







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
这类work最近送审的越来越多了 有的存在根本性错误 证明性的实验性的都有 比如测试集搞成训练集了 比如魔改了常规定义或者performance measure 比如baseline选了过时的过弱的 有的实验机理描述不清甚至前后矛盾 读完无法理解他做了什么 一般我会给个borderline reject提问题 如果能解答我的疑惑 再调分上去 如果让我更加疑惑那就对不起了 strong reject也是有的
当然也有跟文章本身无关的极端情况 比如一稿多投 抄袭等学术不端 那不管文章质量多好都必须拒掉 这里就比较考验搜商了 记得拿到稿子都回去各个数据库比一下
年轻人审稿的时候,往往喜欢挑语法和文章结构错误来向编辑显示自己审的非常细心,尤其是如果作者是来自于母语非英语的国家,加上一句『最好有一个native speaker 来proof-reading会有帮助』几乎是万金油。
但是一般来说,这些并不影响拒稿和修改的决定。
影响比较大的主要是两点,一是贡献,二是执行。
好的文章一般主要看贡献。因为单纯的一个模型推导,或者单纯的跑回归是没什么意义的,本质上是做了一个练习。只有这个练习有了重要的经济学含义,比如解决了文献源流发展中出现的什么问题,揭示了一个什么之前没有的机制,给什么理论提供了新的实证证据…… 之后,这个练习才值得被发表出来。当学生的时候往往喜欢沉迷于方法——用了一个高级的数学工具建模,用了一个先进的纠正偏误方法等等,但是其实这些是锦上添花的,并不是贡献。
把自己的贡献写清楚,可以说是能通过审稿过程的最重要一环。
经济学的期刊对方法论的要求一向比较严格,不差的经济学期刊,可能执行的有好坏,但是基本的底线还是有保证的。
有一些稿件就需要既看贡献,又看执行了。执行没有根本错误,一般都还可以提出意见让对方改,有根本错误的就算了。根本错误就是:你拿这个东西当作文章卖点,然而这个卖点本身不合理甚至于不存在。
比如说,理论模型洋洋洒洒写了三十来页,一堆花符号证明,最后得出一个特别让人惊讶的结果,如果只看贡献,会觉得贡献挺好的。但是如果仔细看模型,里面有一个根本的问题,就是里面的消费者都是韭菜,很多个企业竞争,消费者总是会选一个,而正常来说是要有一个隐含条件的,就是「消费者总是选一个」前提是买总比不买好——不能获得负效用,显然这个条件就被有意无意的忽略了。这种圈起来割韭菜的想法很有意思,但是这么根本的错误,是会推翻其所有的结论的。这种就毫不犹豫的给拒掉。
这是一个好问题。我也算是“萌新审稿人”,从2020年开始成为期刊审稿人,截止到两年后的今天,独立审过十多篇论文,也帮老师审过几篇论文,不算多。
我独立审的论文大部分来自国内心理学顶刊《心理学报》,2020年、2021年分别都审过4篇学报的稿子。曾经有人问:你自己都没发过一篇《心理学报》,为什么能当这个期刊的审稿人?这其实是个误区。审稿人并不一定要在审的期刊上发过文章,你看《Science》《Nature》的审稿人也未必都亲自发过《Science》《Nature》正刊吧?同理,如果被一些普通刊物邀请成为审稿人,也不必先亲自在上面发篇文章才能审稿。所以,「审稿」和「发文章」并不存在必然联系。
但是,「审稿」和「写文章」的关系还挺大:通过审别人的稿,我们就能感受到,什么样的文章是好文章,什么样的文章会被拒稿(正如这个问题所关心的)。如此,我们就能在写自己文章的时候注意规避一些“雷区”,并且追求向“好文章”的标准靠拢。
因此,这是一个好问题,不仅可以促进审稿人相互学习,而且可以帮助作者提升论文质量。
言归正传——审稿人一般在什么情况下会倾向于拒稿?
