






前言
大家好,这里是和你们一起探索 AI绘画月月~
最近一种新的图像生成形式逐渐兴起,即生成的图像会随输入的文字或笔画动作迅速变化,这让图像生成有了更多灵活探索和准确控制的空间。这种「实时反馈」的感觉源于模型能在几秒钟内,根据输入生成新的内容,而之所以能有这么快的生成速度,依靠的就是 LCM 这项新技术。
一、LCM 简介
LCM 项目主页: https://latent-consistency-models.github.io/
Github 主页: https://github.com/luosiallen/latent-consistency-model
LCM 全称 Latent Consistency Models(潜在一致性模型),是清华大学交叉信息科学研究院研发的一款生成模型。它的特点是可以通过少量步骤推理合成高分辨率图像,使图像生成速度提升 2-5 倍,需要的算力也更少。官方称 LCMs 是继 LDMs(Latent Diffusion Models 潜在扩散模型)之后的新一代生成模型。

LCM 的上一代是今年 6 月份的推出的 Consistency Models(CM,一致性模型)。用过 Stable Diffusion 的小伙伴都知道,我们在生成图像的时候需要设置「 采样步数 Steps」,这个参数,涉及到的是 Diffusion 模型中的去噪(Denoise)过程,即以迭代的方式从一张纯噪声图中一步步去除噪点,直至它变成一张清晰的图像。采样步数一般需要 20-50 步。

Consistentcy Models 则对去噪推理这一步进行了优化,它不再需要像 Diffusion 模型那样逐步迭代,而是追求“一步完成推理”,这样需要处理的步数减少了,图像的生成速度自然就提升了。