







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上物联网嵌入式知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、电子书籍、讲解视频,并且后续会持续更新
import requests
这个时候,requests会报红线,这时候,我们将光标对准requests,按快捷键:alt + enter,pycharm会给出解决之道,这时候,选择install package requests,pycharm就会自动为我们安装了,我们只需要稍等片刻,这个库就安装好了。lxml的安装方式同理.
将这两个库安装完毕后,编译器就不会报红线了
接下来进入快乐的爬虫时间

获取网页源代码
之前我就说过,requests可以很方便的让我们得到网页的源代码
网页就拿我的博客地址举例好了:https://blog.csdn.net/it_xf?viewmode=contents
获取源码:
# 获取源码
html = requests.get("https://blog.csdn.net/it\_xf?viewmode=contents")
# 打印源码
print html.text
代码就是这么简单,这个html.text便是这个URL的源码
获取指定数据
现在我们已经得到网页源码了,这时就需要用到lxml来来筛选出我们所需要的信息
这里我就以得到我博客列表为例
首先我们需要分析一下源码,我这里使用的是chrome浏览器,所以右键检查,便是这样一份画面:
然后在源代码中,定位找到第一篇
像这样?
操作太快看不清是不是?
我这里解释一下,首先点击源码页右上角的箭头,然后在网页内容中选中文章标题,这个时候,源码会定位到标题这里,
这时候选中源码的标题元素,右键复制如图:
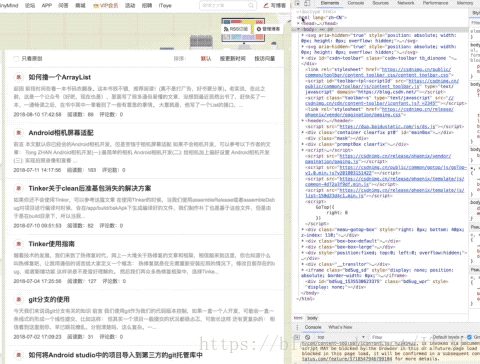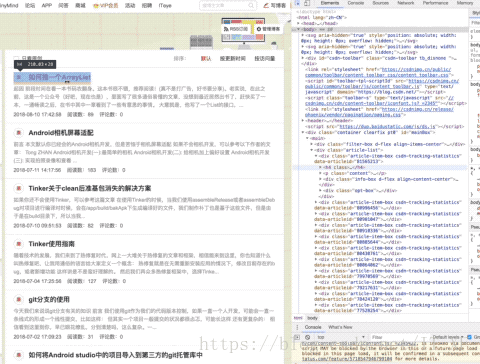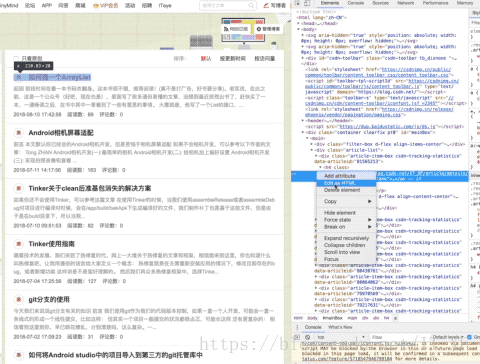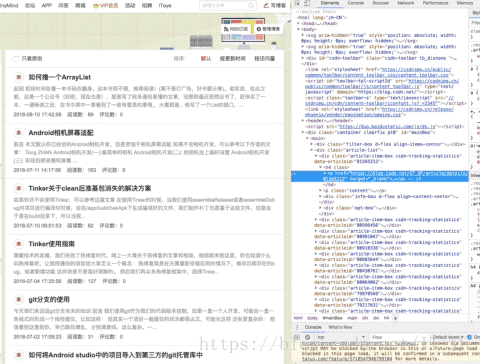
得到xpath,嘿嘿,知道这是什么吗,这个东西相当于地址。比如网页某长图片在源码中的位置,我们不是复制了吗,粘贴出来看看长啥样
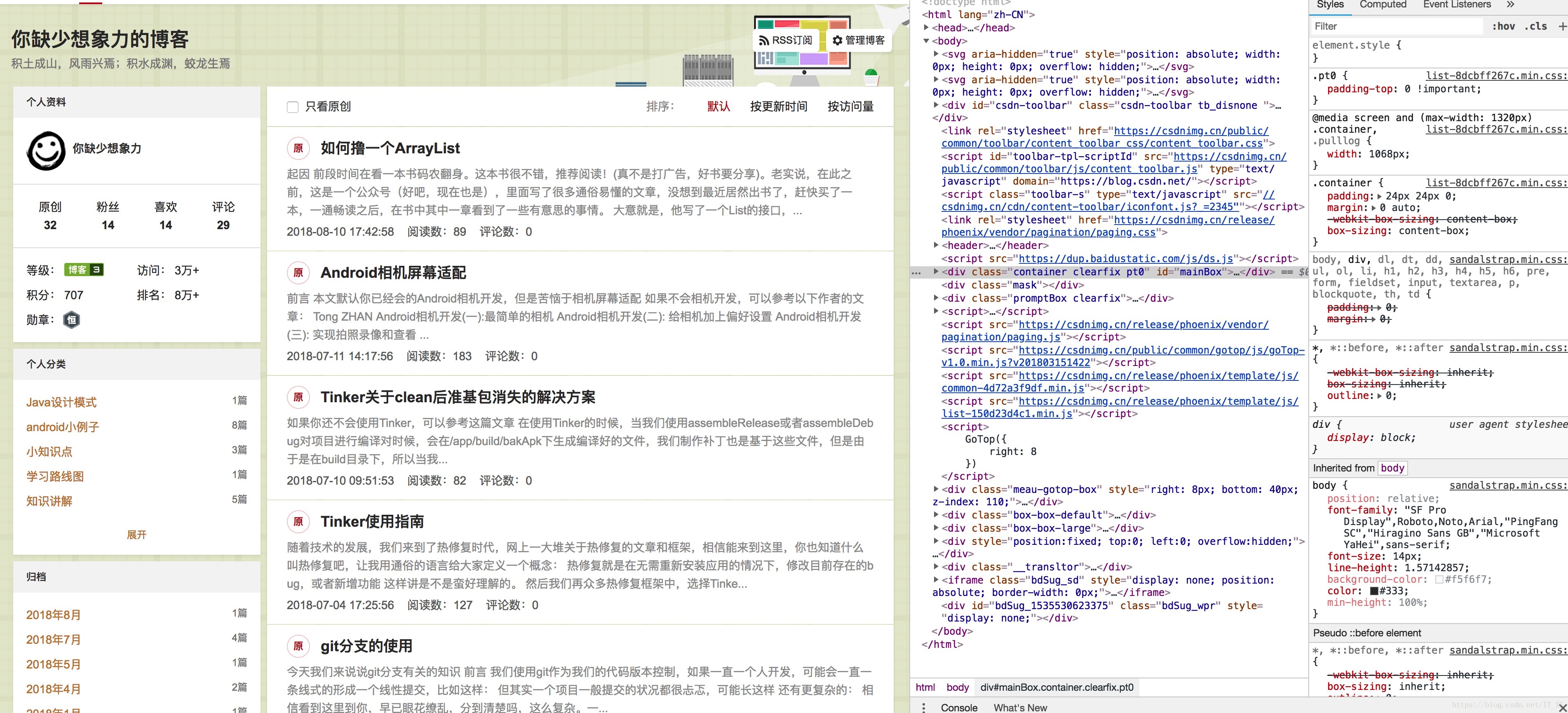