回顾我这两年审过的稿件,大概可以归纳出4个主要的评判维度:
- 写作规范性
- 问题重要性
- 方法严谨性
- 结果创新性
接下来,我想结合心理学/社会科学领域,分别谈谈这4个维度。
1. 写作规范性
我是一个非常critical的人,因此也是一个非常critical的审稿人——对自己严苛,对别人也严苛。
学术文章,抛开“学术”,首先应是一篇合格的“文章”。即使是初稿,也尽可能接近理想的状态,而不是等审稿人给你揪出一堆基础问题。
很多人说只有“萌新审稿人”才会揪着格式、语病、错别字、标点符号等细节不放。这一点本身倒是不错,我刚开始审稿的时候也会过于关注细节,但是,这并不意味着“成熟审稿人”会对这些细节视而不见,也不意味着“投稿人”能够放任自己的初稿充斥大量语病、错别字和标点符号误用。
心理学界泰斗林崇德先生,在接受采访的时候曾经提起过他大学期间的一段往事:“我爱写东西,我写了一篇论文给他(朱智贤教授),里边有错别字,他就说,‘我上大学的时候已经出版著作了,你已经是大学二年级的学生了,你怎么还要写错别字给我?’”
 https://www.bilibili.com/video/BV1yF411h7gA
https://www.bilibili.com/video/BV1yF411h7gA
所以,写作规范性,哪里只是“萌新审稿人”才会关注的?即使是学术泰斗级人物,朱智贤、林崇德教授,依然会严格要求自己不写错别字!老一辈科学家身上的很多优良品质,不能到我们这一代就断掉了。“文章千古事”,不犯语病、不写错别字、用对标点符号,是一篇文章最基本的要求。
现在有没有区分「的」「地」「得」的必要?- 包寒吴霜的回答148 赞同 · 1 评论回答
当然,这些基础细节,也不是审稿人做出“拒稿”决策的最关键因素,只是补充性因素。审稿人(包括我)虽然会关注到一些明显的语病、错别字,但不会因此直接不分青红皂白地否定一篇文章的贡献——只不过,审稿人心中可能会形成一个初步印象,比如觉得作者不够仔细、态度不够端正,进而质疑研究是不是也做得不够严谨、结论是不是也不够可靠。
从这一点来说,写作不规范,仍然会通过“写作态度感知”的中介作用,间接增加审稿人“拒稿”的倾向。尽管审稿人允许稿件存在少量错别字,但每多看到一处错别字,就会在心中多扣一分,等“愤怒值”积攒到一定程度,很可能就会直接形成“拒稿”的总体倾向。一旦这种倾向形成,想要说服审稿人手下留情给你“大修”的机会可就难了,除非论文的贡献非常非常大、方法非常非常严谨、结果非常非常可靠,才有可能逃过一劫。实际上,这种可能性很小,如果一篇文章充斥着错别字,那这篇文章的严谨可靠性一般也高不到哪里去。写作规范性还是可以折射其他很多方面的。
除了文字方面的规范,像心理学学术论文还需要具备APA论文写作规范,比如参考文献列表、文内引用格式、结果报告规范等。
不妨举几个常见的不规范情况吧,下面这些情况,至少对我来说,都是审稿中的“扣分项”(不一定会直接拒稿,但一定会让我质疑作者的写作素养和学术训练程度)。
- 误用或不区分“的、地、得”(详见我的知乎回答:现在有没有区分「的」「地」「得」的必要?)。
