







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
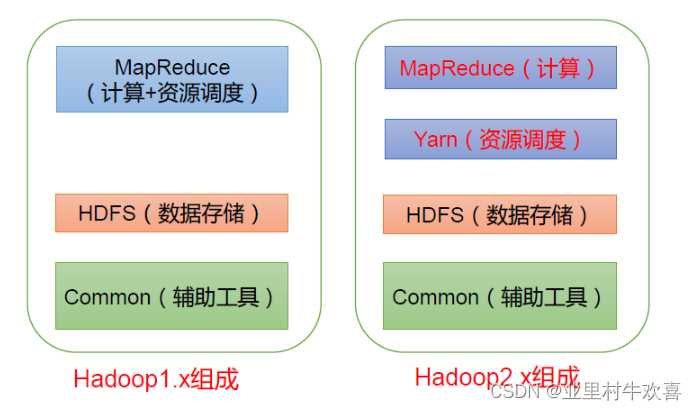
Hadoop的版本迭代也升级了,增加了Yarn进行资源调度。
**(HDFS)**Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
(1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
(2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
(3)Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
**(YARN)**Yet Another Resource Negotiator 简称YARN ,另一种资源协调者,是Hadoop 的资源管理器。
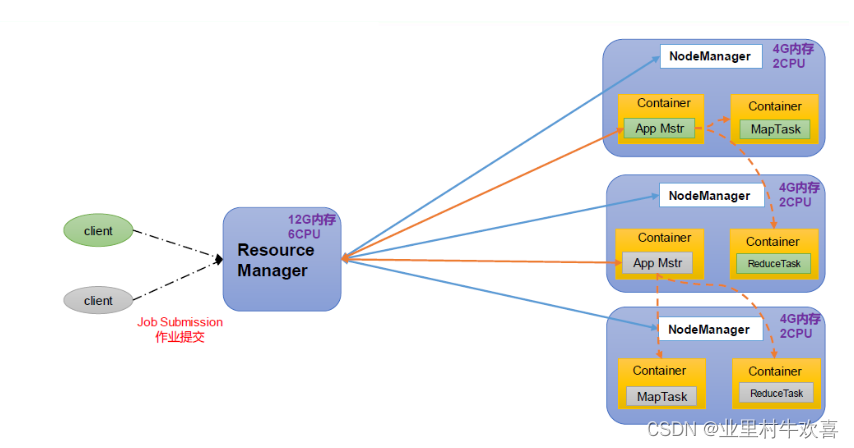
ResourceManager(RM):整个集群资源(内存、CPU等)的管理者
NodeManager(NM):单个节点服务器资源的管理者。
ApplicationMaster(AM):单个任务运行的管理者。
Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
说明:
(1)客户端可以有多个
(2)集群上可以运行多个ApplicationMaster
(3)每个NodeManager上可以有多个Container
(MapReduce )将计算过程分为两个阶段:Map 和Reduce
1)Map 阶段并行处理输入数据
2)Reduce 阶段对Map 结果进行汇总
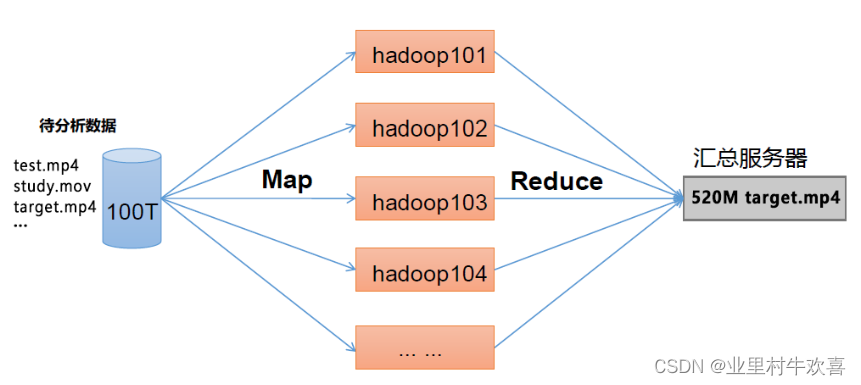
HDFS、YARN、MapReduce 三者关系
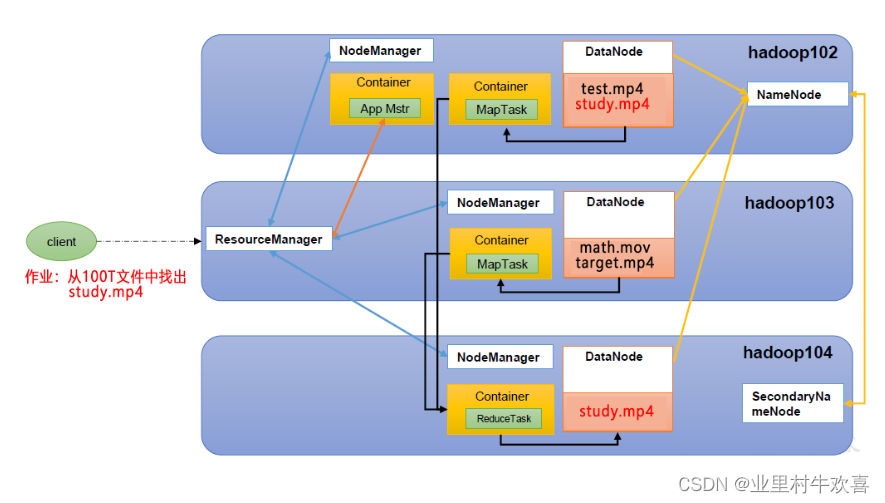
首先是客户端从任务管理器中抽取文件,找到计算中心处理,计算中心将任务文件分配到各个Yarn管理的各个NodeManager,这时候Yarn起到调度的作用,将在各个任务分配到每个独立服务器中,也就是我们所说的slave,slave服务器分别存储不同的资源包,有一些存储电影、有一些存储文件。每个服务器独立存储,很少造成数据丢失。
二、Hadoop 运行环境搭建
(注:基本都是下一步了,需要注意的地方会截图说明)
2.1安装VM(虚拟机管理环境)

