







最后
现在其实从大厂招聘需求可见,在招聘要求上有高并发经验优先,包括很多朋友之前都是做传统行业或者外包项目,一直在小公司,技术搞的比较简单,没有怎么搞过分布式系统,但是现在互联网公司一般都是做分布式系统。
所以说,如果你想进大厂,想脱离传统行业,这些技术知识都是你必备的,下面自己手打了一份Java并发体系思维导图,希望对你有所帮助。

if (L[tn])
Q.push(L[tn]);
if (R[tn])
Q.push(R[tn]);
}
puts(“”);
}
int main() {
int N;
scanf(“%d”, &N);
for (int i = 1; i <= N; i++)
scanf(“%d”, &a[i]);
for (int i = 1; i <= N; i++)
scanf(“%d”, &b[i]);
int root = build(1, N, 1, N);
bfs(root);
return 0;
}
#include
#include
using namespace std;
struct Node {
int data;
Node* lc, * rc;
};
Node* buildTree(int* post, int* in, int n) {
if (n == 0)
return NULL;
int* mid = in;
while (*(post + n - 1) != *mid)mid++;
Node* T = new Node;
T->data = *mid;
int m = mid - in;
T->lc = buildTree(post, in, m);
T->rc = buildTree(post + m, mid + 1, n - 1 - m);
return T;
}
int main() {
queue<Node*>q;
int N, post[30], in[30], vis[30];
cin >> N;
for (int i = 0; i < N; ++i)
cin >> post[i];
for (int i = 0; i < N; ++i)
cin >> in[i];
q.push(buildTree(post, in, N));
int i = 0;
while (!q.empty()) {
cout << (i++ ? " " : “”) << q.front()->data;
if (q.front()->lc)q.push(q.front()->lc);
if (q.front()->rc)q.push(q.front()->rc);
q.pop();
}
return 0;
}
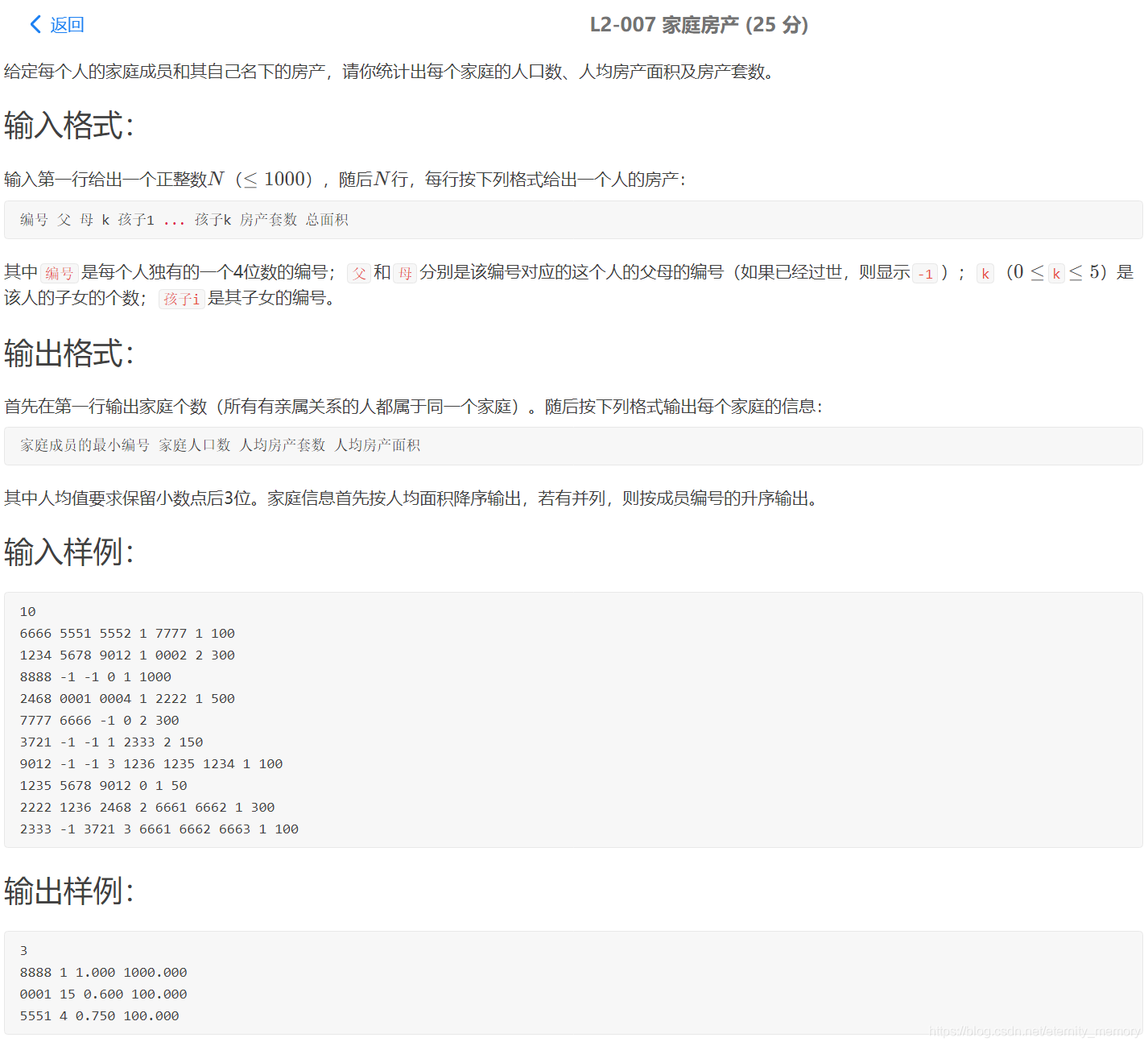
#include<bits/stdc++.h>
using namespace std;
struct node{
int upset,squ,cnt;
node(){
cnt = 1;
upset = 0;
squ = 0;
}
}s[10005];
struct GG{
