






一、什么是LayerDiffusion
随着Stable Diffusion等散射模型的蓬勃发展,人工智能图形生成进入了一个崭新的阶段。我们可以仅仅通过文字提示,就可以让AI模型为我们生成逼真的图像。但是,目前主流的AI生成模型大多只能生成普通的RGB图像,对生成具有透明通道的图片能力还非常有限。这对于许多创作者来说是个痛点。无数PS、AE设计工作都需要大量高质量的透明元素,而目前获取透明图像资源的唯一途径就是人工购买或下载商业透明素材库的资产,这需要花费高昂的费用。
这种情况直到最近才有了转机。一组斯坦福大学的研究人员提出了一个叫做LayerDiffusion的方法,可以让现有的散射模型通过微调直接生成透明图像甚至是多层透明图像[1]。这个方法背后的核心思路其实非常简单直接,研究人员发现,我们可以把透明通道的信息编码进Stable Diffusion等模型的潜向量空间里,也就是给原来的无透明通道的潜向量添加一个小小的透明通道“偏移”。这个偏移量非常关键,它必须微小到不影响原始模型潜向量分布的整体形态。否则的话,加入透明通道反而会使得原始模型的图像生成质量下降。研究者通过构建独立的Encoder和Decoder网络来实现透明通道的潜向量编码和解码,以确保不影响原始Stable
Diffusion等模型的性能。
一旦得到了具有透明通道信息的潜向量表示,我们就可以开始微调现有的散射模型,让它们支持生成透明图像了。为了训练这个框架,研究团队还采用了一种人机交互的方式收集了100万张高质量的透明图像素材。这些图像涵盖了各种各样的内容主题和风格,可以很好地支持透明图像生成模型的训练。
有了LayerDiffusion框架,ComfyUI用户就可以直接把任何已有的散射模型“托管”到这个框架里进行微调,使其快速获得生成透明图像的能力。生成效果非常惊人,完全不逊色于商业透明素材库里的专业素材。更棒的是,这个框架不仅可以生成单层透明图像,还可以生成多层图像。这为各种创意设计提供了极大的便利。
例如,用户可以提供两个文字提示,一个是“火焰”,一个是“木屋的桌子”,让模型生成两层透明图像——一个是火焰,一个是桌子。然后我们可以自由调整这两层的堆叠与混合,就可以得到火焰在桌子上的不同效果。这样的操作极大地丰富了图像创作的可能性。
总之,LayerDiffusion为基于散射模型的图像生成带来了透明图像和分层图像的支持,让艺术家和设计师可以超越传统二维平面图像的限制,进入一个崭新多维的创作空间。它也将会彻底改变我们获取透明图像素材的方式——不再需要人工购买或下载现成的资产,AI模型可以为我们实时生成所需的任何透明元素或层次关系。相信未来这项技术还会ProtocolMessageType和强大,带来更多惊喜。

官方图样
二、ComfyUI中的Node介绍
截至3月2日,官方仅仅发布了Stable Diffusion WebUI(forge)的插件,这令很多ComfyUI用户非常着急。根据官方内容,ComfyUI的支持还未列为高优先级任务,何时能够支持还遥遥无期。不过高手在民间,今天Github上已有大神huchenlei发布了最新的ComfyUI的插件。
插件地址:GitHub - huchenlei/ComfyUI-layerdiffusion: Layer Diffusion custom nodes