这里截图是VM12的版本,后期我升级VM15的的版本,安装步骤差不多。
序列号去网上找一些可以使用,这个很多了。
2.2 VM网络设置
本操作是将VM创建的服务器分配IP地址,将IP地址地段分配一起,避免冲突。
打开控制面板
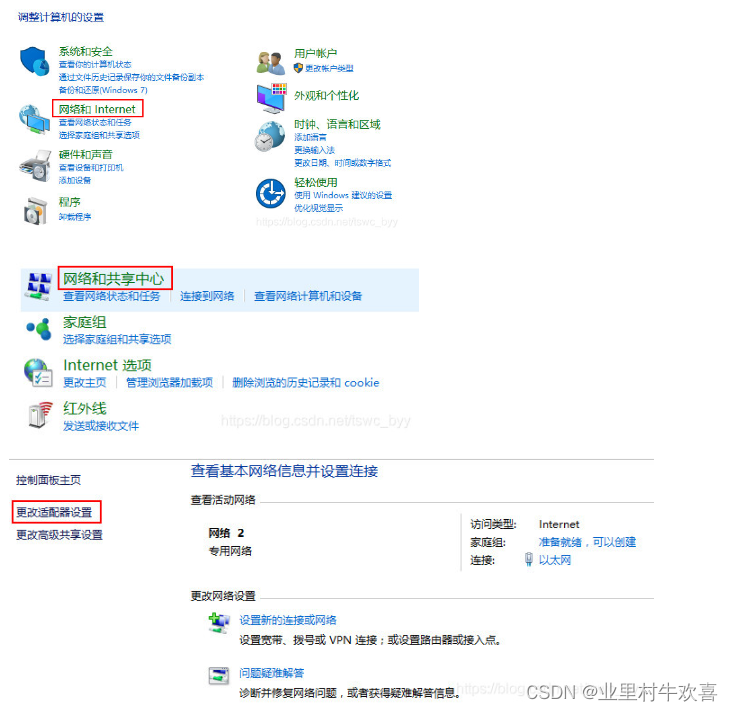
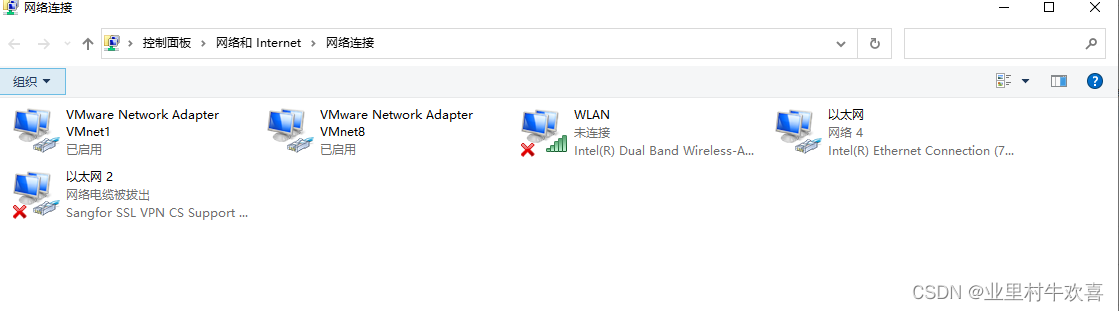
找到虚拟网卡接口VMware Network,进行配置。
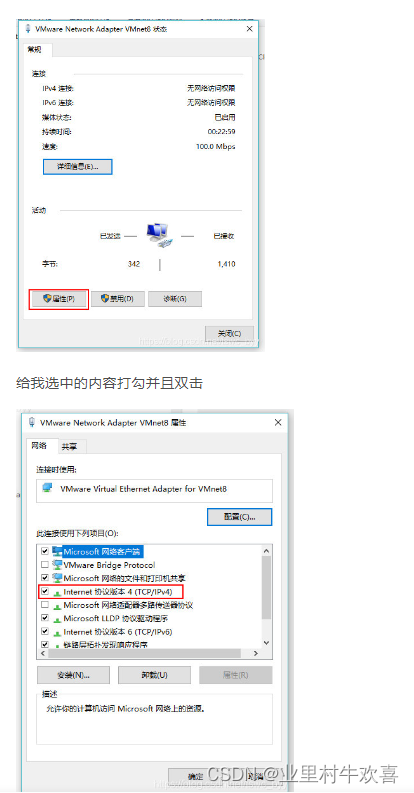
配置192.168.56.1网段。(一般1是主服务器)
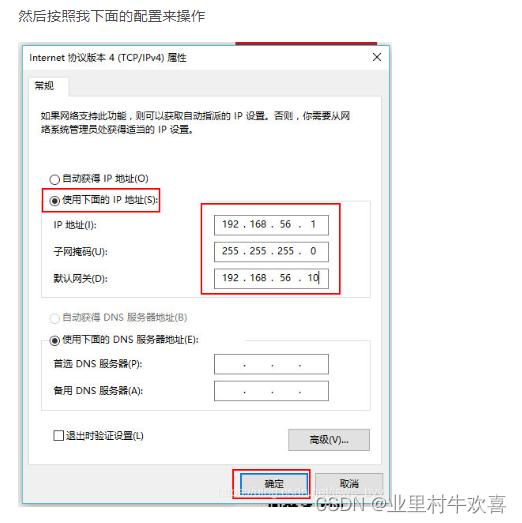

设置网关192.168.56.10网关,以后数据进行交互时是由网关带出去了。
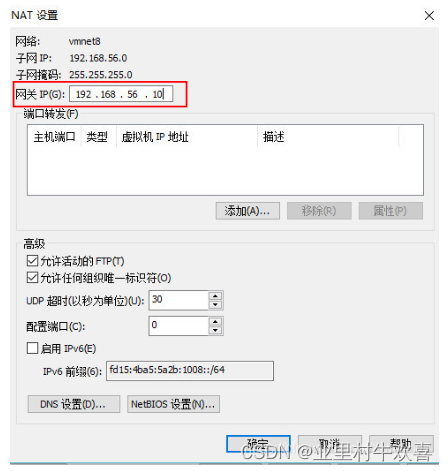
配置网络信息,将创建的虚拟服务器都在同一个网段了。
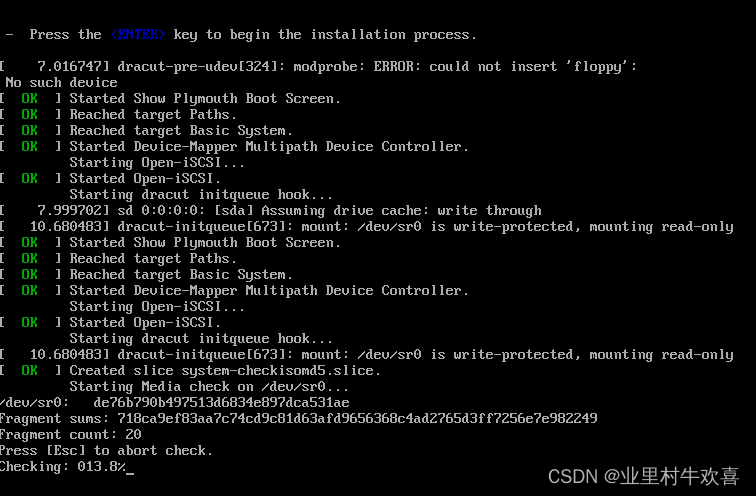
2.3 安装CentOS7系统
下载CentOS-7的镜像(百度搜索可以下载,避免版本冲突,最好下载1804版本)

