







| 比较点 | 抽象类 | 接口 |
| — | — | — |
| 默认方法 | 抽象类可以有默认的方法实现 | java 8之前,接口中不存在方法的实现 |
| 实现方式 | 子类使用extends关键字来继承抽象类.如果子类不是抽象类,子类需要提供抽象类中所声明方法的实现 | 子类使用implements来实现接口,需要提供接口中所有声明的实现. |
| 构造器 | 抽象类中可以有构造器 | 接口中不能 |
| 和正常类区别 | 抽象类不能被实例化 | 接口则是完全不同的类型 |
| 访问修饰符 | 抽象方法可以有public,protected和default等修饰 | 接口默认是public,不能使用其他修饰符 |
| 多继承 | 一个子类只能存在一个父类 | 一个子类可以存在多个接口 |
| 添加新方法 | 抽象类中添加新方法,可以提供默认的实现,因此可以不修改子类现有的代码 | 如果往接口中添加新方法,则子类中需要实现该方法 |
| | | |
不能.重写只适用于实例方法,不能用于静态方法,而子类当中含有和父类相同签名的静态方法,我们一般称之为隐藏.
不可变对象指对象一旦被创建,状态就不能再改变,任何修改都会创建一个新的对象,如 String、Integer及其它包装类.不可变对象最大的好处是线程安全.
静态变量存储在方法区,属于类所有.实例变量存储在堆当中,其引用存在当前线程栈.需要注意的是从JDK1.8开始用于实现方法区的PermSpace被MetaSpace取代了.
当然可以,比如final Person[] persons = new Persion[]{}.persons是不可变对象的引用,但其数组中的Person实例却是可变的.这种情况下需要特别谨慎,不要共享可变对象的引用.这种情况下,如果数据需要变化时,就返回原对象的一个拷贝.
java中提供了以下四种创建对象的方式:
-
new创建新对象
-
通过反射机制
-
采用clone机制
-
通过序列化机制
前两者都需要显式地调用构造方法. 对于clone机制,需要注意浅拷贝和深拷贝的区别,对于序列化机制需要明确其实现原理,在java中序列化可以通过实现Externalizable或者Serializable来实现.
在JDK 1.7之前,switch只能支持byte,short,char,int或者其对应的包装类以及Enum类型.从JDK 1.7之后switch开始支持String类型.但到目前为止,switch都不支持long类型.
equals(),clone(),getClass(),notify(),notifyAll(),wait(),toString
-
==是运算符,用于比较两个变量是否相等,对于基本类型而言比较的是变量的值,对于对象类型而言比较的是对象的地址. -
equals()是Object类的方法,用于比较两个对象内容是否相等.默认Object类的equals()实现如下:
public class Object {
…
public boolean equals(Object obj) {
return (this == obj);
}
…
}
不难看出此时equals()是比较两个对象的地址,此时直接==比较的的结果一样.对于可能用于集合存储中的对象元素而言,通常需要重写其equals()方法.
如果a 和b 都是对象,则 a==b 是比较两个对象内存地址,只有当 a 和 b 指向的是堆中的同一个对象才会返回 true.而 a.equals(b) 是进行内容比较,其比较结果取决于equals()具体实现.多数情况下,我们需要重写该方法,如String 类重写 equals()用于两个不同对象,但是包含的字母相同的比较:
public boolean equals(Object anObject) {
if (this == anObject) { // 同一个对象直接返回true
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) { // 按字符依次比较
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
Object中的equals()和hashcode()的联系
hashCode()是Object类的一个方法,返回一个哈希值.如果两个对象根据equal()方法比较相等,那么调用这两个对象中任意一个对象的hashCode()方法必须产生相同的哈希值;如果两个对象根据eqaul()方法比较不相等,那么产生的哈希值不一定相等(碰撞的情况下还是会相等的.)
a.hashCode()有什么用?与a.equals(b)有什么关系
hashCode()方法是为对象产生整型的 hash 值,用作对象的唯一标识.它常用于基于 hash 的集合类,如 Hashtable,HashMap等等.根据 Java 规范,使用 equal()方法来判断两个相等的对象,必须具有相同的 hashcode.
将对象放入到集合中时,首先判断要放入对象的hashcode是否已经在集合中存在,不存在则直接放入集合.如果hashcode相等,然后通过equal()方法判断要放入对象与集合中的任意对象是否相等:如果equal()判断不相等,直接将该元素放入集合中,否则不放入.
