






因为HashMap不是线程安全的,所以我们需要有一个线程安全的HashMap,能够保证线程安全的有:
HashTable、
Collections.synchronizedMap()、
ConcurrentHashMap,
然而HashTable、
Collections.synchronizedMap()的实现方式是直接上锁的,性能方面没有做到最优解,因此我们需要一个性能更好的,这就是ConcurrentHashMap产生的背景。
所以我们需要搞清楚以下一些问题:
-
HashMap的底层原理;
-
HashMap的哪些地方是线程不安全的?
-
HashTable、Collections.synchronizedMap()、ConcurrentHashMap都是如何保证线程安全的?
-
为什么HashTable、Collections.synchronizedMap()没人提了,ConcurrentHashMap却满天飞、逢面必问呢?
-
面试官问你ConcurrentHashMap真正要考察的知识是什么?
那接下来就让我们一起带着问题去学习这些个为什么。
本文源码基于JDK1.8。
2、HashMap中的那些线程不安全的操作
=====================
关于HashMap的实现原理,你必须熟记于心,然后我们才能继续去学习ConcurrentHashMap,这里一张图来回顾一下HashMap的数据结构:
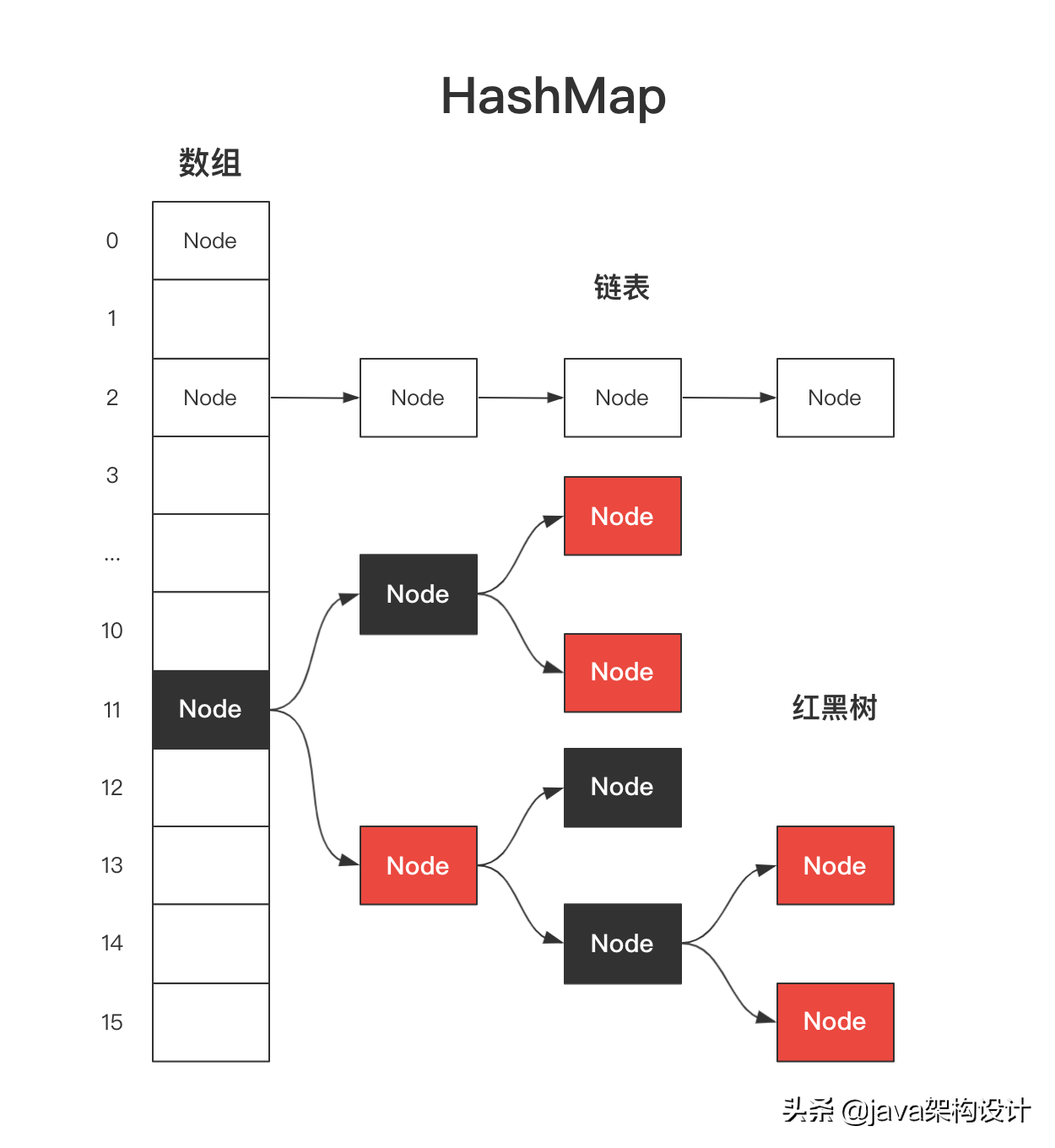
HashMap底层数据结构
如果对HashMap底层实现原理不熟悉的可以先行阅读我的文章:
接下来我们就进入HashMap的源码中来发现那些线程不安全的操作。
3、线程不安全一:数组初始化
==============
当我们初始化一个HashMap的时候,他其实只是定义了initialCapacity和loadFactor这两个值,并没有初始化数组,而是懒加载的思想,在第一次put时候通过resize()方法去加载。

HashMap.put()方法源码
进入resize()方法,前面一堆计算拿到要初始化数组的大小newCap,最终执行new Node[newCap];来初始化数组:

数组初始化
为什么线程不安全?
如果上面的这段话是被两个线程来执行会出现什么情况?
当线程T1和T2同时去put一个值执行putVal()的时候,会是什么情况?
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
例如:
-
T1线程的任务是初始化数组长度为16,T2线程的任务是初始化数组长度为32,是不是就无法得到一个确定的数组了?
-
T1线程还没有完成数组的初始化工作,T2线程已经开始执行putVal()方法了,这个时候T2线程put进去的值还是T1线程初始化的那个数组吗?
也就是在多线程的环境下操作可能会和单线程操作的属于不一致,即所谓的线程安全问题。