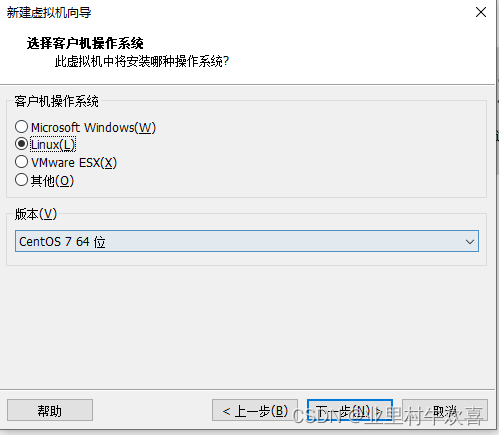
安装位置可以是别的盘,我为了方便就选择C盘了。


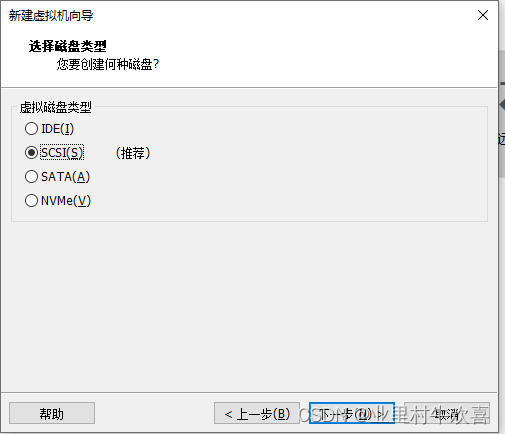
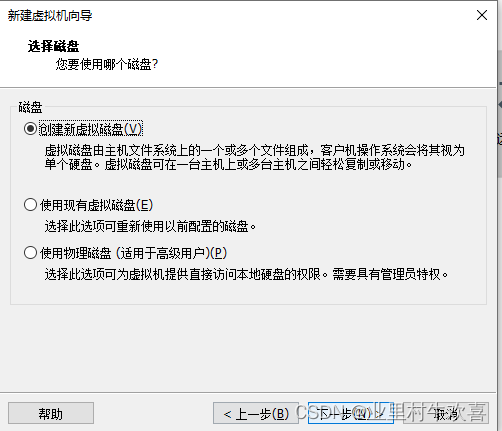
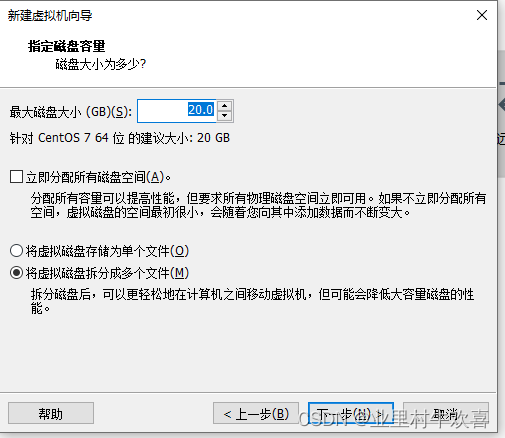
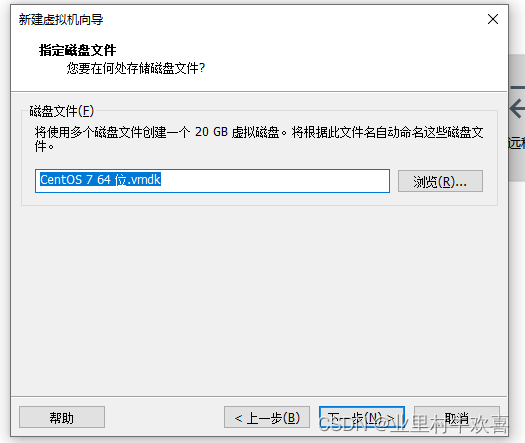 .
.
完成后,会有一个新的主界面,是我们每次启动计算机的界面。
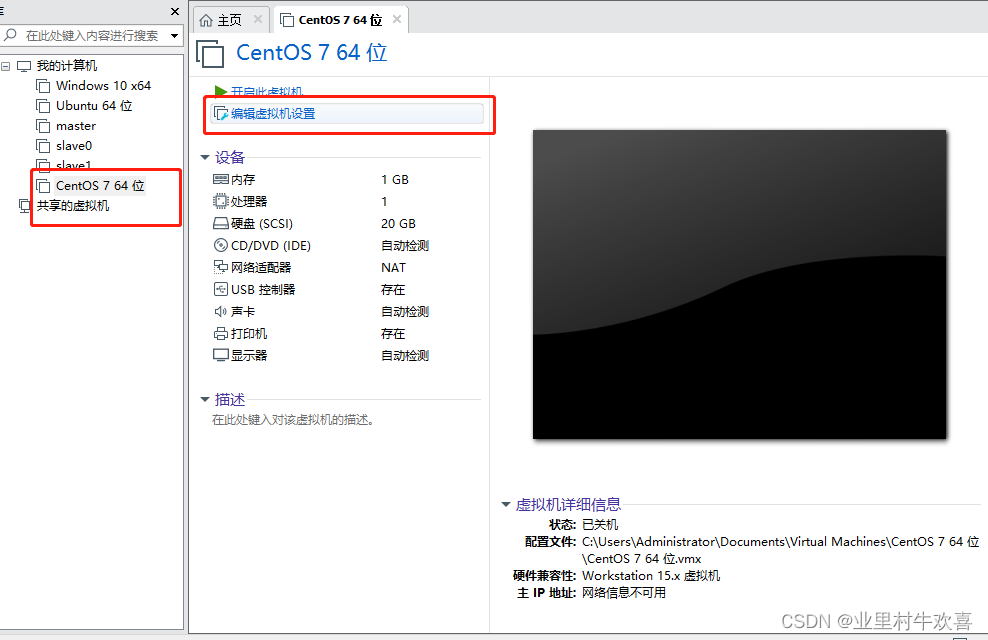
删除掉一些打印机,复印机,不需要的硬件选项,增加运行速度。
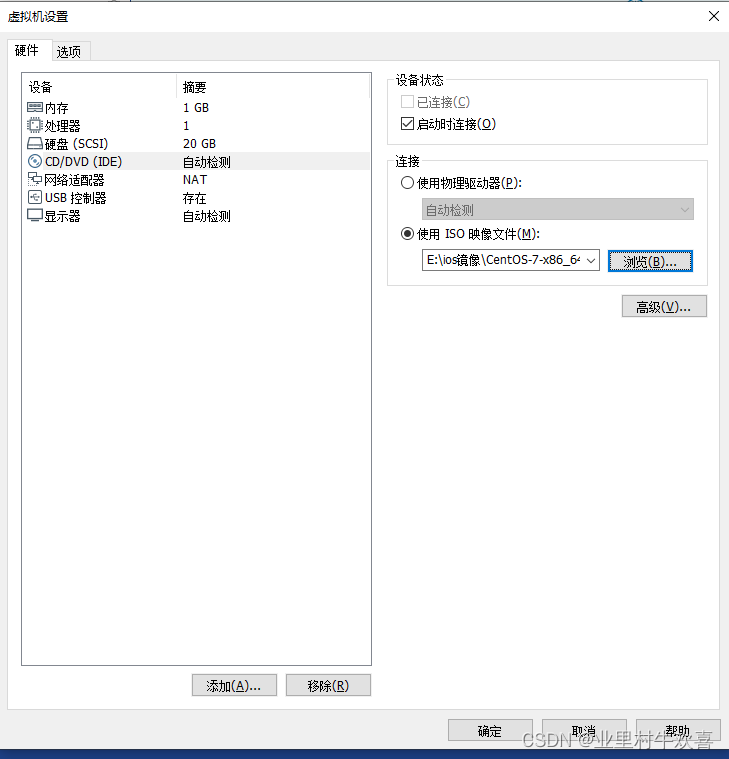
