







大数据文摘受权转载自夕小瑶科技****说
单说大模型 AI 的发展对人们想象力释放的助力,基于 Stable Diffusion 模型的方法首当其冲。透过文本描述到图像生成技术,大模型为我们的想象力打开了一个恢弘的梦幻世界。透过点滴文字,就有可能重现禁锢在我们脑海中无法释放的光怪陆离。

而最近,Stable Diffusion 持续进化,打个响指加一个框架使用 AnimateDiff,文本图像生成便可以由静到动,一次性的将个性化文本生成的图像进行动态化,实现一键生成 GIF 动图!首先,来展示一下 AnimateDiff 的动图生成效果,当我们希望生成展示一个在客厅高兴的穿着自己新盔甲的女孩的图像时,捕捉关键词 cybergirl,smiling,armor,living room 等等,稍作修饰输入如下 Prompt:
long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted.
即可以得到一段自然逼真的动态图像:

类似的,使用 Prompt:
1 girl, anime, long pink hair, necklace, earrings, masterpiece, highly detailed, high quality, 8k
可以生成一段更加动漫风格的 GIF:

利用不同风格的模型,这些生成的动图可以是充满动漫风的卡通形象:

也可以是更加逼真的人物造型:

可以是动漫电影的背景片段:

也可以是水墨风的艺术画卷

而更有意思的,是 AnimateDiff 支持与 ControlNet 结合使用,譬如我们希望让前文生成的盔甲女孩模仿下图女孩的动作:

只需要非常简单的配置启用 ControlNet,将上图作为控制图就可以生成如下的图像,上文生成出的盔甲女孩完美的模仿了上图中女孩的动作,为自定义的动图生成添足了想象力!

同时,通过使用 motion LoRA 方法,利用 Prompt 我们还可以控制“摄像机”的动作,譬如我们希望摄像机向左平移,即背景向右移动,可以在 Prompt 中添加 <lora:v2_lora_PanLeft:0.75 > 表示使用0.75的权重让摄像机向左平移,生成的效果如下图:

此外,AnimateDiff 还支持图像到动图的生成,我们可以定义生成动图的初始图像与结束图像,从而使用 AnimateDiff 补全运动过程。从训练方式上来看,AnimateDiff 也并不复杂,在用户个性化或自定义的文本-图像生成模型(T2I)的基础上,AnimateDiff 使用短视频的剪辑数据完成了一个运动建模模块的训练,类似一个插件,AnimateDiff 通过在 T2I 模型使用基础上嵌入这个运动建模模块,从而使得图像成功“由静转动”。
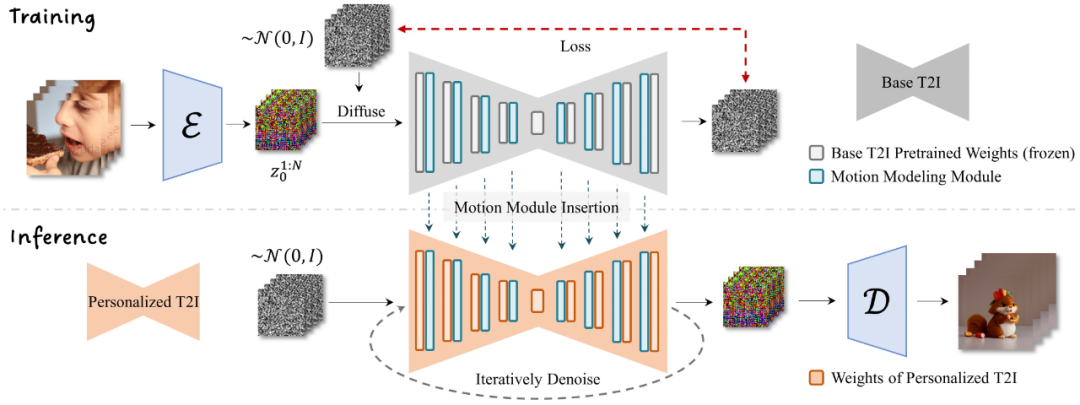
毋庸置疑,单一静态的图像表达能力存在上限,而 AnimateDiff 点石成金般赋予图像“动起来”的能力,极大的扩展了我们简单的输入文本的表达能力。从抽象的语言文字到具象的图片再到细节更加丰富的动图(视频),Stable Diffusion 逐步进化高速发展。走到 AnimateDiff,恰如国外的一则新闻所述:很有可能,AnimateDiff 会重新定义整个动画行业!


写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

 若有侵权,请联系删除
若有侵权,请联系删除

















 4186
4186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