LCM 则是在 Consistency Models 的基础上引入了 Lantent Space (潜空间),进一步压缩需要处理的数据量,从而实现超快速的图像推理合成。LCM 官方以此训练了一个新的模型 Dreamshaper-V7,仅通过 2-4 步就能生成一张 768*768 分辨率的清晰图像。

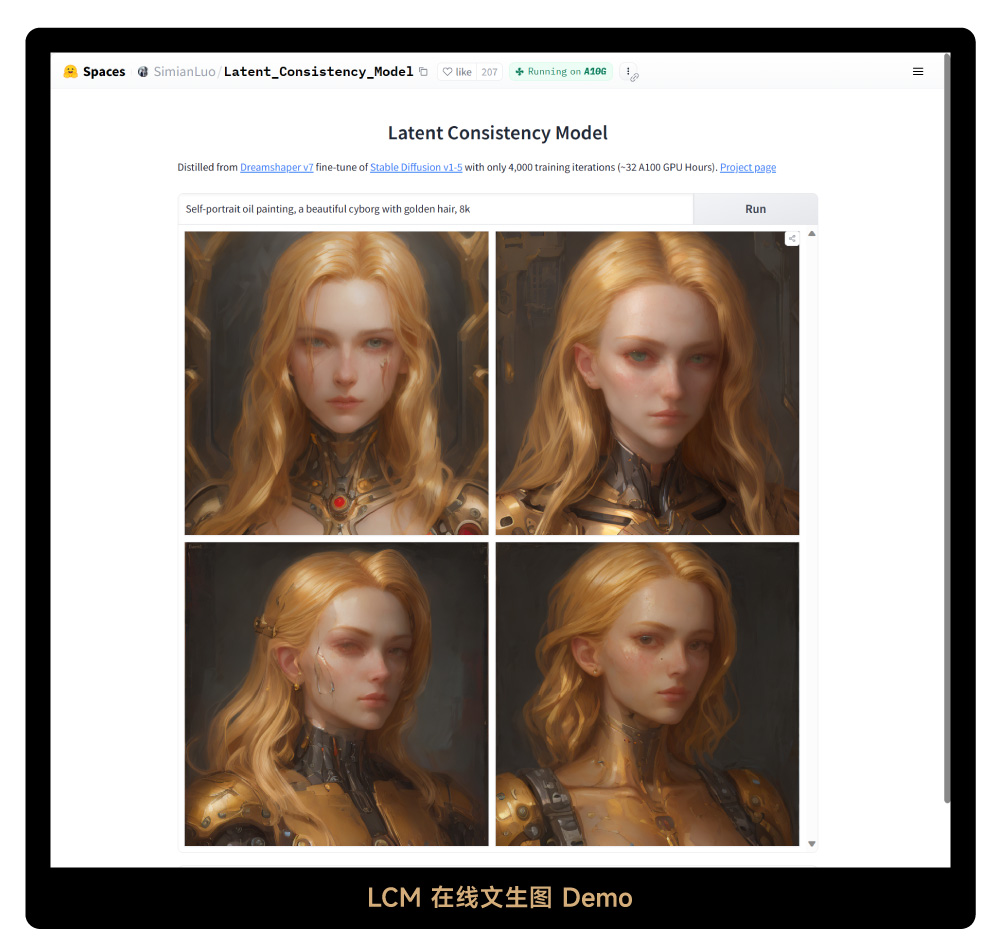
LCM 官方提供了 2 个可以免费在线试玩的 Demo,分别是文生图和图生图。文生图 Demo 使用的就是 Dreamshaper-V7 模型,我试了一下的确可以在几秒之内就生成 4 张图,速度非常惊人,大家也可以去体验一下。
文生图试玩 Demo: https://huggingface.co/spaces/SimianLuo/Latent_Consistency_Model
图生图试玩 Demo: fofr/latent-consistency-model – Run with an API on Replicate
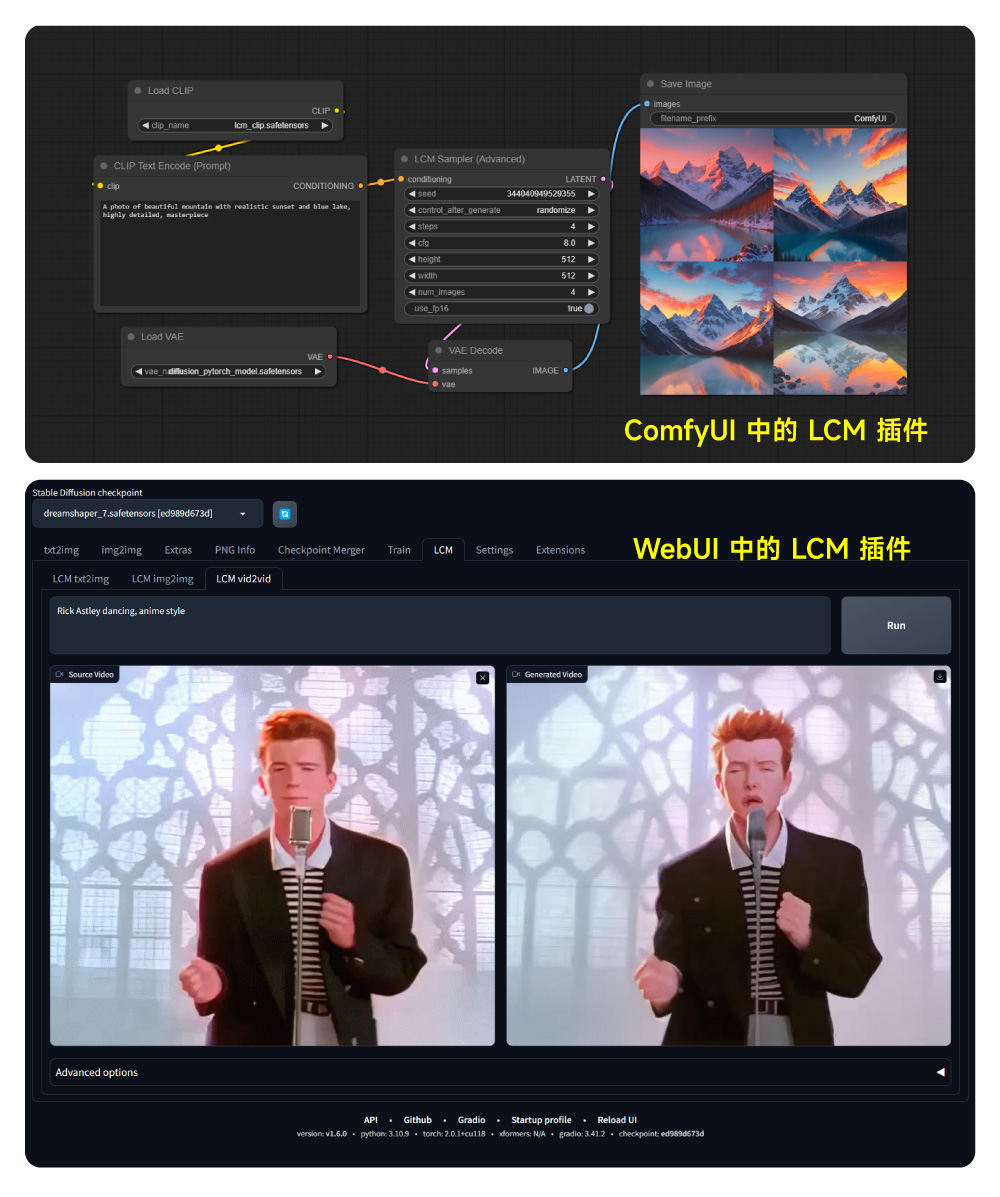
目前可以用的 LCM 模型有 Dreamshaper-V7 和 LCM-SDXL,LCM 也以拓展插件的形式加入了 A1111 WebUI 和 ComfyUI,支持文生图、图生图和视频生成视频,安装插件后我们就可以在自己电脑上体验一下这种 2 款新模型的生成效率。如果你还不了解插件的安装方式,可以查看我之前写的 SD WebUI 插件安装教程 ,或者了解我最新制作的课程 《AI绘画入门完全指南》 ,系统全面地了解 SD WebUI 的使用方法和技巧。
① Dreamshaper-V7 模型下载: SimianLuo/LCM_Dreamshaper_v7 at main (huggingface.co) (文末有资源包)
