







收集整理了一份《2024年最新物联网嵌入式全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升的朋友。
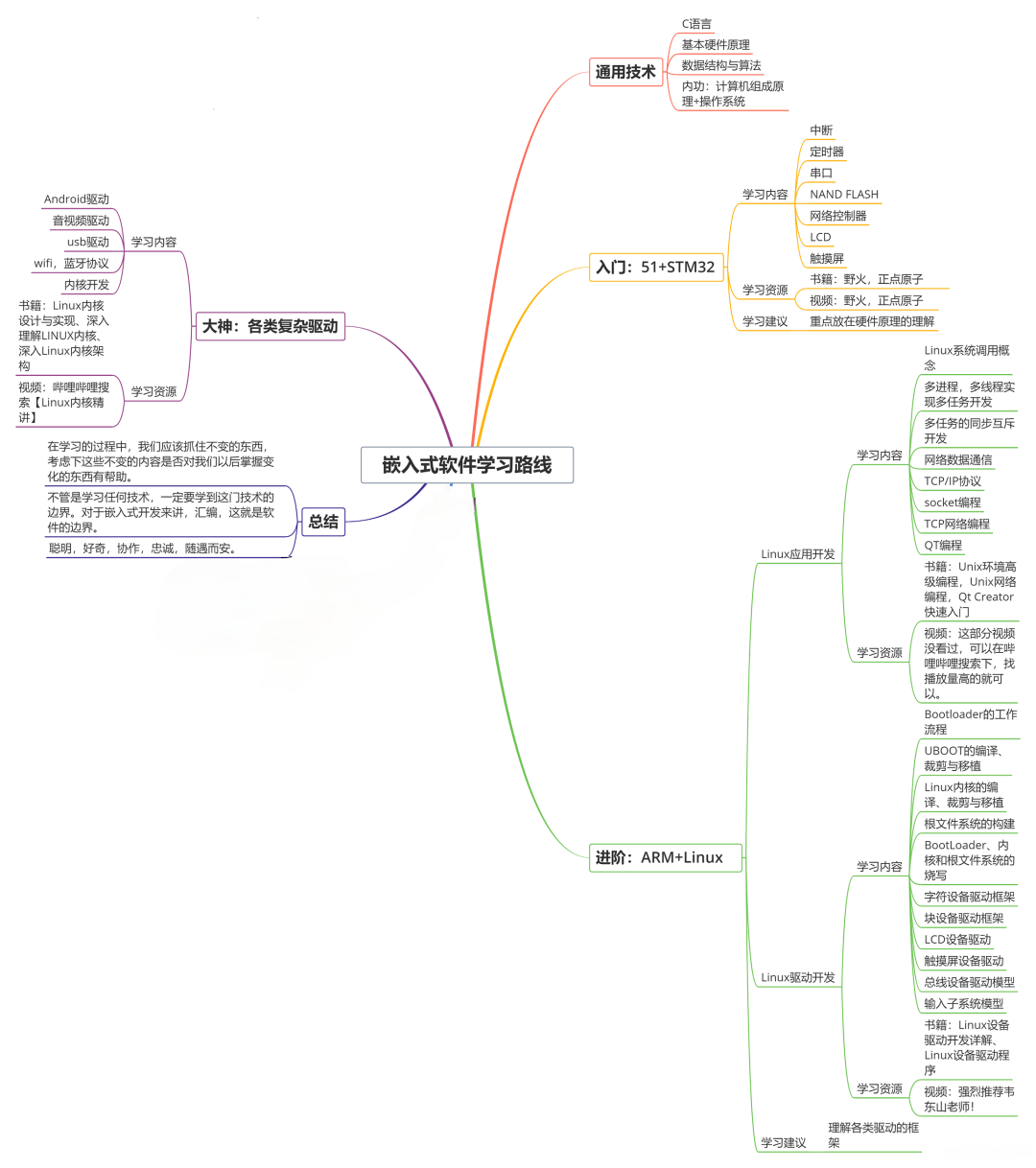
需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
)
O(n)
O(n)。C语言代码实现如下:
int SeqListInsert(struct SeqList \*sq, int k, DataType v) {
int i;
if(sq->length == MAXN) {
return 0; // (1)
}
for(i = sq->length; i > k; --i) {
sq->data[i] = sq->data[i-1]; // (2)
}
sq->data[k] = v; // (3)
sq->length ++; // (4)
return 1; // (5)
}
- (
1
)
(1)
(1) 当元素个数已满时,返回
0
0
0 代表插入失败;
- (
2
)
(2)
(2) 从第
k
k
k 个数开始,每个数往后移动一个位置,注意必须逆序;
- (
3
)
(3)
(3) 将第
k
k
k 个数变成
v
v
v;
- (
4
)
(4)
(4) 插入了一个数,数组长度加一;
- (
5
)
(5)
(5) 返回
1
1
1 代表插入成功;
5、删除
插入接口定义为:将数组的第
k
k
k 个元素删除。由于数组是连续存储的,那么第
k
k
k 个元素删除,往后的元素势必要往前移动一位,当
k
=
0
k=0
k=0 时,所有元素都必须移动,所以最坏时间复杂度为
O
(
n
)
O(n)
O(n)。C语言代码实现如下:
int SeqListDelete(struct SeqList \*sq, int k) {
int i;
if(sq->length == 0) {
return 0; // (1)
}
for(i = k; i < sq->length - 1; ++i) {
sq->data[i] = sq->data[i+1]; // (2)
}
sq->length --; // (3)
return 1; // (4)
}
- (
1
)
(1)
(1) 返回0代表删除失败;
- (
2
)
(2)
(2) 从前往后;
- (
3
)
(3)
(3) 数组长度减一;
- (
4
)
(4)
(4) 返回1代表删除成功;
- 想要了解更多数组相关内容,可以参考:《画解数据结构》(1 - 1)- 数组。
2、链表
内存结构:内存空间连续不连续,看具体实现
实现难度:一般
下标访问:不支持
分类:单向链表、双向链表、循环链表、DancingLinks
插入时间复杂度:O
(
1
)
O(1)
O(1)
查找时间复杂度:O
(
n
)
O(n)
O(n)
删除时间复杂度:O
(
1
)
O(1)
O(1)
一、概念
- 对于顺序存储的结构,如数组,最大的缺点就是:插入 和 删除 的时候需要移动大量的元素。所以,基于前人的智慧,他们发明了链表。
1、链表定义
链表 是由一个个 结点 组成,每个 结点 之间通过 链接关系 串联起来,每个 结点 都有一个 后继节点,最后一个 结点 的 后继结点 为 空结点。如下图所示:

- 由链接关系
A -> B组织起来的两个结点,B被称为A的后继结点,A被称为B的前驱结点。 - 链表 分为 单向链表、双向链表、循环链表 等等,本文要介绍的链表是 单向链表。
- 由于链表是由一个个 结点 组成,所以我们先来看下 结点 的实现。
2、结点结构体定义
typedef int DataType;
struct ListNode {
DataType data; // (1)
ListNode \*next; // (2)
};
- (
1
)
(1)
(1) 数据域:可以是任意类型,由编码的人自行指定;这段代码中,利用typedef将它和int同名,本文的 数据域 也会全部采用int类型进行讲解;
- (
2
)
(2)
(2) 指针域:指向 后继结点 的地址;
- 一个结点包含的两部分如下图所示:

3、结点的创建
- 我们通过 C语言 中的库函数
malloc来创建一个 链表结点,然后对 数据域 和 指针域 进行赋值,代码实现如下:
ListNode \*ListCreateNode(DataType data) {
ListNode \*node = (ListNode \*) malloc ( sizeof(ListNode) ); // (1)
node->data = data; // (2)
node->next = NULL; // (3)
return node; // (4)
}
- (
1
)
(1)
(1) 利用系统库函数malloc分配一块内存空间,用来存放ListNode即链表结点对象;
- (
2
)
(2)
(2) 将 数据域 置为函数传参data;
- (
3
)
(3)
(3) 将 指针域 置空,代表这是一个孤立的 链表结点;
- (
4
)
(4)
(4) 返回这个结点的指针。
- 创建完毕以后,这个孤立结点如下所示:

二、链表的创建 - 尾插法
- 那么接下来,让我们看下如何通过一个 数组中的数据 来创建一个链表。
1、算法描述
首先介绍 尾插法 ,顾名思义,即 从链表尾部插入 的意思,就是记录一个 链表尾结点,然后遍历给定数组,将数组元素一个一个插到链表的尾部,每插入一个结点,则将它更新为新的 链表尾结点。注意初始情况下,链表尾结点 为空。
2、动画演示

上图演示的是 尾插法 的整个过程,其中:
head 代表链表头结点,创建完一个结点以后,它就保持不变了;
tail 代表链表尾结点,即动图中的 绿色结点;
vtx 代表正在插入链表尾部的结点,即动图中的 橙色结点,插入完毕以后,vtx 变成 tail;
- 看完这个动图,你应该已经大致理解了 链表的创建过程。那么接下来,我们用程序语言来描述一下整个过程,这里采用的是 C语言 的形式,如果你是 Java、C#、Python 技术栈的,也可以试着写出自己的版本。
- 语言并不是关键,思维才是关键。
3、源码详解
- C语言 实现如下:
ListNode \*ListCreateListByTail(int n, int a[]) {
ListNode \*head, \*tail, \*vtx; // (1)
int idx;
if(n <= 0)
return NULL; // (2)
idx = 0;
vtx = ListCreateNode(a[0]); // (3)
head = tail = vtx; // (4)
while(++idx < n) { // (5)
vtx = ListCreateNode(a[idx]); // (6)
tail->next = vtx; // (7)
tail = vtx; // (8)
}
return head; // (9)
}
对应的注释如下:
(
1
)
(1)
(1)
head存储头结点的地址,tail存储尾结点的地址,vtx存储当前正在插入结点的地址;(
2
)
(2)
(2) 当需要创建的元素个数为 0 时,直接返回空链表;
(
3
)
(3)
(3) 创建一个 数据域 为
a[0]的链表结点;(
4
)
(4)
(4) 由于初始情况下只有一个结点,所以将链表头结点
head和链表尾结点tail都置为vtx;(
5
)
(5)
(5) 从数组第 1 个元素 (0 - based) 开始,循环遍历数组;
(
6
)
(6)
(6) 由于数组中第 0 个元素已经创建过了,所以这里只需要对除了第 0 个元素以外的数据创建链表结点;
(
7
)
(7)
(7) 结点创建出来后,将当前链表尾结点
tail的 后继结点 置为vtx;(
8
)
(8)
(8) 将最近创建的结点
vtx作为新的 链表尾结点;(
9
)
(9)
(9) 返回链表头结点;
- 尾插法 比较符合直观的思维逻辑,但是就代码量来说还是有点长(注意:在实现相同功能的情况下,代码应该是越简洁,越简单越好的)。
- 于是,我们引入了另一种创建链表的方式 —— 头插法。
三、链表的创建 - 头插法
1、算法描述
头插法,顾名思义,就是每次从头结点前面进行插入,但是这样一来,就会导致插入的数据元素是 逆序 的,所以我们需要 逆序访问数组 执行插入,此所谓 负负得正 的思想。
- 它的特点是代码量短,且 常数时间复杂度 低。虽然没有 尾插法 那么直观,但是代码简洁,更加容易阅读。
2、动画演示