- 参考文献格式混乱(比如文献标题或期刊名没有正确大小写、只有卷号没有页码),实际上很多文献管理软件自动导出的参考文献格式都存在问题,不一定完全符合APA规范,我一般写文章都是自己手动确认一遍参考文献格式,而不是相信文献管理软件。
- 统计显著性p值错误写成“p = .000”甚至“p < .000”(p值不可能为0或小于0,请不要直接照抄SPSS软件的输出结果,极小的p值应写成“p < .001”,而大于.001的p值一般应报告精确值并保留3位小数)(感兴趣的读者还可以看我的这篇知乎回答,里面有一个乱写p值和统计结果但仍然发表出来的真实例子:partial η2怎么计算?)。
- 统计图表乱七八糟,比如下面这张图,取自一篇2009年发表于《Science》正刊的文章,堪称顶刊中的“反面教材”,因为误差线(error bar)完全是在乱画(尤其是最后一根柱子,误差线都能把均值给踢到外面?!)。
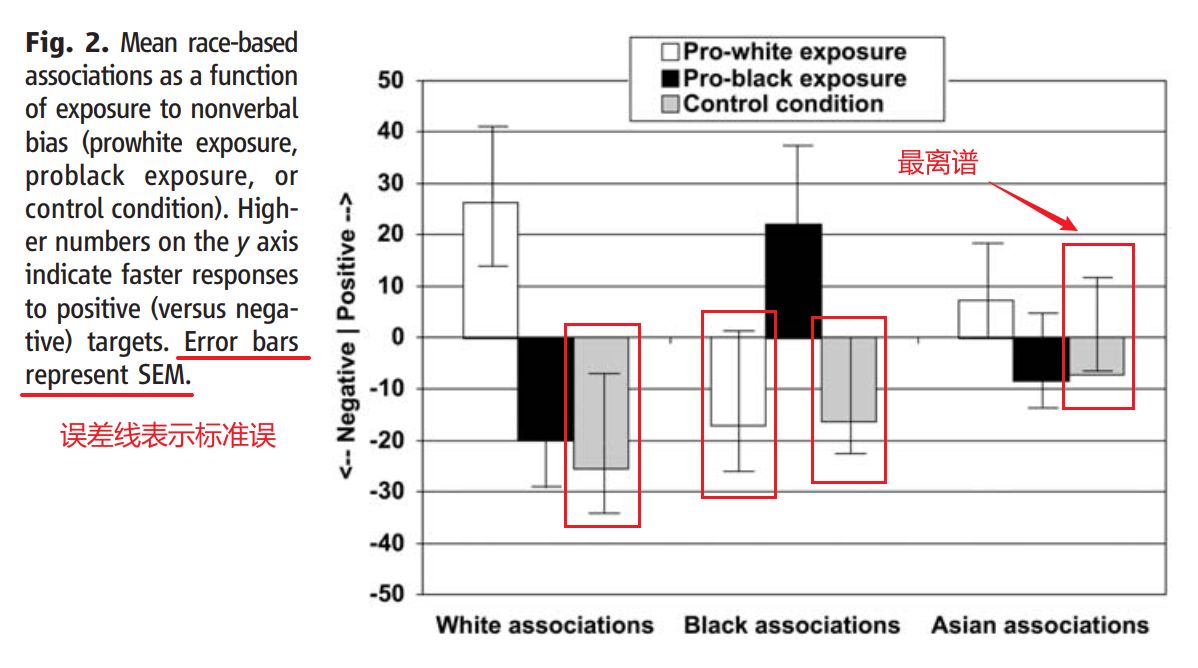 https://doi.org/10.1126/science.1178358
https://doi.org/10.1126/science.1178358
参考文献(反面教材):Weisbuch, M., Pauker, K., & Ambady, N. (2009). The subtle transmission of race bias via televised nonverbal behavior. Science, 326(5960), 1711–1714. https://doi.org/10.1126/science.1178358
2. 问题重要性
很多审稿人(包括我)写审稿意见,都会写“Major”(主要意见)和“Minor”(次要意见)。上面说的写作规范性,虽然很重要,但大部分情况下都属于次要意见,不一定直接导致拒稿。
况且,一篇学术论文真正的“生杀大权”其实是在责任编辑(Action Editor, AE)手里的,审稿人只是为AE提供一些参考,至于拒不拒稿,还得看AE喜不喜欢这篇文章、认不认同审稿人的意见。
而影响拒稿的主要因素,在于接下来所讲的三点:问题重要性、方法严谨性、结果创新性。
像《心理学报》这样的高质量期刊,就更是看重研究问题的价值和重要性,尤其是问题的理论价值、理论贡献、新颖性、时效性。
举一个新手研究者经常走入的误区。不少研究者(尤其是本科生、研究生)会认为自己研究的重要性在于**“别人没做过”“填补了研究空白”“在中国文化背景下探讨了以往研究的某个效应”“在某个特殊群体中验证了以往研究的某个发现”——这些其实都不是**真正的创新贡献或研究意义。
- 别人没做过,你做了?——这与研究意义没有太大关系,世界上还有成千上万没被研究过的问题,凭什么别人没做过而你做的就一定是有意义的?另外,现在我们讲“Open Science”,讲“可重复性”,重复研究(replication)也是有意义的,尤其对于一些尚存争议的效应和发现。
- 填补了研究空白?——这也是句空话、套话,任何一项研究都可以填补以往研究的空白,而你填的这个空白就一定有必要去填吗?不填是不是也可以?