有可能.在产生hash冲突时,两个不相等的对象就会有相同的 hashcode 值.当hash冲突产生时,一般有以下几种方式来处理:
-
拉链法:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向链表进行存储.
-
开放定址法:一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入
-
再哈希:又叫双哈希法,有多个不同的Hash函数.当发生冲突时,使用第二个,第三个….等哈希函数计算地址,直到无冲突.
不行,因为同一对象的 hashcode 值必须是相同的.
基础的概念不能弄混:&是位操作,&&是逻辑运算符.需要记住逻辑运算符具有短路特性,而&不具备短路特性.来看看一下代码执行结果?
public class Test{
static String name;
public static void main(String[] args){
if(name!=null&userName.equals(“”)){
System.out.println(“ok”);
}else{
System.out.println(“erro”);
}
}
}
上述代码将会抛出空指针异常.原因你懂得.
在一个java文件中只能有一个public公共类,但是可以有多个default修饰的类.
-
使用标号和break;
-
通过在外层循环中添加标识符
内部类可以有多个实例,每个实例都有自己的状态信息,并且与其他外围对象的信息相互独立.在单个外围类当中,可以让多个内部类以不同的方式实现同一接口,或者继承同一个类.创建内部类对象的时刻不依赖于外部类对象的创建.内部类并没有令人疑惑的”is-a”关系,它就像是一个独立的实体.此外,内部类提供了更好的封装,除了该外围类,其他类都不能访问.
final,finalize()和finally{}的不同之处
三者没有任何相关性,遇到有问着问题的面试官就拖出去砍了吧.final是一个修饰符,用于修饰变量,方法和类.如果 final 修饰变量,意味着该变量的值在初始化后不能被改变.finalize()方法是在对象被回收之前调用的方法,给对象自己最后一个复活的机会.但是该方法由Finalizer线程调用,但调用时机无法保证.finally是一个关键字,与 try和catch一起用于异常的处理,finally{}一定会被执行,在此处我们通常用于资源关闭操作.
java.lang.Cloneable 是一个标示性接口,不包含任何方法.clone ()方法在 Object 类中定义的一个Native方法:
protected native Object clone() throws CloneNotSupportedException;
深拷贝和浅拷贝的区别是什么?
-
浅拷贝:被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象.换言之,浅拷贝仅仅复制所考虑的对象,而不复制它所引用的对象.
-
深拷贝:被复制对象的所有变量都含有与原来的对象相同的值.而那些引用其他对象的变量将指向被复制过的新对象.而不再是原有的那些被引用的对象.换言之.深拷贝把要复制的对象所引用的对象都复制了一遍.
