






我们知道Stable Diffusion生成图像的随机性导致很难控制生成同样的人物形象或动作。这种问题会出现在绘本创作,小说配图等场景中,因为在这些场景,人物的衣着打扮、人物动作、表情都不一样,但是要求始终是同一个人。这个基本要求很重要,如果你仔细看过 幼儿绘本,会发现很多角色表情或者形象恨不合格,但是小孩子对这种差异性很敏感,很容易辨别出这种差别,我自己就经常被小朋友问到,“为什么这一个小人跟前面的那个不一样”,“为什么这个人的两个眼睛一大一小”,诸如这类问题我只能说设计师画错了。。。
其实人工绘画出错可能性很大,即使两个相同的绘画要保持完全一致也很有难度,但是对于计算机却很容易,这篇文章介绍如何让Stable Diffusion在不同场景保持人物形象的一致性,同时还能保持一定的创造性。
这里主要通过两个场景来介绍:
- 在不同场景的同一人物保持相同动作或者姿势;
- 在不同场景的同一人保持不同当作或者姿势。
首先我先创建一个有“趣味”的人物形象,通过输入
positive prompt:
masterpiece, best quality, 1girl, aqua eyes, black hair, closed mouth, multicolored background, looking at viewer, outdoors, solo, upper body, alluring, clean, beautiful face, pure face, pale skin, sexy pose,((tube top, navel, shorts)),short hair, ((perfect female figure)), mature female, narrow waist, chinese deity, seductive, highly detailed,best quality, masterpiece, highres, original, extremely detailed 8K, wallpaper, illustration, beautifully detailed eyes, cinematic lighting, earrings, jewelry,
sketches, (worst quality:2), (low quality:2), (normal quality:2), multiple breasts, (mutated hands and fingers:1.5 ), (long body :1.3), (mutation, poorly drawn :1.2) , black-white, bad anatomy, liquid body, liquid tongue, disfigured, malformed, mutated, anatomical nonsense, text font ui, error, malformed hands, long neck, blurred, lowers, lowres, bad anatomy, bad proportions, bad shadow, uncoordinated body, unnatural body, fused breasts, bad breasts, huge breasts, poorly drawn breasts, extra breasts, liquid breasts, heavy breasts, missing breasts, huge haunch, huge thighs, huge calf, bad hands, fused hand, missing hand,
采用抽签随机抽一个,就这个吧:
现在我要基于这个人物形象,让她在另一个场景中出现,比如给她换个背景,怎么做呢?你可能直接想到的是抠图?抠图很直观,就像我上篇文章【如何用Stable Diffusion实现类似Photoshop中局部重绘功能】介绍的那样,很麻烦,你得先绘制人物的mask,然后重绘非mask区域,这个过程中,你可能绘制的mask区域不精确,而且mask区域不可重绘。
但是我现在想给人物形象换套服装,那么这种方式就行不通了,这时候得请出ControlNet 新推出的Reference Only preprocessor,它能够基于一张图片作为参考就可以生成对应风格和特定人物的图片,而不需要调用特定训练的LoRa模型。要知道LoRa训练毕竟还是相当麻烦且贵,controlnet的Reference Only大大降低了使用门槛。
上面的照片是在室外,现在把她放到室内,同时更换下服装。假设你已经安装了ControlNet,现在直接将上面的人物形象照片发送到 img2img tab,同时修改下positive prompt:
masterpiece, best quality, 1girl, indoor, (scifi style background), ((in a local bar)),cyberpunker lighting, ((neon lamp)), sci-fi details, insane level of details, hyper realistic, cinematic, composition
Generate 生成4张照片看看:
从结果看,基本人物形象,包括姿势跟前面保持一致,但是服装和装饰有所区别。这就是该处理器的要达成的效果:既保持基本形象,同时增加了创造性。这是inpaint 无法做到的,至少没那么容易做到的。而且它的扩图能力比outpaint还方便!
但是生成的照片连姿势都保持了,这也太无趣了吧,如果我现在想她的姿势显得更“妖娆”一些,怎么办呢?这时候得再请出来ControlNet的另一个重量级的预处理器 OpenPose。它能够迁移人物姿势动作到新的图像上。
通过将这两个神器组合在一起,能够实现非常令人满意的新照片,怎么做呢?首先仍然基于上面的提示词,创建一个富有姿势的照片,因为只要姿势,外貌形象就无所谓了,随机抽签就行:
然后在ControlNet中创建两个unit:一个用于上面介绍的换装,另一个用于迁移姿势:
注:因为在生成图像的过程中,姿势渲染要早于外形渲染,上图中的红框Starting Control Step要稍微晚一点儿,调大一些,而姿势渲染的Starting Control Step要稍微早一点儿,调小一些:
好了,再Generate看看效果吧:
人物姿势完美迁移过来了,但是人脸形象好像有一点儿差异,这个可以通过下面的参数来控制:
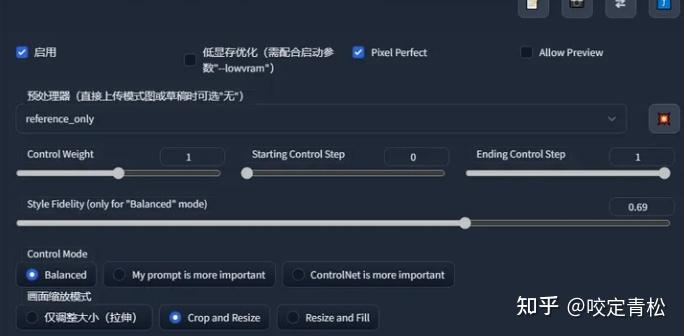
Control Mode:如果需要让prompt起作用,勾选My prompt is more import,否则某些情况,无法更换服装或者背景。
fidelity 容易保持原图风格的程度,值越大,跟原图越像,但不是越大越好,需要针对不同的图仔细尝试权衡效果。
好了,以上就是本文介绍的如何在不同场景保持人物形象的一致性。通过Stable Diffusion的reference only能够保持任务形象的一致性,同时结合Openpose能够实现保持人物形象几乎不变的情况下,丰富人物姿势。值得一体的是以上是基于真实人物大模型,实际上reference only还可以基于其他模型,比如如果换成二次元人物大模型,可以生成原来人物的二次元风格,也就是实现了图像风格迁移。
比如下面的示例:
Stable Diffusion 最强提示词手册
-
Stable Diffusion介绍
-
OpenArt介绍
-
提示词(Prompt) 工程介绍
-
.......

第一章、提示词格式
-
提问引导
-
示例
-
单词的顺序
-
.......

有需要的朋友,可以点击下方卡片免费领取!


















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