double cnt,upset,squ;
int id;
};
int pre[10005];
bool flag[10005]; //刚开始不都是false 如果有出现就true
int find(int x){
if( x == pre[x])
return x;
return pre[x] = find(pre[x]);
}
void merge(int x, int y){
int fx = find(x);
int fy = find(y);
if(fx > fy)
pre[fx] = fy;
else if(fx < fy)
pre[fy] = fx;
return;
}
bool cmp(GG a, GG b){
if(a.squ != b.squ)
return a.squ > b.squ;
else
return a.id < b.id;
}
int main(){
int n;
scanf(“%d”, &n);
for(int i = 1; i <= 10000; i ++)
pre[i] = i;
int me, fa, mo, cnt, child;
for(int i = 1; i <= n; i ++)
{
scanf(“%d %d %d”,&me,&fa,&mo);
flag[me] = true;
if(fa != -1)
{
merge(me, fa);
flag[fa] = true;
}
if(mo != -1)
{
merge(me, mo);
flag[mo] = true;
}
scanf(“%d”,&cnt);
for(int j = 1; j <= cnt; j ++ )
{
scanf(“%d”,&child);
merge(child, me);
flag[child] = true;
}
scanf(“%d %d”,&s[me].upset, &s[me].squ);
}
setst;
for(int i = 10000; i >= 0; i–) //这边wa了第四个测试点因为0—10000 我写成1----10000
{
if(flag[i] == true)
{
int x = find(i);//找到它的祖先
st.insert(x);
if(x != i)
{
s[x].cnt += s[i].cnt;
s[x].squ += s[i].squ;
s[x].upset += s[i].upset;
}
}
}
set::iterator it = st.begin();
vectorvec;
while(it!=st.end())
{
GG gg;
gg.id = *it;
gg.cnt = s[*it].cnt;
gg.squ =s[*it].squ * 1.0 / s[*it].cnt * 1.0;
gg.upset = s[*it].upset * 1.0 / s[*it].cnt * 1.0;
vec.push_back(gg);
it++;
}
sort(vec.begin(),vec.end(),cmp);
printf(“%d\n”,vec.size());
