






目录
前言
准备工作
Git
Python3.9
Cmake
下载模型
合并模型
部署模型
前言
想必有小伙伴也想跟我一样体验下部署大语言模型, 但碍于经济实力, 不过民间上出现了大量的量化模型, 我们平民也能体验体验啦~,
该模型可以在笔记本电脑上部署, 确保你电脑至少有16G运行内存
开原地址:GitHub - ymcui/Chinese-LLaMA-Alpaca: 中文LLaMA&Alpaca大语言模型+本地CPU部署
(Chinese LLaMA & Alpaca LLMs)
Linux和Mac的教程在开源的仓库中有提供,当然如果你是M1的也可以参考以下文章:
https://gist.github.com/cedrickchee/e8d4cb0c4b1df6cc47ce8b18457ebde0
准备工作
最好是有代理, 不然你下载东西可能失败, 我为了下个模型花了一天时间, 痛哭~
我们需要先在电脑上安装以下环境:
- Git
- Python3.9(使用Anaconda3创建该环境)
- Cmake(如果你电脑没有C和C++的编译环境还需要安装mingw)
Git
下载地址:Git - Downloading Package

下载好安装包后打开, 一直点下一步安装即可…
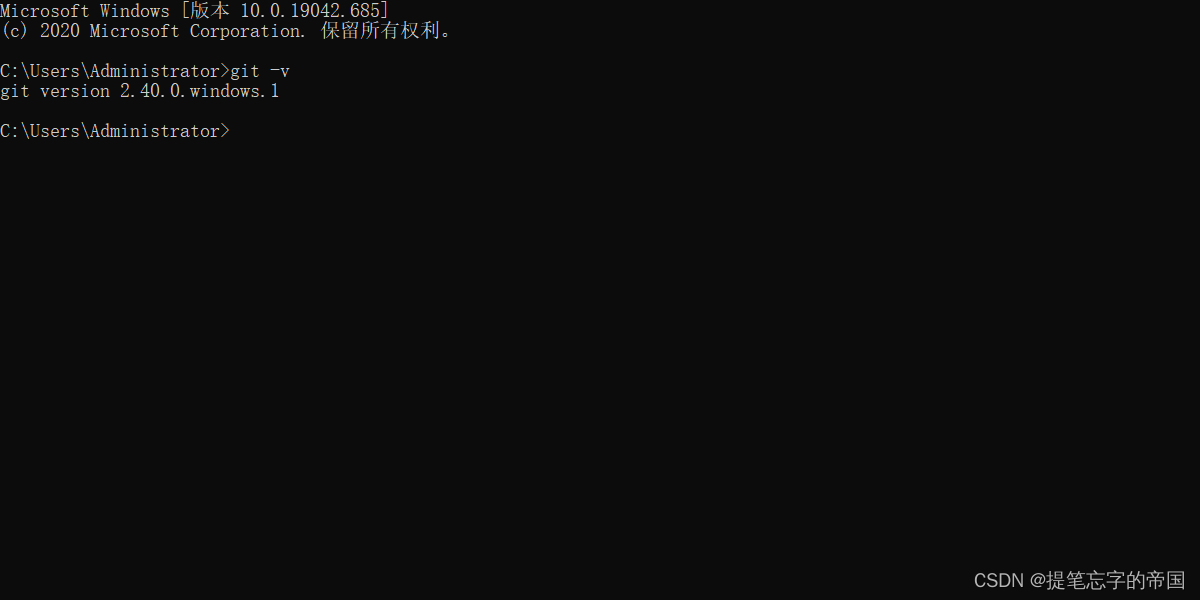
在cmd窗口输入以下如果有版本号显示说明已经安装成功
git -v
Python3.9
我这里使用Anaconda3来使用Python, Anaconda3是什么?
如果你熟悉docker, 那么你可以把docker的概念带过来, docker可以创建很多个容器, 每个容器的环境可能一样也可能不一样,
Anaconda3也是一样的, 它可以创建很多个不同的Python版本, 互相不冲突, 想用哪个版本就切换到哪个版本…
Anaconda3下载地址:Anaconda | Anaconda Distribution
安装步骤参考:





等待安装好后一直点next, 直到点Finish关闭即可
在cmd窗口输入以下命令, 显示版本号则说明安装成功
conda -V

接下来我们在cmd窗口输入以下命令创建一个python3.9的环境
conda create --name py39 python=3.9 -y
–name后面的py39是环境名字, 可以自己任意起, 切换环境的时候需要它
python=3.9是指定python版本
添加-y后就不需要手动输入y去确认安装了

查看有哪些环境的命令:
conda info -e

激活/切换环境的命令:
conda activate py39
要使用哪个环境的话换成对应名字即可

进入环境后你就可以在这输入python相关的命令了, 如:

要退出环境的话输入:
conda deactivate
当我退出环境后再查看python版本的话会提示我不是内部或外部命令,也不是可运行的程序
或批处理文件。如:

Cmake
这是一个编译工具, 我们需要使用它去编译llama.cpp, 量化模型需要用到, 不量化模型个人电脑跑不起来, 觉得量化这个概念不理解的可以理解为压缩, 这种概念是不对的,
只是为了帮助你更好的理解.
在安装之前我们需要安装mingw, 避免编译时找不到编译环境, 按下win+r快捷键输入powershell
输入命令安装scoop, 这是一个包管理器, 我们使用它来下载安装mingw:
这个地方如果没有开代理的话可能会出错
iex "& {$(irm get.scoop.sh)} -RunAsAdmin"
安装好后分别运行下面两个命令(添加库):
scoop bucket add extras
scoop bucket add main
输入命令安装mingw
scoop install mingw
到这就已经安装好mingw了, 如果报错了请评论, 我看到了会回复
接下来安装Cmake
安装参考:



安装好后点Finish即可
下载模型
我们需要下载两个模型, 一个是原版的LLaMA模型, 一个是扩充了中文的模型, 后续会进行一个合并模型的操作
- 原版模型下载地址(要代理):https://ipfs.io/ipfs/Qmb9y5GCkTG7ZzbBWMu2BXwMkzyCKcUjtEKPpgdZ7GEFKm/
- 备用:nyanko7/LLaMA-7B at main
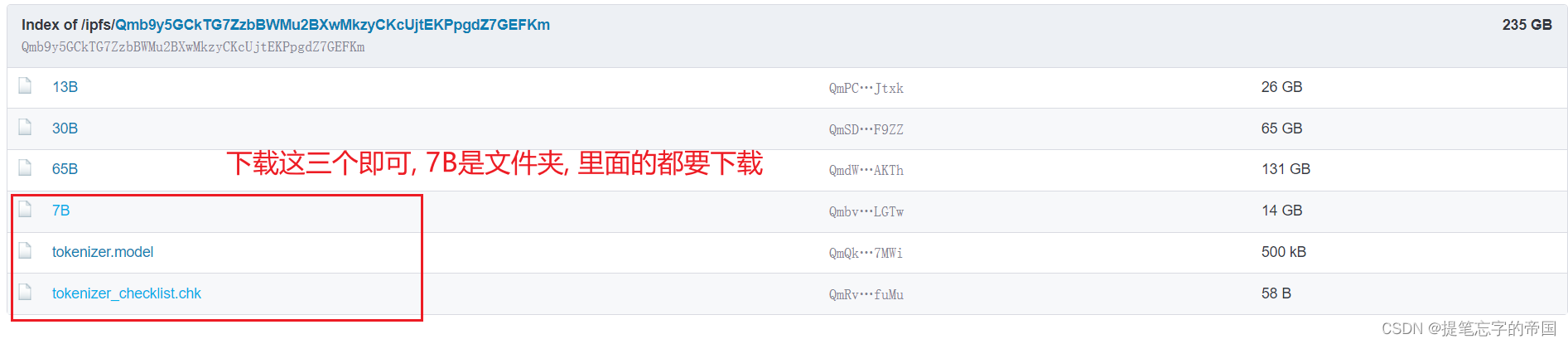
- 扩充了中文的模型下载:
建议在D盘上新建一个文件夹, 在里面进行下载操作, 如下:
在弹出的框中分别输入以下命令:
git lfs install
git clone https://huggingface.co/ziqingyang/chinese-alpaca-lora-7b
这里可能会因为网络问题一直失败…一直重试就行, 有别的问题请评论, 看到会回复
合并模型
终于写到这里了, 累~
在你下载了模型的目录内打开cmd窗口, 如下:

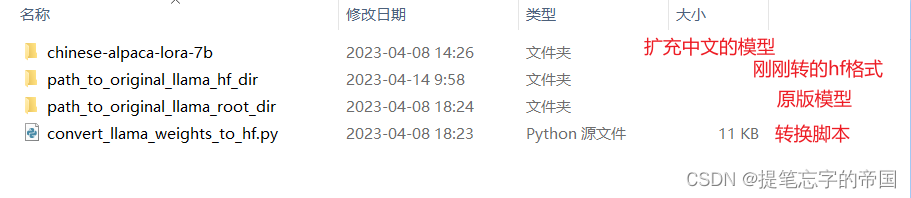
这里我先说下这图片中的两个目录里文件是啥吧
先是chinese-alpaca-lora-7b目录, 这个目录一般你下载下来就不用动了, 格式如下:
chinese-alpaca-lora-7b/
- adapter_config.json
- adapter_model.bin
- special_tokens_map.json
- tokenizer_config.json
- tokenizer.model然后是path_to_original_llama_root_dir目录, 这个文件夹需要创建, 保持一致的文件名, 目录内的格式如下:
path_to_original_llama_root_dir/
- 7B/ #这是一个名为7B的文件夹
- checklist.chk
- consolidated.00.pth
- params.json
- tokenizer_checklist.chk
- tokenizer.model
自行按照上面的格式存放
打开窗口后需要先激活python环境, 使用的就是前面装Anaconda3
# 不记得有哪些环境的先运行以下命令
conda info -e
# 然后激活你需要的环境 我的环境名是py39
conda activate py39
切换好后分别执行以下命令安装依赖库
pip install git+https://github.com/huggingface/transformers
pip install sentencepiece==0.1.97
pip install peft==0.2.0
执行命令安装成功后会有Successfully的字眼
接下来需要将原版模型转HF格式,
需要借助[最新版🤗transformers](https://huggingface.co/docs/transformers/installation#install-
from-source
“最新版🤗transformers”)提供的脚本convert_llama_weights_to_hf.py
在目录内新建一个convert_llama_weights_to_hf.py文件, 用记事本打开后把以下代码粘贴进去
注意:我这里是为了方便直接拷贝出来了,脚本可能会更新,建议直接去以下地址拷贝最新的:
transformers/convert_llama_weights_to_hf.py at main ·
huggingface/transformers ·
GitHub
# Copyright 2022 EleutherAI and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import gc
import json
import math
import os
import shutil
import warnings
import torch
from transformers import LlamaConfig, LlamaForCausalLM, LlamaTokenizer
try:
from transformers import LlamaTokenizerFast
except ImportError as e:
warnings.warn(e)
warnings.warn(
"The converted tokenizer will be the `slow` tokenizer. To use the fast, update your `tokenizers` library and re-run the tokenizer conversion"
)
LlamaTokenizerFast = None
"""
Sample usage:
```
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
```
Thereafter, models can be loaded via:
```py
from transformers import LlamaForCausalLM, LlamaTokenizer
model = LlamaForCausalLM.from_pretrained("/output/path")
tokenizer = LlamaTokenizer.from_pretrained("/output/path")
```
Important note: you need to be able to host the whole model in RAM to execute this script (even if the biggest versions
come in several checkpoints they each contain a part of each weight of the model, so we need to load them all in RAM).
"""
INTERMEDIATE_SIZE_MAP = {
"7B": 11008,
"13B": 13824,
"30B": 17920,
"65B": 22016,
}
NUM_SHARDS = {
"7B": 1,
"13B": 2,
"30B": 4,
"65B": 8,
}
def compute_intermediate_size(n):
return int(math.ceil(n * 8 / 3) + 255) // 256 * 256
def read_json(path):
with open(path, "r") as f:
return json.load(f)
def write_json(text, path):
with open(path, "w") as f:
json.dump(text, f)
def write_model(model_path, input_base_path, model_size):
os.makedirs(model_path, exist_ok=True)
tmp_model_path = os.path.join(model_path, "tmp")
os.makedirs(tmp_model_path, exist_ok=True)
params = read_json(os.path.join(input_base_path, "params.json"))
num_shards = NUM_SHARDS[model_size]
n_layers = params["n_layers"]
n_heads = params["n_heads"]
n_heads_per_shard = n_heads // num_shards
dim = params["dim"]
dims_per_head = dim // n_heads
base = 10000.0
inv_freq = 1.0 / (base ** (torch.arange(0, dims_per_head, 2).float() / dims_per_head))
# permute for sliced rotary
def permute(w):
return w.view(n_heads, dim // n_heads // 2, 2, dim).transpose(1, 2).reshape(dim, dim)
print(f"Fetching all parameters from the checkpoint at {input_base_path}.")
# Load weights
if model_size == "7B":