如何解决呢?是不是可以简单粗暴的对这个put()方法加锁?当一个线程执行put()方法的时候,让其他线程只能等待。
HashTable就是这样做的,可以打开HashTable的源码看到其put()方法如下:
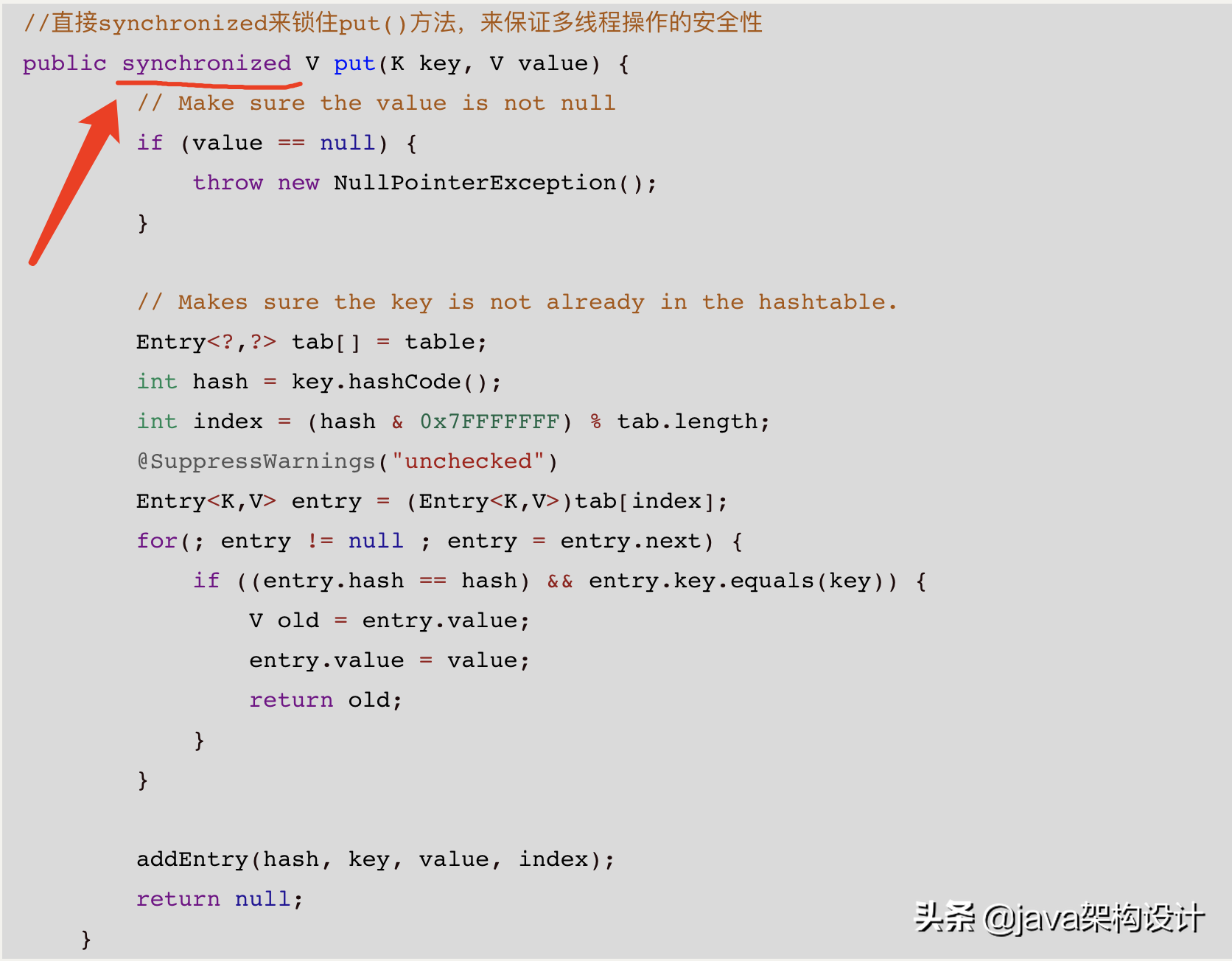
HashTable的put()方法
**Collections.synchronizedMap()**中是定义了一个内部类SynchronizedMap:
包含传入的Map以及定义的Object类型的mutex对象。
所有的方法都必须获得mutex对象的锁才能执行下去:

synchronized (mutex)
换个思路理解就是:在Map对象的外面装了一把锁,想访问Map对象必须获得mutex这把锁才可以。
所以我们可以知道的是:
**无论是HashTable还是
Collections.synchronizedMap()都是通过synchronized关键字来保证线程安全的。**
即使现在的synchronized关键字在锁的优化上有了很大的性能提升,但是依旧不可避免的情况是:
在多线程竞争激烈的情况下,锁会升级至重量级锁,重量级锁是由操作系统所持有和分配的,也就意味着出现了用户态(我们的JVM进程)和内核态(操作系统的kernel进程)的切换,性能也就随之降低!
那么有没有那么一种方法避免这样的情况出现呢?当然有!不然咱们还聊什么?
这就是CAS,Compare And Swap!