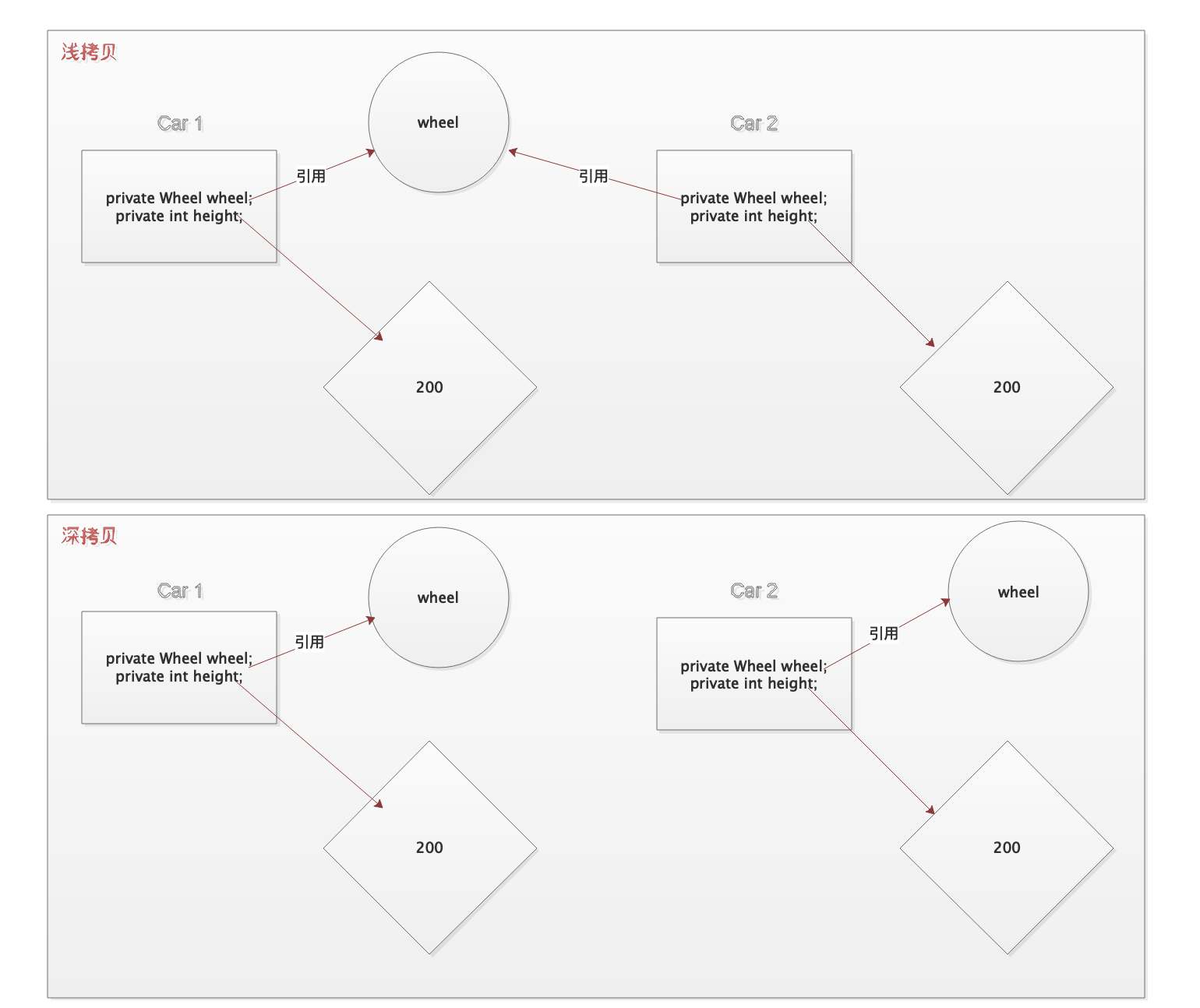
所有的人都知道static关键字这两个基本的用法:静态变量和静态方法.也就是被static所修饰的变量/方法都属于类的静态资源,类实例所共享.
除了静态变量和静态方法之外,static也用于静态块,多用于初始化操作:
public calss PreCache{
static{
//执行相关操作
}
}
此外static也多用于修饰内部类,此时称之为静态内部类.
最后一种用法就是静态导包,即import static.import static是在JDK 1.5之后引入的新特性,可以用来指定导入某个类中的静态资源,并且不需要使用类名,可以直接使用资源名,比如:
import static java.lang.Math.*;
public class Test{
public static void main(String[] args){
//System.out.println(Math.sin(20));传统做法
System.out.println(sin(20));
}
}
final有哪些用法?
final也是很多面试喜欢问的地方,但我觉得这个问题很无聊,通常能回答下以下5点就不错了:
-
被final修饰的类不可以被继承
-
被final修饰的方法不可以被重写
-
被final修饰的变量不可以被改变.如果修饰引用,那么表示引用不可变,引用指向的内容可变.
-
被final修饰的方法,JVM会尝试将其内联,以提高运行效率
-
被final修饰的常量,在编译阶段会存入常量池中.
除此之外,编译器对final域要遵守的两个重排序规则更好:
-
在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序
-
初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序.
====================================================================
这个问题其实很无聊.应该去问java中的各种数据类型在不同的平台运行时期所占位数一样么?
| 类型 | 字节 |
| — | — |
| short | 2 |
| int | 4 |
| long | 8 |
| float | 4 |
| double | 8 |
| char | |
| | |
Java中数据类型所占用的位数和平台无关,在 32 位和64位 的Java 虚拟机中,int 类型的长度都是占4字节.
Integer是int的包装类型,在拆箱和装箱中,二者自动转换.int是基本类型,直接存数值;而integer是对象;用一个引用指向这个对象.由于Integer是一个对象,在JVM中对象需要一定的数据结构进行描述,相比int而言,其占用的内存更大一些.
String s = new String("abc")创建了几个String对象?
2个.一个是字符串字面常数,在字符串常量池中;另一个是new出来的字符串对象,在堆中.
请问s1==s3是true还是false,s1==s4是false还是true?s1==s5呢?