for(int i = 0 ; i < vec.size(); i++)
printf(“%04d %.0lf %.3lf %.3lf\n”,vec[i].id, vec[i].cnt,vec[i].upset, vec[i].squ);
return 0;
}
#include
#include
#include
#include
#include
using namespace std;
const int maxn = 1e5 + 10;
struct node {
int id, houses;
double area;
};
struct family {
int id, members;
double ave_houses, ave_area;
};
bool cmp(const family &a, const family &b) {
if (a.ave_area != b.ave_area) return a.ave_area > b.ave_area;
return a.id < b.id;
}
int pre[maxn];
int find(int x) {
return x == pre[x] ? x : pre[x] = find(pre[x]);
}
int union0(int x, int y) {
int fx = find(x), fy = find(y);
if (fx != fy) {
pre[fx] = fy;
return 1;
}
return 0;
}
int main() {
for (int i = 0; i < maxn; i++) pre[i] = i;
set v;
map<int, node> nodes;
int n;
cin >> n;
while (n–) {
int id, p1, p2, k, houses;
double area;
cin >> id >> p1 >> p2 >> k;
v.insert(id);
if (p1 != -1) {
v.insert(p1);
union0(p1, id);
}
if (p2 != -1) {
v.insert(p2);
union0(p2, id);
}
while (k–) {
int id1;
cin >> id1;
v.insert(id1);
union0(id1, id);
}
cin >> houses >> area;
nodes[id] = node{id, houses, area};
}
set sset;
map<int, vector > mmap;
for (auto it = v.begin(); it != v.end(); it++) {
int fa = find(*it);
mmap[fa].push_back(*it);
sset.insert(fa);
}
cout << sset.size() << endl;
vector families;
for (auto it = sset.begin(); it != sset.end(); it++) {
