






Lora模型
在SD里面,有一个模型叫Lora模型
绝大多数有意思的图,都需要用到Lora模型来生成
这一节课,我们就来看看Lora有什么用,以及该怎么用
一、Lora有什么用
这是我用AI绘画生成出来的美女照片


这是AI美女穿上了我指定的衣服的照片


不管是穿汉服还是穿JK都可以


更好玩的是,通过AI绘画,可以直接生成各种游戏或者动漫的真人coser




以上这些照片都是用了Stable Diffusion的Lora模型生成的
简单来说,Lora可以固定我们照片的特征
固定人物特征,可以让我们生成好看的小姐姐,统一角色形象


固定物品特征,可以让小姐姐穿上特定的衣服


还有固定照片风格,可以生成特定风格的插画


这节课会分为三部分:
1.下载Lora
2.使用Lora
3.随机数种子
我会详细介绍关于lora的知识,让你看完这篇文章,就能生成出来自己的专属模特
二、下载Lora
Lora是需要自己去下载的模型
我在网盘里面给大家分享了一些比较常用,而且比较好看的Lora,有需要的朋友可以自己去保存
除此之外,我们还可以自己去模型网站下载
其中最出名的模型网站就是C站,里面的模型非常多
但是这个网站需要科学上网,大家只能自己想想办法了
现在国内也有很多模型网站,大家也可以去找找看
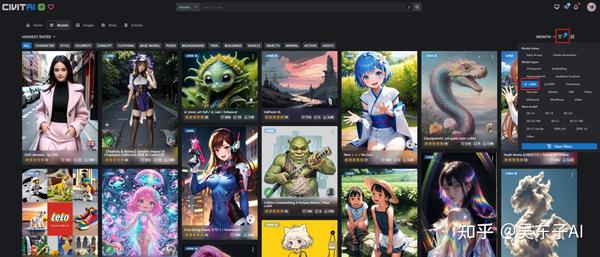
接下来我们看看怎么在C站下载Lora模型
打开C站,点击右上角的小图标,点击“Lora”,就可以把Lora模型筛选出来
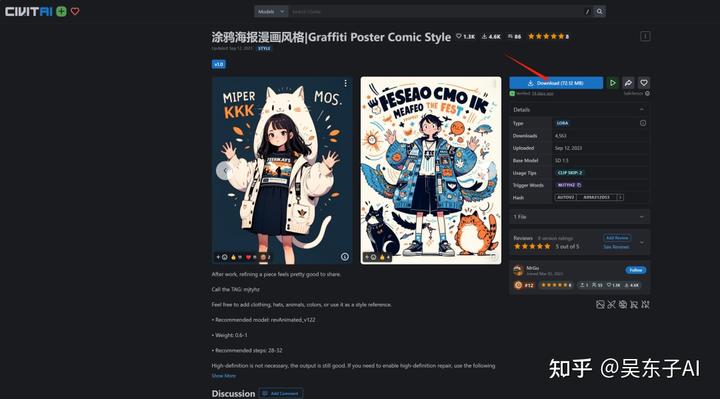
找到自己喜欢的Lora点进去,点击右边的“Download”就可以下载模型
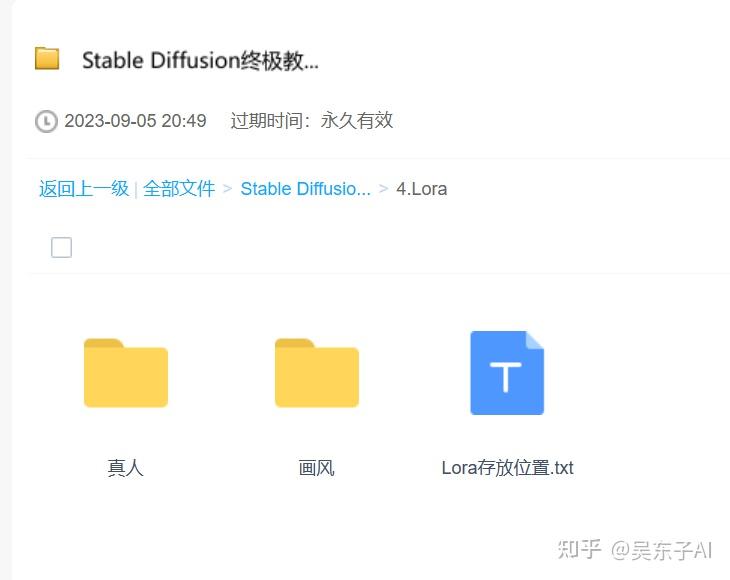
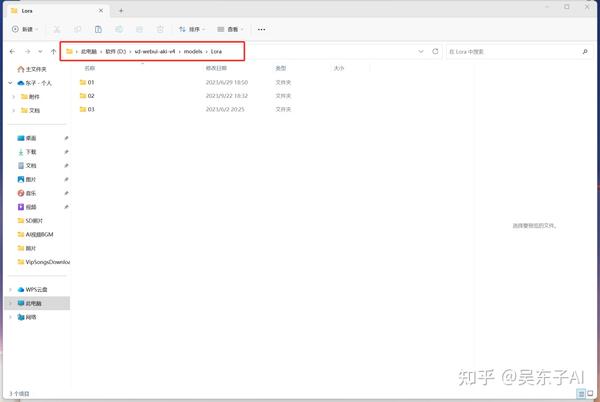
这些下载的模型需要放到特定的文件夹里面
在SD文件夹里面找到models文件夹,把Lora模型放到Lora文件夹里就可以了
除了用网站上别人的Lora,我们还可以自己炼制Lora
炼lora的教程大家可以翻看我前面的文章


三、使用Lora
下载好了lora模型之后,我们就来看看lora怎么用
打开sd,点击lora,这里面就是我们下载保存到电脑的Lora模型
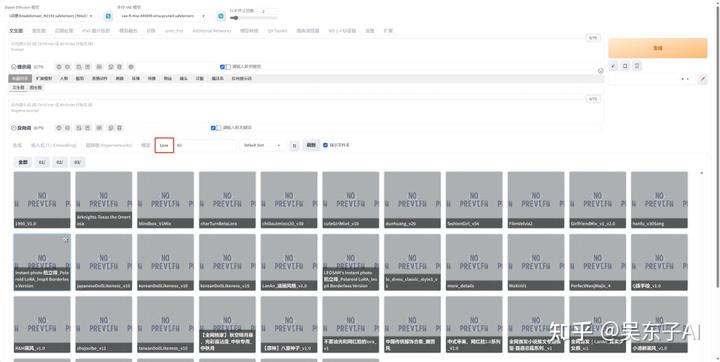
如果这里没有加载出来,点一下这个刷新按钮就行了
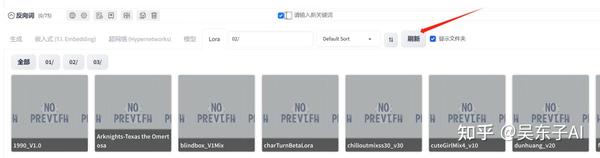
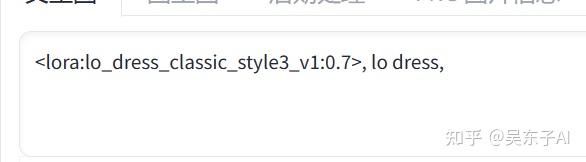
直接点击我们要用的Lora,关键词的文本框里面就会自动添加一串英文
前半部分是这个lora的名字,后面的数字1是权重
lora的权重一般设置在0~1之间,因为权重大于1,出来的照片可能会变得奇奇怪怪
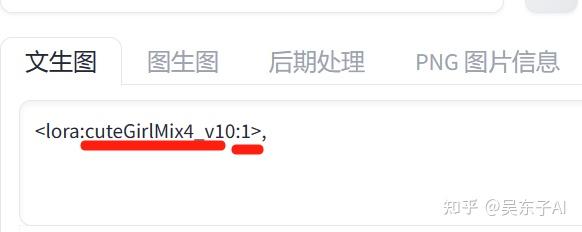
Lora是可以叠加使用的,像这张照片就用了三个Lora
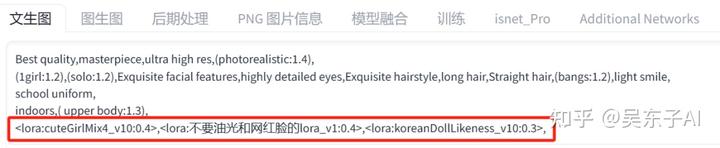

