







在一个已经排好的有序数据序列中插入一个数,且要求插入后此数据序列仍然有序,这个时候就要用到一种的排序方法——插入排序法,一般也称直接插入排序。
排序思想
一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前遍历
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
- 如果比较操作的代价比交换操作大的话,可以采用二分查找法来减少比较操作的数目。该算法可以认为是插入排序的一个变种,称为二分查找插入排序。
实现

实现代码:
public static void insertSort(int[] array) {
for(int i = 1;i < array.length;i++) {//n-1
int tmp = array[i];
int j = i-1;
for(; j >= 0;j--) {//n-1
if(array[j] > tmp) {
array[j+1] = array[j];
}else{
//array[j+1] = tmp;
break;
}
}
array[j+1] = tmp;
}
}
排序性能分析
若目标是把n个元素的序列升序排列,那么采用插入排序的最好情况就是,序列已经是升序排列了,在这种情况下,需要进行的比较操作需n-1次即可。最坏情况就是,序列是降序排列,那么此时需要进行的比较共有(1/2)*n(n-1)次。插入排序的赋值操作是比较操作的次数减去n-1次,因为n-1次循环中,每一次循环的比较都比赋值多一个,多在最后那一次比较并不带来赋值)。平均来说插入排序算法复杂度为O(n^2)。因而,插入排序不适合对于数据量比较大的排序应用。但是,如果需要排序的数据量很小,或者若已知输入元素大致上按照顺序排列,那么还是比较适合使用插入排序的
总结
- 时间复杂度:最好:O(N);最坏O(N^2)
- 空间复杂度O(1)
- 稳定性:稳定
- 当一组数据的数据量比较少且趋于有序时,用插入排序比较好
- 数据越有序越快
希尔排序
原理
希尔排序(Shell’s Sort)又称“缩小增量排序”(Diminishing Increment Sort),它也是一种属插入排序类的方法,但在时间 率上较前述几种排序方法有较大的改进。从对直接插入排序的分析得知,其算法时间复杂度为O(n^2),但是,若待排记录序列为“正序”时,其时间复杂度可提高至O(n)。它的基本思想是:先将整个待排记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行一次直接插入排序。
| 简单来说,希尔排序主要的思想是对一组数据进行预排序,当数据逐渐接近有序时再进行整体排序,这样算法的效率会大大提升 |
| 希尔排序的分析是一个复杂的问题,因为它的时间是所取“增量”序列的函数,这涉及一些微学上尚未解决的难题。因此,到目前为止尚未有人求得一种最好的增量序列,增量序列可以有各种取法,但需注意:应使增量序列中的值没有除1之外的公因子,并且最后一个增量值必须等于1。 |
实现

当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果
实现代码:
public static void shell(int[] array,int gap) {
for (int i = gap; i < array.length; i++) {
int tmp = array[i];
int j = i-gap;
for (; j >= 0; j -= gap) {
if(array[j] > tmp) {
array[j+gap] = array[j];
}else {
break;
}
}
array[j+gap] = tmp;
}
}
public static void shellSort(int[] array) {
//处理gap
int gap = array.length;
while (gap > 1) {
gap = gap / 3 + 1;//+1 保证最后一个序列是 1 除几都行
// gap /= 2;
shell(array,gap);
}
}
排序性能分析
由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,可理解为元素可能会跳跃式移动,所以最后其稳定性就会被打乱,因此shell排序是不稳定的。
时间复杂度:不同的增量序列会产生不同的时间复杂度,比如有人提出当增量序列为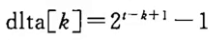
是,其时间复杂度为
其中t为排序趟数,且: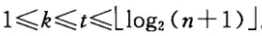
总结:
- 稳定性:不稳定
- 时间复杂度:不确定,但可以记为N(1.3) 到N(1.5) 之间
选择排序
原理
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
实现