上图所示的是 头插法 的整个插入过程,其中:
head 代表链表头结点,即动图中的 绿色结点,每新加一个结点,头结点就变成了新加入的结点;
tail 代表链表尾结点,创建完一个结点以后,它就保持不变了;
vtx 代表正在插入链表头部的结点,即动图中的 橙色结点,插入完毕以后,vtx 变成 head;
3、源码详解
ListNode \*ListCreateListByHead(int n, int \*a) {
ListNode \*head = NULL, \*vtx; // (1)
while(n--) { // (2)
vtx = ListCreateNode(a[n]); // (3)
vtx->next = head; // (4)
head = vtx; // (5)
}
return head; // (6)
}
对应的注释如下:
(
1
)
(1)
(1)
head存储头结点的地址,初始为空链表,vtx存储当前正在插入结点的地址;(
2
)
(2)
(2) 总共需要插入
n
n
n 个结点,所以采用逆序的
n
n
n 次循环;
(
3
)
(3)
(3) 创建一个元素值为
a[i]的链表结点,注意,由于逆序,所以这里i
i
i 的取值为
n
−
1
→
0
n-1 \to 0
n−1→0;
(
4
)
(4)
(4) 将当前创建的结点的 后继结点 置为 链表的头结点
head;(
5
)
(5)
(5) 将链表头结点
head置为vtx;(
6
)
(6)
(6) 返回链表头结点;
- 头插法 的代码量比 尾插法 少了三分之一,而且将 创建结点的逻辑 统一起来了。这句话什么意思呢?仔细观察可以发现,尾插法 在实现过程中,
ListCreateNode在代码里出现了两次,而 头插法 只出现了一次,将流程简化了,所以还是推荐使用 头插法。 - 想要了解更多链表相关内容,可以参考:《画解数据结构》(1 - 3)- 链表。
3、哈希表
内存结构:哈希表本身连续,但是衍生出来的结点逻辑上不连续
实现难度:一般
下标访问:不支持
分类:正数哈希、字符串哈希、滚动哈希
插入时间复杂度:O
(
1
)
O(1)
O(1)
查找时间复杂度:O
(
1
)
O(1)
O(1)
删除时间复杂度:O
(
1
)
O(1)
O(1)
一、哈希表的概念
1、查找算法
当我们在一个 链表 或者 顺序表 中 查找 一个数据元素 是否存在 的时候,唯一的方法就是遍历整个表,这种方法称为 线性枚举。

如果这时候,顺序表是有序的情况下,我们可以采用折半的方式去查找,这种方法称为 二分枚举。
线性枚举 的时间复杂度为
O
(
n
)
O(n)
O(n)。二分枚举 的时间复杂度为
O
(
l
o
g
2
n
)
O(log_2n)
O(log2n)。是否存在更快速的查找方式呢?这就是本要介绍的一种新的数据结构 —— 哈希表。
2、哈希表
由于它不是顺序结构,所以很多数据结构书上称之为 散列表,下文会统一采用 哈希表 的形式来说明,作为读者,只需要知道这两者是同一种数据结构即可。
我们把需要查找的数据,通过一个 函数映射,找到 存储数据的位置 的过程称为 哈希。这里涉及到几个概念:
a)需要 查找的数据 本身被称为 关键字;
b)通过 函数映射 将 关键字 变成一个 哈希值 的过程中,这里的 函数 被称为 哈希函数;
c)生成 哈希值 的过程过程可能产生冲突,需要进行 冲突解决;
d)解决完冲突以后,实际 存储数据的位置 被称为 哈希地址,通俗的说,它就是一个数组下标;
e)存储所有这些数据的数据结构就是 哈希表,程序实现上一般采用数组实现,所以又叫 哈希数组。整个过程如下图所示:

2、哈希数组
为了方便下标索引,哈希表 的底层实现结构是一个数组,数组类型可以是任意类型,每个位置被称为一个槽。如下图所示,它代表的是一个长度为 8 的 哈希表,又叫 哈希数组。

3、关键字
关键字 是哈希数组中的元素,可以是任意类型的,它可以是整型、浮点型、字符型、字符串,甚至是结构体或者类。如下的 A、C、M 都可以是关键字;
int A = 5;
char C[100] = "Hello World!";
struct Obj { };
Obj M;
哈希表的实现过程中,我们需要通过一些手段,将一个非整型的 关键字 转换成 数组下标,也就是 哈希值,从而通过
O
(
1
)
O(1)
O(1) 的时间快速索引到它所对应的位置。
而将一个非整型的 关键字 转换成 整型 的手段就是 哈希函数。
4、哈希函数
哈希函数可以简单的理解为就是小学课本上那个函数,即
y
=
f
(
x
)
y = f(x)
y=f(x),这里的
f
(
x
)
f(x)
f(x) 就是哈希函数,
x
x
x 是关键字,
y
y
y 是哈希值。好的哈希函数应该具备以下两个特质:
a)单射;
b)雪崩效应:输入值
x
x
x 的
1
1
1 比特的变化,能够造成输出值
y
y
y 至少一半比特的变化;
单射很容易理解,图
(
a
)
(a)
(a) 中已知哈希值
y
y
y 时,键
x
x
x 可能有两种情况,不是一个单射;而图
(
b
)
(b)
(b) 中已知哈希值
y
y
y 时,键
x
x
x 一定是唯一确定的,所以它是单射。由于
x
x
x 和
y
y
y 一一对应,这样就从本原上减少了冲突。
 雪崩效应是为了让哈希值更加符合随机分布的原则,哈希表中的键分布的越随机,利用率越高,效率也越高。
雪崩效应是为了让哈希值更加符合随机分布的原则,哈希表中的键分布的越随机,利用率越高,效率也越高。
常用的哈希函数有:直接定址法、除留余数法、数字分析法、平方取中法、折叠法、随机数法 等等。有关哈希函数的内容,下文会进行详细讲解。
5、哈希冲突
哈希函数在生成 哈希值 的过程中,如果产生 不同的关键字得到相同的哈希值 的情况,就被称为 哈希冲突。
即对于哈希函数
y
=
f
(
x
)
y = f(x)
y=f(x),当关键字
x
1
≠
x
2
x_1 \neq x_2
x1=x2,但是却有
f
(
x
1
)
=
f
(
x
2
)
f(x_1) = f(x_2)
f(x1)=f(x2),这时候,我们需要进行冲突解决。
冲突解决方法有很多,主要有:开放定址法、再散列函数法、链地址法、公共溢出区法 等等。有关解决冲突的内容,下文会进行详细讲解。
6、哈希地址
哈希地址 就是一个 数组下标 ,即哈希数组的下标。通过下标获得数据,被称为 索引。通过数据获得下标,被称为 哈希。平时工作的时候,和同事交流时用到的一个词 反查 就是说的 哈希。
二、常用哈希函数
1、直接定址法
直接定址法 就是 关键字 本身就是 哈希值,表示成函数值就是
f
(
x
)
=
x
f(x) = x
f(x)=x 例如,我们需要统计一个字符串中每个字符的出现次数,就可以通过这种方法。任何一个字符的范围都是
[
0
,
255
]
[0, 255]
[0,255],所以只要用一个长度为 256 的哈希数组就可以存储每个字符对应的出现次数,利用一次遍历枚举就可以解决这个问题。C代码实现如下:
int i, hash[256];
for(i = 0; str[i]; ++i) {
++hash[ str[i] ];
}
这个就是最基础的直接定址法的实现。hash[c]代表字符c在这个字符串str中的出现次数。
2、平方取中法
平方取中法 就是对 关键字 进行平方,再取中间的某几位作为 哈希值。
例如,对于关键字
1314
1314
1314,得到平方为
1726596
1726596
1726596,取中间三位作为哈希值,即
265
265
265。
平方取中法 比较适用于 不清楚关键字的分布,且位数也不是很大 的情况。
3、折叠法
折叠法 是将关键字分割成位数相等的几部分(注意最后一部分位数不够可以短一些),然后再进行求和,得到一个 哈希值。
例如,对于关键字
5201314
5201314
5201314,将它分为四组,并且相加得到:
52
01
31
4
=
88
52+01+31+4 = 88
52+01+31+4=88,这就是哈希值。
折叠法 比较适用于 不清楚关键字的分布,但是关键字位数较多 的情况。
4、除留余数法
除留余数法 就是 关键字 模上 哈希表 长度,表示成函数值就是
f
(
x
)
=
x
m
o
d
m
f(x) = x \ mod \ m
f(x)=x mod m 其中
m
m
m 代表了哈希表的长度,这种方法,不仅可以对关键字直接取模,也可以在 平方取中法、折叠法 之后再取模。
例如,对于一个长度为 4 的哈希数组,我们可以将关键字 模 4 得到哈希值,如图所示:

5、位与法
哈希数组的长度一般选择 2 的幂,因为我们知道取模运算是比较耗时的,而位运算相对较为高效。
选择 2 的幂作为数组长度,可以将 取模运算 转换成 二进制位与。
令
m
=
2
k
m = 2^k
m=2k,那么它的二进制表示就是:
m
=
(
1
000…000
⏟
k
)
2
m = (1\underbrace{000…000}_{\rm k})_2
m=(1k
000…000)2,任何一个数模上
m
m
m,就相当于取了
m
m
m 的二进制低
k
k
k 位,而
m
−
1
=
(
111…111
⏟
k
)
2
m-1 = (\underbrace{111…111}_{\rm k})_2
m−1=(k
111…111)2 ,所以和 位与
m
−
1
m-1
m−1 的效果是一样的。即:
x
%
S
=
=
x
&
(
S
−
1
)
x \ % \ S == x \ & \ (S - 1)
x % S==x & (S−1) 除了直接定址法,其它三种方法都有可能导致哈希冲突,接下来,我们就来讨论下常用的一些哈希冲突的解决方案。
三、常见哈希冲突解决方案
1、开放定址法
1)原理讲解
开放定址法 就是一旦发生冲突,就去寻找下一个空的地址,只要哈希表足够大,总能找到一个空的位置,并且记录下来作为它的 哈希地址。公式如下:
f
i
(
x
)
=
(
f
(
x
)
d
i
)
m
o
d
m
f_i(x) = (f(x)+d_i) \ mod \ m
fi(x)=(f(x)+di) mod m
这里的
d
i
d_i
di 是一个数列,可以是常数列
(
1
,
1
,
1
,
.
.
.
,
1
)
(1, 1, 1, …,1)
(1,1,1,…,1),也可以是等差数列
(
1
,
2
,
3
,
.
.
.
,
m
−
1
)
(1,2,3,…,m-1)
(1,2,3,…,m−1)。
2)动画演示

上图中,采用的是哈希函数算法是 除留余数法,采用的哈希冲突解决方案是 开放定址法,哈希表的每个数据就是一个关键字,插入之前需要先进行查找,如果找到的位置未被插入,则执行插入;否则,找到下一个未被插入的位置进行插入;总共插入了 6 个数据,分别为:11、12、13、20、19、28。
这种方法需要注意的是,当插入数据超过哈希表长度时,不能再执行插入。
本文在第四章讲解 哈希表的现实 时采用的就是常数列的开放定址法。
2、再散列函数法
1)原理讲解
再散列函数法 就是一旦发生冲突,就采用另一个哈希函数,可以是 平方取中法、折叠法、除留余数法 等等的组合,一般用两个哈希函数,产生冲突的概率已经微乎其微了。
再散列函数法 能够使关键字不产生聚集,当然,也会增加不少哈希函数的计算时间。
3、链地址法
1)原理讲解
当然,产生冲突后,我们也可以选择不换位置,还是在原来的位置,只是把 哈希值 相同的用链表串联起来。这种方法被称为 链地址法。
2)动画演示