只是要注意,和关键词一样,lora之间也要用英文状态下的逗号分隔开
另外,每个Lora设置的权重不一样,出来的照片都会不一样
想要生成一个好看的小姐姐,可以多去试试不同的权重组合
关于Lora还有一个需要注意的点,那就是我们在网站上下载Lora的时候,要顺带看一下这个Lora有没有触发词
触发词的意思是,我们在使用某个Lora的时候,在关键词里必须输入某个词语,这样Lora才会起作用
比如这个JK制服的Lora,它有两个触发词
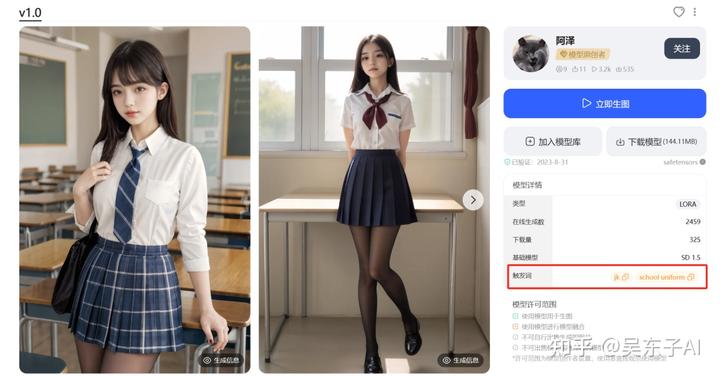
如果我们用了Lora却没加上触发词
出来的照片是这样的,Lora完全不发挥作用

当我们关键词里面加上这两个触发词之后,生成出来的照片是这样的,这时候Lora才起作用了

为了之后我们每一次更加方便的调用Lora,我们可以把触发词和推荐权重直接保存在SD里面
把鼠标放在Lora上,然后点击右上角的小图标
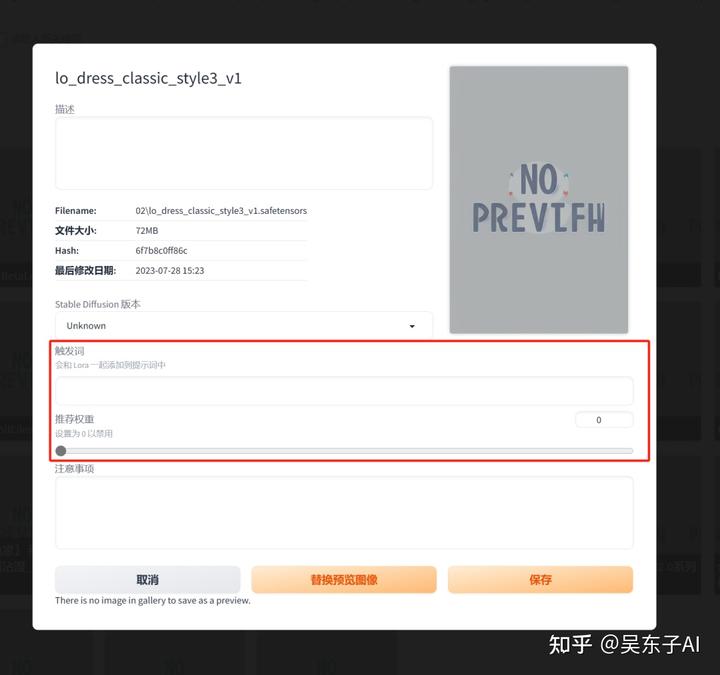
这时候会弹出来这样一个窗口
我们就可以把触发词和推荐权重记在这里
比如这个洛丽塔裙子的Lora,它的触发词是“lo dress”,作者推荐的权重是0.7
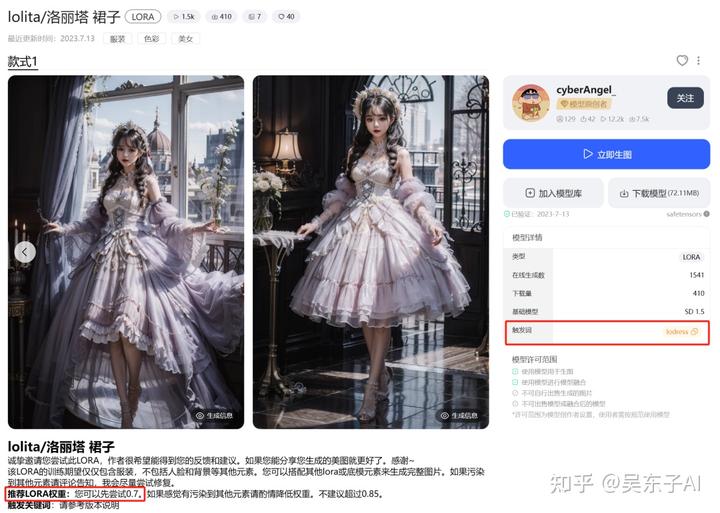
那我们就可以回到SD,把这个信息记录下来,然后点击“保存”
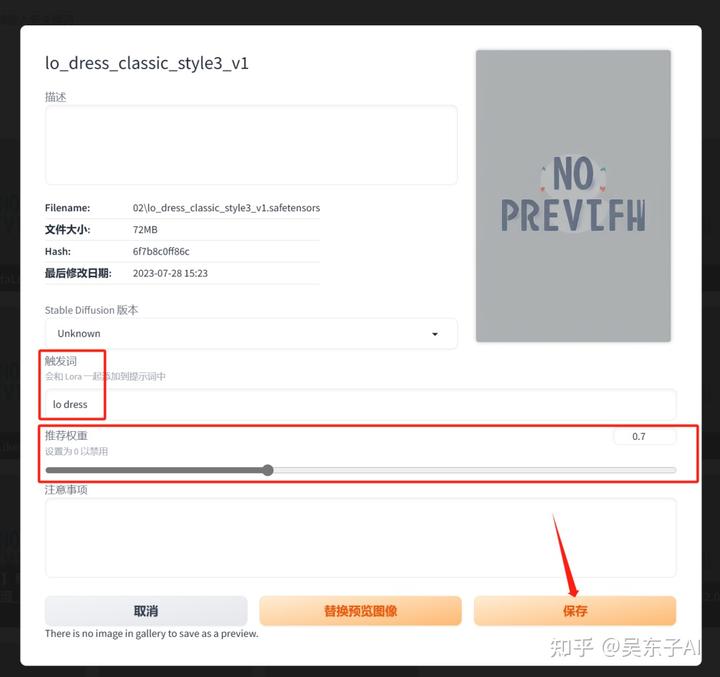
这时候我们直接点这个lora,关键词的文本框里就会自动加载触发词和调整lora权重
这样设置了就非常方便,哪怕很久没用这个lora,也不会忘记它的触发词
四、随机数种子
为什么有时候我们跟别人用的大模型、关键词、Lora还有其他参数都一样
可生成出来的图就是不一样呢

那是因为还有一个因素影响着照片——就是“随机数种子”
AI绘画是在这么一张全是噪点的图片上不断迭代,最后生成出来一张照片的
而不同的随机数种子,就代表着不同的噪点图
哪怕所有设置以及关键词都一样,不同的噪点图生成出来的图片就不一样