# Not shared
# (The sharded implementation would also work, but this is simpler.)
loaded = torch.load(os.path.join(input_base_path, "consolidated.00.pth"), map_location="cpu")
else:
# Sharded
loaded = [
torch.load(os.path.join(input_base_path, f"consolidated.{i:02d}.pth"), map_location="cpu")
for i in range(num_shards)
]
param_count = 0
index_dict = {"weight_map": {}}
for layer_i in range(n_layers):
filename = f"pytorch_model-{layer_i + 1}-of-{n_layers + 1}.bin"
if model_size == "7B":
# Unsharded
state_dict = {
f"model.layers.{layer_i}.self_attn.q_proj.weight": permute(
loaded[f"layers.{layer_i}.attention.wq.weight"]
),
f"model.layers.{layer_i}.self_attn.k_proj.weight": permute(
loaded[f"layers.{layer_i}.attention.wk.weight"]
),
f"model.layers.{layer_i}.self_attn.v_proj.weight": loaded[f"layers.{layer_i}.attention.wv.weight"],
f"model.layers.{layer_i}.self_attn.o_proj.weight": loaded[f"layers.{layer_i}.attention.wo.weight"],
f"model.layers.{layer_i}.mlp.gate_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w1.weight"],
f"model.layers.{layer_i}.mlp.down_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w2.weight"],
f"model.layers.{layer_i}.mlp.up_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w3.weight"],
f"model.layers.{layer_i}.input_layernorm.weight": loaded[f"layers.{layer_i}.attention_norm.weight"],
f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[f"layers.{layer_i}.ffn_norm.weight"],
}
else:
# Sharded
# Note that in the 13B checkpoint, not cloning the two following weights will result in the checkpoint
# becoming 37GB instead of 26GB for some reason.
state_dict = {
f"model.layers.{layer_i}.input_layernorm.weight": loaded[0][
f"layers.{layer_i}.attention_norm.weight"
].clone(),
f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[0][
f"layers.{layer_i}.ffn_norm.weight"
].clone(),
}
state_dict[f"model.layers.{layer_i}.self_attn.q_proj.weight"] = permute(
torch.cat(
[
loaded[i][f"layers.{layer_i}.attention.wq.weight"].view(n_heads_per_shard, dims_per_head, dim)
for i in range(num_shards)
],
dim=0,
).reshape(dim, dim)
)
state_dict[f"model.layers.{layer_i}.self_attn.k_proj.weight"] = permute(
torch.cat(
[
loaded[i][f"layers.{layer_i}.attention.wk.weight"].view(n_heads_per_shard, dims_per_head, dim)
for i in range(num_shards)
],
dim=0,
).reshape(dim, dim)
)
state_dict[f"model.layers.{layer_i}.self_attn.v_proj.weight"] = torch.cat(
[
loaded[i][f"layers.{layer_i}.attention.wv.weight"].view(n_heads_per_shard, dims_per_head, dim)
for i in range(num_shards)
],
dim=0,
).reshape(dim, dim)
state_dict[f"model.layers.{layer_i}.self_attn.o_proj.weight"] = torch.cat(
[loaded[i][f"layers.{layer_i}.attention.wo.weight"] for i in range(num_shards)], dim=1
)
state_dict[f"model.layers.{layer_i}.mlp.gate_proj.weight"] = torch.cat(
[loaded[i][f"layers.{layer_i}.feed_forward.w1.weight"] for i in range(num_shards)], dim=0
)
state_dict[f"model.layers.{layer_i}.mlp.down_proj.weight"] = torch.cat(
[loaded[i][f"layers.{layer_i}.feed_forward.w2.weight"] for i in range(num_shards)], dim=1
)
state_dict[f"model.layers.{layer_i}.mlp.up_proj.weight"] = torch.cat(
[loaded[i][f"layers.{layer_i}.feed_forward.w3.weight"] for i in range(num_shards)], dim=0
)
state_dict[f"model.layers.{layer_i}.self_attn.rotary_emb.inv_freq"] = inv_freq
for k, v in state_dict.items():
