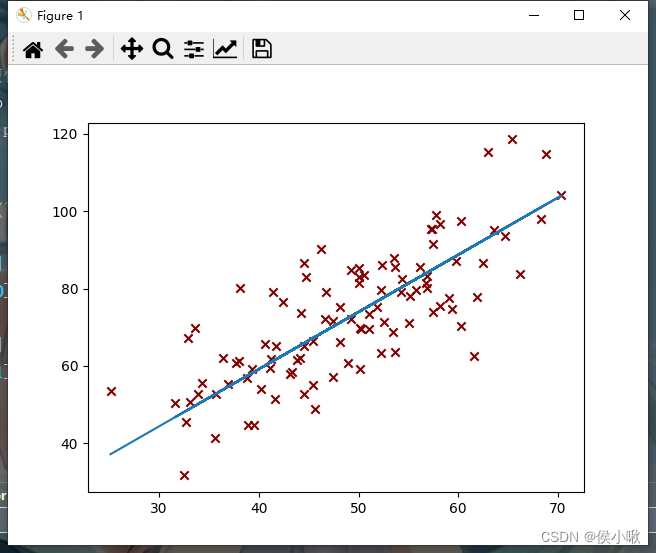
代码执行过程产生了一系列的图像,部分图像如下图所示,随着迭代次数的增加,代价函数越来越小,最终达到预期效果,如下图所示:
第5次迭代:
---
第10次迭代:
---
第50次迭代:



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
片转存中...(img-0QdpHOkU-1715683583692)]
[外链图片转存中...(img-vAfwY5aK-1715683583692)]
[外链图片转存中...(img-BCTYKvVL-1715683583692)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 2358
2358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