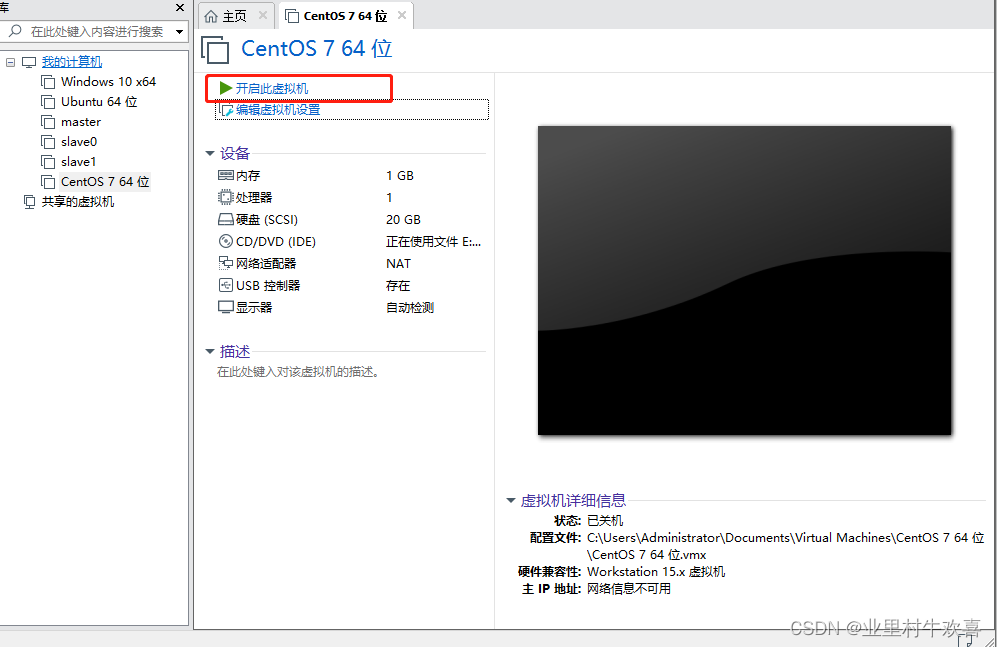
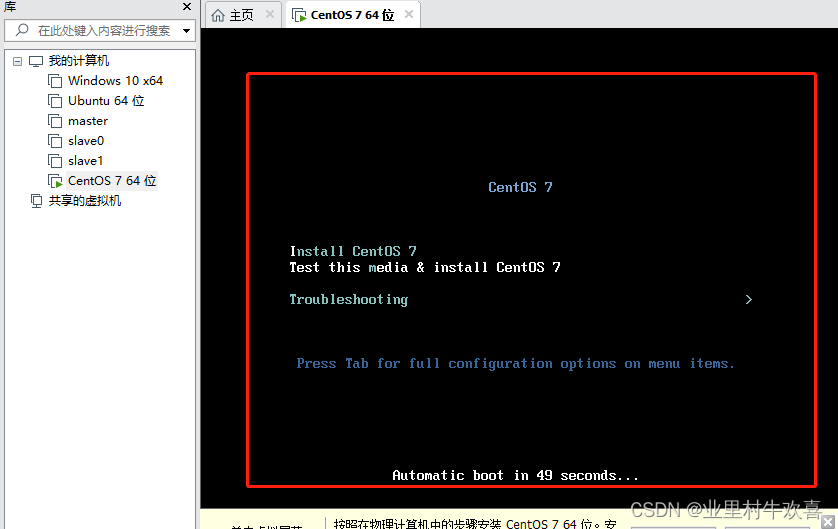
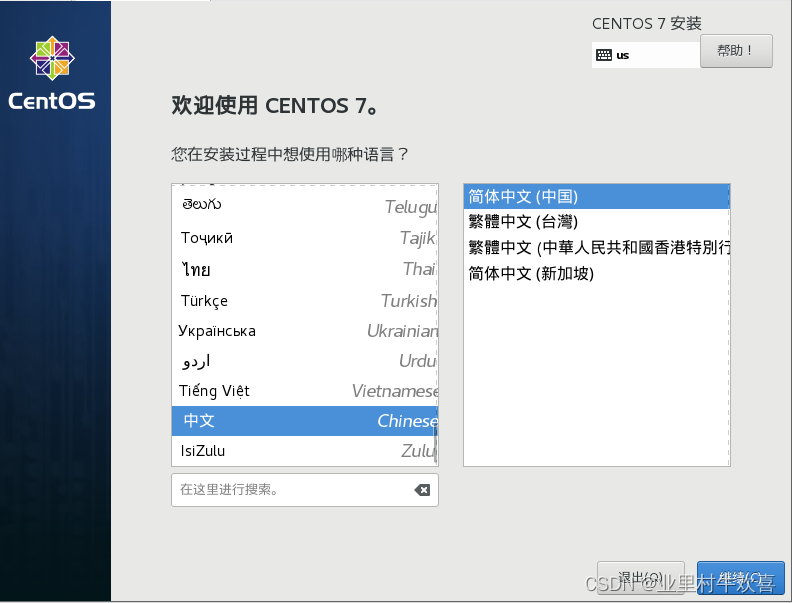
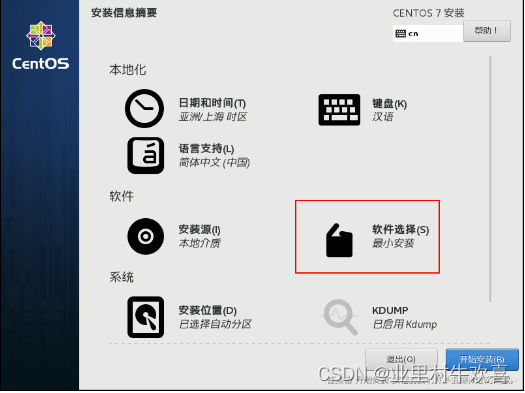
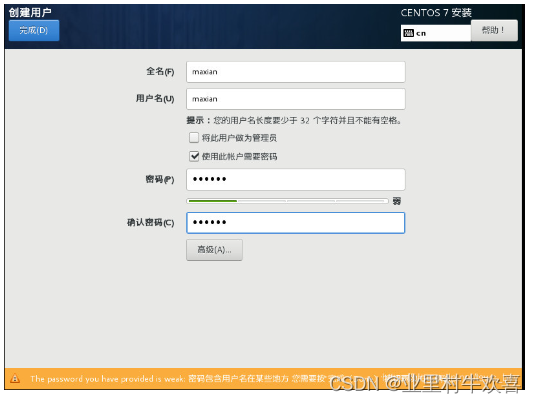
牢记用户密码和Root密码,将来需要改配置,需要密码验证。
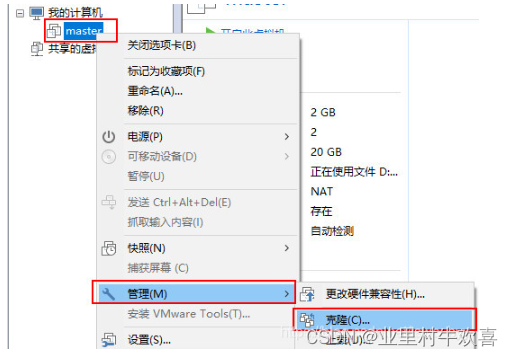
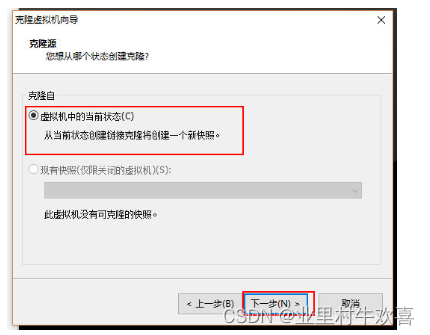
使用VM的克隆的方法,创建三台虚拟服务器的主机,并且将三台服务器更名为master,slave1,slave2;先关闭主服务器master的开关,然后进行管理克隆操作。