官方指南里,需要的一个node:Apply Mask to Image,来自另一个工具:comfyui-tooling-nodes
这里主体使用了两个node:
1、 Layer Diffusion Apply
该节点用于修饰用于KSample的model,输入model,输出也是model。输出的model链接到KSampler的Model输入。该节点还带有2个参数:method和weight。
- method
其中method包含两个方法:Attention Injection以及Conv Injection。
[Attention Injection]
Attention Injection是LayerDiffusion中实现控制透明图像生成的一种方法。它通过在预训练好的Stable Diffusion模型的self-attention层中注入透明度attention map,以控制生成图像的透明区域。
具体来说,首先利用辅助网络来预测目标透明图像的透明度attention map。然后在Stable Diffusion模型的self-attention计算中,将这个透明度attention map与原始的attention map进行concat拼接,送入后续的attention运算。透明度attention map中,透明区域的值接近1,不透明区域的值接近0。这样,原始的attention map与透明度attention map共同作用,可以指导模型仅在指定的透明区域生成透明效果。
Attention Injection的优点是可以精确控制图像的透明区域,同时对原有模型的干扰很小。但需要训练额外的网络来预测透明度attention map,增加了一定计算量。
[Conv Injection]
Conv Injection是LayerDiffusion中另一种控制透明图像生成的方法。它通过在Stable Diffusion模型的中间卷积层中注入透明度feat map来控制生成结果。
具体是,一个辅助卷积网络会预测目标图像的透明度feat map,然后将其添加到Stable Diffusion模型中途的卷积层作为额外的输入通道。透明区域的feat map通道值接近1,不透明区域接近0。这样,Stable Diffusion在生成图像时,会把透明度信息融入到特征中,从而控制最终输出的透明效果。
与Attention Injection相比,Conv Injection增加的计算量更小,但控制效果较粗糙。它通过全局的特征融合控制透明效果,不能像Attention Injection那样精确指定透明的区域。
综上,Attention Injection和Conv Injection都是LayerDiffusion实现控制生成透明图像的有效方法,各有优劣。可以根据实际需求选择使用。
- weight
0表示完全不透明,1表示完全透明。weight值在0到1之间表示半透明的透明度。
2、Layer Diffusion Decode
该节点用于解码转化为影响图像生成的信号。具体解释如下:
- Attention Injection
在Attention Injection中,decode的作用是将融合了透明度attention map的attention转化为影响图像生成的信号。
具体来说,经过attention计算得到的融合attention map,还不能直接影响最终的图像输出。需要通过后续的decode计算,将attention转化为影响图像生成的信号,最终反映到输出结果中。
这里的decode可以看作是attention的解析过程。它将attention中编码的透明度信息,解码出来,转化为模型生成透明的具体操作信号。
- Conv Injection
在Conv Injection中,decode的作用也是将透明度feat map转化为影响图像生成的信号。
经过卷积计算后,特征图中已经包含了透明度信息。但这些特征还需要进一步的decode,才能转换为模型生成透明的具体操作。
这里的decode可以视为特征的解析过程。它将特征中编码的透明度,解码出来,转化为模型对图像透明效果的实际控制。
