






今天我们来揭开 Stable Diffusion 技术的神秘面纱
稳定扩散原理
Stable Diffusion 在2022年发表,一种基于Latent Diffusion Models的新兴机器学习技术。它基于扩散过程,利用数学模型将机器学习中的高维度数据降低到低维度空间,并在该空间中进行训练。Stable Diffusion的原理涉及到以下三个组件:
-
Text Encoder 文字特征化:为了输入文字的内容,我们要先有一个powerful的文字特征萃取器,可以是GPT、BERT等常见的主流Transformer model,总之能把文字特征做得好,就好的是Encoder 。
-
Diffusion Model 扩散模型:透过降躁过程,将一个潜在空间Latent Space的图像,逐步转回真实图像的技术,里面用到U-Net架构及Attenation技术,来提高模型表现,与传统的Diffusion略有不同。
-
VAE (Variational Autoencoder):变分自编码器,负责图像在潜在空间的压缩与重建,压缩后的图像能让模型学得更快更好。
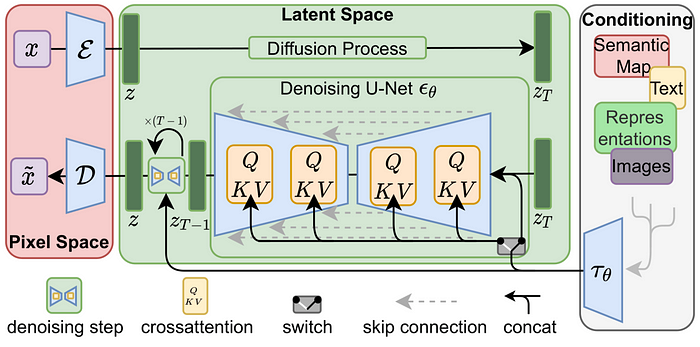
以功能来切,大概可以这样理解
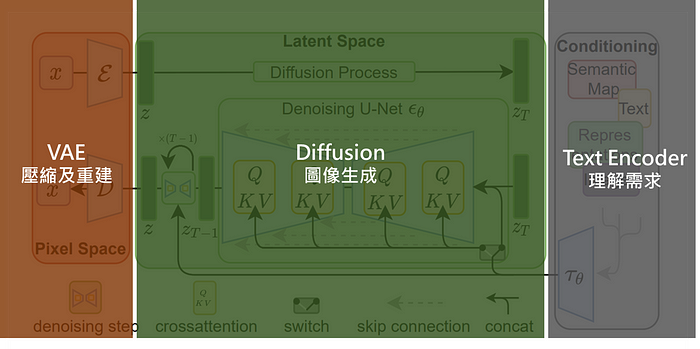
以模型的学习与训练来看,可以这样理解: 将高维特征压缩到低维,然后在低维空间上进行操作的方法具有泛用性,可以很容易推广到文本、音频、影像等数据。
将高维特征压缩到低维,然后在低维空间上进行操作的方法具有泛用性,可以很容易推广到文本、音频、影像等数据。

Stable Diffusion模型中,有几种不同的sampling方法可以用来生成数据,以下是一些常见的sampling方法:
-
Gaussian sampling:是Stable Diffusion中最常用的一种sampling方法。它通过将高斯噪声添加到数据中来生成新的样本。这种方法可以帮助模型更好地理解数据的分布和特征。
-
Langevin sampling:一种基于随机梯度下降的sampling方法。它通过将随机噪声添加到梯度中来生成新的样本。这种方法可以帮助模型更好地处理高度非线性的数据。
-
Metropolis-Hastings sampling:一种Markov Chain Monte Carlo(MCMC)方法,它可以生成一个序列来表示数据的分布。这种方法可以帮助模型更好地理解数据的复杂性和不确定性。
-
Hamiltonian Monte Carlo sampling:一种MCMC方法,它可以利用动态系统的特性来生成数据样本。这种方法可以帮助模型更好地理解数据中的隐含结构和特征。
-
Diffusion Process Model:DPM是基于扩散过程的理论原理,通过对数据样本中的噪声进行建模,可以帮助消除数据中的噪声和偏差,提高模型的准确性和泛化能力。
这些方法在Stable Diffusion的参数中都可以调整,其中Sampling step更会影响图片生成的运算时间及效果,原则上会根据采样方法不同而有所差异。
Dreambooth 原理
Google 在2022年提出的技术,可以保留你想想要的图片特征,基于 GAN 模型的核心思想,即通过将生成器和判别器部分相互对抗,从而提高生成器生成图像的质量和真实度。在Dreambooth中,生成器部分利用深度学习技术从文字描述中学习生成图像的能力,而判别器部分则利用深度学习技术评估图像的真实度,从而驱动生成器不断地优化生成图像的效果。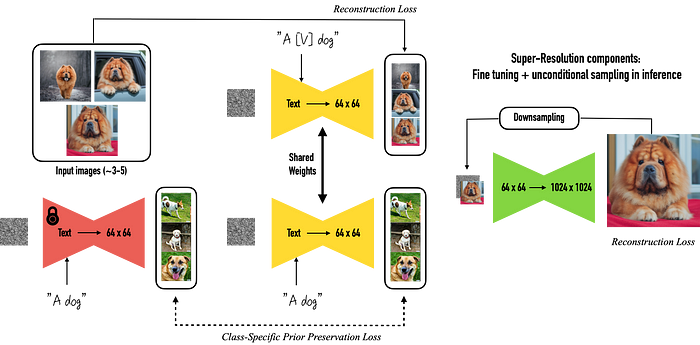 透过对Stable Diffusion的微调,让图片可以在保留特征的情况下生成更多样式,这也是近期很多艺术家反弹的艺术风格道德问题,如果你喜欢某个画师的风格,就能用这个技术将之模仿并创作。
透过对Stable Diffusion的微调,让图片可以在保留特征的情况下生成更多样式,这也是近期很多艺术家反弹的艺术风格道德问题,如果你喜欢某个画师的风格,就能用这个技术将之模仿并创作。

