






在信息爆炸的时代,数据已成为新石油。但如何从杂乱的数据中提炼出商业价值?今天我结合真实案例,总结出这套"数据炼金术"方法论。助你突破常规,深挖数据价值,在复杂的业务场景中脱颖而出。
方法一:RFM模型——识别你的黄金客户
概念原理:通过最近消费时间(Recency)、消费频率(Frequency)、消费金额(Monetary)三维度划分用户价值。
最近一次消费(Recency):是指客户最近一次购买的时间距离现在的间隔。一般来说,间隔越短,说明客户对企业的产品或服务越关注,也更有可能再次购买。
消费频率(Frequency):指客户在一定时间内购买的次数。消费频率高的客户通常对产品或服务有较高的忠诚度和满意度,是企业的优质客户。
消费金额(Monetary):是指客户在一定时间内购买产品或服务的总金额。该指标直接反映了客户对企业的贡献价值,消费金额越高的客户,对企业的利润贡献越大。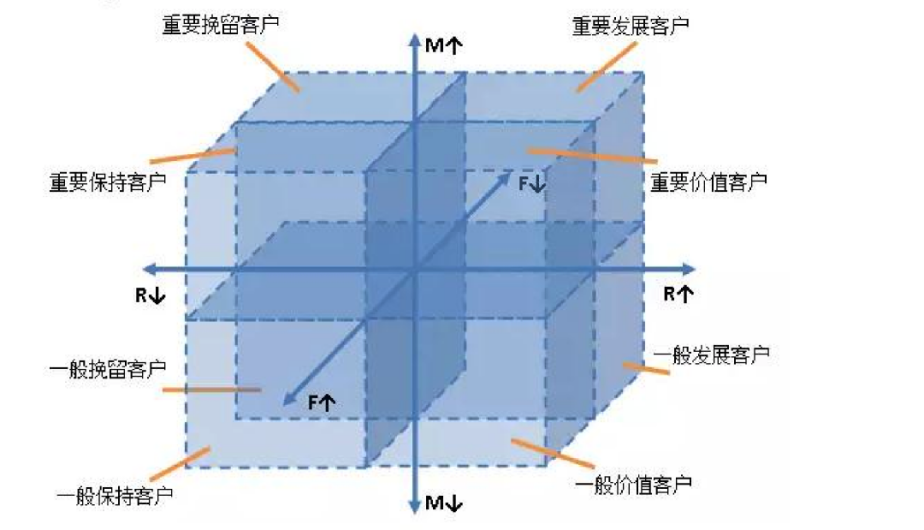 案例分析:某母婴品牌通过RFM分析发现:重要价值客户仅占2.97%却贡献43%营收,沉睡客户激活活动ROI提升300%。
案例分析:某母婴品牌通过RFM分析发现:重要价值客户仅占2.97%却贡献43%营收,沉睡客户激活活动ROI提升300%。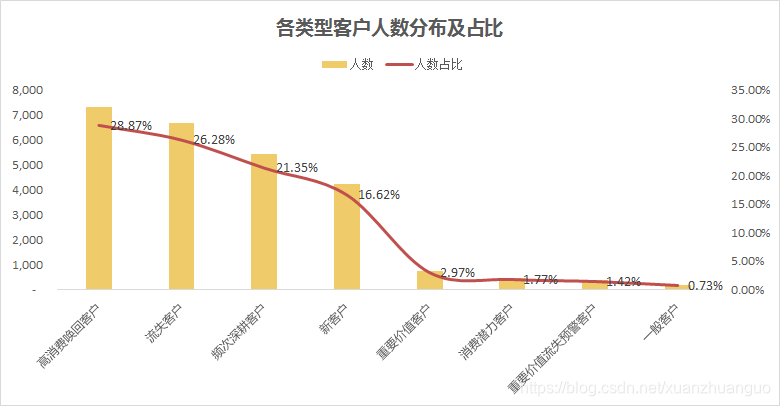
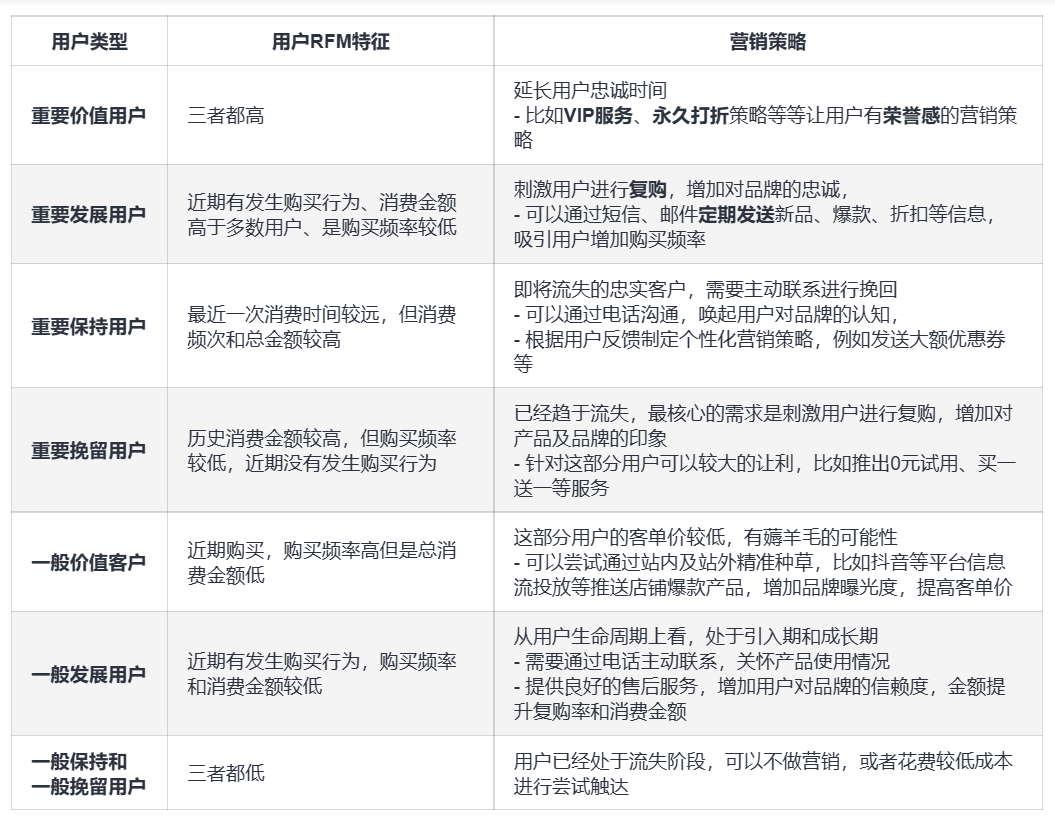
