







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
具体可以阅读博主文章:❤️🔥【神秘海域】[动图] 顺序表千字破解~
顺序表存在两个非常不方便的缺点,所以 链表 诞生了
链表的优缺点
谈论链表的优缺点如果谈论
单链表,那链表的优势就不能完全展露出来,所以 以带头双向循环链表来对链表优缺点进行分析
与 顺序表 不同的是,使用 链表 结构在内存中的存储数据,对内存的使用一般是 不连续的,因为它的不连续所以:
- 在链表中任意位置对数据 插入或者删除 ,都可以 以
[O(N)]的时间复杂度完成,效率高(优点) - 不需要扩容,存放数据 即申请即存,删除数据直接释放,
按需申请和释放(优点) 不能随机访问数据,只能按顺序从某节点处开始 查找访问
不能随机访问数据,导致链表不适用一些算法:二分法、随机访问的排序等(缺点)
具体可以阅读博主文章:
❤️🔥【神秘海域】[动图] 掌握 单链表 只需要这篇文章~ 「超详细」
顺序表及链表对比
| 顺序表 | 链表 | |
|---|---|---|
| 空间占用 | 连续的物理空间 | 一般 不连续的物理空间 |
| 访问方式 | 可随机访问😁 | 只能顺序访问🙁 |
| 存储方式 | 顺序存储,空间不够需要扩容🙁 | 顺序存储,按需申请和释放 无需扩容😁 |
| 插入删除 | 中间插入需挪动数据,效率低🙁 | 任意位置插入时间复杂度均为 O(1) 效率高😁 |
| 高速缓存 命中率 | 高😁 | 低(可能存在其他问题) 🙁 |
通过对比可以很明显的看出,其实 顺序表 和 链表 是互补的存在,是相辅相成的
不过,这里提到了一个名词 高速缓存命中率
下面简单介绍一下,什么是 高速缓存命中率
高速缓存命中率
在 介绍 高速缓存命中率 之前,先介绍一下 什么是 高速缓存
高速缓存