所以,只有当大模型、关键词、参数以及随机数种子都一样的时候,我们才能生成和别人差不多一样的照片
但因为电脑配置的差别,也会导致照片有细微的不同
在我们生成的照片下面,有一大串英文,这是照片的生成信息,seed值就是我们这张照片的随机数种子
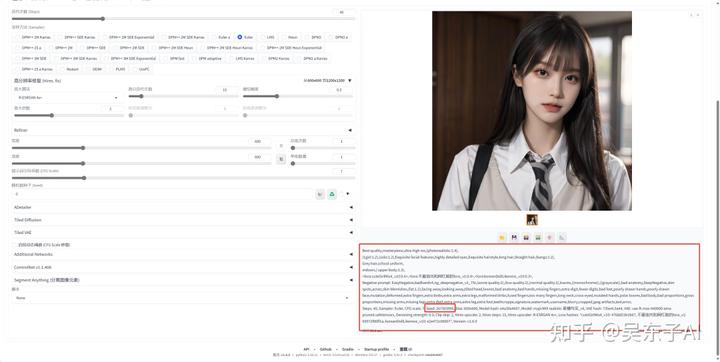
点击随机数种子这个绿色图标,这个seed值就会加载上来
这时候我们点击生成,就会用这个随机数种子的噪点图作为底图重新生成照片
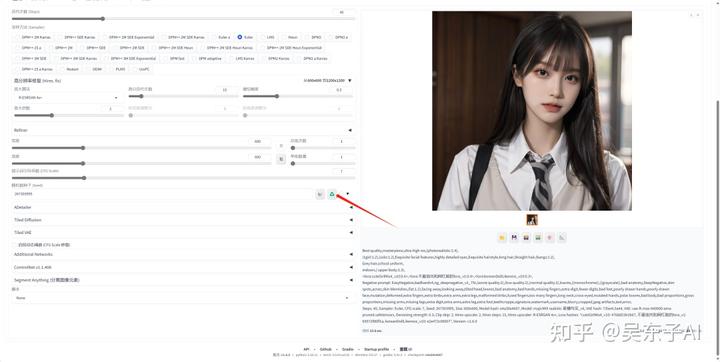
点击这个骰子就会变成-1
当随机数种子为“-1”的时候,代表着每一次生成照片都会给一个随机的数值
这也是为什么 我们每次点生成都能出来不同照片的原因

通过加不同的Lora,或者是多个Lora不同权重的叠加
我们就可以生成出来非常多有意思的图片
好啦,以上就是关于Lora的全部内容
图生图
在前面的课程中,我们是通过写关键词来生成图片,就是文字生成图片,也叫文生图
而第四节课我们就来讲讲用图片来生成图片,也就是我们给SD一张图片,让SD在这张图片的基础上生成出来一张新的图片,这个功能就叫图生图
一、图生图能做什么
1.真人和二次元相互转换
可以用自己的图片生成二次元头像


也可以将动漫里的人物变成真人


2.局部修改图片信息
给小姐姐在线换装


改图片人物
将右边的小姐姐换成一个男生


3.AI商业模特
将商场里的假人模特变成真人


图生图的玩法还有很多,例如给人物换脸、对图片进行扩图等等
这节课我会结合二次元头像、人物在线换装、AI商业模特三个最好玩的案例
详细介绍图生图的功能以及操作流程
看完这篇文章,你也能立刻做出来同款有趣的照片
二、二次元头像
不知道大家以前有没有试过在网上找别人定制头像,把自己的照片发给别人,然后定制一张自己的二次元头像
现在用AI一分钟就能做出来了


制作方法具体可以分为三步:
1.上传图片+参数设置
2.关键词
3.选大模型
1.上传图片
打开SD,在状态栏里点击“图生图”
这个就是图生图的页面,和文生图没有太大的区别
只是下面会多出来一个空白区域给我们上传照片
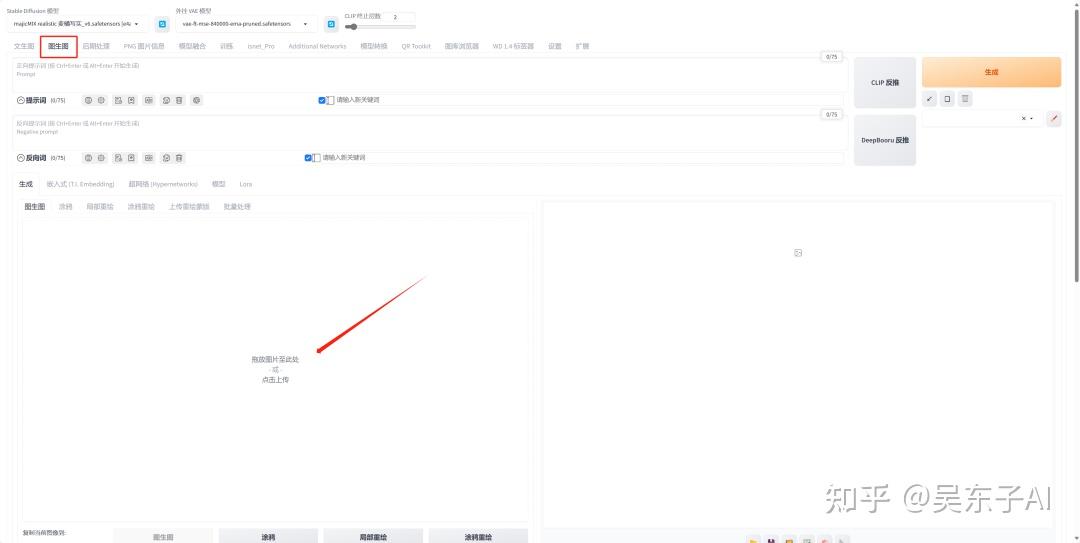
这里的图生图、涂鸦、局部重绘等等就是图生图的功能
生成二次元头像用的就是第一个,图生图
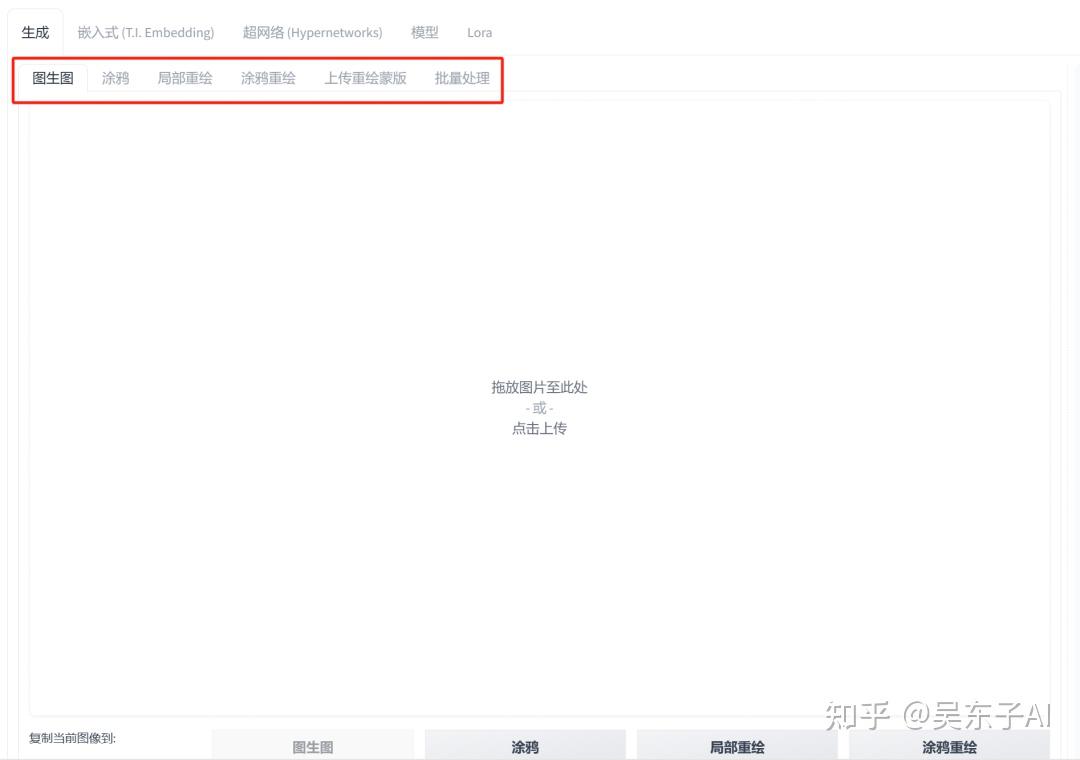
在空白的地方上传一张真人照片
往下滑看到参数设置
迭代步数:30步
采样方法:DPM++2M Karras
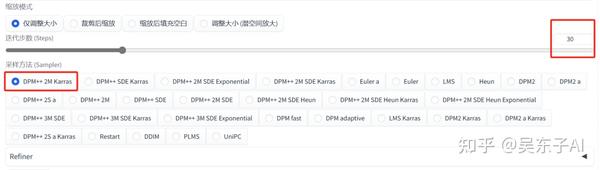
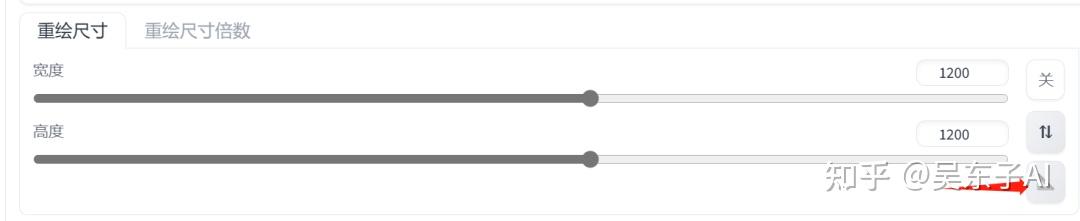
这个重绘尺寸要设置成和我们上传的图片一样的比例
可以直接点右边的尺子同步参数
如果同步的参数过大或者过小
可以自己把这个数值除以2或者乘2
还有最重要的一个参数,就是重绘幅度
重绘幅度的意思就是 我们最后生成的照片跟原图差别有多大