如Civitai上的Checkpoint Model,就是Stable Diffusion用来生成图片的主模型,可以快速找到你想要的风格。

LoRA 原理
Low-rank adaptation of large language models,又称 LoRA,微软开发的局部调整模型,非常轻量,可以在Stable Diffusion主模型的基础上,增加局部特征。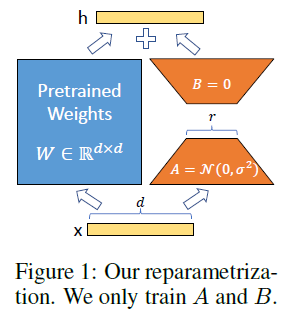 主要原理是将低秩矩阵分解应用到大型语言模型中,将模型中的权重矩阵分解成低秩的两个矩阵,从而减少存储需求和计算成本。此外模型还通过自适应学习的方法来调整模型的参数,以更好地适应不同的语言模型和文本数据。
主要原理是将低秩矩阵分解应用到大型语言模型中,将模型中的权重矩阵分解成低秩的两个矩阵,从而减少存储需求和计算成本。此外模型还通过自适应学习的方法来调整模型的参数,以更好地适应不同的语言模型和文本数据。
如Civitai上的LoRA Model,就能将想要的风格加进主模型中,你就可以建立各种表情、服装的Tifa之类的。
ControlNet 原理
ControlNet 模型通常由两个部分组成:一个称为系统动态的部分,用于处理非线性问题,另一个称为控制器的部分,用于调节模型的输出。控制器的输出可以根据系统动态的状态和期望输出值进行调整,从而提高模型的性能和准确度。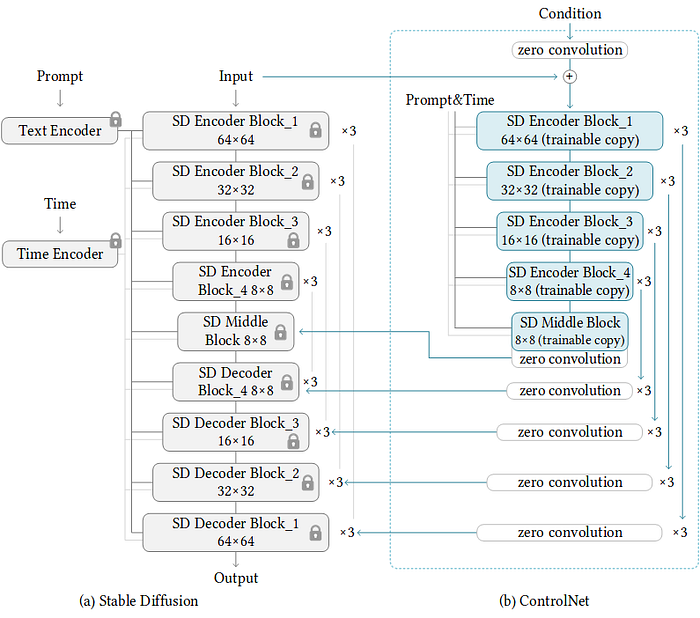 ControlNet 应该是 Stable Diffusion 目前最夯的应用,主要可以控制人物的动作,或是物体结构,不需要打一堆咒语,快速让AI懂你要的东西。
ControlNet 应该是 Stable Diffusion 目前最夯的应用,主要可以控制人物的动作,或是物体结构,不需要打一堆咒语,快速让AI懂你要的东西。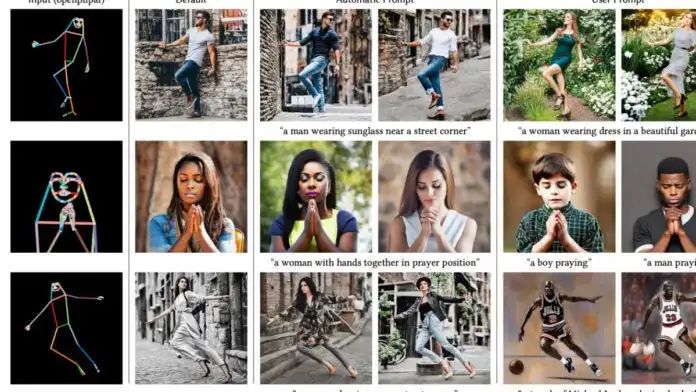
写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除















 2819
2819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