- 中国文化下的探讨、特殊群体中的验证?——这些同样不属于真正的创新,更多是对某个效应的跨文化普遍性、跨样本可重复性的检验。凭什么在中国文化背景下才能研究这个问题?如果作者真的认为这一点很重要,那么需要充分论证在中国背景下研究这个问题有哪些必要性、优势、独特的理论贡献。
3. 方法严谨性
问题重要性,决定了一篇论文目标期刊的层次;而方法严谨性,则是任何层次的期刊都有的要求。
在心理学领域,常见的量化研究方法不外乎问卷调查和行为实验。关于这两者的优劣,存在两种不同的声音:一种声音认为,纯问卷调查就是不靠谱的,只有随机分配被试的实验才有发表的价值,因为只有实验可以解决因果关系;另一种声音认为,调查和实验不应该存在“鄙视链”,问卷调查+简单统计,仍然可以发很好的刊物。
我对上面的两种观点都不完全赞同。我认为数据质量和方法恰当才是最重要的两个因素。
无论是可以回答因果关系的实验,还是只能回答相关关系的调查,都有它们各自适用的研究问题。比如评估临床干预的效果,显然需要随机分配被试才能知道干预是否有效,而不是安慰剂效应;但如果研究人格特质对心理/行为的影响,显然我们很难随机操纵个体的人格变量,只能去观察测量。
然而,这些并不意味着“实验一定更优”或“调查一定也行”:如果一个实验没有很好地控制关键的混淆因素,或者一个调查只是方便取样而没有考虑样本的随机性和代表性,那么数据质量都是大打折扣的,这与研究者选用哪种方法论无关。而且,虽然现在鼓励开展所谓的“大数据”研究,但并不是“样本量大”就是“大数据”了,也不能简单认为“只要样本量大,研究就一定很有价值”——道理是一样的,如果数据质量不高,那么再大的样本量都是“Garbage In, Garbage Out”。
其次,有了数据质量的保证,**选用合适的统计方法(用对方法,而不是用酷炫的方法)**也很重要。这就不再详细展开,因为关于统计方法,可以讲的内容实在太多了。
4. 结果创新性
最后,我想简单谈谈我对结果创新性的看法。
我审稿的时候,其实不会太看重结果是不是“反直觉”,因为我觉得一个真正合理、可信的结果,一定是基于靠谱的理论、严谨的方法,并且能让人“眼前一亮”,而不在于这个结果是不是“与常识相反”。所谓的“反直觉”,看上去是一种创新,但也是一种悖论——难道我们的直觉永远都是错的?难道与常识不符的结果才是有价值的?不同意。有不少一开始反直觉的发现,后来经过重复检验,都被发现是不靠谱的、不稳定的、不可重复的,比如大名鼎鼎的“自我损耗效应”。
结果创新性,我认为应该体现在至少三个方面。
- **是不是提升了我们对一个现象的认识?**比如之前对此认识模糊,而你的研究结果让我们的认识更加清晰、准确、深入了。
- **是不是完善了某个已有理论甚至形成了某个新的理论?**比如2014年《Science》发表的“水稻理论”,虽然争议很多,但不可不说是一个实质性的理论创新。
- **是不是有可能改变我们的生产生活乃至改造我们的世界?**这个要求其实非常高,属于锦上添花,如果满足不了肯定不会被拒稿,但是如果满足,那一定是顶刊级别。
以上。
phd已毕业的路过,我一般不会扣细节,格式图表语法这些都是小问题,找起来费时间又不是判断工作质量的主要依据,在审稿意见里通常也只能作为minor comments。期刊虽然没明确细分打分方向,但审过会议论文就知道,一篇文章是从broader impact、novelty、technical soundness、presentation等方面综合考虑的,reviewer也应该对着这几项分别给comments。格式图表语法再多问题,都只属于presentation这一个部分,而且属于最好在审稿过程中改进的一类的。何况作为non native speaker,我不会因为单纯语言问题拒稿,因为我自己的稿子如果没有native speaker合作者改肯定也会有一堆语言问题;我不会因为ppt画图拒稿,因为我自己有十几个图都是ppt画的文章被TIT接收(我也用过tikz画图但是觉得太浪费时间了,甚至没有任何reviewer说你的图不够美观之类的),且我也读过古早的大牛的文章里的图是手画的那种,说明这些压根不是主要问题。