可以看一下这张对比图
当重绘幅度为0的时候,照片不会发生变化
当重绘幅度为1的时候,生成出来的照片跟原图就毫无关系了
我们的重绘幅度可以设置在0.5~0.7之间
这个参数是没有固定的,大家在实际操作中可以多试试不同的重绘幅度

这样我们的参数就设置好啦
2.写关键词
关键词最主要的就是用词语去描述我们的原图
这里我们可以借助一个插件——标签器
它可以根据我们的图片反推出来关键词
在状态栏里点击“WD1.4标签器”
在左边空白区域上传我们的原图
右边就是自动生成的关键词
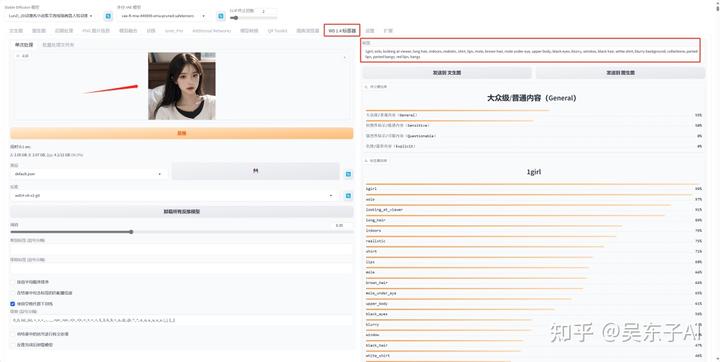
我们可以把这些关键词复制到翻译软件,大概检查一下,把不符合我们出图的关键词删掉
比如我们现在是要生成二次元图片,那“realistic(现实)”这个关键词就要删掉
关键词里面还有“痣”这个单词,如果不想最后生成的图片里有痣的话,这个关键词就可以删掉
1girl, solo, looking at viewer, long hair, indoors, realistic, shirt, lips, mole, brown hair, mole under eye, upper body, black eyes, blurry, window, black hair, white shirt, blurry background, collarbone, parted lips, parted bangs, red lips, bangs
1girl,solo,看着观众,长发,室内,逼真,衬衫,嘴唇,痣,棕色头发,眼睛下面的痣,上身,黑色眼睛,模糊,窗口,黑色头发,白色衬衫,模糊背景,锁骨,分开的嘴唇,分开的刘海,红唇,刘海
接着把其余的关键词复制到SD里面
再把我们通用的负面关键词复制进来

这样我们的关键词就写完了
3.选大模型
要生成二次元图片,大模型就一定要换成二次元的大模型


换不同的二次元模型还可以出来不同风格的图片



好啦,以上就是将真实照片转成二次元照片的制作方法
二次元转换成真人的制作方法也是一样的,这里就不再演示了
只是一定要记得,大模型要换成一个真实的大模型


三、人物在线换装
具体的操作步骤和前面是差不多的
只是这里用到的是图生图的局部重绘功能
意思就是重新生成图片的某个区域
1.上传图片
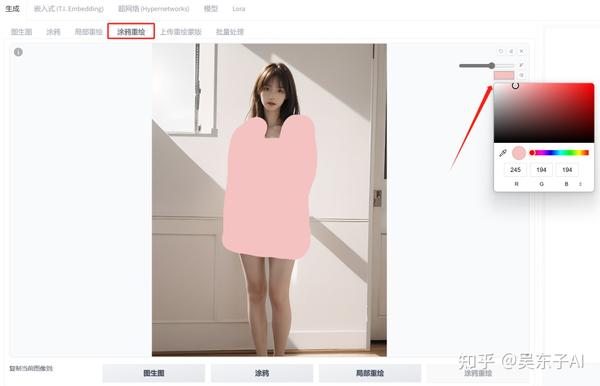
打开“局部重绘”,上传我们要修改的图片
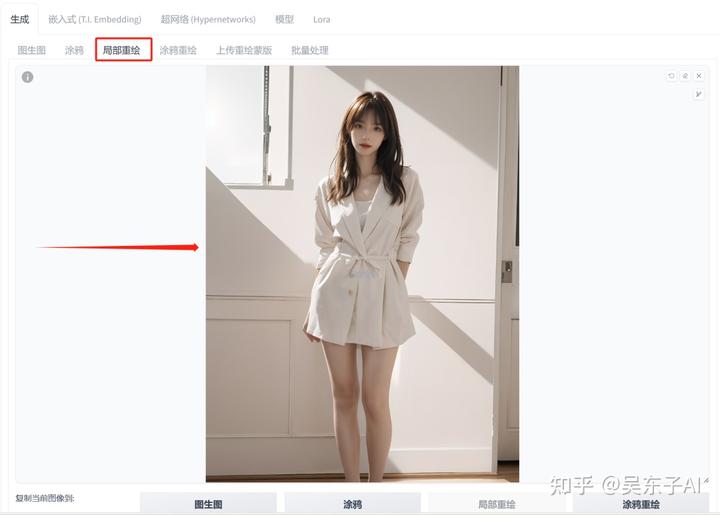
在右边可以调整画笔的大小,把人物的衣服区域都涂白