int fa = find(*it), sz = mmap[fa].size();
double hs = 0, area = 0;
for (int i = 0; i < sz; i++) {
hs += nodes[mmap[fa][i]].houses;
area += nodes[mmap[fa][i]].area;
}
families.push_back(family{mmap[fa][0], sz, hs / sz, area / sz});
}
sort(families.begin(), families.end(), cmp);
for (int i = 0; i < families.size(); i++) {
printf(“%04d %d %.3lf %.3lf”, families[i].id, families[i].members, families[i].ave_houses, families[i].ave_area);
if (i < families.size() - 1) puts(“”);
}
return 0;
}
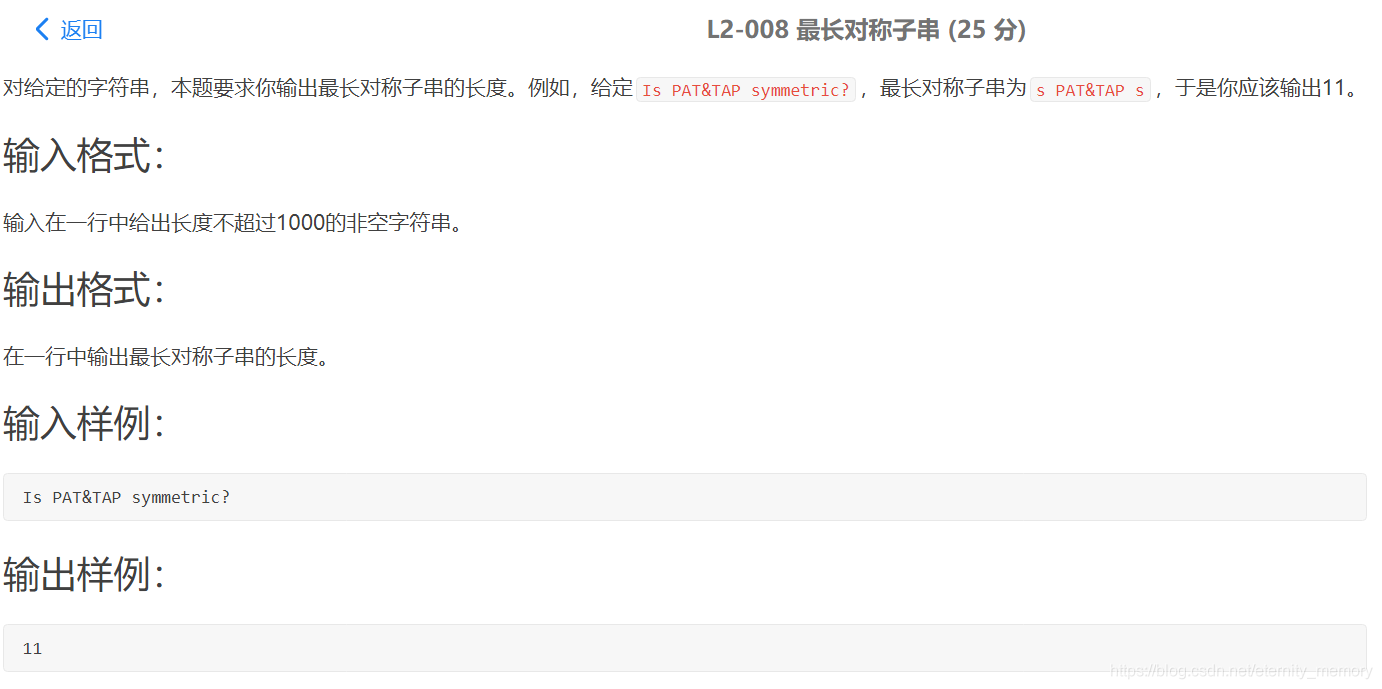
#include<bits/stdc++.h>
using namespace std;
string s;
int main()
{
getline(cin,s);
int ans=-1;
for(int i=0;i<s.size();i++)
{
for(int j=s.size()-1;j>=i;j–)
{
int l=i,r=j;
while(s[l]==s[r] && l<=r)
{
l++;
r–;
}
if(l>r)
{
ans=max(ans,j-i+1);
}
}
}
cout<<ans;
return 0;
}
#include<bits/stdc++.h>
using namespace std;
#define ll long long
string s;
char p[5000];
int len[5000];
void init()
{
p[0]=‘@’;
int l=s.length();
for(int i=1;i<=l*2;i+=2)
{
p[i]=‘#’;p[i+1]=s[i/2];
}
p[l*2+1]=‘#’;
p[l*2+2]=‘!’;
}
int main()
{
ios::sync_with_stdio(false);
getline(cin,s);
init();
int po=0,mx=0,maxn=0,l;//po最长子串的中心点,mx最长子串的右端点
l=strlen§;
for(int i=1;i<=l;i++)
{
if(i<mx) len[i]=min(len[2*po-i],mx-i);
else len[i]=1;
while(p[i-len[i]]==p[i+len[i]]) //中心扩展
len[i]++;
if(i+len[i]>mx)//更新
{
mx=i+len[i];po=i;
}
maxn=max(maxn,len[i]);
}
cout<<maxn-1;//子串长度为len[i]-1