而且根据我个人收到杂志的审稿意见的经验,越是senior researcher或者领域大佬,其实越懂得把握全局评论也越是从欣赏的角度来,给的comments越constructive和谨慎;越是菜的reviewer越是吹毛求疵酸言酸语。因此你经常可以得到那种洋洋洒洒20+条修改意见,但同时毫不吝啬地夸你的工作novel and worthwhile的审稿意见;同时遇到那种声称只看了你的introduction就觉得不符合期待、没看proof但觉得就是不可能得到这个结果、然后又暗戳戳叫你cite她的phd thesis的那种审稿人。我就遇到过ap都当了好几年,从phd到当上野鸡学校的ap期间都只有一篇一作TCOM的领域nobody,强行说她的phd thesis里的某个未发表theorem是relevant work,要我cite她的phd thesis到我的TIT paper里,同时还酸溜溜地说自己只读了introduction但觉得novelty不符合期待(在其他两个reviewer都说我们的工作novel/explores an interesting avenue/technically sound and worthwhile的情况下)…着实令人无语…师兄表示很震惊她怎么会在自己的所有文章都是incremental improvement的情况下厚脸皮说我们的文章不够novel(师兄得过3个paper award)…
个人比较关心的是motivation够不够合理——这一点是判断你研究的问题重不重要,你解决的问题是不重要没有impact别人压根都懒得去研究,还是解决了一个前人关心但解决不了的问题,这一点大概决定了你的文章上限适合哪个档次的期刊。另外,这一点也不该和领域应用火还是不火挂钩,而是在小领域内与前人工作对比够不够自洽,毕竟有很多靠大佬话语权强行扯应用火了3-5年就死了的小方向,背靠这种大树并不意味着真正的broad impact,推崇这种不务实的应用只会坑一代又一代的缺乏资源平台的新手。
其次,contribution有没有说清楚——这一点是很重要的,审过一些文章,乍一看摆了许多公式许多定理,提了很多其他工作,但自己的工作相对于前人工作的改进和主要卖点在哪里,压根没提,还得审稿人反复去对比寻找。如果核心contribution不能在abstract里说明白的话,很多情况下是因为contribution是incremental的。
至于technical soundness,我觉得不应该从公式有多长、工具初等还是高等这种方面来判断,而是根据从已有的工作到这篇文章的gap有多大、多难,结合文章的核心卖点来判断,而且techinical soundness并不与novelty直接挂钩。比如说一篇用到了很高等的工具卖点也是数学技巧,但其实主要技巧难点都是别人的工作,自己只是改了一点点条件,核心证明思路都差不多的文章,对比一个核心思路看上去简单初等但是别人就是没有想到的文章,那我会判定二者都是technically sound但前者novelty不足。而如果这种方法迁移的卖点就是应用且投到了应用杂志上,之前没有其他人把这个理论用个到这个应用里,那也是techinically sound且novel的。
另外,如果自己做过数学证明就知道,很多情况下冗长的证明其实是obvious中规中矩就能顺下来的或者只是想复杂了:我审paper的时候也见过作者扯了一大堆代数用了半页证明一个定理但实际上三行就能证完的情况。如果卖点是数学技巧,那么有经验的审稿人会要求你用简短的几句话总结你的主要idea,说明你的数学技巧为什么work,而前人的方法为什么不能work,如果这一点不能说清楚,其实很可能是单纯的machinery的方法,或者别人懒得去做的obvious extension。当然这种情况的工作也是可以发表的,做框架性的挖坑工作的作者其实很多情况下会有意留下来这种很显然的extension的方向攒citation吸引follow up work,自己把什么都做完了一个方向死了也没什么意义,还费时费力;只是发顶刊就差强人意一点,通常审稿人应该推荐提交给会议或者less selective的期刊。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
wSpcv-1715644258675)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 2592
2592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









