







总结
阿里伤透我心,疯狂复习刷题,终于喜提offer 哈哈~好啦,不闲扯了

1、JAVA面试核心知识整理(PDF):包含JVM,JAVA集合,JAVA多线程并发,JAVA基础,Spring原理,微服务,Netty与RPC,网络,日志,Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,设计模式,负载均衡,数据库,一致性哈希,JAVA算法,数据结构,加密算法,分布式缓存,Hadoop,Spark,Storm,YARN,机器学习,云计算共30个章节。

2、Redis学习笔记及学习思维脑图

3、数据面试必备20题+数据库性能优化的21个最佳实践

全系列链接
版本和环境准备
本次实战的环境和版本如下:
-
JDK:1.8.0_211
-
Flink:1.9.2
-
Maven:3.6.0
-
操作系统:macOS Catalina 10.15.3 (MacBook Pro 13-inch, 2018)
-
IDEA:2018.3.5 (Ultimate Edition)
-
Kafka:2.4.0
-
Zookeeper:3.5.5
请确保上述环境和服务已经就绪;
源码下载
如果您不想写代码,整个系列的源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
| :-- | :-- | :-- |
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
这个git项目中有多个文件夹,本章的应用在flinksinkdemo文件夹下,如下图红框所示:
准备完毕,开始开发;
准备工作
正式编码前,先去官网查看相关资料了解基本情况:
-
地址:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/connectors/kafka.html
-
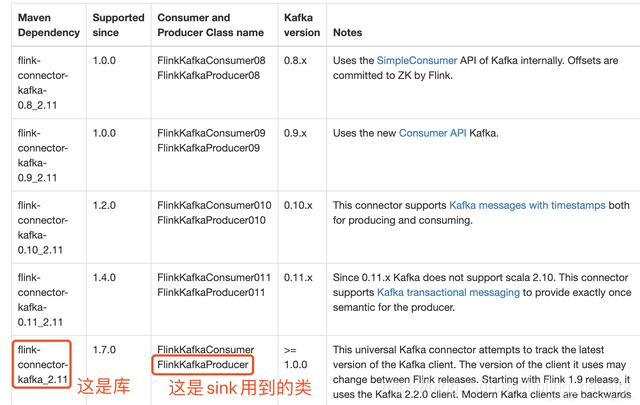
我这里用的kafka是2.4.0版本,在官方文档查找对应的库和类,如下图红框所示:
kafka准备
- 创建名为test006的topic,有四个分区,参考命令:
./kafka-topics.sh \
–create \
–bootstrap-server 127.0.0.1:9092 \
–replication-factor 1 \
–partitions 4 \
–topic test006
- 在控制台消费test006的消息,参考命令:
./kafka-console-consumer.sh \
–bootstrap-server 127.0.0.1:9092 \
–topic test006
-
此时如果该topic有消息进来,就会在控制台输出;
-
接下来开始编码;
创建工程
- 用maven命令创建flink工程:
mvn \
archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.9.2
-
根据提示,groupid输入com.bolingcavalry,artifactid输入flinksinkdemo,即可创建一个maven工程;
-
在pom.xml中增加kafka依赖库:
org.apache.flink
flink-connector-kafka_2.11
1.9.0
- 工程创建完成,开始编写flink任务的代码;
发送字符串消息的sink
先尝试发送字符串类型的消息:
- 创建KafkaSerializationSchema接口的实现类,后面这个类要作为创建sink对象的参数使用:
package com.bolingcavalry.addsink;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.nio.charset.StandardCharsets;
public class ProducerStringSerializationSchema implements KafkaSerializationSchema {
private String topic;
public ProducerStringSerializationSchema(String topic) {
super();
this.topic = topic;
}
@Override
public ProducerRecord<byte[], byte[]> serialize(String element, Long timestamp) {
return new ProducerRecord<byte[], byte[]>(topic, element.getBytes(StandardCharsets.UTF_8));
}
}
- 创建任务类KafkaStrSink,请注意FlinkKafkaProducer对象的参数,FlinkKafkaProducer.Semantic.EXACTLY_ONCE表示严格一次:
package com.bolingcavalry.addsink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class KafkaStrSink {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//并行度为1
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty(“bootstrap.servers”, “192.168.50.43:9092”);
String topic = “test006”;
FlinkKafkaProducer producer = new FlinkKafkaProducer<>(topic,
new ProducerStringSerializationSchema(topic),
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
//创建一个List,里面有两个Tuple2元素
List list = new ArrayList<>();
list.add(“aaa”);
list.add(“bbb”);
list.add(“ccc”);
list.add(“ddd”);
list.add(“eee”);
list.add(“fff”);
list.add(“aaa”);
//统计每个单词的数量
env.fromCollection(list)
.addSink(producer)
.setParallelism(4);
env.execute(“sink demo : kafka str”);
}
}
最后
本人也收藏了一份Java面试核心知识点来应付面试,借着这次机会可以送给我的读者朋友们
目录:

Java面试核心知识点
一共有30个专题,足够读者朋友们应付面试啦,也节省朋友们去到处搜刮资料自己整理的时间!

Java面试核心知识点
已经有读者朋友靠着这一份Java面试知识点指导拿到不错的offer了

14907525119)]
Java面试核心知识点
一共有30个专题,足够读者朋友们应付面试啦,也节省朋友们去到处搜刮资料自己整理的时间!
[外链图片转存中…(img-54H76J3s-1714907525120)]
Java面试核心知识点
已经有读者朋友靠着这一份Java面试知识点指导拿到不错的offer了
[外链图片转存中…(img-Qmgs4oS9-1714907525120)]















 632
632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









