






首先,我们需要知道为什么线性回归不适用于数据类别。从下图可以看出,第一个用于线性回归,第二个也用于线性但具有二进制类别值。我们可以从这两个图表中得出的见解是,第一个图表具有线性逼近值,即自变量增加,因变量也增加。但是,第二张图没有说明这种行为,而是将因变量值仅标记在两个值上,即“ 0”和“ 1”。
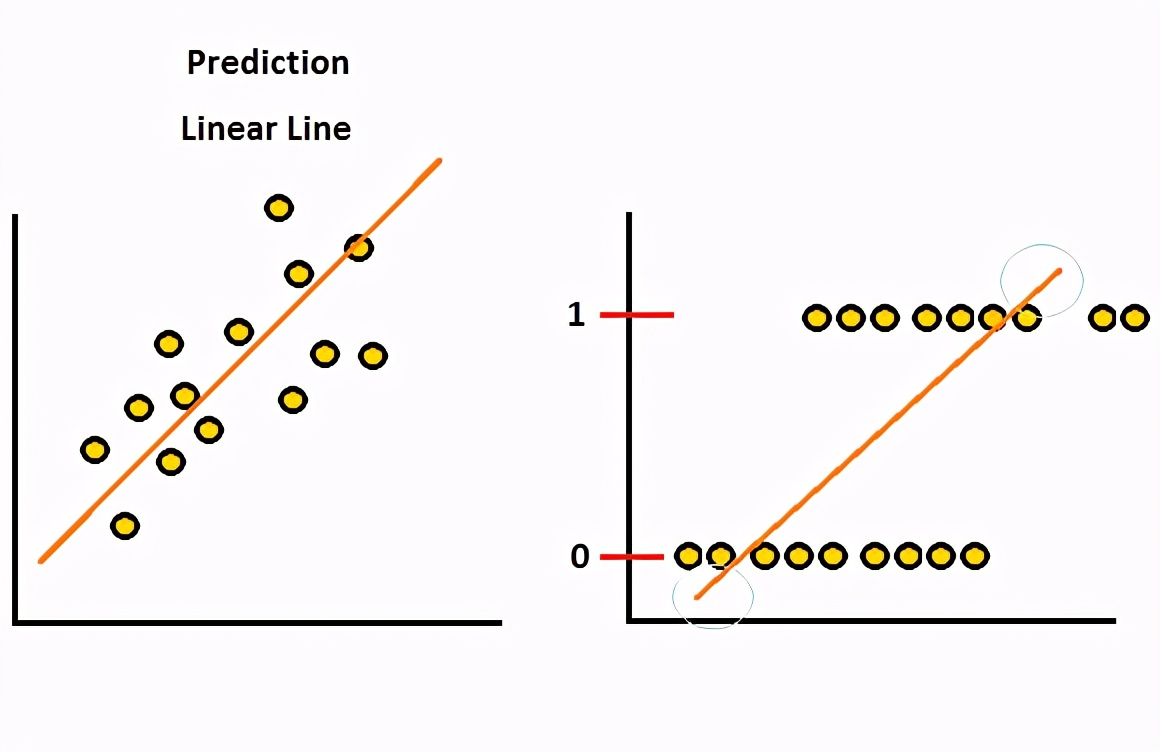
不同类型因变量上的线性方法
如果我们在第二个值上使用线性方法,则错误率将增加,我们的模型将无法很好地拟合,还有一点需要注意的是,线性线在数据点的上方和下方越来越多,而我们不需要预言。因此,我们需要一种仅将预测设置为“ 0”和“ 1”的方法。
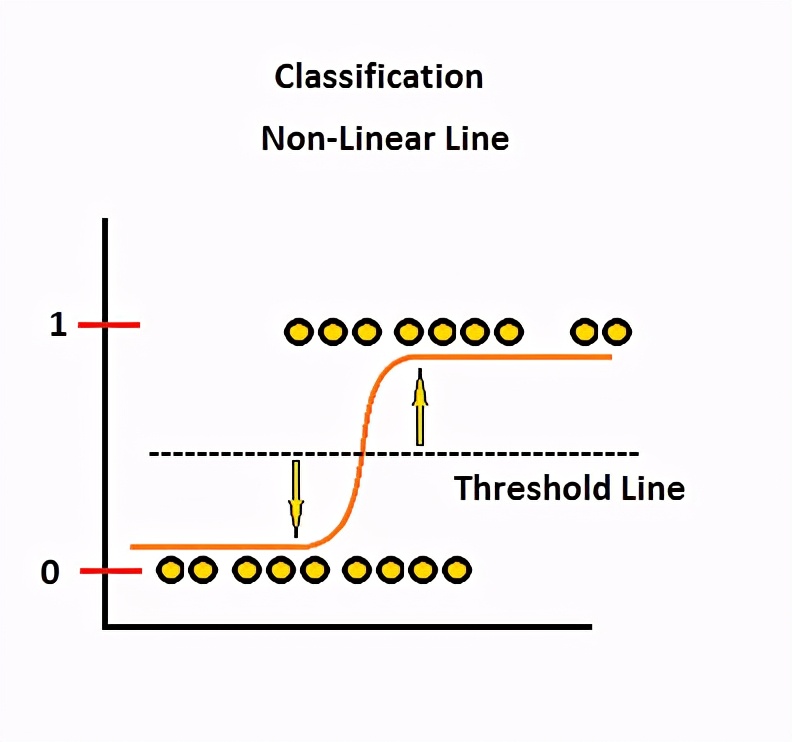
从这个想法,我们可以考虑概率值从“ 0”到“ 1”的概率。好的,但是我们还需要更改我们的预测线。许多功能基于某个阈值将值设置为“ 0”和“ 1”。该曲线可以称为逻辑回归曲线或逻辑函数。
Logit回归模型如下所示。
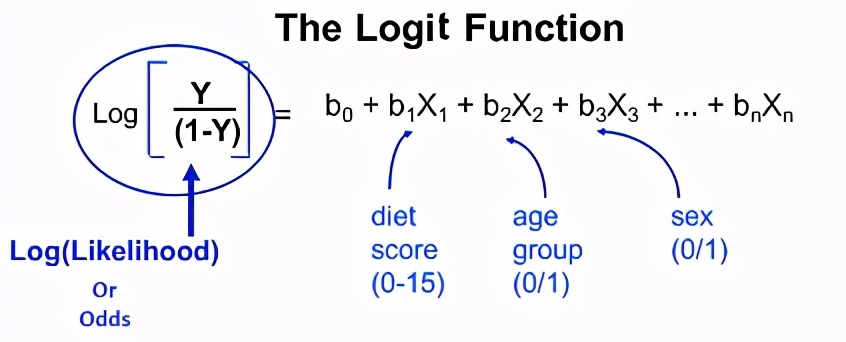
因此,几率的对数等于线性模型。
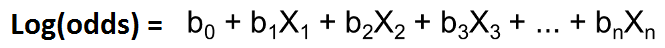
logit函数比普通的logistic函数更具解释性。因此,此函数不过是一个Sigmoid函数,它给出“ 0”和“ 1”中的值。
当我们尝试拟合我们的模型时,它将在内部计算迭代和函数值。这两个词都意味着经过多次迭代后,模型优化将无法工作,并且函数值中获得的值就是目标函数的值,通过该值我们可以收敛。
现在让我们使用python进行实际操作。
我们创建了一个小数据集来解释逻辑回归中二进制输出的分类方法。
#importing the libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings(“ignore”)
现在读取excel文件并查看其前5行。
df = pd.read_excel(“logistic.xlsx”)
df.head()
将数据集分为一个独立变量和因变量。
x = df.iloc[:,[0,1]].values
y = df.iloc[:,2].values
现在,将数据分为训练数据和测试数据。
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size =
0.25, random_state = 0)
标准化数据,以使数量的变化变得正常。
from sklearn.preprocessing import StandardScaler
sc_x = StandardScaler()
x_train = sc_x.fit_transform(x_train)
x_test = sc_x.transform(x_test)
拟合训练集以适合模型。
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(x_train, y_train)
用分类器进行预测。
y_pred = classifier.predict(x_test)
生成混淆矩阵。
from sklearn.metrics import confusion_matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print (“Confusion Matrix : \n”, conf_matrix)
#output:
Confusion Matrix :
[[10 0]
[ 0 10]]
检查逻辑模型的准确性。
from sklearn.metrics import accuracy_score
print ("Accuracy : ", accuracy_score(y_test, y_pred))
#output:
Accuracy : 1.0
绘制二进制分类模型。
from matplotlib.colors import ListedColormap
X_set, y_set = x_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1,
stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1,
stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(
np.array([X1.ravel(), X2.ravel()]).T).reshape(
X1.shape), alpha = 0.75, cmap = ListedColormap((‘red’, ‘green’)))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
❤️ 谢谢支持
喜欢的话别忘了 关注、点赞哦~。

.ravel()]).T).reshape(
X1.shape), alpha = 0.75, cmap = ListedColormap((‘red’, ‘green’)))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
❤️ 谢谢支持
喜欢的话别忘了 关注、点赞哦~。
[外链图片转存中…(img-ZztM3Cq6-1718873873078)]















 1896
1896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