上图中,采用的是哈希函数算法是 除留余数法,采用的哈希冲突解决方案是 链地址法,哈希表的每个数据保留了一个 链表头结点 和 尾结点,插入之前需要先进行查找,如果找到的位置,链表非空,则插入尾结点并且更新尾结点;否则,生成一个新的链表头结点和尾结点;总共插入了 6 个数据,分别为:11、12、13、20、19、28。
4、公共溢出区法
1)原理讲解
一旦产生冲突的数据,统一放到另外一个顺序表中,每次查找数据,在哈希数组中到的关键字和给定关键字相等,则认为查找成功;否则,就去公共溢出区顺序查找,这种方法被称为 公共溢出区法。
这种方法适合冲突较少的情况。
哈希表相关的内容,可以参考我的这篇文章:夜深人静写算法(九)- 哈希表
4、队列
内存结构:看用数组实现,还是链表实现
实现难度:一般
下标访问:不支持
分类:FIFO、单调队列、双端队列
插入时间复杂度:O
(
1
)
O(1)
O(1)
查找时间复杂度:理论上不支持
删除时间复杂度:O
(
1
)
O(1)
O(1)
一、概念
1、队列的定义
队列 是仅限在 一端 进行 插入,另一端 进行 删除 的 线性表。
队列 又被称为 先进先出 (First In First Out) 的线性表,简称 FIFO 。

2、队首
允许进行元素删除的一端称为 队首。如下图所示:

3、队尾
允许进行元素插入的一端称为 队尾。如下图所示:

二、接口
1、数据入队
队列的插入操作,叫做 入队。它是将 数据元素 从 队尾 进行插入的过程,如图所示,表示的是 插入 两个数据(绿色 和 蓝色)的过程:

2、数据出队
队列的删除操作,叫做 出队。它是将 队首 元素进行删除的过程,如图所示,表示的是 依次 删除 两个数据(红色 和 橙色)的过程:

3、清空队列
队列的清空操作,就是一直 出队,直到队列为空的过程,当 队首 和 队尾 重合时,就代表队尾为空了,如图所示:

4、获取队首数据
对于一个队列来说只能获取 队首 数据,一般不支持获取 其它数据。
5、获取队列元素个数
队列元素个数一般用一个额外变量存储,入队 时加一,出队 时减一。这样获取队列元素的时候就不需要遍历整个队列。通过
O
(
1
)
O(1)
O(1) 的时间复杂度获取队列元素个数。
6、队列的判空
当队列元素个数为零时,就是一个 空队,空队 不允许 出队 操作。
有关队列的更多内容,可以参考我的这篇文章:《画解数据结构》(1 - 6)- 队列
5、栈
内存结构:看用数组实现,还是链表实现
实现难度:一般
下标访问:不支持
分类:FILO、单调栈
插入时间复杂度:O
(
1
)
O(1)
O(1)
查找时间复杂度:理论上不支持
删除时间复杂度:O
(
1
)
O(1)
O(1)
一、概念
1、栈的定义
栈 是仅限在 表尾 进行 插入 和 删除 的 线性表。
栈 又被称为 后进先出 (Last In First Out) 的线性表,简称 LIFO 。
2、栈顶
栈 是一个线性表,我们把允许 插入 和 删除 的一端称为 栈顶。

3、栈底
和 栈顶 相对,另一端称为 栈底,实际上,栈底的元素我们不需要关心。

二、接口
1、数据入栈
栈的插入操作,叫做 入栈,也可称为 进栈、压栈。如下图所示,代表了三次入栈操作:

2、数据出栈
栈的删除操作,叫做 出栈,也可称为 弹栈。如下图所示,代表了两次出栈操作:

3、清空栈
一直 出栈,直到栈为空,如下图所示:

1、获取栈顶数据
对于一个栈来说只能获取 栈顶 数据,一般不支持获取 其它数据。
2、获取栈元素个数
栈元素个数一般用一个额外变量存储,入栈 时加一,出栈 时减一。这样获取栈元素的时候就不需要遍历整个栈。通过
O
(
1
)
O(1)
O(1) 的时间复杂度获取栈元素个数。
3、栈的判空
当栈元素个数为零时,就是一个空栈,空栈不允许 出栈 操作。
栈相关的内容,可以参考我的这篇文章:《画解数据结构》(1 - 5)- 栈
🌵7、二叉树
优先队列 是 堆实现的,所以也属于 二叉树 范畴。它和队列不同,不属于线性表。
内存结构:内存结构一般不连续,但是有时候实现的时候,为了方便,一般是物理连续,逻辑不连续
实现难度:较难
下标访问:不支持
分类:二叉树 和 多叉树
插入时间复杂度:看情况而定
查找时间复杂度:理论上O
(
l
o
g
2
n
)
O(log_2n)
O(log2n)
删除时间复杂度:看情况而定
🌳8、多叉树
内存结构:内存结构一般不连续,但是有时候实现的时候,为了方便,一般是物理连续,逻辑不连续
实现难度:较难
下标访问:不支持
分类:二叉树 和 多叉树
插入时间复杂度:看情况而定
查找时间复杂度:理论上O
(
l
o
g
2
n
)
O(log_2n)
O(log2n)
删除时间复杂度:看情况而定
- 一种经典的多叉树是字典树,可以参考我的这篇文章:
- 夜深人静写算法(七)- 字典树
🌲9、森林
- 比较经典的森林是:并查集,可以参考我的这篇文章:
- 夜深人静写算法(五)- 并查集
🍀10、树状数组
- 树状数组是用来做 单点更新,成端求和 的问题的,有关于它的内容,可以参考:
- 夜深人静写算法(十三)- 树状数组
🌍11、图
内存结构:不一定
实现难度:难
下标访问:不支持
分类:有向图、无向图
插入时间复杂度:根据算法而定
查找时间复杂度:根据算法而定
删除时间复杂度:根据算法而定
1、图的概念
- 在讲解最短路问题之前,首先需要介绍一下计算机中图(图论)的概念,如下:
- 图
G
G
G 是一个有序二元组
(
V
,
E
)
(V,E)
(V,E),其中
V
V
V 称为顶点集合,
E
E
E 称为边集合,
E
E
E 与
V
V
V 不相交。顶点集合的元素被称为顶点,边集合的元素被称为边。
- 对于无权图,边由二元组
(
u
,
v
)
(u,v)
(u,v) 表示,其中
u
,
v
∈
V
u, v \in V
u,v∈V。对于带权图,边由三元组
(
u
,
v
,
w
)
(u,v, w)
(u,v,w) 表示,其中
u
,
v
∈
V
u, v \in V
u,v∈V,
w
w
w 为权值,可以是任意类型。
- 图分为有向图和无向图,对于有向图,
(
u
,
v
)
(u, v)
(u,v) 表示的是 从顶点
u
u
u 到 顶点
v
v
v 的边,即
u
→
v
u \to v
u→v;对于无向图,
(
u
,
v
)
(u, v)
(u,v) 可以理解成两条边,一条是 从顶点
u
u
u 到 顶点
v
v
v 的边,即
u
→
v
u \to v
u→v,另一条是从顶点
v
v
v 到 顶点
u
u
u 的边,即
v
→
u
v \to u
v→u;
2、图的存储
- 对于图的存储,程序实现上也有多种方案,根据不同情况采用不同的方案。接下来以图二-3-1所表示的图为例,讲解四种存储图的方案。

