









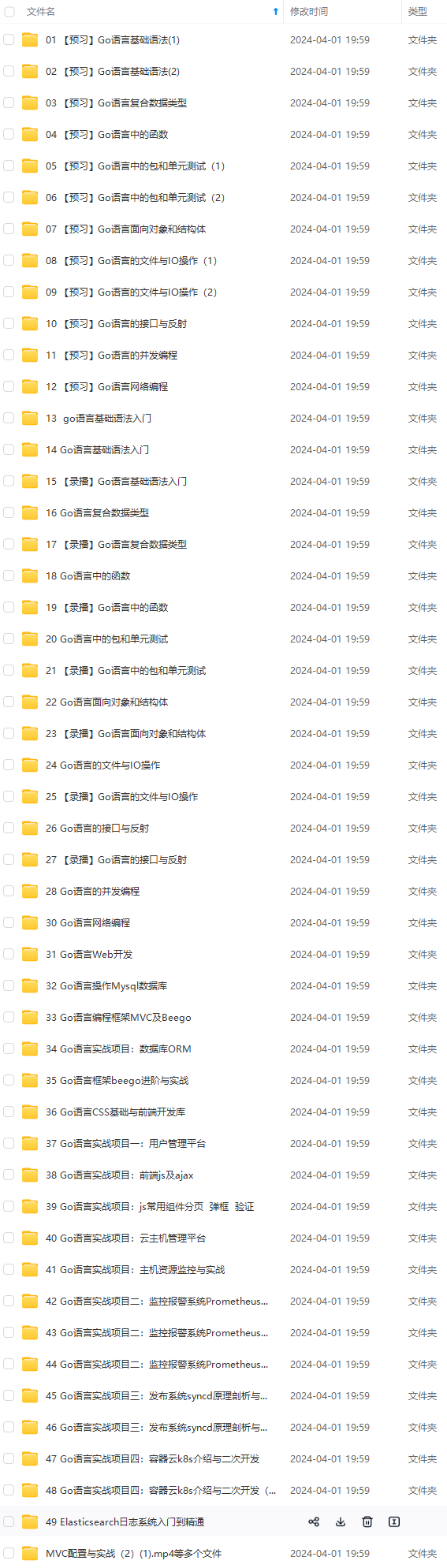
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
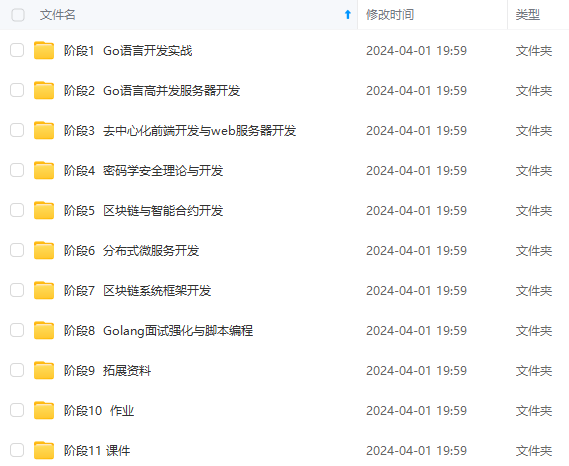
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
ApacheCN cwiki 地址为 scikit-learn 0.18 中文文档 : http://cwiki.apachecn.org/pages/viewpage.action?pageId=10030181
sklearn : 基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上。
此外,Apache Spark 2.2.0 官方文档中文版,开始采用 github 迭代维护的方式来更新,欢迎大家一起来迭代维护,地址为 https://github.com/apachecn/spark-doc-zh。
以下是 sklearn 官方文档中文版,如果你也有兴趣,欢迎来一起来维护迭代。
- 快速入门
- 用户指南
- 监督学习
- Generalized Linear Models ( 广义线性模型 )
- Linear and Quadratic Discriminant Analysis ( 线性和二次判别分析 )