//\*[@id="mainBox"]/main/div[2]/div[1]/h4/a
这里给你解释解释:
// 定位根节点
/ 往下层寻找
提取文本内容:/text()
提取属性内容:/@xxxx
后面两个我们还没有在这个表达式见过,待会说,先摆张图放出来
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a
我们来琢磨琢磨,首先,//表示根节点,也就是说啊,这//后面的东西为根,则说明只有一个啊
也就是说,我们需要的东西,在这里面
然后/表示往下层寻找,根据图片,也显而易见,div -> main -> div[2] -> div[1] -> h4 -> a
追踪到a这里,我想,你们应该也就看得懂了,然后我们在后面加个/text,表示要把元素的内容提取出来,所以我们最终的表达式长这样:

//\*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
这个表达式只针对这个网页的这个元素,不难理解吧?
那么这个东西怎么用呢?
所有代码:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it\_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//\*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
print(each)
这时候,each里面的数据就是我们想要得到的数据了
打印结果:
如何撸一个ArrayList
打印结果却是这个结果,我们把换行和空格去掉
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it\_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//\*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
相当nice,那么,如果我们要得到所有的博客列表呢
看图看表达式分析大法
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
其实我们能够很容易发现,main->div[2]其实包含所有文章,只是我们取了main->div[2]->div[1],也就是说我们只是取了第一个而已。所以,其实表达式写出这样,就可以得到所有的文章了
//\*[@id="mainBox"]/main/div[2]/div/h4/a/text()
再来一次:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it\_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//\*[@id="mainBox"]/main/div[2]/div/h4/a/text()')


**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上物联网嵌入式知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、电子书籍、讲解视频,并且后续会持续更新**
**[如果你需要这些资料,可以戳这里获取](https://bbs.csdn.net/topics/618679757)**
年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上物联网嵌入式知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、电子书籍、讲解视频,并且后续会持续更新**
**[如果你需要这些资料,可以戳这里获取](https://bbs.csdn.net/topics/618679757)**















 3466
3466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