1)邻接矩阵
- 邻接矩阵是直接利用一个二维数组对边的关系进行存储,矩阵的第
i
i
i 行第
j
j
j 列的值 表示
i
→
j
i \to j
i→j 这条边的权值;特殊的,如果不存在这条边,用一个特殊标记
∞
\infty
∞ 来表示;如果
i
=
j
i = j
i=j,则权值为
0
0
0。
- 它的优点是:实现非常简单,而且很容易理解;缺点也很明显,如果这个图是一个非常稀疏的图,图中边很少,但是点很多,就会造成非常大的内存浪费,点数过大的时候根本就无法存储。
- [
0
∞
3
∞
1
0
2
∞
∞
∞
0
3
9
8
∞
0
]
\left[ \begin{matrix} 0 & \infty & 3 & \infty \ 1 & 0 & 2 & \infty \ \infty & \infty & 0 & 3 \ 9 & 8 & \infty & 0 \end{matrix} \right]
⎣⎢⎢⎡01∞9∞0∞8320∞∞∞30⎦⎥⎥⎤
2)邻接表
- 邻接表是图中常用的存储结构之一,采用链表来存储,每个顶点都有一个链表,链表的数据表示和当前顶点直接相邻的顶点的数据
(
v
,
w
)
(v, w)
(v,w),即 顶点 和 边权。
- 它的优点是:对于稀疏图不会有数据浪费;缺点就是实现相对邻接矩阵来说较麻烦,需要自己实现链表,动态分配内存。
- 如图所示,
d
a
t
a
data
data 即
(
v
,
w
)
(v, w)
(v,w) 二元组,代表和对应顶点
u
u
u 直接相连的顶点数据,
w
w
w 代表
u
→
v
u \to v
u→v 的边权,
n
e
x
t
next
next 是一个指针,指向下一个
(
v
,
w
)
(v, w)
(v,w) 二元组。

- 在 C++ 中,还可以使用 vector 这个容器来代替链表的功能;
vector<Edge> edges[maxn];
3)前向星
- 前向星是以存储边的方式来存储图,先将边读入并存储在连续的数组中,然后按照边的起点进行排序,这样数组中起点相等的边就能够在数组中进行连续访问了。
- 它的优点是实现简单,容易理解;缺点是需要在所有边都读入完毕的情况下对所有边进行一次排序,带来了时间开销,实用性也较差,只适合离线算法。
- 如图所示,表示的是三元组
(
u
,
v
,
w
)
(u, v, w)
(u,v,w) 的数组,
i
d
x
idx
idx 代表数组下标。
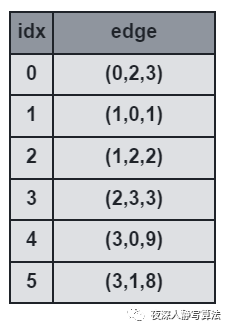
- 那么用哪种数据结构才能满足所有图的需求呢?
- 接下来介绍一种新的数据结构 —— 链式前向星。
4)链式前向星
- 链式前向星和邻接表类似,也是链式结构和数组结构的结合,每个结点
i
i
i 都有一个链表,链表的所有数据是从
i
i
i 出发的所有边的集合(对比邻接表存的是顶点集合),边的表示为一个四元组
(
u
,
v
,
w
,
n
e
x
t
)
(u, v, w, next)
(u,v,w,next),其中
(
u
,
v
)
(u, v)
(u,v) 代表该条边的有向顶点对
u
→
v
u \to v
u→v,
w
w
w 代表边上的权值,
n
e
x
t
next
next 指向下一条边。
- 具体的,我们需要一个边的结构体数组
edge[maxm],maxm表示边的总数,所有边都存储在这个结构体数组中,并且用head[i]来指向
i
i
i 结点的第一条边。
- 边的结构体声明如下:
struct Edge {
int u, v, w, next;
Edge() {}
Edge(int _u, int _v, int _w, int _next) :
u(_u), v(_v), w(_w), next(_next)
{
}
}edge[maxm];
- 初始化所有的
head[i] = -1,当前边总数edgeCount = 0; - 每读入一条
u
→
v
u \to v
u→v 的边,调用 addEdge(u, v, w),具体函数的实现如下:
void addEdge(int u, int v, int w) {
edge[edgeCount] = Edge(u, v, w, head[u]);
head[u] = edgeCount++;
}
- 这个函数的含义是每加入一条边
(
u
,
v
,
w
)
(u, v, w)
(u,v,w),就在原有的链表结构的首部插入这条边,使得每次插入的时间复杂度为
O
(
1
)
O(1)
O(1),所以链表的边的顺序和读入顺序正好是逆序的。这种结构在无论是稠密的还是稀疏的图上都有非常好的表现,空间上没有浪费,时间上也是最小开销。
- 调用的时候只要通过
head[i]就能访问到由
i
i
i 出发的第一条边的编号,通过编号到edge数组进行索引可以得到边的具体信息,然后根据这条边的next域可以得到第二条边的编号,以此类推,直到 next域为 -1 为止。
for (int e = head[u]; ~e; e = edges[e].next) {
int v = edges[e].v;
ValueType w = edges[e].w;
...
}
- 文中的
~e等价于e != -1,是对e进行二进制取反的操作(-1 的的补码二进制全是 1,取反后变成全 0,这样就使得条件不满足跳出循环)。
三、四个入门算法
1、排序
- 一般网上的文章在讲各种 「 排序 」 算法的时候,都会甩出一张 「 思维导图 」,如下:

- 当然,我也不例外……
- 这些概念也不用多说,只要你能够把**「 快速排序 」的思想理解了。基本上其它算法的思想也都能学会。这个思路就是经典的:「 要学就学最难的,其它肯定能学会 」。因为当你连「 最难的 」都已经 「 KO 」 了,其它的还不是「 小菜一碟 」**?信心自然就来了。
- 我们要战胜的其实不是**「 算法 」本身,而是我们对 「 算法 」 的恐惧。一旦建立起「 自信心 」,后面的事情,就「 水到渠成 」**了。
- 然而,实际情况比这可要简单得多。实际在上机刷题的过程中,不可能让你手写一个排序,你只需要知道 C++ 中 STL 的 sort 函数就够了,它的底层就是由【快速排序】实现的。
- 所有的排序题都可以做。我挑一个来说。至于上面说到的那十个排序算法,如果有缘,我会在八月份的这个专栏 ❤️**《画解数据结构》导航** ❤️ 中更新,尽情期待~~
I、例题描述
给你两个有序整数数组
n
u
m
s
1
nums1
nums1 和
n
u
m
s
2
nums2
nums2,请你将
n
u
m
s
2
nums2
nums2 合并到
n
u
m
s
1
nums1
nums1 中,使
n
u
m
s
1
nums1
nums1 成为一个有序数组。初始化
n
u
m
s
1
nums1
nums1 和
n
u
m
s
2
nums2
nums2 的元素数量分别为
m
m
m 和
n
n
n 。你可以假设
n
u
m
s
1
nums1
nums1 的空间大小等于
m
n
m + n
m+n,这样它就有足够的空间保存来自
n
u
m
s
2
nums2
nums2 的元素。
样例输入:n
u
m
s
1
=
[
1
,
2
,
3
,
0
,
0
,
0
]
,
m
=
3
,
n
u
m
s
2
=
[
2
,
5
,
6
]
,
n
=
3
nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
nums1=[1,2,3,0,0,0],m=3,nums2=[2,5,6],n=3
样例输出:[
1
,
2
,
2
,
3
,
5
,
6
]
[1,2,2,3,5,6]
[1,2,2,3,5,6]
原题出处: LeetCode 88. 合并两个有序数组
II、基础框架
- c++ 版本给出的基础框架代码如下:
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
}
};
III、思路分析
- 这个题别想太多,直接把第二个数组的元素加到第一个数组元素的后面,然后直接排序就成。

IV、时间复杂度
- STL 排序函数的时间复杂度为
O
(
n
l
o
g
2
n
)
O(nlog_2n)
O(nlog2n),遍历的时间复杂度为
O
(
n
)
O(n)
O(n),所以总的时间复杂度为
O
(
n
l
o
g
2
n
)
O(nlog_2n)
O(nlog2n)。
IV、源码详解
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
for(int i = m; i < n + m; ++i) {
nums1[i] = nums2[i-m]; // (1)
}
sort(nums1.begin(), nums1.end()); // (2)
}
};
- (
1
)
(1)
(1) 简单合并两个数组;
- (
2
)
(2)
(2) 对数组1进行排序;
VI、本题小知识
只要能够达到最终的结果,
O
(
n
)
O(n)
O(n) 和
O
(
n
l
o
g
2
n
)
O(nlog_2n)
O(nlog2n) 的差距其实并没有那么大。只要是和有序相关的,就可以调用这个函数,直接就出来了。
2、线性迭代
- 迭代就是一件事情重复的做,干的事情一样,只是参数的不同。一般配合的 数据结构 是 【数组】 或者 【链表】,实现方式也是一个循环。比 枚举 稍微复杂一点。
I、例题描述
给定单链表的头节点
h
e
a
d
head
head ,要求反转链表,并返回反转后的链表头。
样例输入:[
1
,
2
,
3
,
4
]
[1,2,3,4]
[1,2,3,4]
样例输出:[
4
,
3
,
2
,
1
]
[4, 3, 2, 1]
[4,3,2,1]
原题出处: LeetCode 206. 反转链表

II、基础框架
- c++ 版本给出的基础框架代码如下:
/\*\*
\* Definition for singly-linked list.
\* struct ListNode {
\* int val;
\* ListNode \*next;
\* ListNode() : val(0), next(nullptr) {}
\* ListNode(int x) : val(x), next(nullptr) {}
\* ListNode(int x, ListNode \*next) : val(x), next(next) {}
\* };
\*/
class Solution {
public:
ListNode\* reverseList(ListNode\* head) {
}
};
- 这里引入了一种数据结构 链表
ListNode; - 成员有两个:数据域
val和指针域next。 - 返回的是链表头结点;
III、思路分析
- 这个问题,我们可以采用头插法,即每次拿出第 2 个节点插到头部,拿出第 3 个节点插到头部,拿出第 4 个节点插到头部,… 拿出最后一个节点插到头部。
- 于是整个过程可以分为两个步骤:删除第
i
i
i 个节点,将它放到头部,反复迭代
i
i
i 即可。
- 如图所示:

- 我们发现,图中的蓝色指针永远固定在最开始的链表头结点上,那么可以以它为契机,每次删除它的
next,并且插到最新的头结点前面,不断改变头结点head的指向,迭代
n
−
1
n-1
n−1 次就能得到答案了。
IV、时间复杂度
- 每个结点只会被访问一次,执行一次头插操作,总共
n
n
n 个节点的情况下,时间复杂度
O
(
n
)
O(n)
O(n)。
V、源码详解
class Solution {
ListNode \*removeNextAndReturn(ListNode\* now) { // (1)
if(now == nullptr || now->next == nullptr) {
return nullptr; // (2)
}
ListNode \*retNode = now->next; // (3)
now->next = now->next->next; // (4)
return retNode;
}
public:
ListNode\* reverseList(ListNode\* head) {
ListNode \*doRemoveNode = head; // (5)
while(doRemoveNode) { // (6)
ListNode \*newHead = removeNextAndReturn(doRemoveNode); // (7)
if(newHead) { // (8)
newHead->next = head;
head = newHead;
}else {
break; // (9)
}
}