实现代码:
public static void selectSort(int[] array) {
for (int i = 0; i < array.length; i++) {
for (int j = i+1; j < array.length; j++) {
if(array[j] < array[i]) {
int tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
}
}
}
排序性能分析
选择排序较为简单,其最好的情况和最坏的情况下程序执行的次数是一样的,因此时间复杂度是一个定值
总结
- 时间复杂度:O(N2 )
- 空间复杂度:O(1)
堆排序
原理
- 堆排序是利用堆这种数据结构设计出的一种排序算法,其是选择排序的一种,它利用大顶堆(小顶堆)堆顶元素是最大值(最小值)这一特性,使得每次从无序中选择最大值(最小值)变得简单。
- 排升序要建大堆;排降序要建小堆。
具体步骤如下
step1:先将带排序的数组构造成一个大根堆,假设有如下数组:int[] array2={2,3,4,1,6,5};

构造成大根堆如下:

step2:将堆顶元素与堆尾元素交换:
step3:将除6以外其他的所有元素继续构造大根堆:
以此类推,然后再将堆顶元素与堆中倒数第二个元素交换,换完之后除了倒数第一个和倒数第二个元素以外,其他元素继续构造成大堆,最终会得到有序的数组
同理,如果要从大到小排,则构建小堆即可!
实现
public static void siftDown(int[] array,int root,int len) {
int parent = root;
int child = 2\*parent+1;
while (child < len) {
//找到左右孩子的最大值
//1、前提是你得有右孩子
if(child+1 < len && array[child] < array[child+1]) {
child++;
}
//child的下标就是左右孩子的最大值下标
if(array[child] > array[parent]) {
int tmp = array[child];
array[child] = array[parent];
array[parent] = tmp;
parent = child;
child = 2\*parent+1;
}else {
break;
}
}
}
public static void createHeap(int[] array) {
//从小到大排序 -》 大根堆
for (int i = (array.length-1 - 1) / 2; i >= 0 ; i--) {
siftDown(array,i,array.length);
}
}
public static void heapSort(int[] array) {
createHeap(array);//O(n)
int end = array.length-1;
while (end > 0) {//O(N\*logN)
int tmp = array[end];
array[end] = array[0];
array[0] = tmp;
siftDown(array,0,end);
end--;
}
}
排序性能分析
- 时间复杂度:O(N* log(N))(最好和最坏的都是这个)
- 空间复杂度:O(1)(在整个调整的过程中并没有重新定义数组)
- 稳定性:不稳定
这个堆排序我上一篇博客中有详细地讲过哦,相信大家看完后一定会有收获的有关堆的相关知识点

冒泡排序
原理
冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。一直重复进行上述步骤,直到没有元素再需要交换,也就是说该数列已经排序完成。
实现

public static void bubbleSort(int[] array) {
for (int i = 0; i < array.length-1; i++) {
for (int j = 0; j < array.length-1-i; j++) {
if(array[j] > array[j+1]) {
int tmp = array[j];
array[j] = array[j+1];
array[j+1] = tmp;
flg = true;
}
}
}
}
排序性能分析
- 时间复杂度:最好/最坏:O(N2 ),若优化,则最好的情况下时间复杂度为O(n)
- 空间复杂度:O(1)
- 稳定性:稳定
优化方法
public static void bubbleSort(int[] array) {
// boolean flg = false;
for (int i = 0; i < array.length-1; i++) {
boolean flg = false;
for (int j = 0; j < array.length-1-i; j++) {
if(array[j] > array[j+1]) {
int tmp = array[j];
array[j] = array[j+1];
array[j+1] = tmp;
flg = true;
}
}
if(flg == false) {
break;
}
}
}
设置一个flg,若当前排序时已经有序,可以提前结束本次循环
快速排序
原理
- 快速排序是对冒泡排序的一种改进。
- 排序前首先选择一个基准值(pivot)将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再对左右两个区间选取基准值,重复此步骤,采用分治思想,对左右两个小区间按照同样的方式处理,直到小区间的长度为1,代表已经有序,或者小区间的长度为0,代表没有数据,排序完成!整个排序过程可以递归进行,也可以非递归进行(如使用栈)
基准的选取(递归实现快速排序)
挖坑法
定义两个变量,假如数组的首元素位置下标是low,数组的尾元素位置下标是high,挖坑法为固定位置选取基准法,比如让low下标的元素作为基准,让其存到临时变量tmp当中,然后将high从后往前遍历,找比tmp的值小的数字,若找到,则将这个值存到low下标对应的位置中。接着让low从左到右遍历去找比tmp的值大的元素,若找到,则将其值存到high下标对应的位置中,以此循环。直到low和high相遇,那么就把tmp的值放到相遇位置作为基准即可。这样即可实现把要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小了