return 0;
}
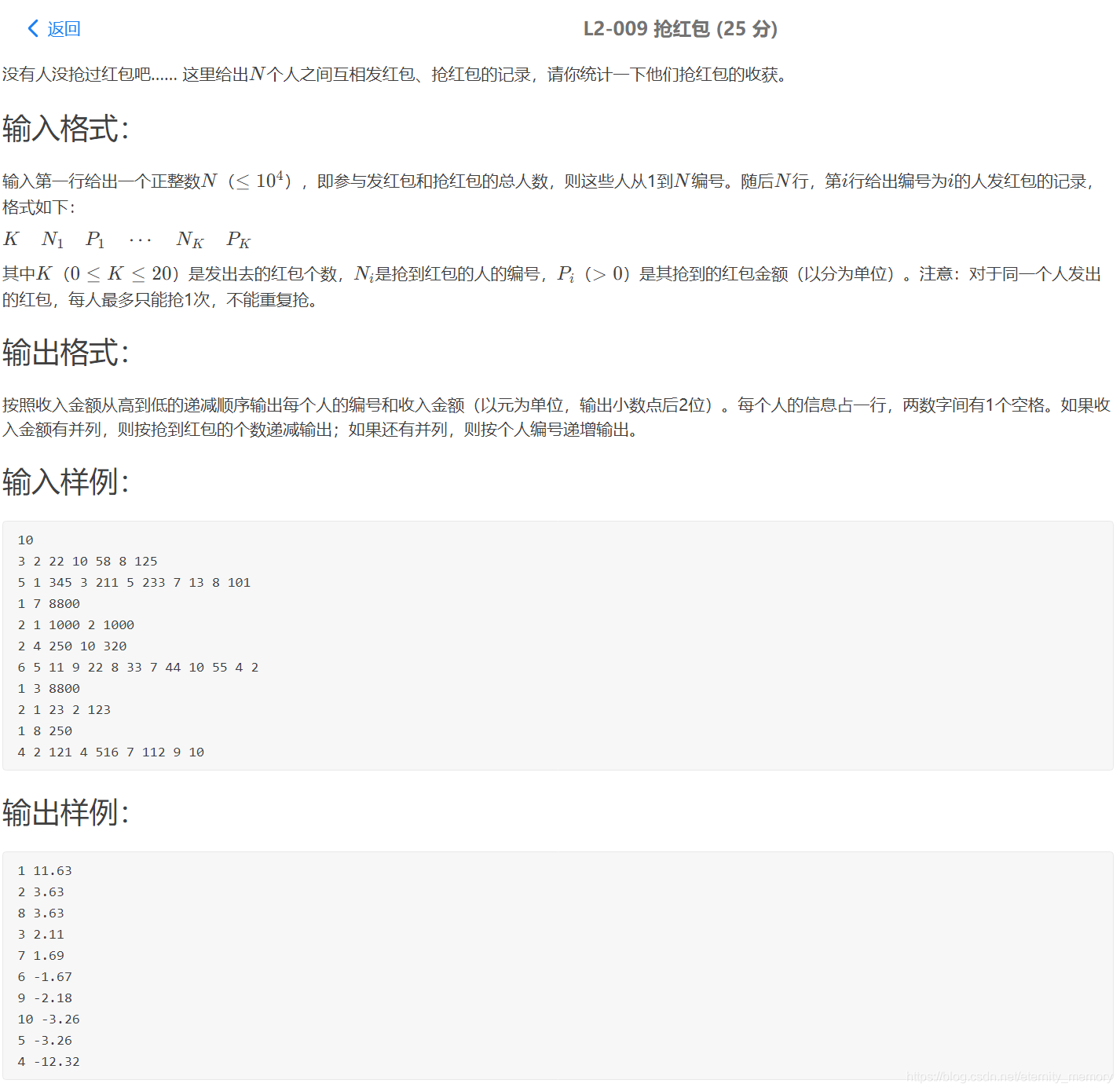
#include<bits/stdc++.h>
using namespace std;
struct T{
int id;//存储id
int money;//钱数
int sumHb;//红包个数
};
auto cmp=[](T &e1,T &e2){//用来排序的规则
return tie(e2.money,e2.sumHb,e1.id)<tie(e1.money,e1.sumHb,e2.id);
};
int main(){
int N;
cin>>N;
map<int,int>val;
map<int,int>hb;
vectorflag;
for(int i=1;i<=N;i++){
int num,sum=0;
cin>>num;
for(int j=1;j<=num;j++){
int id,mon;
cin>>id>>mon;
if(count(flag.begin(),flag.end(),id)==0){//用来判断id有没有重复抢红包
sum+=mon;//用来统计编号i发放的红包总额
val[id]+=mon;//抢到红包的人 增加其金钱总额
hb[id]++;//存放编号i发放的红包个数
flag.push_back(id);
}
}
val[i]-=sum;//从编号i已有的金钱数减去发放红包的钱数
flag.clear();//清空容器
}
vectorss;//存放编号id 收入金额 红包个数
for(auto item : val){
ss.push_back({item.first,item.second,hb[item.first]});
}
sort(ss.begin(),ss.end(),cmp);//排序
for(int i=0;i<ss.size();i++){
printf(“%d %.2f”,ss[i].id,(ss[i].money*1.0)/100);
if(i+1!=ss.size())
cout<<endl;
}
return 0;
}
#include//C++头文件的标准写法;
#include
using namespace std;
#include//包含了sort函数;
struct node
{
int id;//人的编号;
int num;//人抢到红包的个数;
int value;//抢到红包的金额;
}person[10000];
bool f(struct node a,struct node b)
{
if(a.value!=b.value)//如果金额没有并列,则按照总金额从达到小的顺序递减输出;
{
return a.value>b.value;
}
else if(a.num != b.num)//金额有并列,则按照抢到红包的个数递减输出;
{
return a.num>b.num;
}
else if(a.id != b.id)//如果金额和抢到红包的个数都有并列,则按照人的编号递增输出;
{
