







作为一名在数据行业打拼了两年多的数据分析师,虽然目前收入还算ok,但每每想起房价,男儿三十还未立,内心就不免彷徨不已~
两年时间里曾经换过一份工作,一直都是从事大数据相关的行业。目前是一家企业的BI工程师,主要工作就是给业务部门出报表和业务分析报告。
回想自己过去的工作成绩也还算是不错的,多次通过自己分析告,解决了业务的疑难杂症,领导们各种离不开。
但安逸久了总会有点莫名的慌张,所以我所在的这个岗位未来会有多大发展空间,十年之后我能成为什么样的人呢?自己的收入空间还有多少?
一番惆怅之后,别再问路在何方了,于是抄起自己的“家伙”,花了一小会时间爬了智联招聘上BI岗位的数据信息,做了个分析。
PS:所用工具为Python+BI
数据分析的过程如同烧一顿饭,先要数据采集(买菜),然后数据建模(配菜)、数据清洗(洗菜)、数据分析(做菜)、数据可视化(摆盘上菜)。
所以第一步,要采集/选择数据。
一、Python爬取智联招聘岗位信息(附源码)
选择智联招聘,通过Python来进行“BI工程师”的关键数据信息的爬取,这里大家也可以试着爬取自己岗位的关键词,如“数据分析师”、“java开发工程师 ”等。经过F12分析调试,数据是以JSON的形式存储的,可以通过智联招聘提供的接口调用返回。
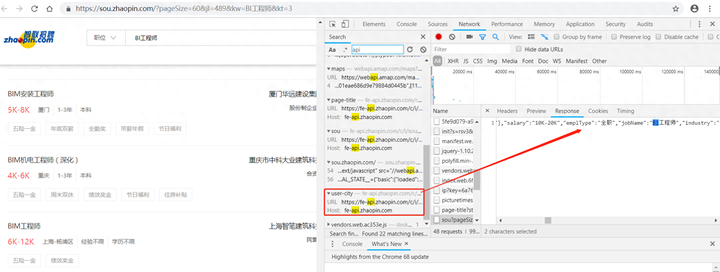
那么我这边通过Python对智联招聘网站的数据进行解析,爬取了30页数据,并且将岗位名称、公司名称、薪水、所在城市、所属行业、学历要求、工作年限这些关键信息用CSV文件保存下来。
附上完整Python源码:
import requests
import json
import csv
from urllib.parse import urlencode
import time
def saveHtml(file_name,file_content): #保存conten对象为html文件
with open(file_name.replace('/','_')+'.html','wb') as f:
f.write(file_content)
def GetData(url,writer):#解析并将数据保存为CSV文件
response= requests.get(url)
data=response.content
saveHtml('zlzp',data) #保存html文件
jsondata=json.loads(data)
dataList=jsondata['data']['results']
#print(jsondata)
for dic in dataList:
jobName=dic['jobName'] #岗位名称
company=dic['company']['name'] #公司名称
salary=dic['salary'] #薪水
city=dic['city']['display'] #城市
jobtype = dic['jobType']['display'] #所属行业
eduLevel=dic['eduLevel']['name'] #学历要求
workingExp=dic['workingExp']['name'] #工作经验
print(jobName,company,salary,city,jobtype,eduLevel,workingExp)
writer.writerow([jobName,company,salary,city,jobtype,eduLevel,workingExp])
param={ 'start':0,
'pageSize':60,
'cityId':489,
'workExperience':-1,
'education':-1,
'companyType': -1,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