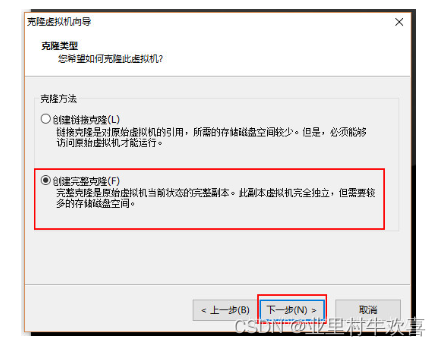
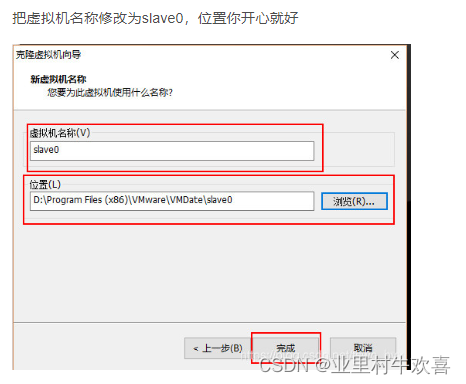
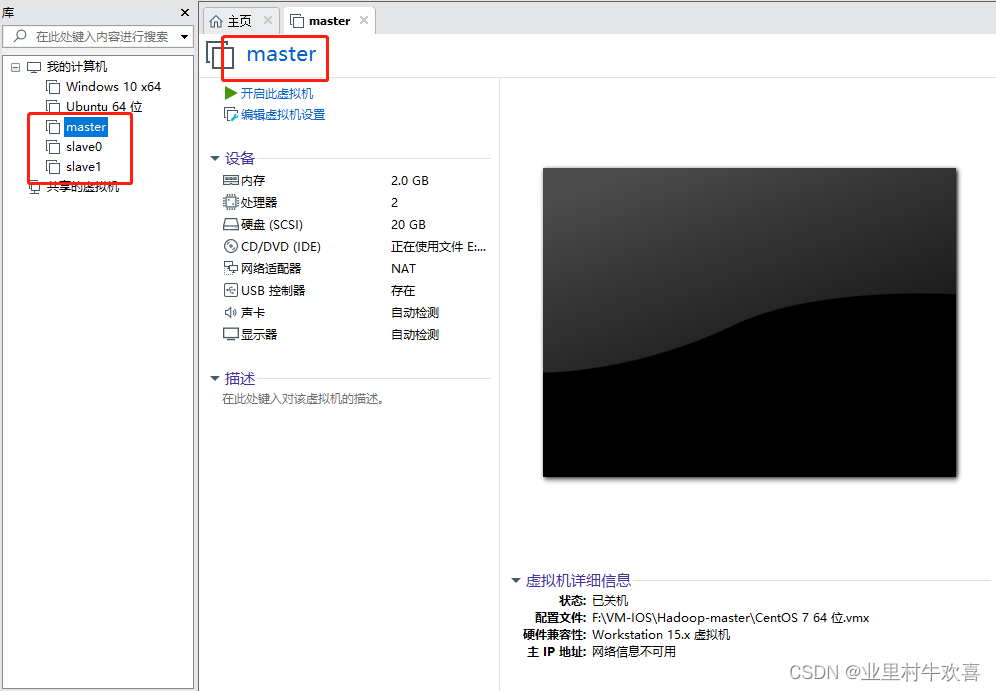
2.4 master主机进行网络配置
登陆成功直接输入下面命令然后回车会出现下面内容
vi /etc/sysconfig/network-scripts/ifcfg-ens33
改成以下内容
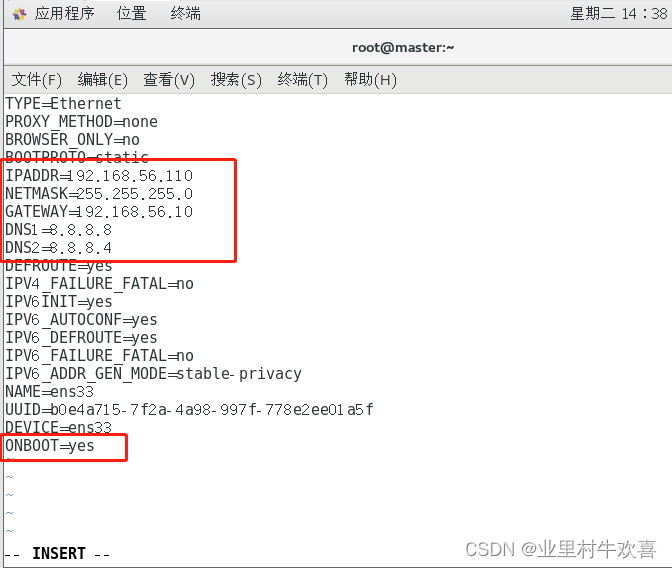
service network restart