return a.id<b.id;
}
}
int main()
{
int n,k,p,i,j,sum=0,n1;//k指的是抢到红包的个数,n指的是抢红包人的编号,p指的是抢到红包的金额;
cin>>n;
for(i=1;i<=n;i++)
{
person[i].id = i;//编号是i的人对应的id值是i;
cin>>k;
sum=0;
for(j=1;j<=k;j++)
{
cin>>n1>>p;
// person[n1].id = n1;易错点,因为你不知道每个人都抢了红包,当有的人没有抢,那么对应的id值就变成了0;
person[n1].value = person[n1].value + p;//记录抢到红包的金额;
person[n1].num ++;//记录抢到红包的个数;
sum = sum + p;//记录第i个人发红包的总金额;
}
person[i].value = person[i].value - sum;//更新编号为i的人剩余的总金额;
}
总结
这份面试题几乎包含了他在一年内遇到的所有面试题以及答案,甚至包括面试中的细节对话以及语录,可谓是细节到极致,甚至简历优化和怎么投简历更容易得到面试机会也包括在内!也包括教你怎么去获得一些大厂,比如阿里,腾讯的内推名额!
某位名人说过成功是靠99%的汗水和1%的机遇得到的,而你想获得那1%的机遇你首先就得付出99%的汗水!你只有朝着你的目标一步一步坚持不懈的走下去你才能有机会获得成功!
成功只会留给那些有准备的人!

cin>>n;
for(i=1;i<=n;i++)
{
person[i].id = i;//编号是i的人对应的id值是i;
cin>>k;
sum=0;
for(j=1;j<=k;j++)
{
cin>>n1>>p;
// person[n1].id = n1;易错点,因为你不知道每个人都抢了红包,当有的人没有抢,那么对应的id值就变成了0;
person[n1].value = person[n1].value + p;//记录抢到红包的金额;
person[n1].num ++;//记录抢到红包的个数;
sum = sum + p;//记录第i个人发红包的总金额;
}
person[i].value = person[i].value - sum;//更新编号为i的人剩余的总金额;
}
总结
这份面试题几乎包含了他在一年内遇到的所有面试题以及答案,甚至包括面试中的细节对话以及语录,可谓是细节到极致,甚至简历优化和怎么投简历更容易得到面试机会也包括在内!也包括教你怎么去获得一些大厂,比如阿里,腾讯的内推名额!
某位名人说过成功是靠99%的汗水和1%的机遇得到的,而你想获得那1%的机遇你首先就得付出99%的汗水!你只有朝着你的目标一步一步坚持不懈的走下去你才能有机会获得成功!
成功只会留给那些有准备的人!
[外链图片转存中…(img-pUOh2Gn3-1715549576917)]















 2547
2547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