String s1 = “abc”;
String s2 = “a”;
String s3 = s2 + “bc”;
String s4 = “a” + “bc”;
String s5 = s3.intern();
s1==s3返回false,s1==s4返回true,s1==s5返回true.
“abc"这个字符串常量值会直接方法字符串常量池中,s1是对其的引用.由于s2是个变量,编译器在编译期间无法确定该变量后续会不会改,因此无法直接将s3的值在编译器计算出来,因此s3是堆中"abc"的引用.因此s1!=s3.对于s4而言,其赋值号右边是常量表达式,因此可以在编译阶段直接被优化为"abc”,由于"abc"已经在字符串常量池中存在,因此s4是对其的引用,此时也就意味s1和s4引用了常量池中的同一个"abc".所以s1==s4.String中的intern()会首先从字符串常量池中检索是否已经存在字面值为"abc"的对象,如果不存在则先将其添加到字符串常量池中,否则直接返回已存在字符串常量的引用.此处由于"abc"已经存在字符串常量池中了,因此s5和s1引用的是同一个字符串常量.
String s1=“ab”;
String s2=“a”+“b”;
String s3=“a”;
String s4=“b”;
String s5=s3+s4;
返回false.在编译过程中,编译器会将s2直接优化为"ab",将其放置在常量池当中;而s5则是被创建在堆区,相当于s5=new String(“ab”);
Stirng中的intern()是个Native方法,它会首先从常量池中查找是否存在该常量值的字符串,若不存在则先在常量池中创建,否则直接返回常量池已经存在的字符串的引用. 比如
String s1=“aa”;
String s2=s1.intern();
System.out.print(s1==s2);
上述代码将返回true.因为在"aa"会在编译阶段确定下来,并放置字符串常量池中,因此最终s1和s2引用的是同一个字符串常量对象.
String,StringBuffer和StringBuilder区别?
String是字符串常量,final修饰;StringBuffer字符串变量(线程安全);StringBuilder 字符串变量(线程不安全).此外StringBuilder和StringBuffer实现原理一样,都是基于数组扩容来实现的.
String和StringBuffer主要区别是性能:String是不可变对象,每次对String类型进行操作都等同于产生了一个新的String对象,然后指向新的String对象.所以尽量不要对String进行大量的拼接操作,否则会产生很多临时对象,导致GC开始工作,影响系统性能.
StringBuffer是对象本身操作,而不是产生新的对象,因此在有大量拼接的情况下,我们建议使用StringBuffer(线程安全).
需要注意现在JVM会对String拼接做一定的优化,比如
String s="This is only "+ “simple” +“test”;
以上代码在编译阶段会直接被优化成会`String s=“This is only simple test”.
StringBuffer和StringBuilder的实现原理一样,其父类都是AbstractStringBuilder.StringBuffer是线程安全的,StringBuilder是JDK 1.5新增的,其功能和StringBuffer类似,但是非线程安全.因此,在没有多线程问题的前提下,使用StringBuilder会取得更好的性能.
公共静态不可变,即public static final修饰的变量就是我们所说的编译期常量.这里的public可选的.实际上这些变量在编译时会被替换掉,因为编译器明确的能推断出这些变量的值(如果你熟悉C++,那么这里就相当于宏替换).
编译器常量虽然能够提升性能,但是也存在一定问题:你使用了一个内部的或第三方库中的公有编译时常量,但是这个值后面被其他人改变了,但是你的客户端没有重新编译,这意味着你仍然在使用被修改之前的常量值.
false,因为有些浮点数不能完全精确的表示出来.
如果不是特别关心内存和性能的话,使用BigDecimal.否则使用预定义精度的 double 类型.
可以使用String接收 byte[] 参数的构造器来进行转换,注意要使用的正确的编码,否则会使用平台默认编码.这个编码可能跟原来的编码相同.也可能不同.
可以做强制转换,但是Java中int是32位的而byte是8 位的.如果强制转化int类型的高24位将会被丢弃,byte 类型的范围是从-128到128.
+=操作符会进行隐式自动类型转换,此处a+=b隐式的将加操作的结果类型强制转换为持有结果的类型,而a=a+b则不会自动进行类型转换.如:
byte a = 127;
byte b = 127;
b = a + b; // 报编译错误:cannot convert from int to byte
b += a;
以下代码是否有错,有的话怎么改?
short s1= 1;
s1 = s1 + 1;
以下代码是否有错,有的话怎么改?
short s1= 1;
s1 = s1 + 1;
有错误.short类型在进行运算时会自动提升为int类型,也就是说s1+1的运算结果是int类型,而s1是short类型,此时编译器会报错.
short s1= 1;
s1 += 1;
+=操作符会对右边的表达式结果强转匹配左边的数据类型,所以没错.