实现代码:
public static int partition(int[] array,int low,int high) {
int tmp = array[low];
while (low < high) {
while (low < high && array[high] >= tmp) {
high--;
}
array[low] = array[high];
while (low < high && array[low] <= tmp) {
low++;
}
array[high] = array[low];
}
array[low] = tmp;
return low;
}
有了基准后,就可以进行快速排序的下一步了,然后再对左右两个小区间选取基准值进行排序,下面我们将使用递归的方法:
import java.util.Arrays;
public class TestDemo {
public static int partition(int[] array,int low,int high) {
int tmp = array[low];
while (low < high) {
while (low < high && array[high] >= tmp) {
high--;
}
array[low] = array[high];
while (low < high && array[low] <= tmp) {
low++;
}
array[high] = array[low];
}
array[low] = tmp;
return low;
}
public static void quick(int[] array,int start,int end) {
if(start >= end) {
return;
}
int pivot = partition(array,start,end);
quick(array,start,pivot-1);
quick(array,pivot+1,end);
}
public static void quickSort1(int[] array) {
quick(array,0,array.length-1);
}
public static void main(String[] args) {
int[] array={12,5,37,41,55,28,6,1,69,17};
quickSort1(array);
System.out.println(Arrays.toString(array));
}
}
打印的结果为: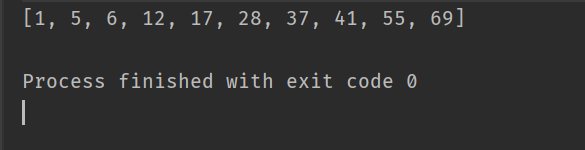
排序完成!
性能分析
- 时间复杂度:
最好情况:O(N*logN)(每一次排序时分割区间都是均匀的)
最坏情况:O(N2)(对已经有序的一对数据排序)
- 空间复杂度:
最好:O(logN)
最坏:O(N)
- 稳定性:不稳定
三数取中
对于上述用挖坑法递归进行快速排序时,因为空间复杂度为O(n),那么当数据足够多时且越趋于有序而导致排序分割的区间不均匀时,那可能会栈溢出(因为递归是在栈上开辟内存的),因此,我们可以用三数取中来实现让排序的区间更趋于均匀,从而提升算法的效率。
具体思路:
让low下标等于数组首元素位置,让high等于数组最后一个元素的位置,定义一个mid使其等于数组的中间位置,然后让low下标的值等于这三个下标对应的值第二大的,即中间大小的值
实现代码:
mport java.util.Arrays;
public class TestDemo {
public static int partition(int[] array,int low,int high) {
int tmp = array[low];
while (low < high) {
while (low < high && array[high] >= tmp) {
high--;
}
array[low] = array[high];
while (low < high && array[low] <= tmp) {
low++;
}
array[high] = array[low];
}
array[low] = tmp;
return low;
}
public static void swap(int[] array,int i,int j) {
int tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
public static void selectPivotMedianOfThree(int[] array,int start,int end,int mid) {
//array[mid] <= array[start] <= array[end]
if(array[mid] > array[start]) {
swap(array,start,mid);
}// array[mid] <= array[start]
if(array[start] > array[end]) {
swap(array,start,end);
}// array[start] <= array[end]
if(array[mid] > array[end]) {
swap(array,start,end);
}// array[mid] <= array[end]
}
public static void quick(int[] array,int start,int end) {
if(start >= end) {
return;
}
int mid = (start+end)/2;
selectPivotMedianOfThree(array,start,end,mid);
int pivot = partition(array,start,end);
quick(array,start,pivot-1);
quick(array,pivot+1,end);
}
public static void quickSort1(int[] array) {
quick(array,0,array.length-1);
}
public static void main(String[] args) {
int[] array={12,5,37,41,55,28,6,1,69,17};
quickSort1(array);
System.out.println(Arrays.toString(array));
}
}
优化
利用递归法求基准进行快速排序时,当分割的区间越来越小时,其区间内的数据越趋于有序,因此我们可以设定一个区间范围,然后在这个区间范围进行直接插入排序,排好序之后就不再递归了,这样可以大大提高算法的效率
直接插入排序部分代码:
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1444
1444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