综上,在两种方法中,decode都起到将透明度信息从attention或特征中解析出来的作用。将透明度控制信号转换为模型生成透明图像的实际执行操作。这个过程非常关键。
该节点有2个输入,一个是Sample,接受从KSample输出的Latent。一个是Images,用于接受VAE Decode输出的Image。然后经过解码生成两个输出:Image是包含主体信息的前景RGB图像, MASK是控制透明度的蒙版。
3、Apply Mask to Image
该节点来自comfyui-tooling-nodes,其作用是将前景图像加上透明度蒙版最终合成最终图像。
完整的Workflow可以参考下图:
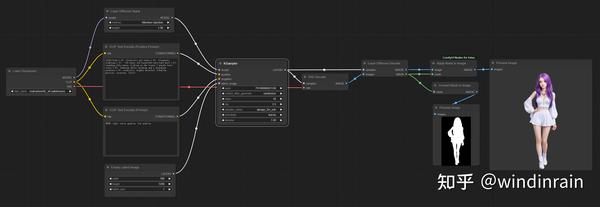
三、在Ultimate SD Upscale 中放大图像
因为最终输出的图像是包含Alpha通道的4通道图像,该图像无法使用Ultimate SD Upscale进行放大。可LayerDiffusion目前还无法直接支持Tile放大。但是实际工作中,我们常常需要使用Ultimate SD Upscale进行图像放大以获得更加精细的输出。尤其在输出全身像的时候,原始输出图片常常脸崩,只有经过Ultimate SD Upscale放大以后才能获得高质量的图像。这时候如何使用LayerDIffusion来获得高质量的透明图像呢。经过实验,可以通过下面方法使用。
1、放大Mask
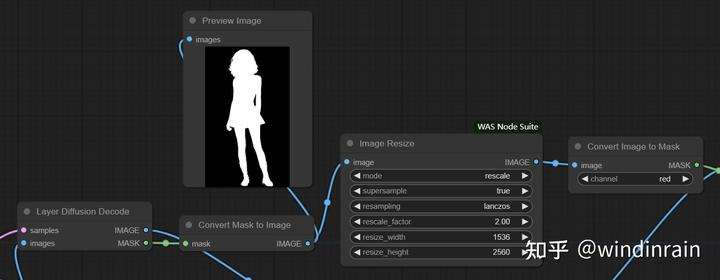
首先通过Convert Mask to Image将蒙版转换成单通道图像,使用Image Resize将单通道图像放大,这里需要注意的是放大后的尺寸必须和原图放大的尺寸一致,否则后期蒙版和原图无法合并。
2、放大原始图
使用Ultimate SD Upscale进行图像放大。
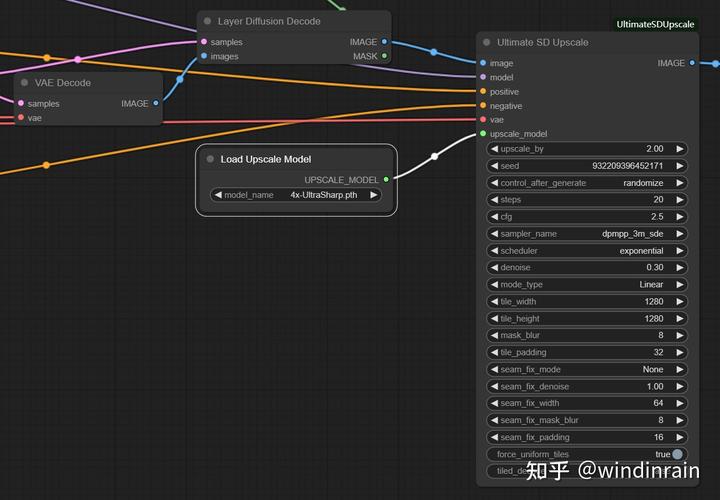
这里放大的图像使用Layer Diffusion Decode的Image输出,其他输入与KSample输入一致。Upscale Model我习惯使用4x-UltraSharp.pth,这个影响不太大。
3、合并图像生成放大的透明图
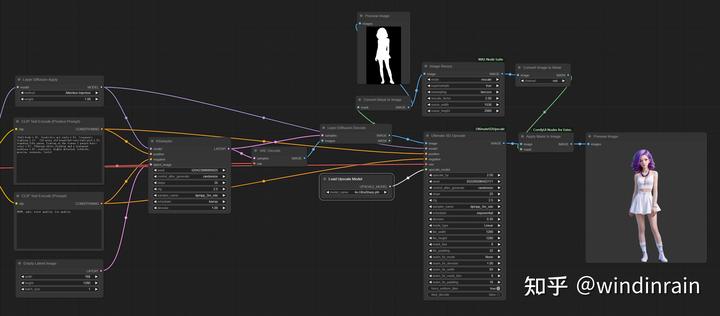
最后,将放大后的Mask和Image进行合并,生成最终的透明图像。这里还是使用Apply Mask to Image节点完成。
最终放大透明图的workflow如下:
四、总结
因为我更喜欢使用ComfyUI来完成自己的工作,所以对LayerDiffusion支持ComfyUI这件事更加关注。自从2月28日LayerDiffusion发布以来,日日夜夜都在关注项目进度。今天发现终于等到了ComfyUI-layerdiffusion的发布。
希望各位能够痛快的进行工作吧。



为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取

一、ComfyUI配置指南
-
报错指南
-
环境配置
-
脚本更新
-
后记
-
.......
二、ComfyUI基础入门
-
软件安装篇
-
插件安装篇
-
......
三、 ComfyUI工作流节点/底层逻辑详解
-
ComfyUI 基础概念理解
-
Stable diffusion 工作原理
-
工作流底层逻辑
-
必备插件补全
-
......
四、ComfyUI节点技巧进阶/多模型串联
-
节点进阶详解
-
提词技巧精通
-
多模型节点串联
-
......
五、ComfyUI遮罩修改重绘/Inpenting模块详解
-
图像分辨率
-
姿势
-
......

六、ComfyUI超实用SDXL工作流手把手搭建
-
Refined模型
-
SDXL风格化提示词
-
SDXL工作流搭建
-
......

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