有时候希望传入的类型有一个指定的范围,从而可以进行一些特定的操作,这时候就需要通配符了?在Java中常见的通配符主要有以下几种:
-
<?>: 无限制通配符 -
<? extends E>: extends 关键字声明了类型的上界,表示参数化的类型可能是所指定的类型,或者是此类型的子类 -
<? super E>: super关键字声明了类型的下界,表示参数化的类型可能是指定的类型,或者是此类型的父类
它们的目的都是为了使方法接口更为灵活,可以接受更为广泛的类型.
-
< ? extends E>: 用于灵活读取,使得方法可以读取 E 或 E 的任意子类型的容器对象。 -
< ? super E>: 用于灵活写入或比较,使得对象可以写入父类型的容器,使得父类型的比较方法可以应用于子类对象。
用简单的一句话来概括就是为了获得最大限度的灵活性,要在表示生产者或者消费者的输入参数上使用通配符,使用的规则就是:生产者有上限(读操作使用extends),消费者有下限(写操作使用super).
==================================================================
JVM中垃圾回收机制最基本的做法是分代回收.内存中的区域被划分成不同的世代,对象根据其存活的时间被保存在对应世代的区域中.一般的实现是划分成3个世代:年轻,年老和永久代.所有新生成的对象优先放在年轻代的(大对象可能被直接分配在老年代,作为一种分配担保机制),年轻代按照统计规律被分为三个区:一个Eden区,两个 Survivor区.在年轻代中经历了N次垃圾回收后仍然存活的对象,就会被放到年老代中.因此可以认为年老代中存放的都是一些生命周期较长的对象.
方法区也被称为永久代,用于存储每一个java类的结构信息:比如运行时常量池,字段和方法数据,构造函数和普通方法的字节码内容以及类,实例,接口初始化时需要使用到的特殊方法等数据,根据虚拟机实现不同,GC可以选择对方法区进行回收也可以不回收.
对于不同的世代可以使用不同的垃圾回收算法。比如对由于年轻代存放的对象多是朝生夕死,因此可以采用标记-复制,而对于老年代则可以采用标记-整理/清除.
Minor GC
发生在新生代的GC为Minor GC .在Minor GC时会将新生代中还存活着的对象复制进一个Survivor中,然后对Eden和另一个Survivor进行清理.所以,平常可用的新生代大小为Eden的大小+一个Survivor的大小.
Major GC
在老年代中的GC则为Major GC.
Full GC
通常是和Major GC等价的,针对整个新生代,老年代,元空间metaspace(java8以上版本取代perm gen)的全局范围的GC.
关于GC的类型,其实依赖于不同的垃圾回收器.可以具体查看相关垃圾回收器的实现.
新生代进入老年代
-
分配担保机制:当Minor GC时,新生代存活的对象大于Survivor的大小时,这时一个Survivor装不下它们,那么它们就会进入老年代.
-
如果设置了-XX:PretenureSizeThreshold5M 那么大于5M的对象就会直接就进入老年代.
-
在新生代的每一次Minor GC 都会给在新生代中的对象+1岁,默认到15岁时就会从新生代进入老年代,可以通过-XX:MaxTenuringThreshold来设置这个临界点
垃圾回收从理论上非常容易理解,具体的方法有以下几种:
-
标记-清除
-
标记-复制
-
标记-整理
-
分代回收
更详细的内容参见深入理解垃圾回收算法
这就是所谓的对象存活性判断,常用的方法有两种:
-
引用计数法
-
对象可达性分析
由于引用计数法存在互相引用导致无法进行GC的问题,所以目前JVM虚拟机多使用对象可达性分析算法.
主要由以下四种:
-
JVM方法栈中引用的对象
-
本地方法栈中引用的对象
-
方法区常量引用的对象
-
方法区类属性引用的对象
通知GC开始工作,但是GC真正开始的时间不确定.
在java中主要有以下四种引用类型:强引用,软引用,弱引用,虚引用.不同的引用类型主要体现在GC上:
-
强引用:如果一个对象具有强引用,它就不会被垃圾回收器回收.即使当前内存空间不足,JVM也不会回收它.而是抛出 OutOfMemoryError 错误.使程序异常终止.如果想中断强引用和某个对象之间的关联.可以显式地将引用赋值为null,这样一来的话.JVM在合适的时间就会回收该对象.