实际应用:根据行业特性调整权重,如快消品侧重F,奢侈品侧重M最后把用户分成八个类别,针对不同的RFM特征为用户制定不同的营销策略:
方法二:购物篮分析——发现隐藏的关联规则
概念原理:是一种在零售业非常流行的技术,用于发现顾客购买产品之间的关联规则。
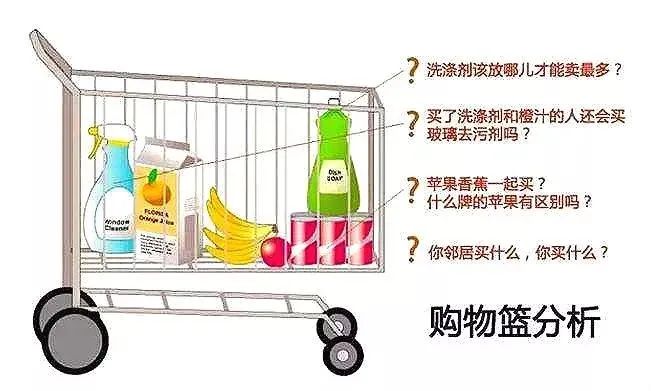
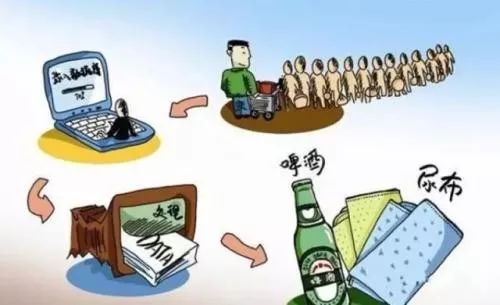
案例分析:20 世纪 90 年代,美国沃尔玛超市的管理人员在分析销售数据时,发现“啤酒”与“尿布”这两件看似无关的商品,经常会同时出现在同一个购物篮中。经调查,在美国有婴儿的家庭中,通常是母亲在家照看婴儿,年轻的父亲下班后去超市购买尿布,同时会顺便为自己买啤酒。沃尔玛发现这一现象后,将啤酒与尿布摆放在相同区域,方便年轻父亲购买,这一举措提高了顾客购物体验,使啤酒和尿布的销量都得到增加,为超市带来更多收入。
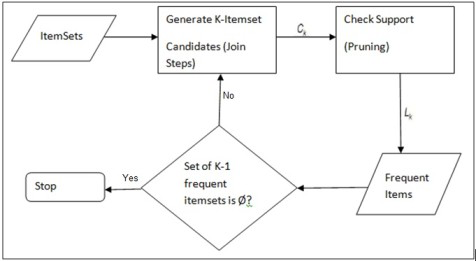
Apriori算法:是一种用于挖掘数据集中频繁项集的算法,进而用于生成关联规则。这种算法在数据挖掘、机器学习、市场篮子分析等多个领域都有广泛的应用。执行流程主要包含以下两个部分:
频繁项集生成(Frequent Itemset Generation): 找出满足最小支持度阈值的所有频繁项集。
关联规则生成(Association Rule Generation): 从频繁项集中生成高置信度的关联规则。