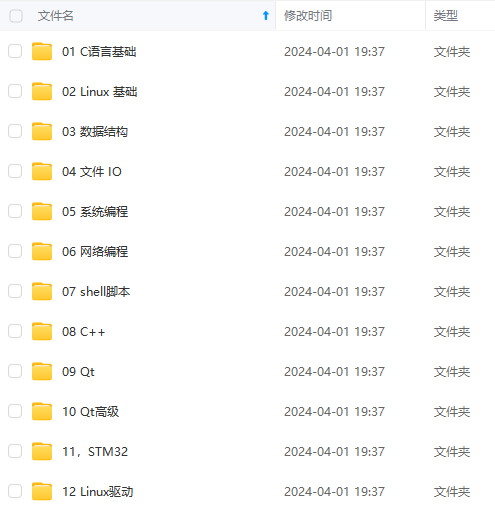
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上物联网嵌入式知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、电子书籍、讲解视频,并且后续会持续更新**
**需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)**
**[如果你需要这些资料,可以戳这里获取](https://bbs.csdn.net/topics/618679757)**
STL 排序函数的时间复杂度为
O
(
n
l
o
g
2
n
)
O(nlog\_2n)
O(nlog2n),遍历的时间复杂度为
O
(
n
)
O(n)
O(n),所以总的时间复杂度为
O
(
n
l
o
g
2
n
)
O(nlog\_2n)
O(nlog2n)。
**IV、源码详解**
class Solution {
public:
void merge(vector& nums1, int m, vector& nums2, int n) {
for(int i = m; i < n + m; ++i) {
nums1[i] = nums2[i-m]; // (1)
}
sort(nums1.begin(), nums1.end()); // (2)
}
};
* (
1
)
(1)
(1) 简单合并两个数组;
* (
2
)
(2)
(2) 对数组1进行排序;
**VI、本题小知识**
>
> 只要能够达到最终的结果,
>
>
>
>
> O
>
>
> (
>
>
> n
>
>
> )
>
>
>
> O(n)
>
>
> O(n) 和
>
>
>
>
> O
>
>
> (
>
>
> n
>
>
> l
>
>
> o
>
>
>
> g
>
>
> 2
>
>
>
> n
>
>
> )
>
>
>
> O(nlog\_2n)
>
>
> O(nlog2n) 的差距其实并没有那么大。只要是和有序相关的,就可以调用这个函数,直接就出来了。
>
>
>
---
### 2、线性迭代
* 迭代就是一件事情重复的做,干的事情一样,只是参数的不同。一般配合的 数据结构 是 【数组】 或者 【链表】,实现方式也是一个循环。比 枚举 稍微复杂一点。
**I、例题描述**
>
> 给定单链表的头节点
>
>
>
>
> h
>
>
> e
>
>
> a
>
>
> d
>
>
>
> head
>
>
> head ,要求反转链表,并返回反转后的链表头。
> **样例输入:**
>
>
>
>
> [
>
>
> 1
>
>
> ,
>
>
> 2
>
>
> ,
>
>
> 3
>
>
> ,
>
>
> 4
>
>
> ]
>
>
>
> [1,2,3,4]
>
>
> [1,2,3,4]
> **样例输出:**
>
>
>
>
> [
>
>
> 4
>
>
> ,
>
>
> 3
>
>
> ,
>
>
> 2
>
>
> ,
>
>
> 1
>
>
> ]
>
>
>
> [4, 3, 2, 1]
>
>
> [4,3,2,1]
> **原题出处:** LeetCode 206. 反转链表
> 
>
>
>
**II、基础框架**
* c++ 版本给出的基础框架代码如下:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
}
};
* 这里引入了一种数据结构 链表 `ListNode`;
* 成员有两个:数据域`val`和指针域`next`。
* 返回的是链表头结点;
**III、思路分析**
* 这个问题,我们可以采用头插法,即每次拿出第 2 个节点插到头部,拿出第 3 个节点插到头部,拿出第 4 个节点插到头部,… 拿出最后一个节点插到头部。
* 于是整个过程可以分为两个步骤:删除第
i
i
i 个节点,将它放到头部,反复迭代
i
i
i 即可。
* 如图所示:

* 我们发现,图中的蓝色指针永远固定在最开始的链表头结点上,那么可以以它为契机,每次删除它的`next`,并且插到最新的头结点前面,不断改变头结点`head`的指向,迭代
n
−
1
n-1
n−1 次就能得到答案了。
**IV、时间复杂度**
* 每个结点只会被访问一次,执行一次头插操作,总共
n
n
n 个节点的情况下,时间复杂度
O
(
n
)
O(n)
O(n)。
**V、源码详解**
class Solution {
ListNode *removeNextAndReturn(ListNode* now) { // (1)
if(now == nullptr || now->next == nullptr) {
return nullptr; // (2)
}
ListNode *retNode = now->next; // (3)
now->next = now->next->next; // (4)
return retNode;
}
public:
ListNode* reverseList(ListNode* head) {
ListNode *doRemoveNode = head; // (5)
while(doRemoveNode) { // (6)
ListNode *newHead = removeNextAndReturn(doRemoveNode); // (7)
if(newHead) { // (8)
newHead->next = head;
head = newHead;
}else {
break; // (9)
}
}
[外链图片转存中…(img-uG6DhYMw-1715802636083)]
[外链图片转存中…(img-QNVxIlaj-1715802636084)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上物联网嵌入式知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、电子书籍、讲解视频,并且后续会持续更新
需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