然后往下看到参数设置
这里会比前面多了两个参数
一个是蒙版模式,“重绘蒙版内容”的意思是重新生成我们涂白的地方
“重绘非蒙版内容”就是除了涂白的地方,其他都重新生成
这里我们是要重新生成衣服,所以就选“重绘蒙版内容”
然后就是“蒙版区域内容处理”
一般就用前面两个,填充和原图
如果要重新生成的地方跟原图区别比较大,那就选填充
如果只是想在原图的基础上进行一点小变动,那就选原图
接下来的迭代步数、采用方法、重绘尺寸和前面是一样的
看到最后一个重绘幅度,设置在0.6~0.8之间
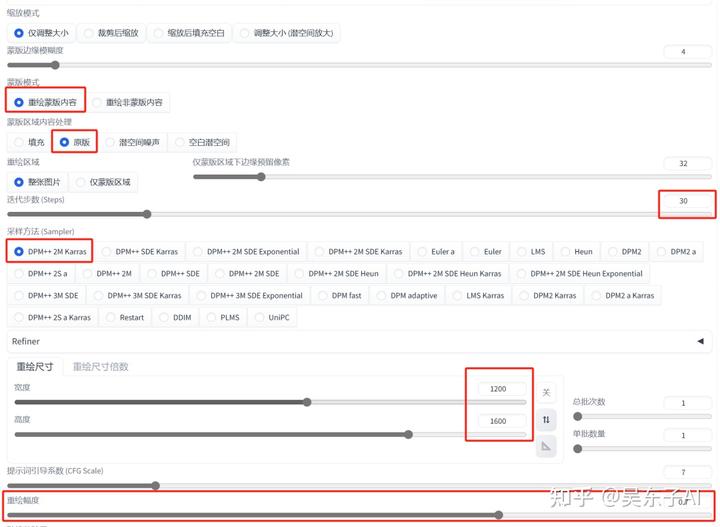
这样我们的参数就设置好了
2.写关键词
关键词的内容除了我们反推出来的关键词,我们还要加上对重绘部分的描述
比如我现在要把白色的衣服换成粉色的裙子,那我就要在关键词里面输入“粉色裙子”
再加上通用的负面关键词
这样关键词就写好了

3.选大模型
大模型就选一个写实的大模型就可以

点击生成,就可以实现一键换装

除了局部重绘,涂鸦重绘也可以给人物换装
并且涂鸦重绘可以直接指定画笔的颜色,这样生成的照片就会按照我们画的颜色直接生成对应颜色的衣服



局部重绘不仅可以给人物换衣服
还可以对人物换头、换脸、换背景
四、AI商业模特
AI商业模特就是让我们现实中的衣服穿在AI模特身上


首先我们需要一张衣服的图片,这个衣服最好是穿在假人模特身上,或者是衣服的平铺图,这样衣服的褶皱会比较自然
然后还需要一张把衣服抠出来的黑白蒙版图片


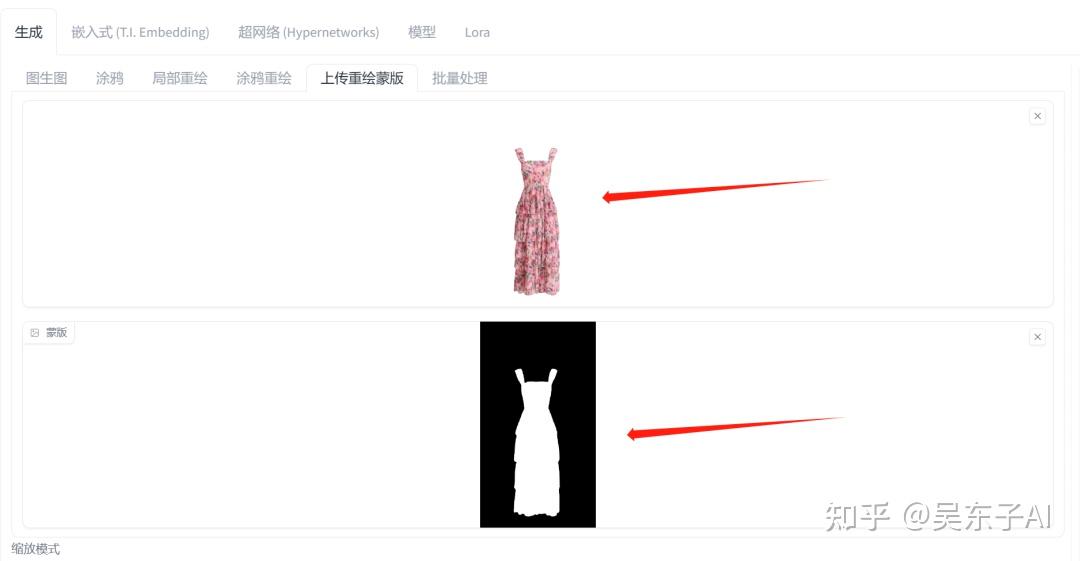
打开SD,用到的是图生图的蒙版重绘
蒙版重绘需要上传两张图片
上面上传衣服的原图下面上传黑白蒙版图
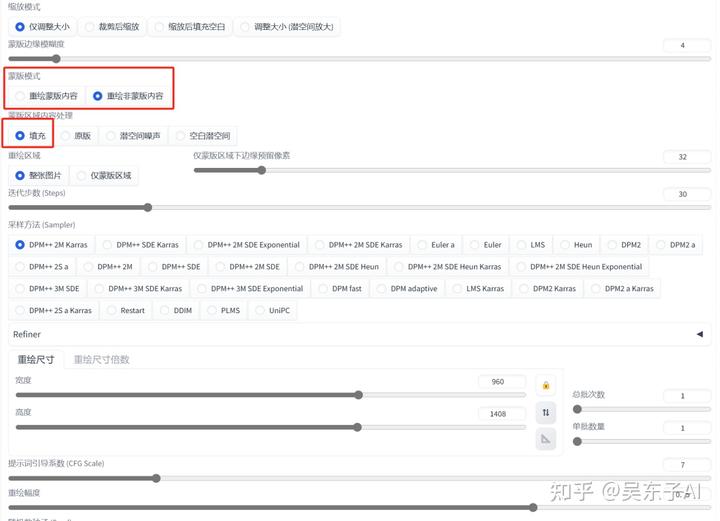
下面的蒙版模式换成“重绘非蒙版内容”
因为我们现在是要生成除了衣服以外的地方
然后蒙版内容处理选择“填充”
其他参数和前面的设置是一样的
接下来选一个写实的大模型
关键词就写生成一个女生的关键词

最后点击生成

除了我们上面的三个实操案例
图生图还有很多好玩的地方
例如对人物进行换头、换脸,把游戏装备高清真实化等等
这些具体的案例教程大家可以直接去看我们的其他文章
好啦,以上就是图生图的内容,希望对大家有帮助
ControlNet
在SD里面,想要生成出来的图片最大程度的符合我们脑海里的画面有三个最关键的因素
1.关键词
2.Lora
3.ControlNet
关键词和Lora我们已经讲过了,这节课我们就讲SD里最强大的功能——ControlNet
一、Controlnet有什么用
1.给老照片上色


2.给线稿上色


3.控制人物姿势


4.让照片动起来


5.有趣玩法
可以生成酷炫的赛博机车照、真人漫改



制作二次元头像


生成创意字


controlnet好玩的地方还有很多很多,例如恢复照片画质、制作艺术二维码等等等等。
作者:吴东子AI
链接:https://zhuanlan.zhihu.com/p/659211251
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
二、controlnet是什么
AI绘画最终要实现的目标——让出的图与我们脑海里想象的画面一致
但目前现状是:随机性太强
很多时候能不能出来一个好看的画面,只能通过大量的「抽卡」实现,以数量去对冲概率
这种情况下,如果能用好控制出图的三个最关键因素,能让「出图与我们想象的画面一致」概率更高
1.提示词
2.Lora
3.ControlNet
提示词的作用是奠定整个图的大致画面
Lora的作用是让图片主体符合我们的需求
ControNet的作用是精细化控制整体图片的元素——主体、背景、风格、形式等
提示词的用法我在SD的教程里讲过,这个更多的是需要平时的积累,用AB测试去知道每个词对图片产生的影响,从而养成提示词思维
而我们这篇文章主要讲的是ControlNet的用法,把17种模型都给你演示一遍,让你知道每一种模型有什么用,应该怎么用,从而真正掌握ControlNet
ControlNet就是你提供一张图片,然后选择一种采集方式,去生成一张新的图片
比如这张照片
可以选择采集图片中人物的骨架,从而在新的图片中,生成出一样姿势的人


