







 本文介绍了如何使用Scrapy框架创建一个爬虫,从星际论坛抓取帖子标题和内容,通过XPath解析HTML,利用yield和pipelines处理数据,以及如何配置Middleware进行请求修改。
本文介绍了如何使用Scrapy框架创建一个爬虫,从星际论坛抓取帖子标题和内容,通过XPath解析HTML,利用yield和pipelines处理数据,以及如何配置Middleware进行请求修改。
scrapy startproject miao
随后你会得到如下的一个由scrapy创建的目录结构
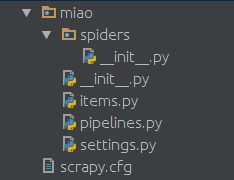
在spiders文件夹中创建一个python文件,比如miao.py,来作为爬虫的脚本。内容如下:
import scrapy
class NgaSpider(scrapy.Spider):
name = "NgaSpider"
host = "http://bbs.ngacn.cc/"
# start_urls是我们准备爬的初始页
start_urls = [
"http://bbs.ngacn.cc/thread.php?fid=406",
]
# 这个是解析函数,如果不特别指明的话,scrapy抓回来的页面会由这个函数进行解析。
# 对页面的处理和分析工作都在此进行,这个示例里我们只是简单地把页面内容打印出来。
def parse(self, response):
print response.body
2.跑一个试试?
如果用命令行的话就这样:
cd miao
scrapy crawl NgaSpider
你可以看到爬虫君已经把你坛星际区第一页打印出来了,当然由于没有任何处理,所以混杂着html标签和js脚本都一并打印出来了。
解析
接下来我们要把刚刚抓下来的页面进行分析,从这坨html和js堆里把这一页的帖子标题提炼出来。其实解析页面是个体力活,方法多的是,这里只介绍xpath。
0.为什么不试试神奇的xpath呢
看一下刚才抓下来的那坨东西,或者用chrome浏览器手动打开那个页面然后按F12可以看到页面结构。每个标题其实都是由这么一个html标签包裹着的。举个例子:
<a href='/read.php?tid=10803874' id='t_tt1_33' class='topic'>[合作模式] 合作模式修改设想</a>
可以看到href就是这个帖子的地址(当然前面要拼上论坛地址),而这个标签包裹的内容就是帖子的标题了。
于是我们用xpath的绝对定位方法,把class='topic’的部分摘出来。
1.看看xpath的效果
在最上面加上引用:
from scrapy import Selector
把parse函数改成:
def parse(self, response):
selector = Selector(response)
# 在此,xpath会将所有class=topic的标签提取出来,当然这是个list
# 这个list里的每一个元素都是我们要找的html标签
content_list = selector.xpath("//*[@class='topic']")
# 遍历这个list,处理每一个标签
for content in content_list:
# 此处解析标签,提取出我们需要的帖子标题。
topic = content.xpath('string(.)').extract_first()
print topic
# 此处提取出帖子的url地址。
url = self.host + content.xpath('@href').extract_first()
print url
再次运行就可以看到输出你坛星际区第一页所有帖子的标题和url了。
递归
接下来我们要抓取每一个帖子的内容。这里需要用到python的yield。
yield Request(url=url, callback=self.parse_topic)
此处会告诉scrapy去抓取这个url,然后把抓回来的页面用指定的parse_topic函数进行解析。
至此我们需要定义一个新的函数来分析一个帖子里的内容。
完整的代码如下:
import scrapy
from scrapy import Selector
from scrapy import Request
class NgaSpider(scrapy.Spider):
name = "NgaSpider"
host = "http://bbs.ngacn.cc/"
# 这个例子中只指定了一个页面作为爬取的起始url
# 当然从数据库或者文件或者什么其他地方读取起始url也是可以的
start_urls = [
"http://bbs.ngacn.cc/thread.php?fid=406",
]
# 爬虫的入口,可以在此进行一些初始化工作,比如从某个文件或者数据库读入起始url
def start_requests(self):
for url in self.start_urls:
# 此处将起始url加入scrapy的待爬取队列,并指定解析函数
# scrapy会自行调度,并访问该url然后把内容拿回来
yield Request(url=url, callback=self.parse_page)
# 版面解析函数,解析一个版面上的帖子的标题和地址
def parse_page(self, response):
selector = Selector(response)
content_list = selector.xpath("//*[@class='topic']")