② LCM-SDXL模型下载: latent-consistency/lcm-sdxl · Hugging Face — 潜在一致性/lcm-sdxl ·拥抱的脸 (文末有资源包)
③ LCM WebUI 插件安装使用: https://github.com/0xbitches/sd-webui-lcm
④ LCM ComfyUI 插件安装使用: https://github.com/0xbitches/ComfyUI-LCM
二、LCM-LoRA
LCM 可以有效缩短图像的生成时间,但它的模型需要单独训练,前面的提到的 Dreamshaper-V7 和 LCM-SDXL 是目前仅有的 2 款可以在 LCM 插件中使用的大模型,这显然不符合大家的使用需求。为了改变这种情况,官方又训练出了 LCM-LoRA 模型,可以搭配 SD1.5 和 SDXL 的所有大模型使用,这比上面安装 LCM 插件更方便。目前我们可以在 ComfyUI 和 Fooocus 中使用 LCM-LoRA。
① LCM-LoRA 项目主页: https://huggingface.co/blog/lcm_lora
② lcm-lora-sdv1-5 下载: https://huggingface.co/latent-consistency/lcm-lora-sdv1-5
③ lcm-lora-sdxl 下载: https://huggingface.co/latent-consistency/lcm-lora-sdxl
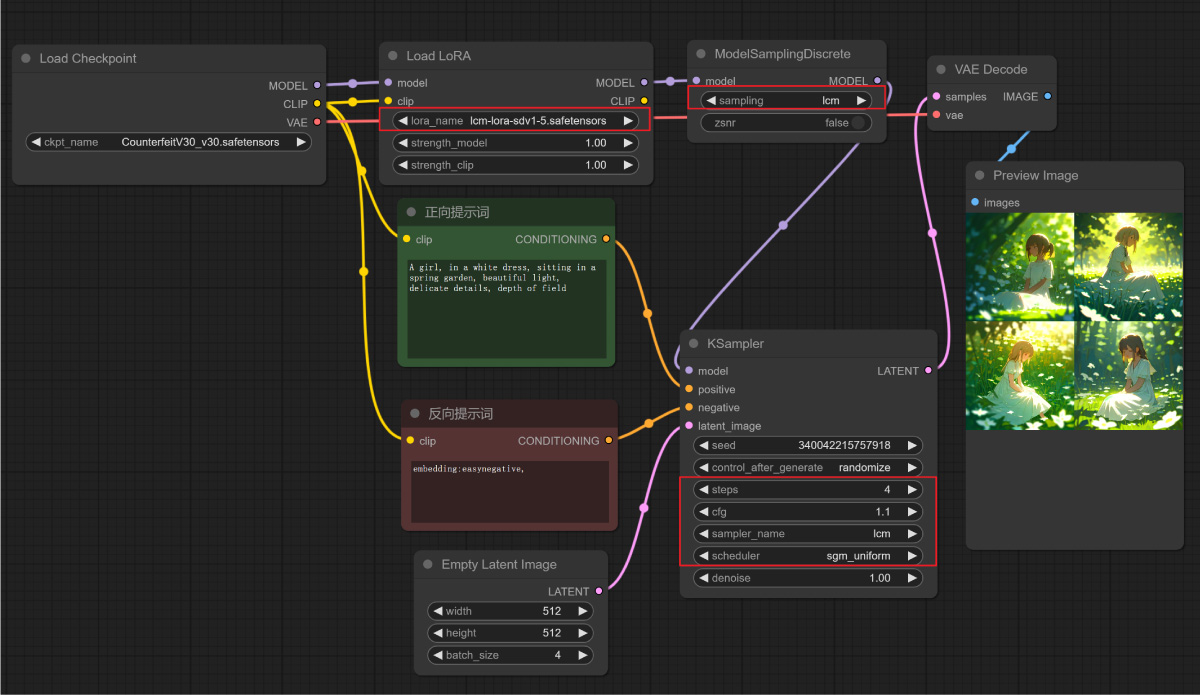
LoRA 模型在文末有资源包,下载后安装到 ComfyUI 根目录的 loras 文件夹内即可(如果是和 WebUI 共享的模型,就放到 WebUI 的 lora 文件夹内 )。在 ComfyUI 中使用 LCM-LoRA 需要注意以下几点:
- 模型下载链接内包含模型使用方法和注意事项,使用需要仔细阅读;
- 在 ComfyUI 中使用 lcm-lora 需要先安装 ComfyUI-LCM 插件;
- 采样步数 Steps 数值在 2 - 8 之间,CFG 参数在 1.0 - 2.0 之间。
下图是在 ComfyUI 中使用 lcm-lora-sdv1-5 的工作流(json 文件在文末资源包内),经测试生成 4 张图像仅需 3 秒。速度的确非常快,但图像质量比起正常的 Stable Diffusion 模型来说还是稍微差了一些。

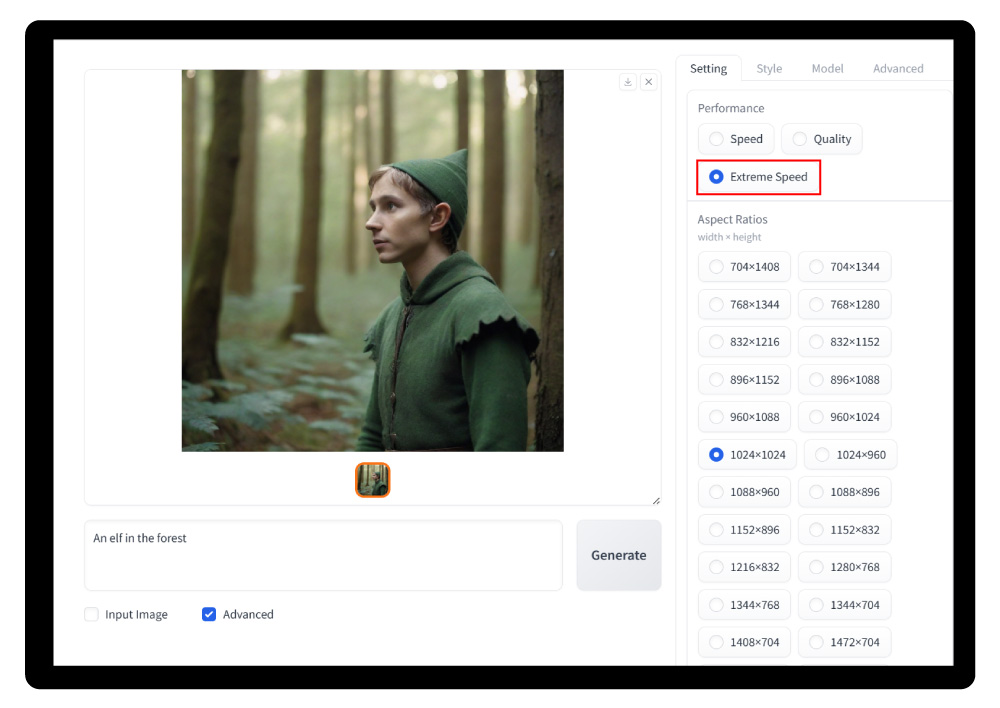
如果想在 Fooocus 中使用 LCM-LoRA,需要安装最新版的 Fooocus ,然后将文末资源包内的 sdxl_lcm_lora 放入 Fooocus\models\loras 文件夹中。启动后,在 setting 中选择 Extreme Speed 模式,系统会启动 lcm-lora。然后在 Models 中选择一个 SDXL 大模型,lora 和 style 可以自定义,再点击生成即可。经测试生成一张 1024*1024 px 的图像只需要 9 秒,比之前快了 5 倍,图像质量依旧保持的不错。
三、Animatediff 与 LCM-LoRA
Animatediff 是目前最受关注的 AI 视频工具之一,可以通过文本生成流畅的动图或视频。有了 LCM 之后,Animatediff 的图像处理速度也得到了明显提升。据我个人测试,使用 lcm-lora 后生成一个 16 帧的动图只需要 27 秒,如果不使用则需要 75 秒,速度差了 3 倍。