也可以选择采集图片中的线稿,从而在新的图片中,生成一样线稿的画面


又或者选择采集图片中已有的风格,从而在新的图片中,生成一样风格的画面


用的时候不必拘束于哪一种模型更好,更重要的是你脑海里想要什么样的画面
多去尝试,也可以结合其他模型一起用,最终把图片变成你想要的画面就可以了
接下来这节课分为三个部分,会详细介绍controlnet的全部内容
1.安装controlnet
2.controlnet的具体使用流程
3.controlnet的分类讲解
三、安装controlnet
一般通过整合包安装的Stable Diffusion,都已经装了有ControlNet这个插件
我们只要更新插件,然后下载对应的模型就可以了
打开sd的启动页面
点击左边的版本管理,打开扩展页面
找到controlnet那一栏,点击更新就好了

接下来就是下载controlnet模型
17种模型我已经全部打包好放在网盘了
大家只要下载下来,放在对应的文件夹就可以
存放位置:SD文件夹>models>controlnet

四、controlnet的具体使用流程
Controlnet里面总共有17个模型,理论上来说就可以有14种用法甚至可以两个或者多个Controlnet一起用,这样就有更多的玩法了
但不管怎样,它们的具体操作步骤都是差不多的
接下来我们先讲解controlnet的统一操作方法
再讲解controlnet的每一个模型的功能
就以指定人物姿势为例子,
看看怎么让我们生成出来的照片,摆出来这个同款芭蕾舞姿势

这里我们可以分为两个步骤:
- 1.SD基础设置
- 2.controlnet的设置
1.SD基础设置
SD的基础设置就是我们前面课程所讲的内容
包括选大模型、写关键词、参数设置、如果是想生成好看的真人图片,还可以加上Lora
01.选大模型
首先是选一个大模型,我这里选的是一个写实的大模型

02.写关键词
关键词就是按照我们第二节课的关键词模板去写,再加上Lora模型
再把通用的负面关键词也复制进来

03.参数设置
迭代步数35步
采样方法:Euler
宽度和高度可以先不管,我们等一下再处理

这样SD的基础设置就完成了,接下来就到controlnet的设置
2.controlnet的使用
controlnet的使用方法就只有两步
- 上传图片
- 选模型
滑到SD最下面打开controlnet的面板,在空白的地方上传参考照片

把这里的 启用 和 完美像素模式 打开
如果电脑配置比较低,还可以打开这个低显存模式

然后点击右边这个向上的小按钮,这样照片的尺寸就会自动同步到宽度和高度

如果发现同步过来的数值太大或者太小,我们可以按比例把这个数字除以2或者乘2

再往下看到控制类型,意思就是 我们要控制生成图片的什么地方
现在我们要控制的是人物的姿势那就选openpose
下面就会自动加载预处理器和模型

简单来说,预处理器是用来识别我们上传的参考照片的,不同的预处理器识别出来的东西就不一样
模型就是将预处理器处理之后的结果加载到我们要生成的照片上面
点击爆炸按钮 ,就可以看到预处理之后的人物姿势线条

最后点击生成就可以了,小姐姐就会摆出和我们参考图一样的姿势


controlnet的不同功能的实现其实就是上传不一样的照片,然后选用不一样的预处理器和模型
一般情况下,预处理器和模型名字一样,是配套使用的
controlnet是辅助我们生成想要的照片的一个工具
我们的大模型和关键词也非常关键
要换照片风格一定要记得换大模型
接下来我们就看一下每一种预处理器和模型都有什么用
三、controlnet的分类讲解
我把17种模型,按照对照片的不同约束类型,分成了以下几类
有对人物姿势进行约束的,也有对照片里的线条进行约束的,还有对照片风格进行约束等等

现在我们就按照分类顺序,看看17种模型具体能干些什么
1.姿势约束
这一节讲的是openpose模型,主要控制生成照片人物的姿势
这里的姿势有身体姿势、表情、手指形态三个
可以只控制某一个或者两个,也可以三个一起控制
身体姿势身体姿势+脸部表情只有脸部表情身体姿势+手指+表情身体姿势+手指

01.控制身体姿势
一般情况下,在SD里面生成一张照片,照片人物的动作都是随机的
但controlnet可以让生成出来的人物摆出任何你想要的姿势


首先我们正常设置大模型和关键词
然后打开controlnet,上传自己想要生成的姿势照片
controlnet的模型选择:
预处理器:openpose
模型:openpose
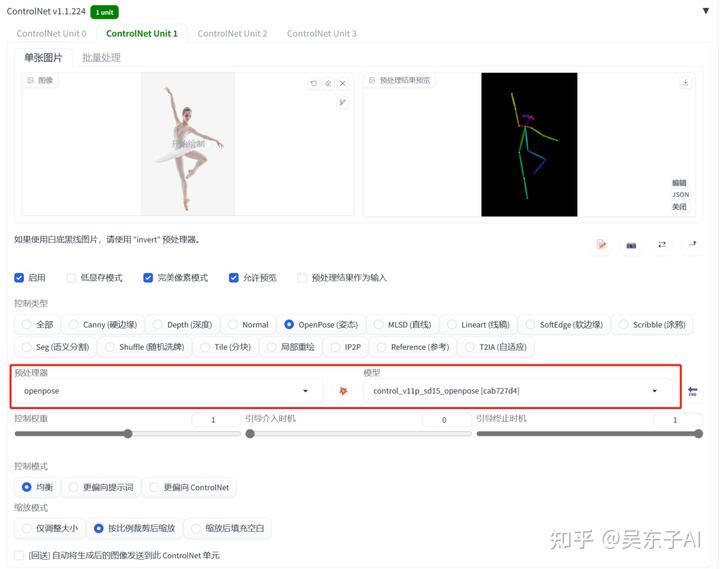
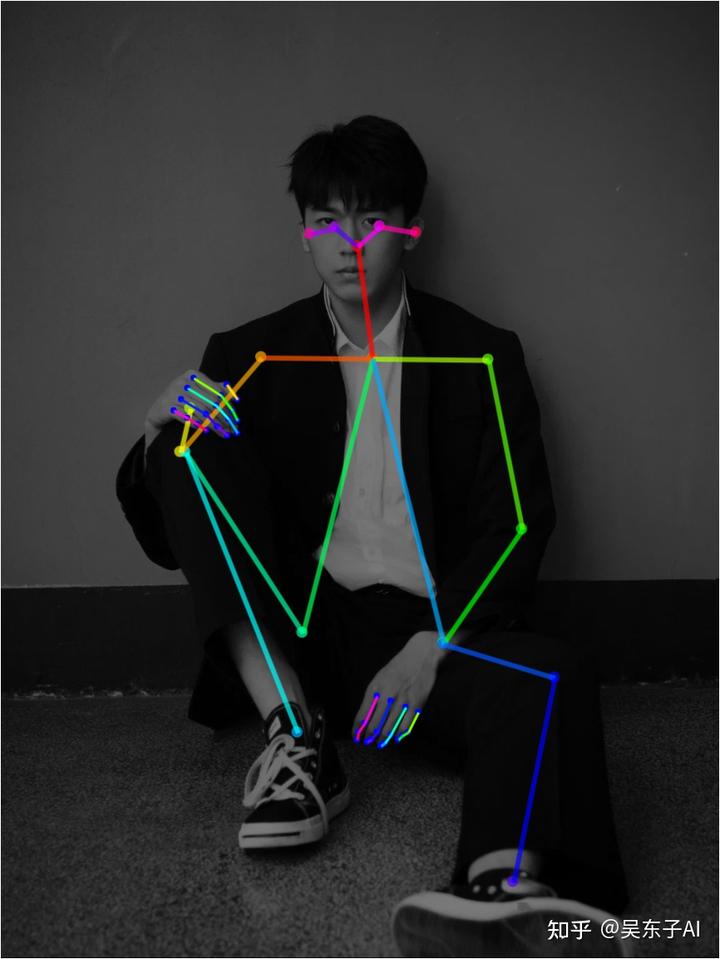
点击预处理的爆炸按钮就可以看到,模特的姿势被提取成了一个火柴人
里面的小圆点就是人体的重要关节节点