算法步骤如下图:
实际应用:某书店发现"心理学书籍+香薰蜡烛"的组合购买率超预期,重组货架后相关品类销量提升27%
方法三:漏斗分析法——诊断转化瓶颈
概念原理:是一种通过分析业务流程中各环节转化率来评估流程效率与效果的数据分析方法。其分析步骤包括确定业务流程,如电商购物的浏览、加购、下单、支付等流程;定义各环节指标,像浏览量、购物车用户数、订单数等;收集相关数据;计算各环节转化率与流失率;绘制漏斗图直观展示数据;依据结果分析原因并提出优化建议。
案例分析:某电商平台将数据可视化为漏斗分析图,能帮助找出用户流失点、评估活动效果、提升用户留存及优化业务流程,以提高转化率、销售额、工作效率等。
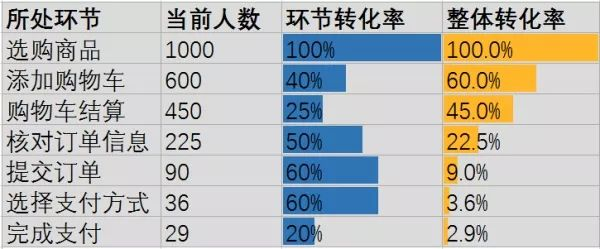
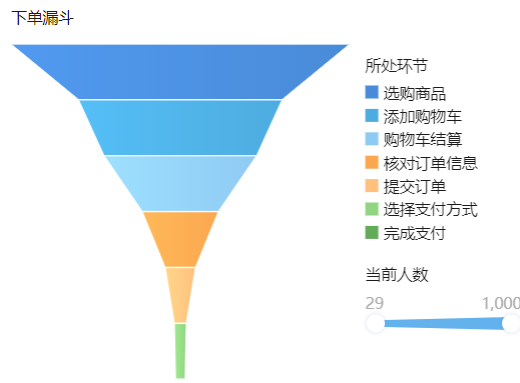
实际应用:根据漏斗图中显示的结果,深入分析转化率较低或流失率较高的环节。可能的原因包括页面设计不佳、流程繁琐、产品价格过高、用户体验差等。针对不同的原因,提出相应的优化建议和改进措施,例如优化页面布局、简化流程、调整价格策略、提供更好的客户服务等。
方法四:聚类分析——打破传统分类局限
概念原理:聚类分析是一种无监督学习的数据分析方法,旨在将数据集中的样本划分为不同的群组,使得同一群组内的样本具有较高的相似性,而不同群组间的样本具有较大的差异性。
K-means算法要点:肘部法则确定最佳K值需对数据进行标准化处理案例分析:用某航空公司的数据对客户群进行聚类,然后对不同客户制定不同的营销策略。

