







LCM 的全称是 Latent Consistency Models(潜在一致性模型),由清华大学交叉信息研究院的研究者们构建。通过一些创新性的方法,LCM 只用少数的几步推理就能生成高分辨率图像,将主流文生图模型的效率提高 5-10 倍,所以能呈现出实时的效果。
目前LCM只可以使用一个模型Dreamshaper_v7,基于SD版本Dreamshaper微调而来的。
LCM模型下载:
项目源码:
安装依赖库
pip install --upgrade diffusers # make sure to use at least diffusers >= 0.22
pip install transformers accelerate运行模型
文生图
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("SimianLuo/LCM_Dreamshaper_v7")
# To save GPU memory, torch.float16 can be used, but it may compromise image quality.
pipe.to(torch_device="cuda", torch_dtype=torch.float32)
prompt = "Self-portrait oil painting, a beautiful cyborg with golden hair, 8k"
# Can be set to 1~50 steps. LCM support fast inference even <= 4 steps. Recommend: 1~8 steps.
num_inference_steps = 4
images = pipe(prompt=prompt, num_inference_steps=num_inference_steps, guidance_scale=8.0, lcm_origin_steps=50, output_type="pil").images
images[0].save("image.png")图生图
from diffusers import AutoPipelineForImage2Image
import torch
import PIL
pipe = AutoPipelineForImage2Image.from_pretrained("SimianLuo/LCM_Dreamshaper_v7")
# To save GPU memory, torch.float16 can be used, but it may compromise image quality.
pipe.to(torch_device="cuda", torch_dtype=torch.float32)
prompt = "High altitude snowy mountains"
image = PIL.Image.open("./snowy_mountains.png")
# Can be set to 1~50 steps. LCM support fast inference even <= 4 steps. Recommend: 1~8 steps.
num_inference_steps = 4