看看生成出来的照片,模特的姿势就几乎完全复刻出来了
02.控制人物姿势和手指
除了识别人物整体的姿势以外,还可以识别手指的骨骼
这样在一定程度下就可以避免生成多手指或者缺少手指的照片


具体的操作跟前面是一样的
只是预处理器的选择不同
controlnet的模型选择:
预处理器:openpose_hand
模型:openpose
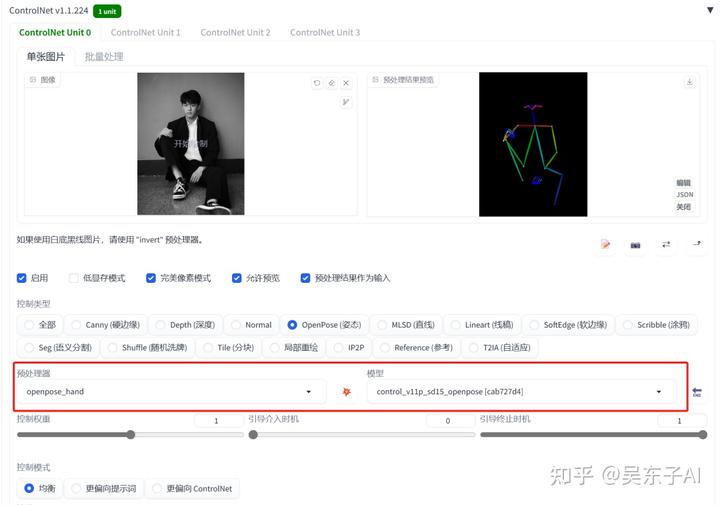
看看SD预处理之后的火柴人,在人体整体姿势的基础上,还多了线条和节点表示手指
03.控制人物表情
openpose除了控制人物的姿势,还可以控制人物的表情
但是用controlnet复刻人物表情比较适合放特写的大头照
这样识别出来的五官才会更加精确
相对应的也只能生成出来大头照


这里我们又换了一个预处理器
controlnet的模型选择:
预处理器:openpose_faceonly
模型:openpose
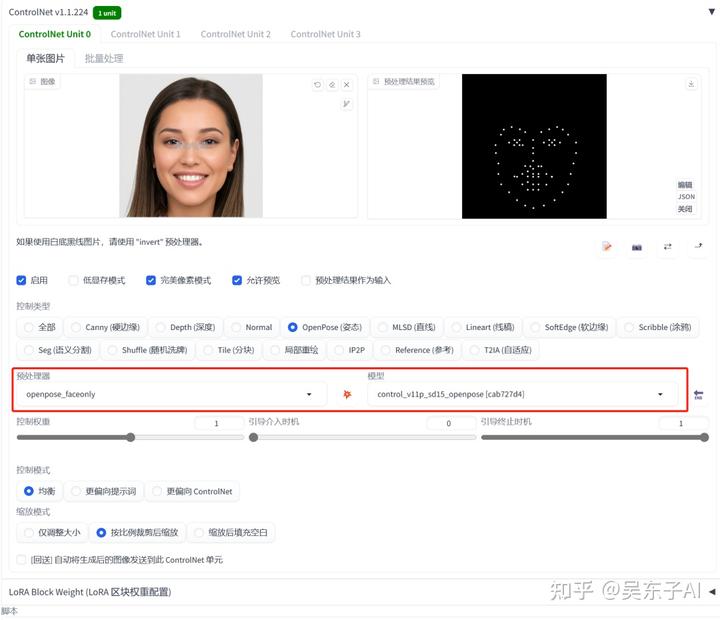
预处理之后就是把模特的脸型五官用点描出来

看看生成出来的照片,脸型和五官在一定程度上都还原了
但是,如果你生成的照片用了Lora再用controlnet控制表情可能会导致生成出来的照片跟Lora的人不太像
因为生成出来的照片的人物五官和脸型都被controlnet影响了