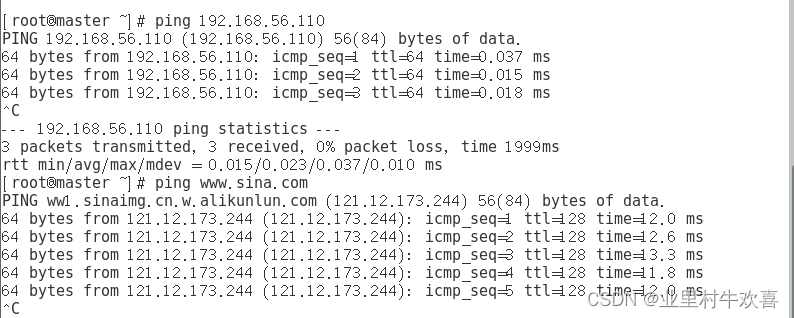
slave0和slave1网络配置
使用同样的方法配置slave0和slave1的网络ip地址,开启服务器成功以后。输入代码
vi /etc/sysconfig/network-scripts/ifcfg-ens33
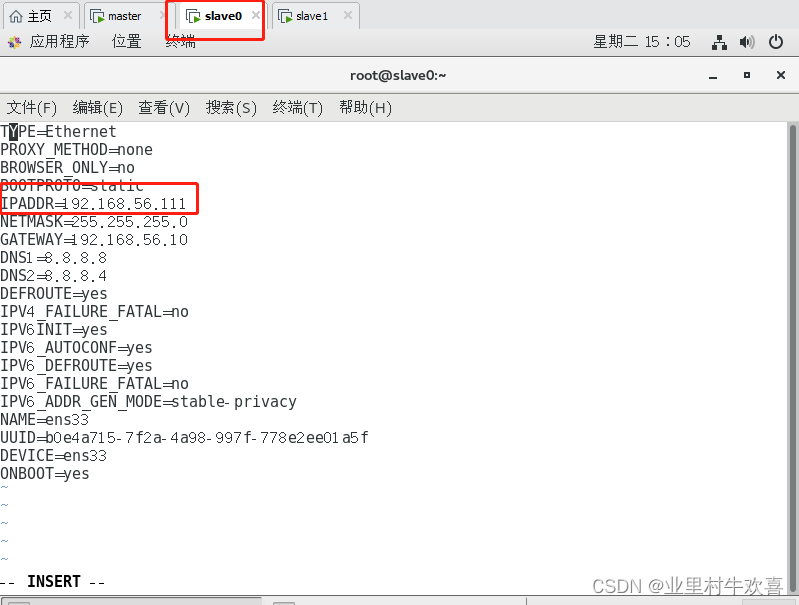
同样的操作,在slave1中操作,配置slave1的网络变成192.168.56.112,配置网络后ping主机地址,然后再ping一下www.sina.com地址,保证互联网访问正常。
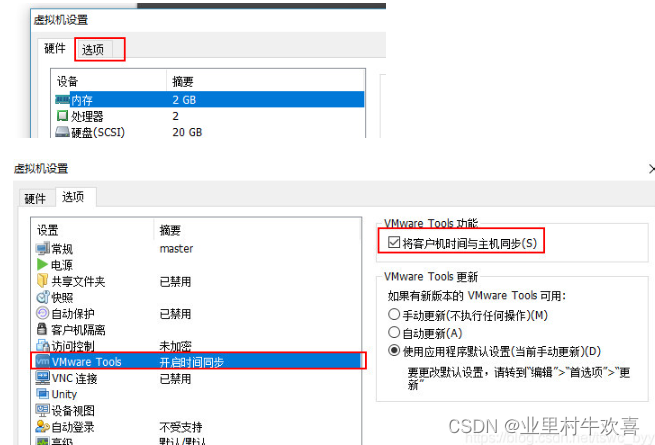
2.5 同步时间
首先先把三台虚拟机关机
2.6 Xshell6的安装与使用
Xshell6的作用
可以同时连接多台服务器,将多台服务器连接在一台软件上操作,这样就不用在每台服务器上进行操作,方便远程操作服务器;主要是对服务器进行命令操作,并行可以操作多台虚拟主机
Xshell6安装(基本上都是默认,这里忽略,选择安装的语言记得中文,英语很强请忽略我。)
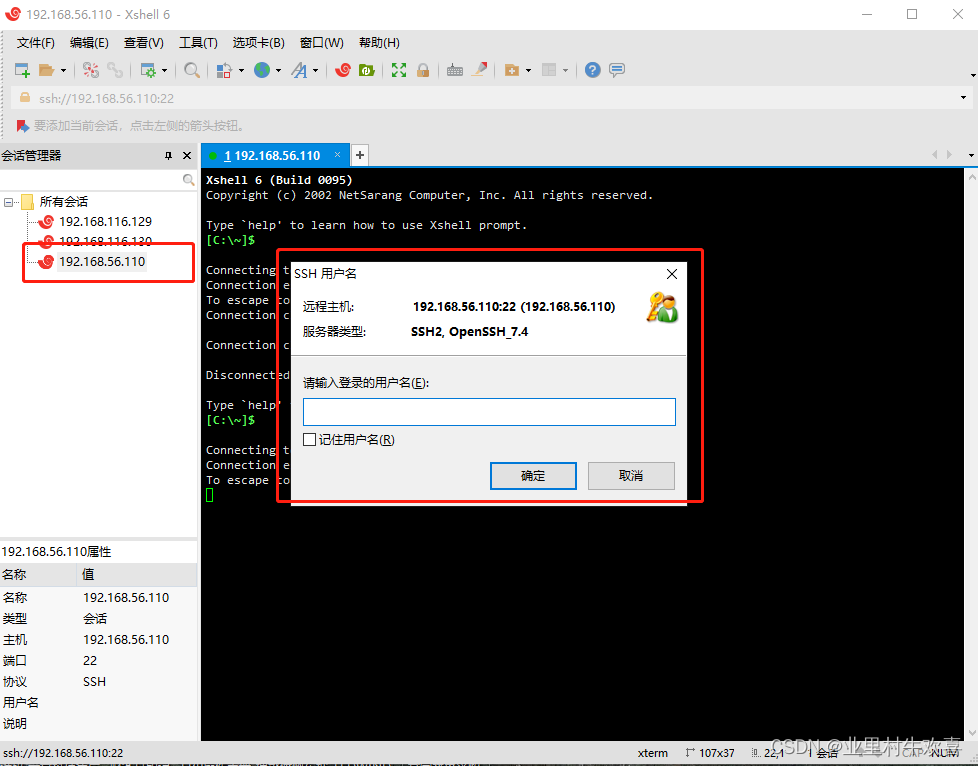