images = pipe(prompt=prompt, image=image, num_inference_steps=num_inference_steps, guidance_scale=8.0).images
images[0].save("image.png")在线demo
将LCM集成到Stable Diffusion WebUI中
SD WebUI 的 LCM 插件源码
GitHub - 0xbitches/sd-webui-lcm: Latent Consistency Model for AUTOMATIC1111 Stable Diffusion WebUILatent Consistency Model for AUTOMATIC1111 Stable Diffusion WebUI - GitHub - 0xbitches/sd-webui-lcm: Latent Consistency Model for AUTOMATIC1111 Stable Diffusion WebUI![]() https://github.com/0xbitches/sd-webui-lcm选择“Extensions”->“Install from URL”,安装LCM插件。
https://github.com/0xbitches/sd-webui-lcm选择“Extensions”->“Install from URL”,安装LCM插件。
生成的图片将会保存到outputs/txt2img-images/LCM
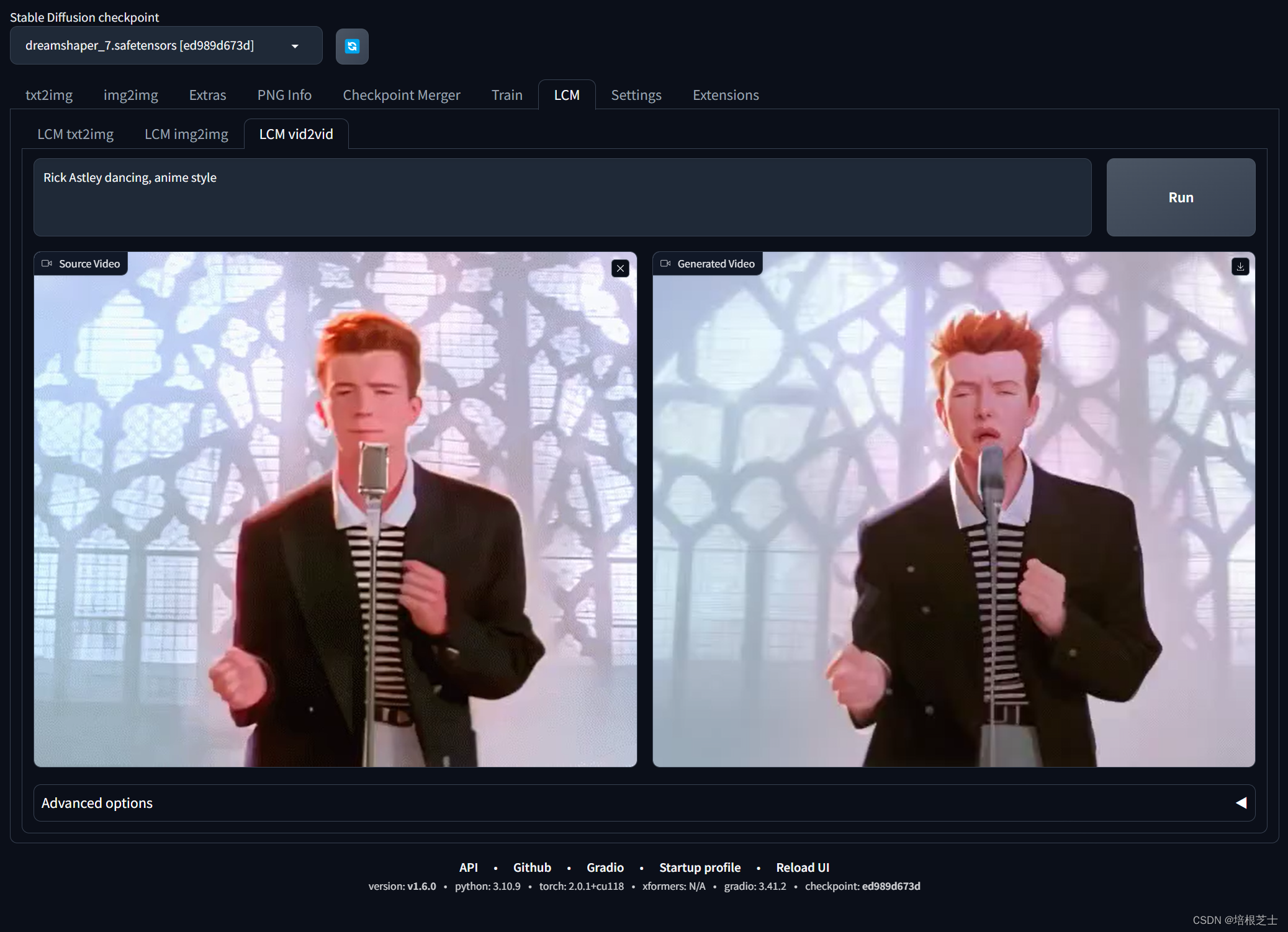
LCM插件提供了txt2img、img2img、vid2vid三个选项卡。
Img2Img和Vid2Vid的输出高度和宽度将与输入相同,目前不可更改。
生成的视频将保存到outputs/LCM-vid2vid
LCM-LoRA
LCM每个模型都需要单独蒸馏,以获得潜在的一致性蒸馏。LCM-LoRA的核心思想是只训练几个适配器层,在这种情况下,适配器是LoRA。这样,我们不必训练完整模型,并保持可训练参数数量的管理。然后,由此产生的LoRA可以应用于模型的任何微调版本,而无需单独蒸馏它们。此外,LoRA可以应用于img2img, ControlNet/T2I-Adapter, inpainting, AnimateDiff等。LCM-LoRA还可以与其他LoRA相结合,只需几个步骤(4-8)即可生成样式图像。
Lora模型下载
LCM-LoRAs 可用于 stable-diffusion-v1-5, stable-diffusion-xl-base-1.0, 和 SSD-1B 模型。
https://huggingface.co/latent-consistency/lcm-lora-sdv1-5
https://huggingface.co/latent-consistency/lcm-lora-sdxl
https://huggingface.co/latent-consistency/lcm-lora-ssd-1b
使用时我们可以将推理步骤的数量减少到仅2到8个步骤,将CFG Scale值介于1.0和2.0之间。调整Lora的权重,使其更接近原本的效果。
















 258
258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