04.全方面控制人物姿势
这里我们是把人物的整体姿势、手指、表情都复刻了


controlnet的模型选择:
预处理器:openpose_full
模型:openpose
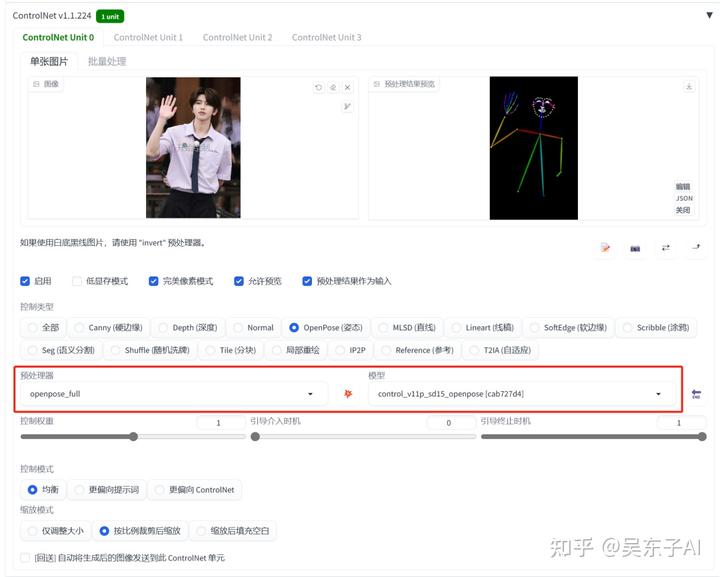
看看处理后的照片就会有我们上面说到的所有东西
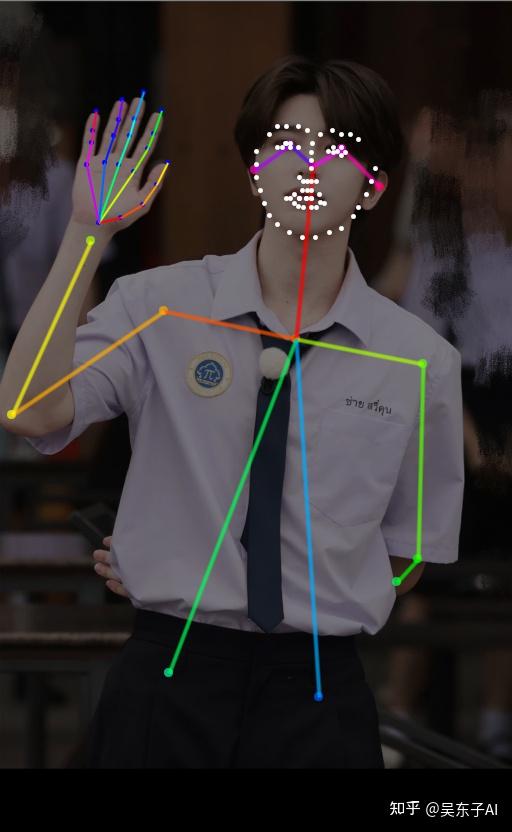
05.自由编辑火柴人
有时候预处理器处理出来的火柴人可能会不太准确
又或者我们需要更加细致的去调节
这时候我们可以再安装一个插件,这样我们就可以自己去调节预处理之后的火柴人
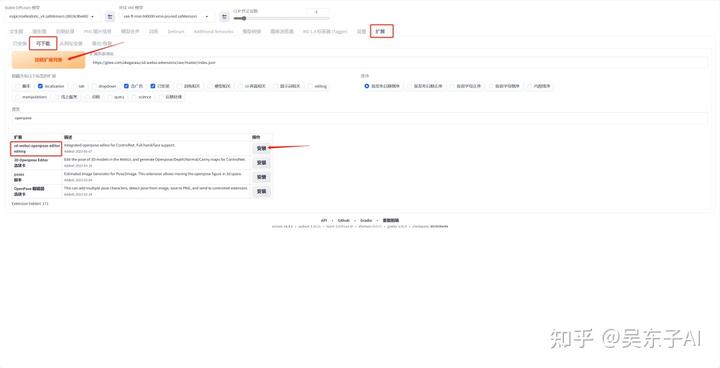
安装插件的方法:
①在“扩展”里点击“可下载”页面
②点击“加载扩展列表”
③在搜索框里输入“openpose”
④安装“sd-webui-openpose-editor”
⑤点击“已安装”页面
⑥点击“应用更改并重载前端”按钮
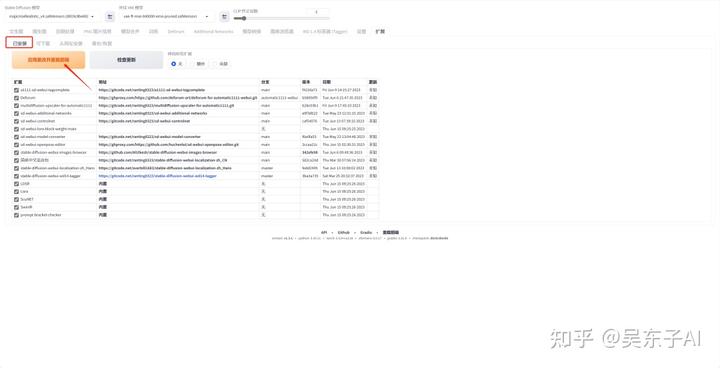
这样插件就安装好啦!
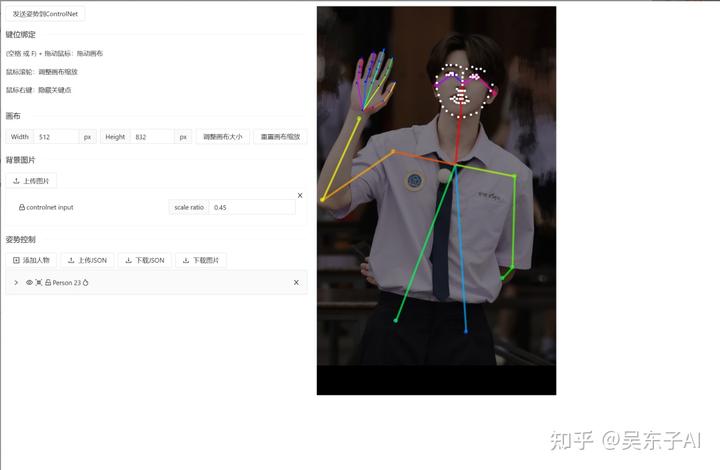
插件的使用方法
接着我们回到controlnet里面
点击预处理后的图像旁边的“编辑”按钮,就可以自行去编辑火柴人的节点
如果打开编辑按钮是空白的,那就先点击一下预处理之后的图片,再去编辑
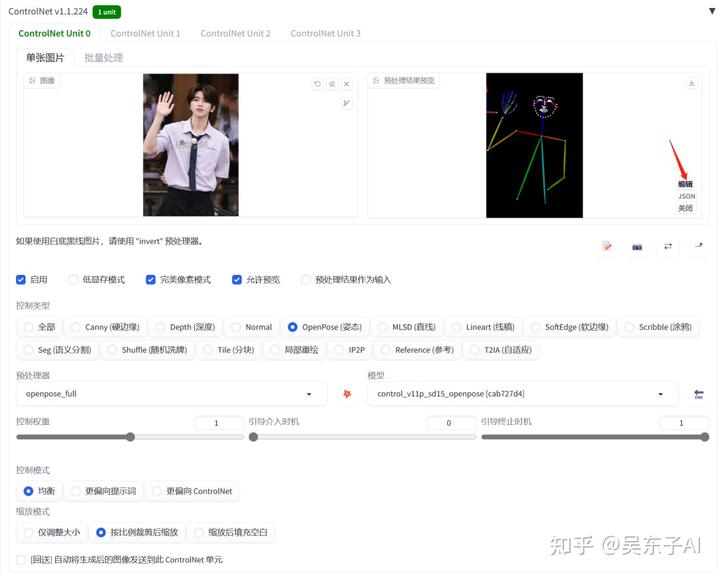
把鼠标放到圆形节点上面,就可以调整位置
调整好了之后,点击左上角的“发送姿势到controlnet”就可以啦
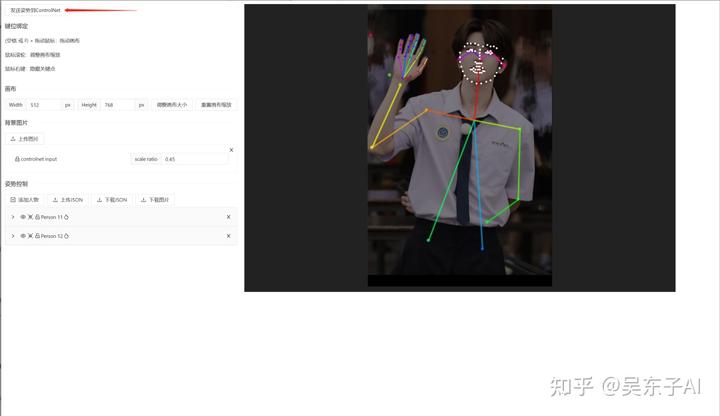
这样通过自己的调节,把腿的节点拉长,就可以生成一个大长腿美女了


06.小结
识别人体姿势有五个预处理器,在这里有一些我自己选预处理器的小技巧
在日常使用中,如果原图的手指骨骼比较清晰,可以用识别到手指的预处理器
如果识别出来的手指线条比较乱,自己调整也没调整好,那就只识别身体姿势
不然生成出来的照片手指反而更乱了
控制表情的最好用在生成近景特写图片,这样识别出来的才比较准确
最后想说
AIGC(AI Generated Content)技术,即人工智能生成内容的技术,具有非常广阔的发展前景。随着技术的不断进步,AIGC的应用范围和影响力都将显著扩大。以下是一些关于AIGC技术发展前景的预测和展望:
1、AIGC技术将使得内容创造过程更加自动化,包括文章、报告、音乐、艺术作品等。这将极大地提高内容生产的效率,降低成本。2、在游戏、电影和虚拟现实等领域,AIGC技术将能够创造更加丰富和沉浸式的体验,推动娱乐产业的创新。3、AIGC技术可以帮助设计师和创意工作者快速生成和迭代设计理念,提高创意过程的效率。
未来,AIGC技术将持续提升,同时也将与人工智能技术深度融合,在更多领域得到广泛应用。感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程。
对于从来没有接触过AI绘画的同学,我已经帮你们准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
AIGC学习必备工具和学习步骤
工具都帮大家整理好了,安装就可直接上手

现在AI绘画还是发展初期,大家都在摸索前进。
但新事物就意味着新机会,我们普通人要做的就是抢先进场,先学会技能,这样当真正的机会来了,你才能抓得住。
如果你对AI绘画感兴趣,我可以分享我在学习过程中收集的各种教程和资料。
学完后,可以毫无问题地应对市场上绝大部分的需求。
这份AI绘画资料包整理了Stable Diffusion入门学习思维导图、Stable Diffusion安装包、120000+提示词库,800+骨骼姿势图,Stable Diffusion学习书籍手册、AI绘画视频教程、AIGC实战等等。
【Stable Diffusion安装包(含常用插件、模型)】
【AI绘画12000+提示词库】

【AI绘画800+骨骼姿势图】

【AI绘画视频合集】
还有一些已经总结好的学习笔记,可以学到不一样的思路。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

















 4664
4664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