Xshell6的使用
链接master主机地址,输入账号密码即可访问
Xftp6的作用
可以同时连接多台服务器,将多台服务器连接在一台机器上操作,这样就不用在每台服务器上进行操作,方便远程操作服务器;主要是对服务器进行文件传输操作.(安装步骤省略,网上有很多资源可以下载)使用操作说明
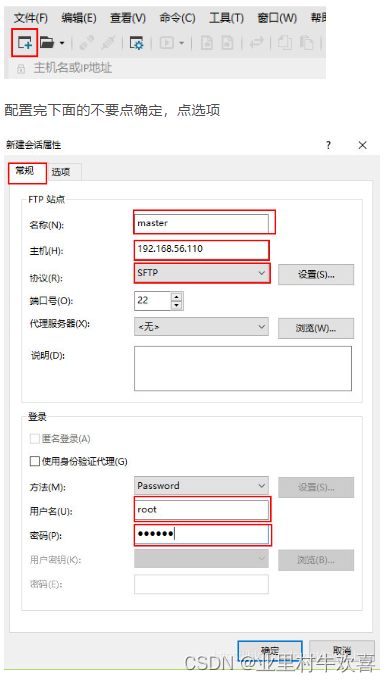
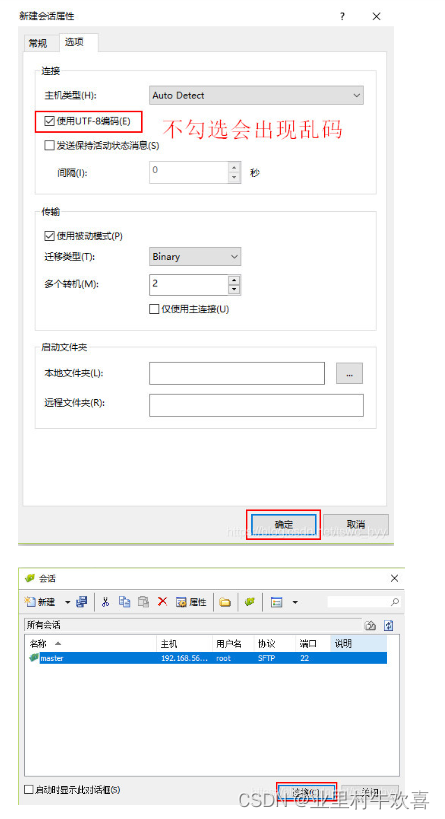
出现桌面文件和master路径文件的话,表示已经成功了。其他的两台机器就不演示操作了。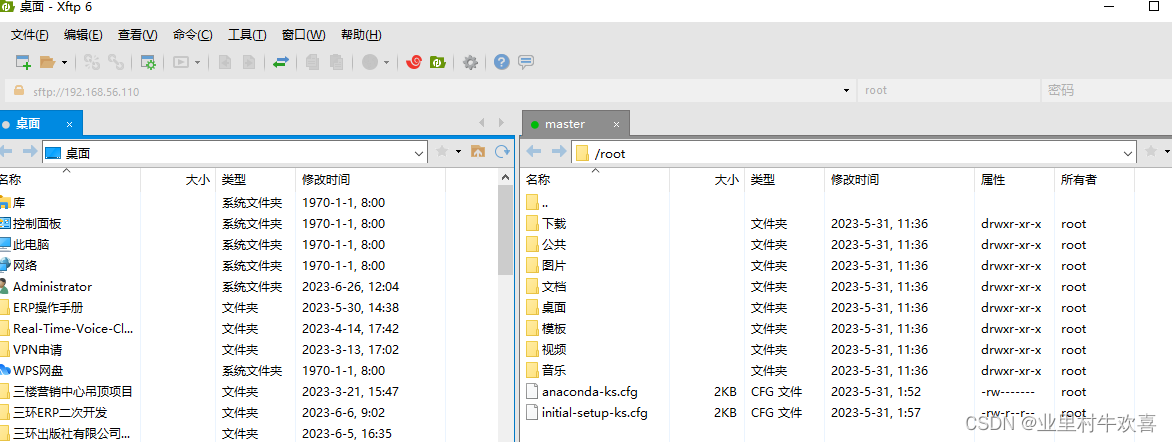
2.7 关闭防火墙
首先打开并登陆master服务器
使用指令查看防火墙状态,一般都是active(running)激活状态,然后用指令关闭防火墙,关闭完后使用systemctl指令加入开机启动项。
systemctl status firewalld.service
systemctl stop firewalld.service
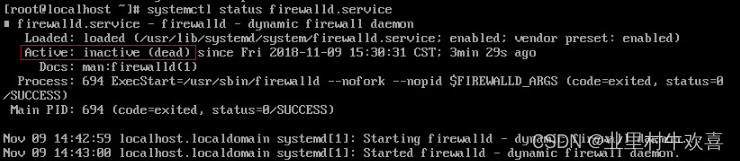
systemctl disable firewalld.service