- Kernel ridge regression ( 内核岭回归 )
- Support Vector Machines(支持向量机, SVM)
- Stochastic Gradient Descent ( 随机梯度下降 )
- Nearest Neighbors ( 最近邻 )
- Gaussian Processes(高斯过程)
- Cross decomposition(交叉分解)
- Naive Bayes ( 朴素贝叶斯 )
- Decision Trees(决策树)
- Ensemble methods(集成方法)
- 多类和多标签算法
- 功能选择
- 半监督
- 等式回归
- 概率校准
- 神经网络模型(监督)
- 无监督学习
- 模型选择和评估
- 数据集转换
- 数据集加载实用程序
- 计算策略:更大的数据
- 计算性能
- 监督学习
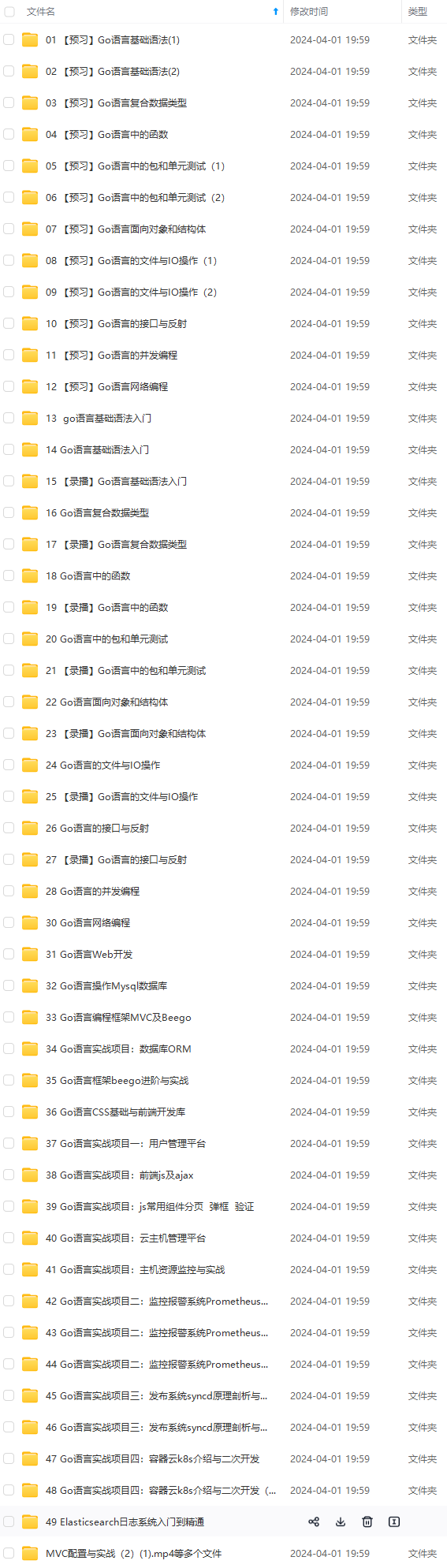
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
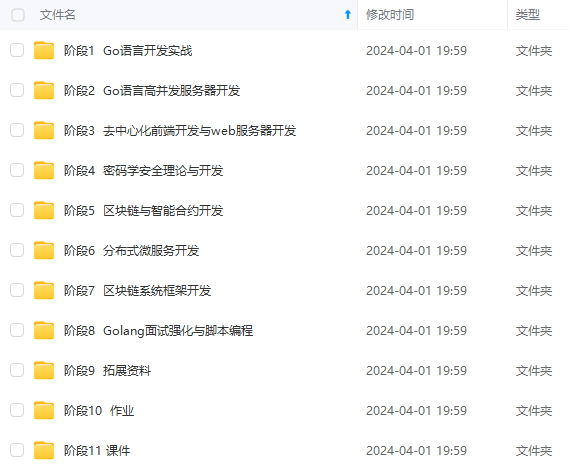
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 842
842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