客户群0:没有任何特征的普通客户
客户群1:偏爱乘坐打折飞机的客户
客户群2:乘坐飞机次数都离城远的高净值客户
客户群3:入会时间较早的客户
客户群4:近期没有进行消费的客户
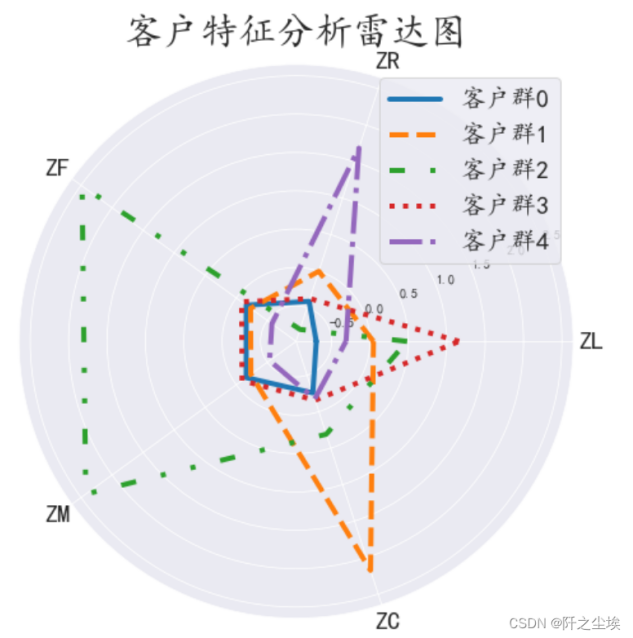
实际应用:针对不同聚类的客户,公司制定了不同的营销策略。通过这种精准营销,公司提高了客户满意度和销售额。
方法五:时间序列预测——预见未来趋势ARIMA 模型(自回归积分滑动平均模型):是一种广泛应用的时间序列预测模型。它由自回归(AR)部分、差分(I)部分和滑动平均(MA)部分组成。
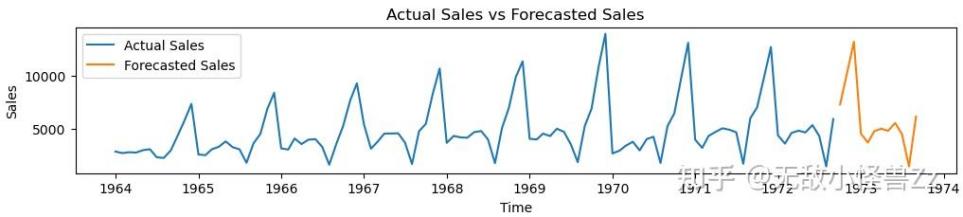
案例分析:下图是某公司营业额的数据
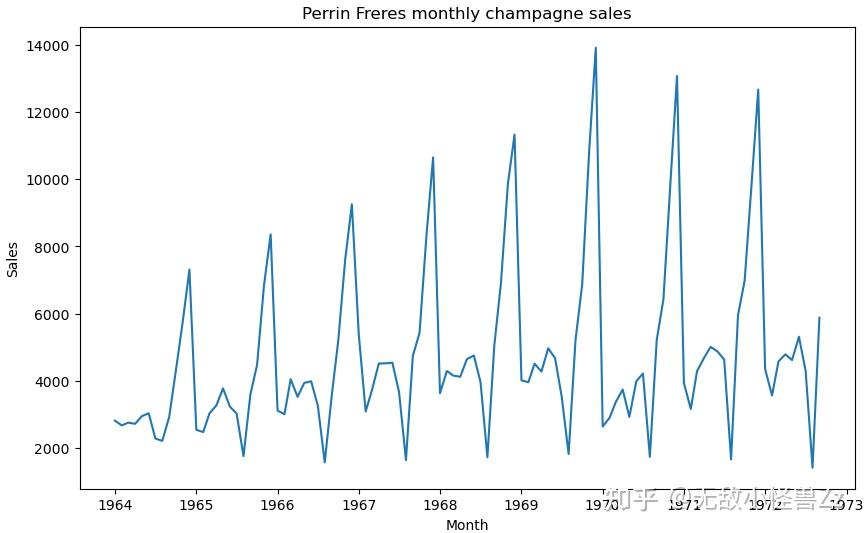
使用SARIMA模型进行预测,黄色部分就是预测的未来一年(12)个月的值:
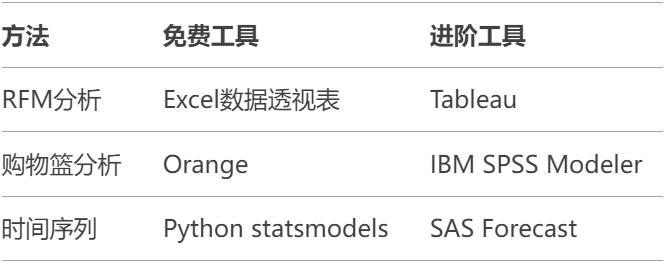
最后附上为大家整理的工具推荐清单:
您想要深度解锁掌握这些好用的数据分析方法吗?为大家推荐探潜数据分析,这是一个很强大的数据分析的学习平台,内容丰富讲解细致,欢迎大家一起分享经验,交流学习!
图片来源于网络,如有侵权请私信删除。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