for content in content_list:
topic = content.xpath('string(.)').extract_first()
print topic
url = self.host + content.xpath('@href').extract_first()
print url
# 此处,将解析出的帖子地址加入待爬取队列,并指定解析函数
yield Request(url=url, callback=self.parse_topic)
# 可以在此处解析翻页信息,从而实现爬取版区的多个页面
# 帖子的解析函数,解析一个帖子的每一楼的内容
def parse_topic(self, response):
selector = Selector(response)
content_list = selector.xpath("//*[@class='postcontent ubbcode']")
for content in content_list:
content = content.xpath('string(.)').extract_first()
print content
# 可以在此处解析翻页信息,从而实现爬取帖子的多个页面
到此为止,这个爬虫可以爬取你坛第一页所有的帖子的标题,并爬取每个帖子里第一页的每一层楼的内容。爬取多个页面的原理相同,注意解析翻页的url地址、设定终止条件、指定好对应的页面解析函数即可。
Pipelines——管道
此处是对已抓取、解析后的内容的处理,可以通过管道写入本地文件、数据库。
0.定义一个Item
在miao文件夹中创建一个items.py文件。
from scrapy import Item, Field
class TopicItem(Item):
url = Field()
title = Field()
author = Field()
class ContentItem(Item):
url = Field()
content = Field()
author = Field()
此处我们定义了两个简单的class来描述我们爬取的结果。
1. 写一个处理方法
在miao文件夹下面找到那个pipelines.py文件,scrapy之前应该已经自动生成好了。
我们可以在此建一个处理方法。
class FilePipeline(object):
## 爬虫的分析结果都会由scrapy交给此函数处理
def process_item(self, item, spider):
if isinstance(item, TopicItem):
## 在此可进行文件写入、数据库写入等操作
pass
if isinstance(item, ContentItem):
## 在此可进行文件写入、数据库写入等操作
pass
## ...
return item
2.在爬虫中调用这个处理方法。
要调用这个方法我们只需在爬虫中调用即可,例如原先的内容处理函数可改为:
def parse_topic(self, response):
selector = Selector(response)
content_list = selector.xpath("//*[@class='postcontent ubbcode']")
for content in content_list:
content = content.xpath('string(.)').extract_first()
## 以上是原内容
## 创建个ContentItem对象把我们爬取的东西放进去
item = ContentItem()
item["url"] = response.url
item["content"] = content
item["author"] = "" ## 略
## 这样调用就可以了
## scrapy会把这个item交给我们刚刚写的FilePipeline来处理
yield item
3.在配置文件里指定这个pipeline
找到settings.py文件,在里面加入
ITEM_PIPELINES = {
'miao.pipelines.FilePipeline': 400,
}
这样在爬虫里调用
yield item
的时候都会由经这个FilePipeline来处理。后面的数字400表示的是优先级。
可以在此配置多个Pipeline,scrapy会根据优先级,把item依次交给各个item来处理,每个处理完的结果会传递给下一个pipeline来处理。
可以这样配置多个pipeline:
ITEM_PIPELINES = {
'miao.pipelines.Pipeline00': 400,
'miao.pipelines.Pipeline01': 401,
'miao.pipelines.Pipeline02': 402,
'miao.pipelines.Pipeline03': 403,
## ...
}
Middleware——中间件
通过Middleware我们可以对请求信息作出一些修改,比如常用的设置UA、代理、登录信息等等都可以通过Middleware来配置。
0.Middleware的配置
与pipeline的配置类似,在setting.py中加入Middleware的名字,例如
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 856
856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