也就是本文的主角ConcurrentHashMap的实现方式,它是采用了CAS无锁化的方式来保证了数组初始化的线程安全:
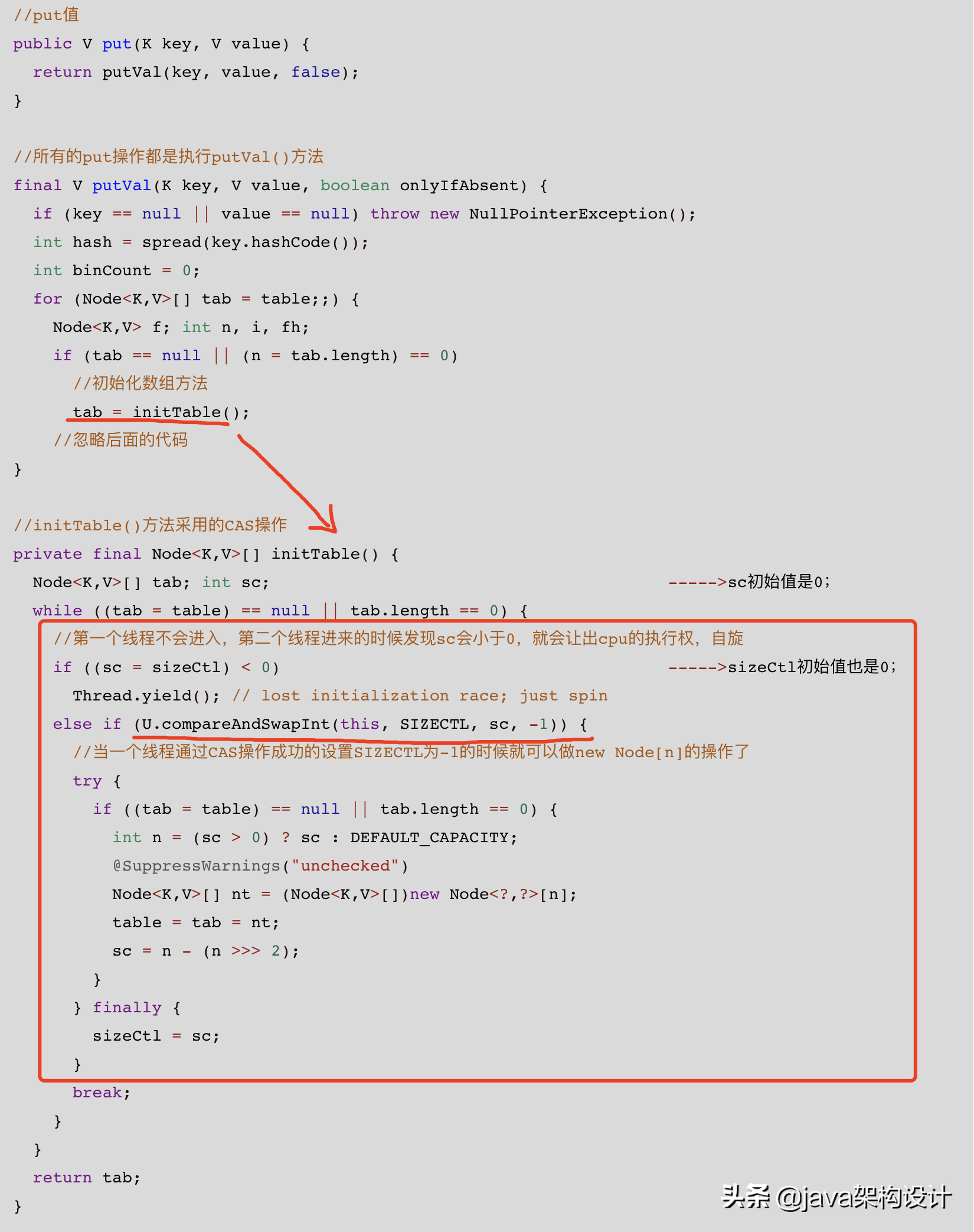
U.compareAndSwapInt(this, SIZECTL, sc, -1)
最核心的就是上面的**initTable()**方法了,最核心的就是这句话:
最核心的就是上面的**initTable()**方法了,最核心的就是这句话:
同时要注意的是这里的几个成员变量都是volatile修饰的:
transient volatile Node<K,V>[] table;
private transient volatile int sizeCtl;
4、其他线程不安全的操作
============
上面主要是通过数组初始化这一步来讲HashMap是如何线程不安全的,并且ConcurrentHashMap中是如何保证线程安全的。
HashMap中线程不安全的地方,ConcurrentHashMap中找对应功能的地方,看是怎么保证线程安全的就可以了。
接下来我们继续看HashMap源码中那些线程不安全的操作,继续看putVal()方法:

看图片里的代码注释
大家如果细看上面的源码以及我写的注释的话,会发现初始化数组后,就开始要把对象put到刚刚初始化的数组中去了:
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
那么上面这句话是线程安全的吗?