众所周知,CPU 读取数据是从 内存中读取的,但是 CPU 读取数据的速度 远远远远大于 内存传输数据的速度
所以为了中和 两者之间的差距,在 CPU 和 内存 之间添加了 数据传输速度介于 CPU 和 内存 之间的 存储器寄存器 和 高速缓存
所以目前通用计算机的存储器结构 大致 的示意图如下:
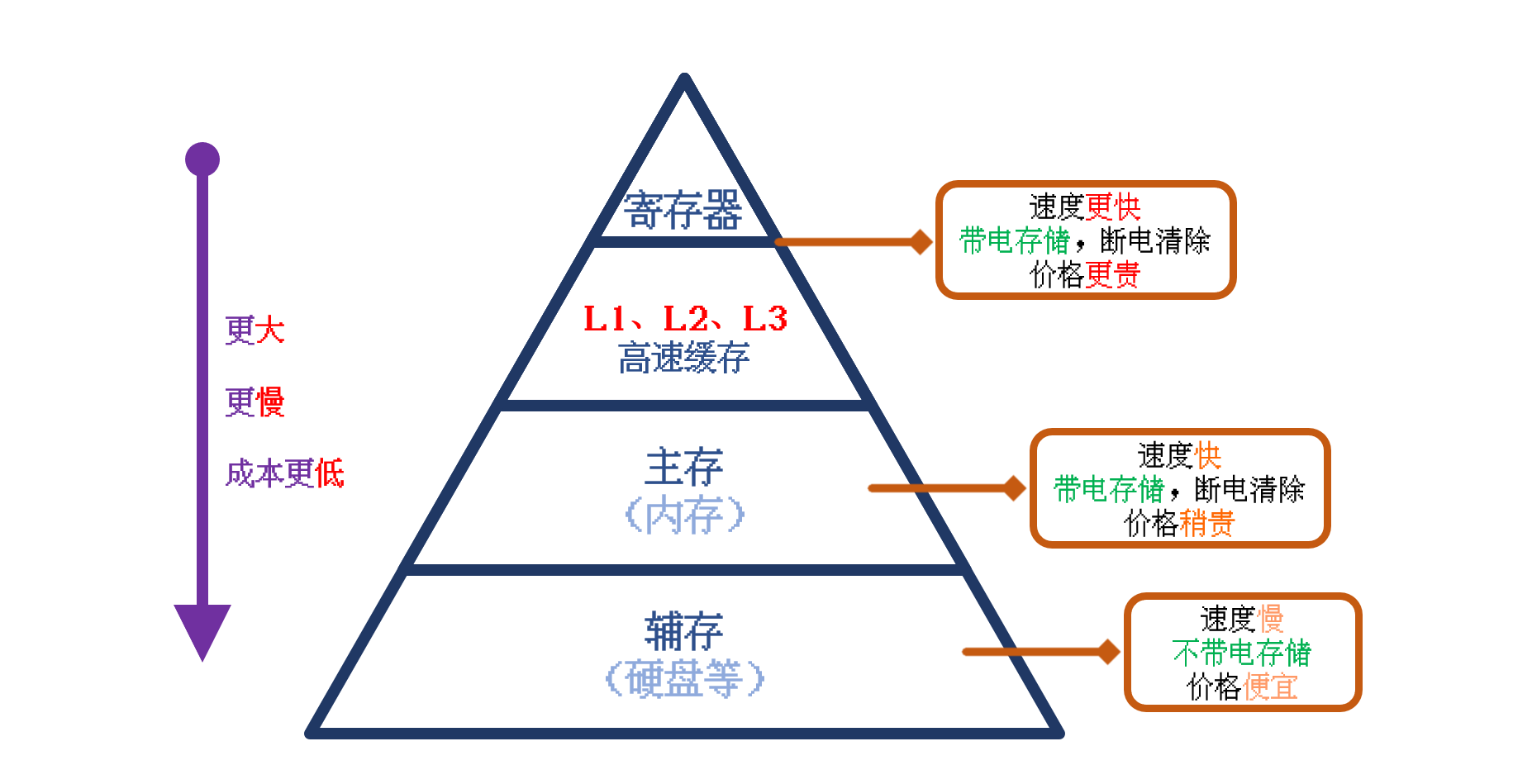
高速缓存 的数据传输速度 一般比 内存 快 5~10 倍,是为了中和 CPU 读取速度 与 内存 传输速度差距过大而被添加的
有了 高速缓存 之后,CPU 读取数据 就会优先从 高速缓存 中读取,所以,内存中比较常用的数据 一般 会被存储到 高速缓存 中
高速缓存命中率
既然,CPU 会优先从 高速缓存 中读取数据,而 高速缓存 中并 不能存储内存中的所有数据 ,那么就一定会存在:
CPU从高速缓存中找不到需要的数据,被称为高速缓存不命中CPU从高速缓存中能找到需要的数据,被称为高速缓存命中
CPU 从 高速缓存 中 能找到需要数据的次数 与 CPU 从 高速缓存 中 找数据的总次数 的比 就被称为 高速缓存命中率(简称缓存命中率)
那么 为什么 用 顺序表 存储数据 缓存命中率 比 用 链表 存储数据 缓存命中率 高呢?
顺序表及链表的缓存命中率分析
顺序表 和 链表 的逻辑结构都是线性的
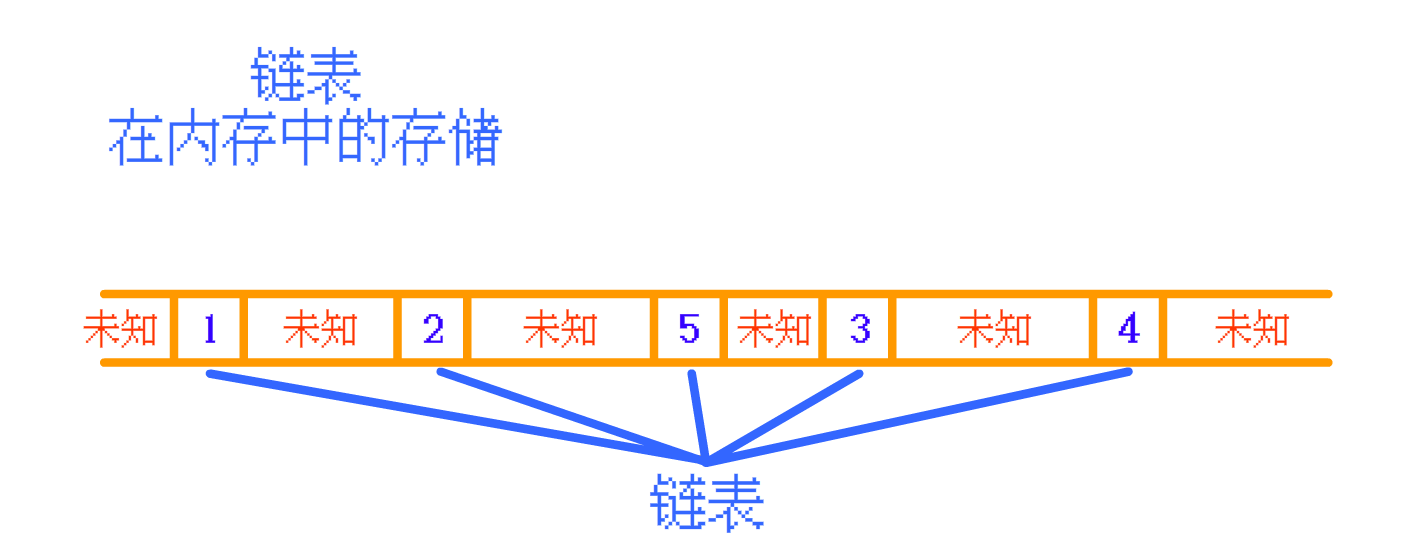
但是在实际的内存空间中,顺序表 是连续存放的,而 链表 一般并不是连续存放的
那么,使用顺序表 和 链表 存储数据,在内存中大致的的存储情况应该是这样的:
顺序表:

链表:
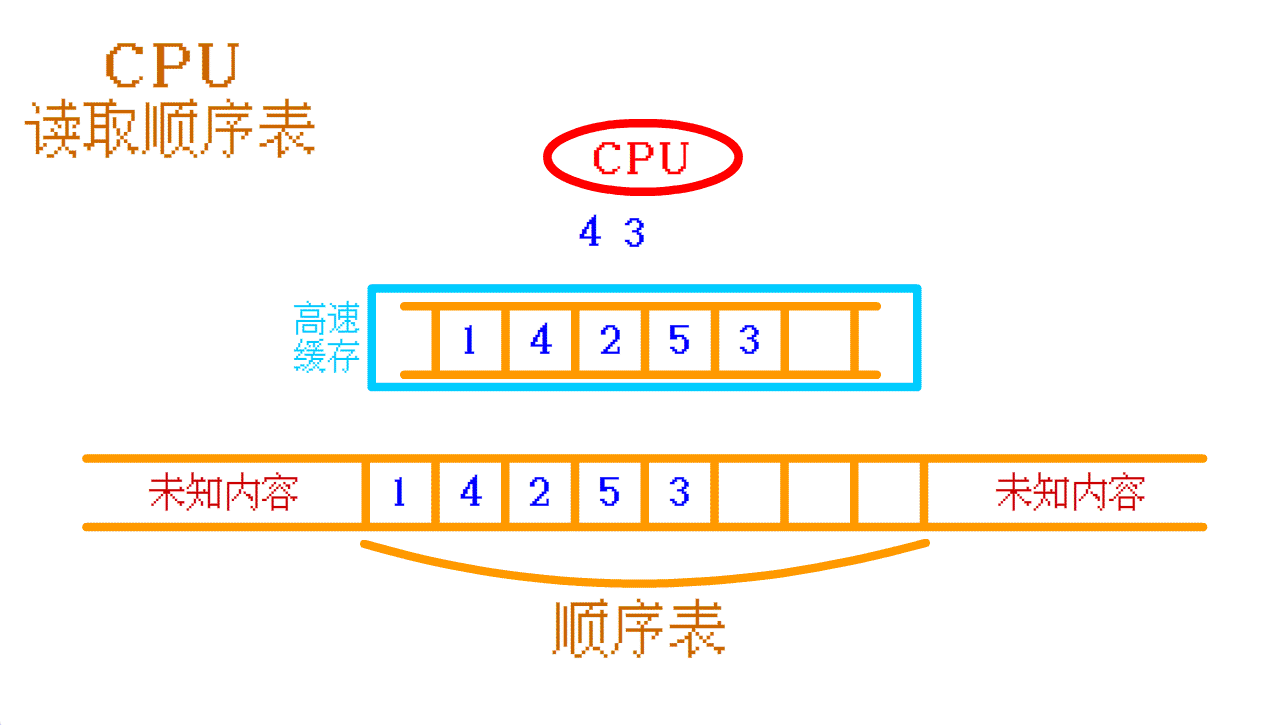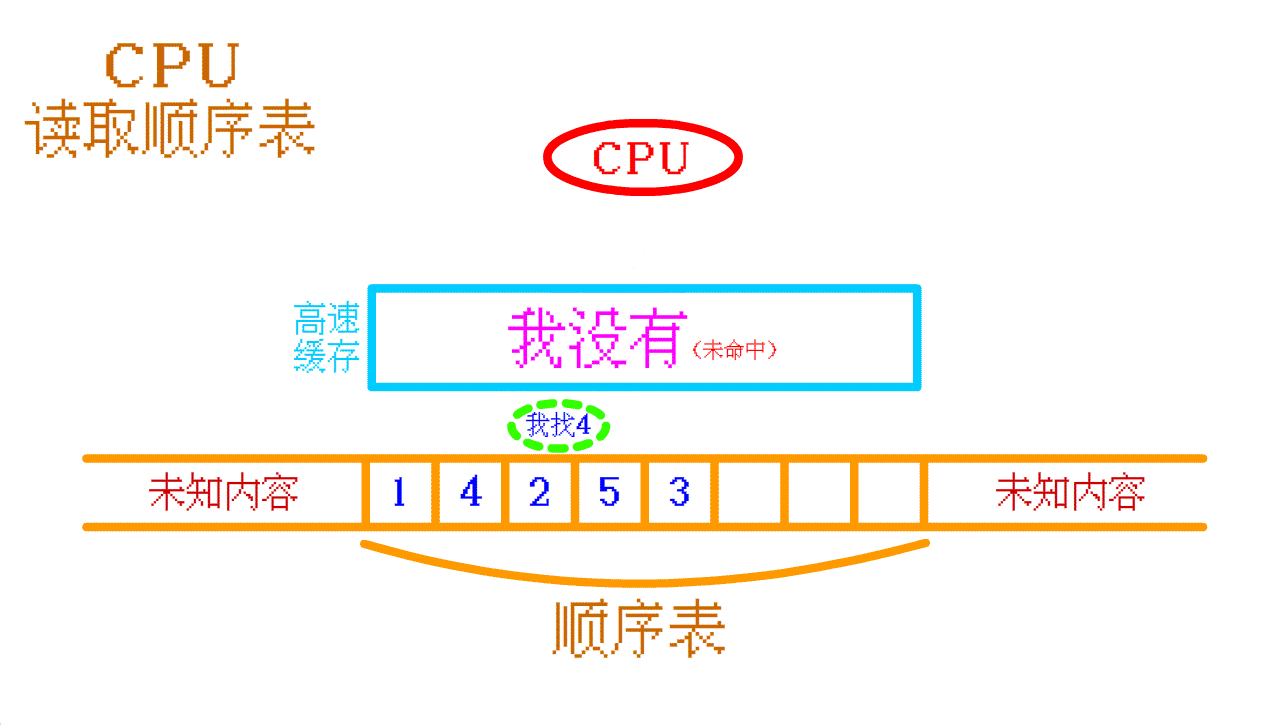