2.8 设置主机名
先在master服务器上操作’,输入下面命令
vi /etc/sysconfig/network

再次修改主机名字,将hostname中内容删除掉,增加mastert名字操作
vi /etc/hostname

按照上述操作方法,将其他的虚拟机更改主机名字,对应的slave0,slave1都修改。修改完记得重启验证一下,主机名字是否更变。
2.9 hosts设置
使用计算机名进行网络访问,需要修改vi /etc/hosts 文件中的主机名与IP地址的对照列表。三台服务器都需要配置一下(master,slave0,slave1)

免密钥登陆配置
首先在master服务器下面生成秘钥
ssh-keygen -t rsa
然后按四次回车,出现下面内容
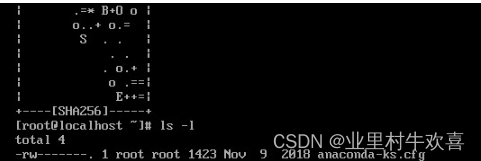
进入根目录文件夹中
cd ~/.ssh
ls -l

然后输入下面命令把公钥文件发送到自己和其它服务器还有发送自己了。
ssh-copy-id -i id_rsa.pub root@master
输入Yes,一直接收

输入root密码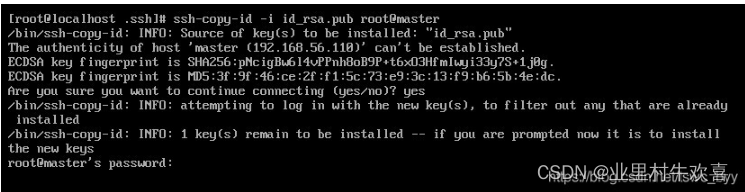
成功后出现下面内容
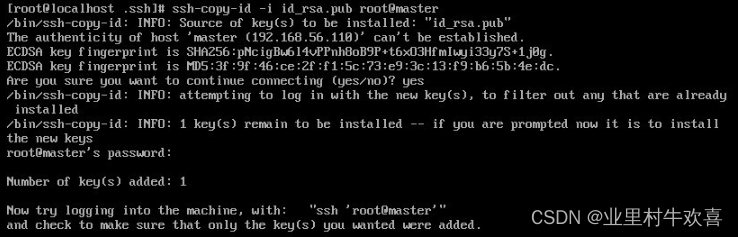
然后再分别发送给slave0和slave1
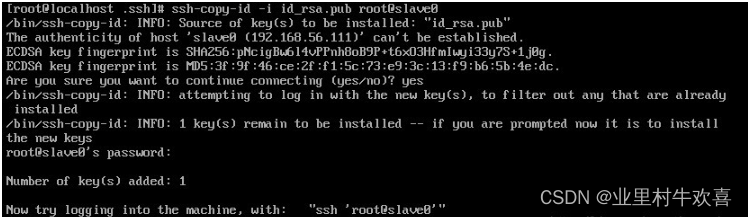
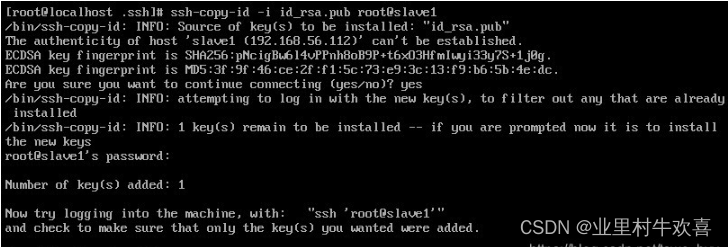
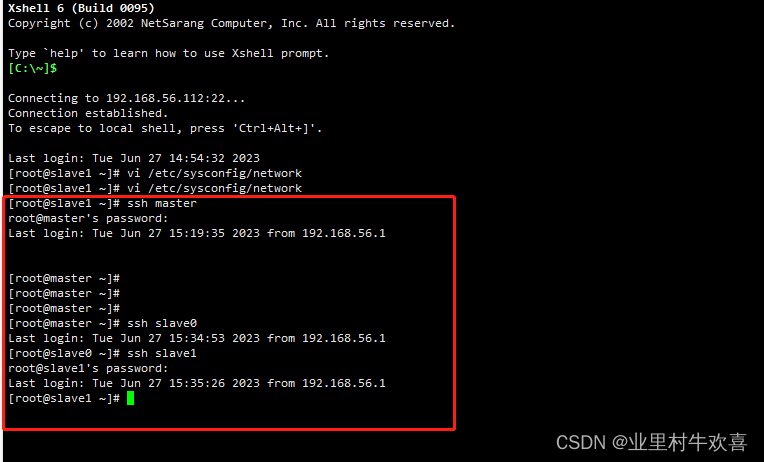
验证是否成功
在master服务器输入下面的命令,都不需要输入密码,就说明成功了,注意每执行完一条命令都用exit退出一下再执行下一条。
2.10 安装JDK
首先在master服务器的usr/local目录下新建一个java文件夹,用下面命令就可以完成
mkdir /usr/local/java
然后用Xftp连接master服务器,打开usr/local/java这个目录,把jdk-8u162-linux-x64.tar复制进去,
使用指令解压
tar -zxvf jdk-8u162-linux-x64.tar.gz
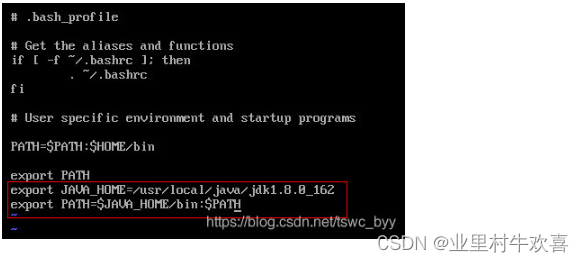
接下来开始配置环境变量,先用cd命令回到总目录

输入下面命令开始配置

增加以下内容,
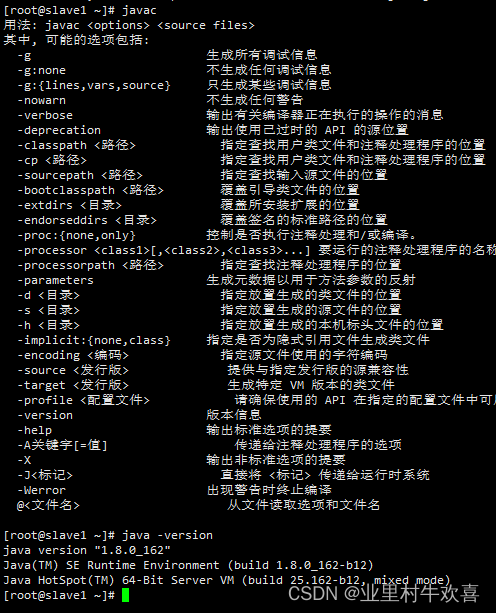
加载环境变量,使用

然后输入java、javac和java -version验证,如果都出现一大堆代码说明配置成功了,如果其中有一个或多个出现不是内部或外部命令,也不是可运行的程序或批处理文件等类似语句,就说明配置失败了,需要重新配置jdk环境。
这样就安装好master服务器的jdk了,但是还没有安装好slave0和slave1的jdk,我们可以用下面命令把master中的jdk复制到slave0上面
scp -r /usr/local/java root@slave0:/usr/local
这时已经把jdk复制到slave0了,但是slave0的环境变量还没有配置,我们同样可以使用下面命令来复制环境变量
scp -r /root/.bash_profile root@slave0:/root
在slave0加载环境变量,同样用java,javac,java-version测试环境。
source /root/.bash_profile
slave1操作和slave0一致,重复操作,进行java测试。
2.11 Hadoop安装与环境配置
先用下面的命令给opt文件夹中新建一个hapoop文件夹,后期配置hadoop文件
mkdir /opt/hadoop
然后把hadoop-2.7.5复制到hadoop文件夹中
使用下面命令进入到hadoop文件夹,进行解压
cd /opt/hadoop
tar -zxvf hadoop-2.7.5.tar.gz
使用mv指令把hadoop-2.7.5文件夹重命名成hadoop
mv hadoop-2.7.5 hadoop
在主服务器master上配置
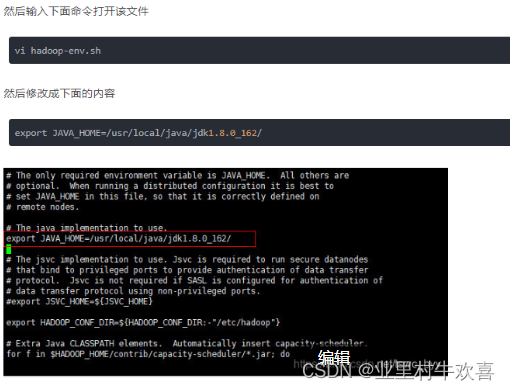
1.配置hadoop-env.sh
该文件设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统设置了JAVA_HOME,它也是不认识的,因为Hadoop即使是在本机上执行,它也是把当前执行的环境当成远程服务器。所以这里设置的目的是确保Hadoop能正确的找到jdk。


在hadoop文件中找到hadoop-env.sh文件进行修改,配置java的路径。
2. 配置core-site.xml
core-site.xm所在的目录和上面的目录一样,所以直接使用下面命令打开该文件即可

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
ee569b5e79d636.png)
在hadoop文件中找到hadoop-env.sh文件进行修改,配置java的路径。
2. 配置core-site.xml
core-site.xm所在的目录和上面的目录一样,所以直接使用下面命令打开该文件即可
[外链图片转存中…(img-UibtbZ23-1714909098037)]
[外链图片转存中…(img-nYcKiYAy-1714909098038)]
[外链图片转存中…(img-weSV4pak-1714909098038)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 2819
2819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