当然不是,可以这么说,这种带if判断的都不是线程安全的。
当一个线程判断当前这个tab[i]节点是null的时候,但是还没有执行完下一句,这个时候另外一个线程也来了,他判断这个节点也是null,也执行下面那句话,那最终两个线程只能有一个数据能写进去,另一个就丢了。
还是和上面的一样,HashTable就不说了,putVal()方法被synchronized了,里面所有的操作都是线程安全的,
Collections.synchronizedMap()类似。
我们来看看在ConcurrentHashMap中是怎么来保证线程安全的,还是找到putVal()方法:

casTabAt()
看上面的源码注释,当数组被安全的的初始化后,就开始put值进去了,这个地方一个是通过U.getObjectVolatile()来线程安全的判断出该数组下标对应的节点是否为null,如果是null,则执行casTabAt()方法去写入!
还是采用的是CAS无锁化的技术来保证写入的线程安全!
5、ConcurrentHashMap除了CAS还有其他保证线程安全的方式吗?
=======================================
上面两部分说的都是ConcurrentHashMap中用CAS来保证数组的初始化、下标为空的时候putVal()时候的线程安全。
那是不是ConcurrentHashMap中是不是都是用CAS来保证线程安全的呢?
还有其他的方式吗?synchronized出现了!
也就是说初始化数组、数组下标为null时候采用的都是CAS操作来保证线程安全的,但是当当前下标不为空的时候,就采用synchronized来保证线程安全了:

那么问题来了:
-
不是说synchronized慢么?这里是怎么回事?
-
为什么不用CAS?
这里的synchronized锁的是对象f,这个f有可能就是一个Node,有可能是一个链表或红黑树,即:
f = tabAt(tab, i = (n - 1) & hash)
也就是说锁的不是ConcurrentHashMap这个大对象,而是这个对象里的每一个数组里的对象,锁的粒度大大降低!
JDK1.7中的分段锁也是这个思想:降低锁的粒度。
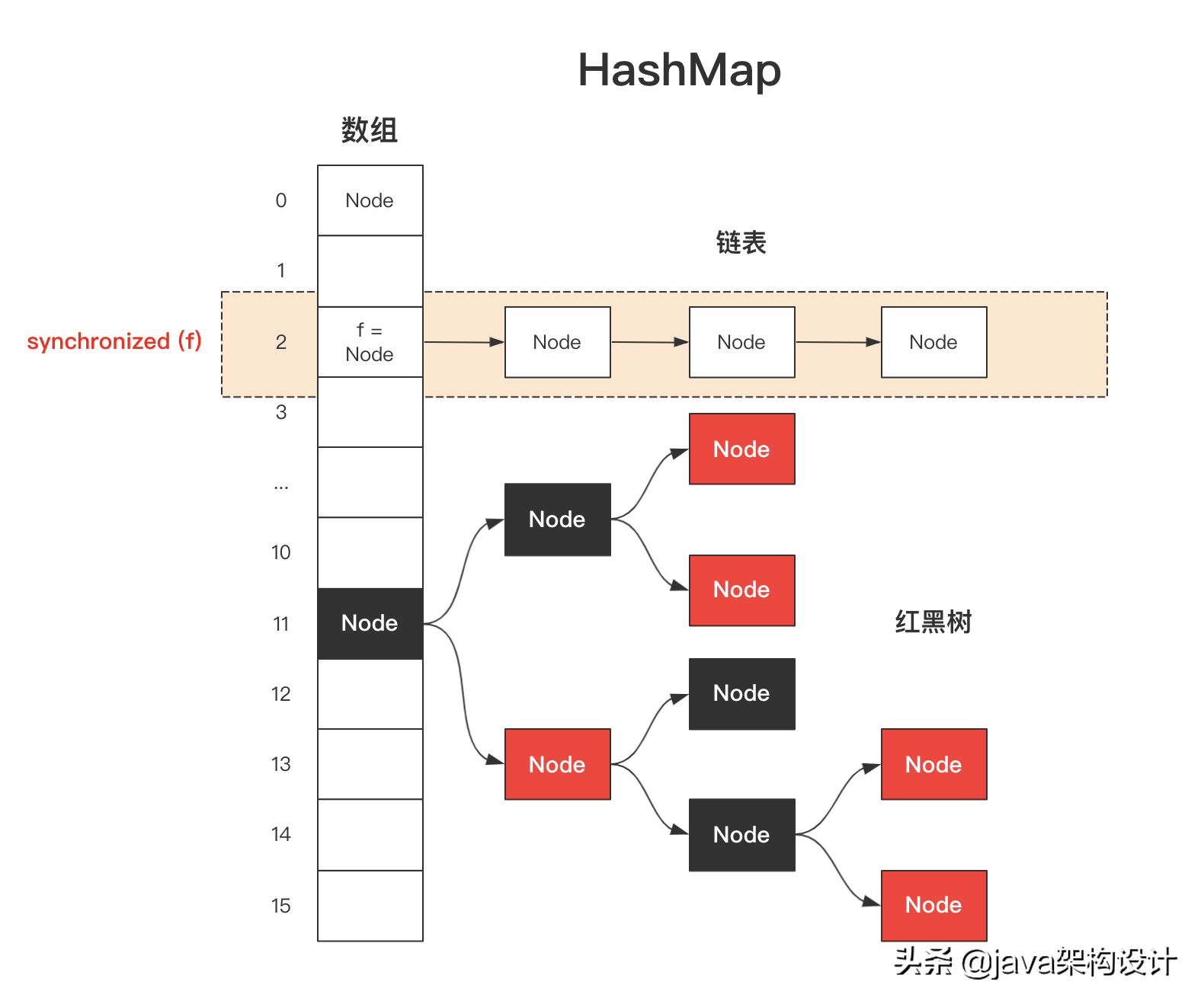
只锁住当前的对象f
第二个问题:为什么不用CAS?
当数组初始化或者数组下标为null时候,其实CAS要比较的就一个对象,相对比较简单,但是一旦有哈希冲突后,再用CAS来做Compare And Swap的时候,需要比较的对象就太多了!
想象一下链表里元素的逐个比较会是什么样的酸爽?
再想象一下红黑树里的Compare And Swap!各种树的调整,左旋、右旋,更酸爽!
这是要累死CPU的节奏!
所以显然在这个时候,直接用synchronized来锁住吧,在这样的场景下,synchronized的性能不一定比CAS差。
6、扩容
====
ConcurrentHashMap中最最最复杂的就是扩容了!
先来看HashMap中的扩容源码,还是从putVal()方法开始进入:

resize()方法在前面讲初始化数组的时候已经讲过,这里依旧是通过resize()方法来进行扩容:

具体描述看代码中的注释,我们继续来看HashMap的扩容过程以及新、旧数组的迁移过程中有没有线程安全的问题?
想象这样的一个场景:
当一个线程在对当前的HashMap进行扩容的时候,另外一个线程要put元素进来,那么这个元素是被put到新的数组里面去呢还是旧的数组里面去呢?
显然,无论是新的数组还是旧的数组,这都是有问题的!















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