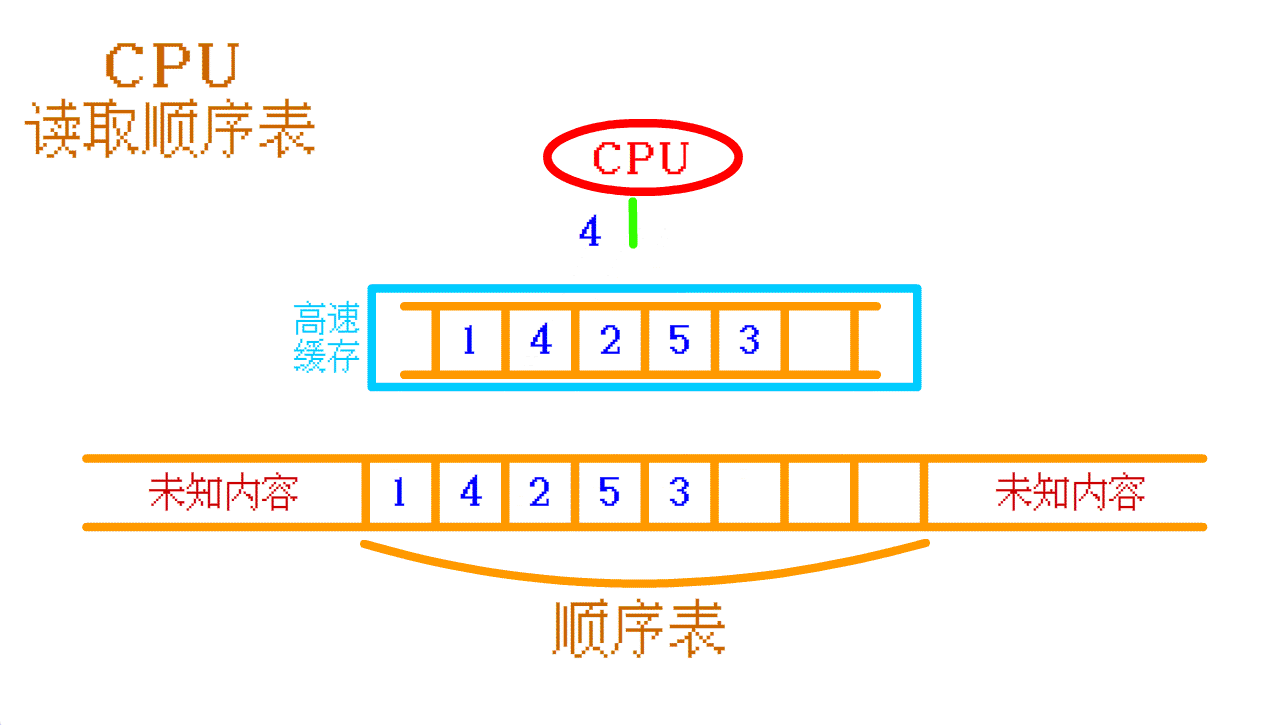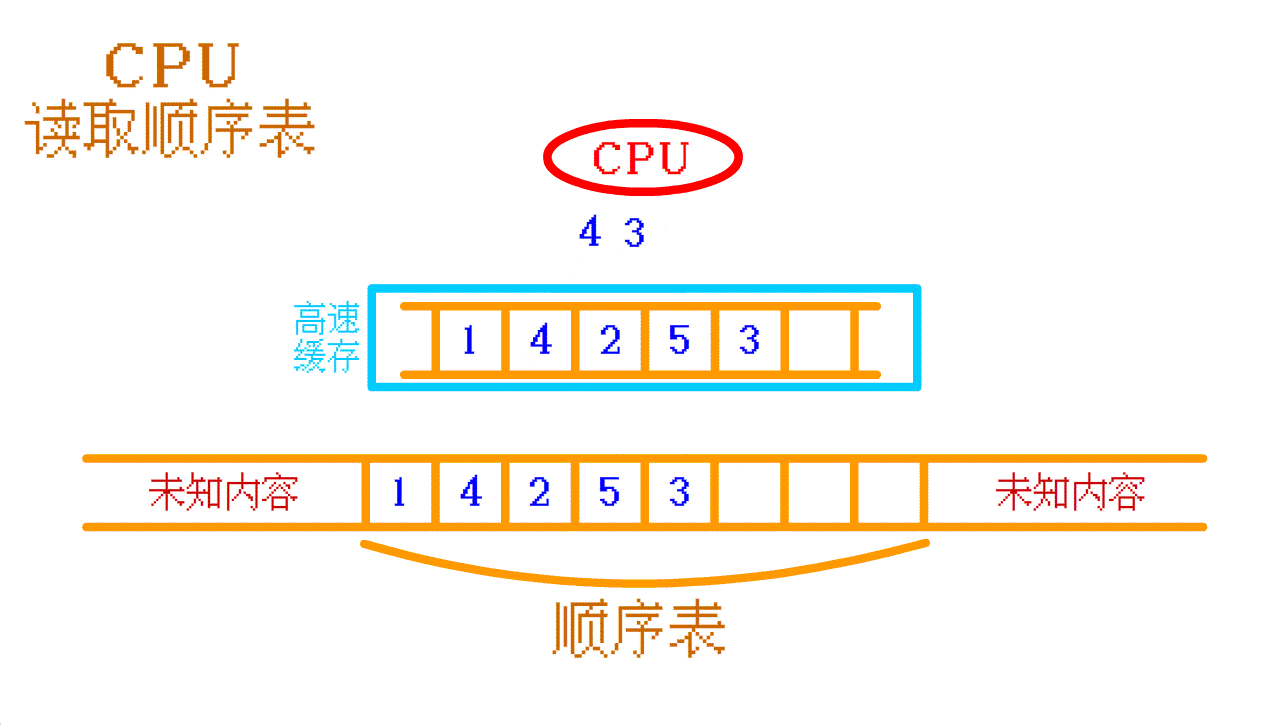
假设,这两个结构的数据都 没有被存入高速缓存 中,当 CPU 需要读取数据的时候
CPU读取数据,如果没有在高速缓存中读取到,就会去内存中寻找,然后再将寻找到的数据及其周围的数据存入高速缓存中以提高缓存命中率
对于 顺序表 :
如果需要读取 顺序表中的 4 ,高速缓存中没有,那么 CPU 就会再往 内存中 找,找到之后会将 顺序表中的 4 及其周围的一部分数据 一起存入 高速缓存 中。如果 CPU 需要再次访问 顺序表 中其他的数据时,CPU 大概率可以直接从 高速缓存 中找到相应的数据。
如此,顺序表 的 高速缓存命中率 就 高。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