-
软引用:在使用软引用时,如果内存的空间足够,软引用就能继续被使用而不会被垃圾回收器回收.只有在内存不足时,软引用才会被垃圾回收器回收.
-
弱引用:具有弱引用的对象拥有的生命周期更短暂.因为当 JVM 进行垃圾回收,一旦发现弱引用对象,无论当前内存空间是否充足,都会将弱引用回收.不过由于垃圾回收器是一个优先级较低的线程,所以并不一定能迅速发现弱引用对象.
-
虚引用:如果一个对象仅持有虚引用,那么它相当于没有引用,在任何时候都可能被垃圾回收器回收.
更多了解参见深入对象引用
WeakReference与SoftReference的区别?
这点在四种引用类型中已经做了解释,这里在重复一下.虽然WeakReference与SoftReference都有利于提高 GC和内存的效率,但是 WeakReference ,一旦失去最后一个强引用,就会被 GC 回收,而软引用虽然不能阻止被回收,但是可以延迟到 JVM 内存不足的时候.
不像C语言,我们可以控制内存的申请和释放,在Java中有时候我们需要适当的控制对象被回收的时机,因此就诞生了不同的引用类型,可以说不同的引用类型实则是对GC回收时机不可控的妥协.
=====================================================================
简而言之,进程是程序运行和资源分配的基本单位,一个程序至少有一个进程,一个进程至少有一个线程.进程在执行过程中拥有独立的内存单元,而多个线程共享内存资源,减少切换次数,从而效率更高.线程是进程的一个实体,是cpu调度和分派的基本单位,是比程序更小的能独立运行的基本单位.同一进程中的多个线程之间可以并发执行.在Linux中,进程也称为Task.
程序运行完毕,jvm会等待非守护线程完成后关闭,但是jvm不会等待守护线程.守护线程最典型的例子就是GC线程.
多线程的上下文切换是指CPU控制权由一个已经正在运行的线程切换到另外一个就绪并等待获取CPU执行权的线程的过程.
通过实现java.lang.Runnable或者通过扩展java.lang.Thread类.相比扩展Thread,实现Runnable接口可能更优.原因有二:
-
Java不支持多继承.因此扩展Thread类就代表这个子类不能扩展其他类.而实现Runnable接口的类还可能扩展另一个类.
-
类可能只要求可执行即可,因此继承整个Thread类的开销过大.
两者都能用来编写多线程,但实现Callable接口的任务线程能返回执行结果,而实现Runnable接口的任务线程不能返回结果.Callable通常需要和Future/FutureTask结合使用,用于获取异步计算结果.
Thread类中的start()和run()方法有什么区别?
在start()方法中最终要的是调用了Native方法start0()用来启动新创建的线程线程启动后会自动调用run()方法.如果我们直接调用其run()方法就和我们调用其他方法一样,不会在新的线程中执行.
##怎么检测一个线程是否持有对象锁
Thread类提供了一个Native方法holdsLock(Object obj)方法用于检测是否持有某个对象锁:当且仅当对象obj的锁被某线程持有的时候才会返回true.
public static native boolean holdsLock(Object obj);
线程阻塞有哪些原因?
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,不论你是刚入门Java开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
结果,而实现Runnable接口的任务线程不能返回结果.Callable通常需要和Future/FutureTask结合使用,用于获取异步计算结果.
Thread类中的start()和run()方法有什么区别?
在start()方法中最终要的是调用了Native方法start0()用来启动新创建的线程线程启动后会自动调用run()方法.如果我们直接调用其run()方法就和我们调用其他方法一样,不会在新的线程中执行.
##怎么检测一个线程是否持有对象锁
Thread类提供了一个Native方法holdsLock(Object obj)方法用于检测是否持有某个对象锁:当且仅当对象obj的锁被某线程持有的时候才会返回true.
public static native boolean holdsLock(Object obj);
线程阻塞有哪些原因?
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
[外链图片转存中…(img-9qkG26o0-1715729180157)]
[外链图片转存中…(img-l8357RPE-1715729180158)]
[外链图片转存中…(img-7aVBjZSX-1715729180159)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,不论你是刚入门Java开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!















 2538
2538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