ComfyUI 中使用 lcm-lora-sdv1-5 + Animatediff 的工作流(json 文件在文末资源包内):
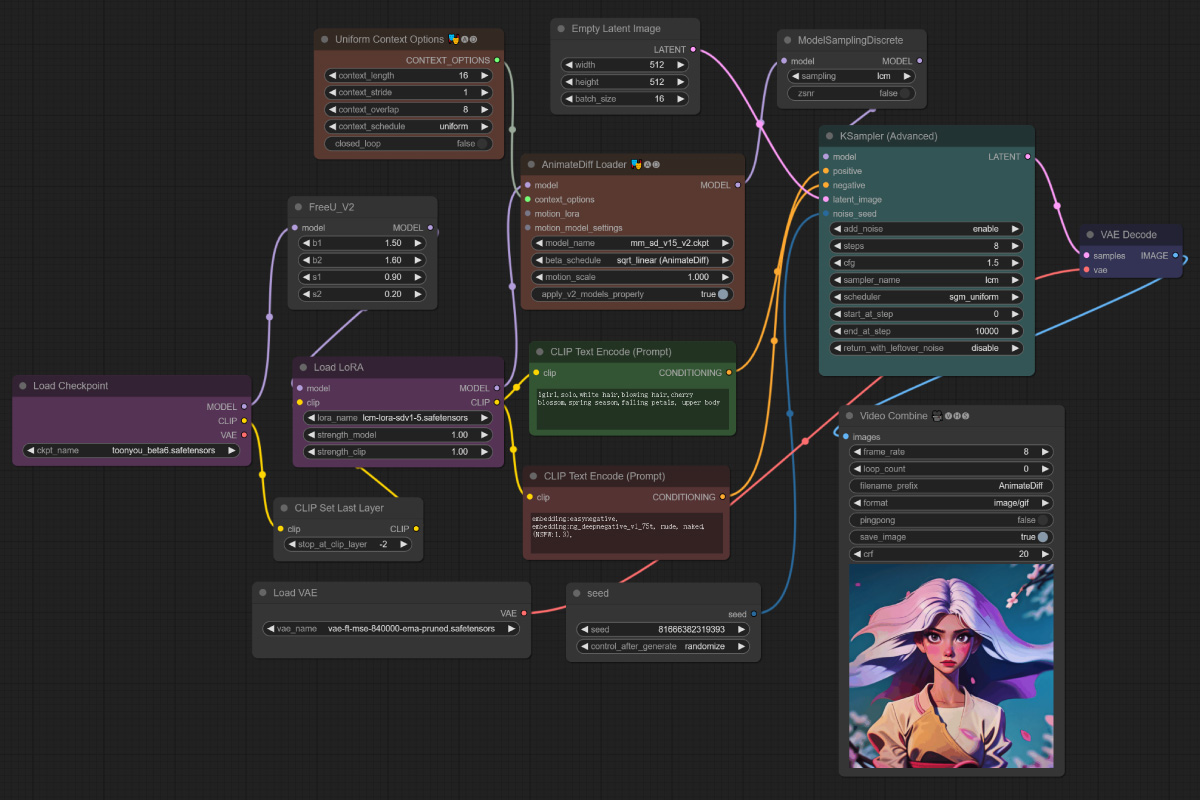
效果图:

LCM 让我们看到了 SD 模型在生成速度上的突破,虽然目前质量稍微差了一些,但 AI 技术的发展速度是惊人的,未来肯定会有改善。而随着 LCM 的发展成熟,图像处理速度可能会进一步缩短到毫秒级,这将极大促进实时文生图、图生图以文生视频的发展,给用户带更好的使用体验;也可能会进一步和 Controlnet 或者 IP-Adapter 兼容,来提升这些插件的处理效率。
这里为了帮助大家更好地掌握 ComfyUI,分享一套字节大佬整理的ComfyUI工作流集合,其包含了很多好玩有趣,但又有点复杂的工作流节点和json配置。
涵盖了 Stable Scascade、3D、LLM+SD、Portrait Master、SVD 等相关类别的工作流,共计15个类目38项工作流。这些都放在了下方卡片,需要的点击免费获取:


对于初学者来说,最佳的学习方法是以这些现成的工作流为模板,一步步地复刻并理解它们。
通过观察和分析别人的工作流,你可以学习到各种节点搭建的技巧和方法。随着理解的深入,你将能够根据自己的需求创新和搭建属于自己的工作流。
希望本文能帮助你有效地提升你的设计效率和创造力。
对于从来没有接触过AI绘画的同学,我已经帮你们准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
这份完整版的AI绘画资料和SD整合包已经打包好了,需要的点击下方插件,即可前往免费领取!
















 7905
7905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