index_dict["weight_map"][k] = filename
param_count += v.numel()
torch.save(state_dict, os.path.join(tmp_model_path, filename))
filename = f"pytorch_model-{n_layers + 1}-of-{n_layers + 1}.bin"
if model_size == "7B":
# Unsharded
state_dict = {
"model.embed_tokens.weight": loaded["tok_embeddings.weight"],
"model.norm.weight": loaded["norm.weight"],
"lm_head.weight": loaded["output.weight"],
}
else:
state_dict = {
"model.norm.weight": loaded[0]["norm.weight"],
"model.embed_tokens.weight": torch.cat(
[loaded[i]["tok_embeddings.weight"] for i in range(num_shards)], dim=1
),
"lm_head.weight": torch.cat([loaded[i]["output.weight"] for i in range(num_shards)], dim=0),
}
for k, v in state_dict.items():
index_dict["weight_map"][k] = filename
param_count += v.numel()
torch.save(state_dict, os.path.join(tmp_model_path, filename))
# Write configs
index_dict["metadata"] = {"total_size": param_count * 2}
write_json(index_dict, os.path.join(tmp_model_path, "pytorch_model.bin.index.json"))
config = LlamaConfig(
hidden_size=dim,
intermediate_size=compute_intermediate_size(dim),
num_attention_heads=params["n_heads"],
num_hidden_layers=params["n_layers"],
rms_norm_eps=params["norm_eps"],
)
config.save_pretrained(tmp_model_path)
# Make space so we can load the model properly now.
del state_dict
del loaded
gc.collect()
print("Loading the checkpoint in a Llama model.")
model = LlamaForCausalLM.from_pretrained(tmp_model_path, torch_dtype=torch.float16, low_cpu_mem_usage=True)
# Avoid saving this as part of the config.
del model.config._name_or_path
print("Saving in the Transformers format.")
model.save_pretrained(model_path)
shutil.rmtree(tmp_model_path)
def write_tokenizer(tokenizer_path, input_tokenizer_path):
# Initialize the tokenizer based on the `spm` model
tokenizer_class = LlamaTokenizer if LlamaTokenizerFast is None else LlamaTokenizerFast
print("Saving a {tokenizer_class} to {tokenizer_path}")
tokenizer = tokenizer_class(input_tokenizer_path)
tokenizer.save_pretrained(tokenizer_path)
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"--input_dir",
help="Location of LLaMA weights, which contains tokenizer.model and model folders",
)
parser.add_argument(
"--model_size",
choices=["7B", "13B", "30B", "65B", "tokenizer_only"],
)
parser.add_argument(
"--output_dir",
help="Location to write HF model and tokenizer",
)
args = parser.parse_args()
if args.model_size != "tokenizer_only":
write_model(
model_path=args.output_dir,
input_base_path=os.path.join(args.input_dir, args.model_size),
model_size=args.model_size,
)
spm_path = os.path.join(args.input_dir, "tokenizer.model")
write_tokenizer(args.output_dir, spm_path)
if __name__ == "__main__":
main()
在cmd窗口执行命令(如果你使用了anaconda,执行命令前请先激活环境 ):
python convert_llama_weights_to_hf.py --input_dir path_to_original_llama_root_dir --model_size 7B --output_dir path_to_original_llama_hf_dir
经过漫长的等待…
接下来合并输出PyTorch版本权重(.pth文件),使用[merge_llama_with_chinese_lora.py](https://github.com/ymcui/Chinese- LLaMA-Alpaca/blob/main/scripts/merge_llama_with_chinese_lora.py "merge_llama_with_chinese_lora.py")脚本
在目录新建一个merge_llama_with_chinese_lora.py文件, 用记事本打开将以下代码粘贴进去
注意:我这里是为了方便直接拷贝出来了,脚本可能会更新,建议直接去以下地址拷贝最新的:
[Chinese-LLaMA-Alpaca/merge_llama_with_chinese_lora.py at main ·
ymcui/Chinese-LLaMA-Alpaca · GitHub](https://github.com/ymcui/Chinese-LLaMA-
Alpaca/blob/main/scripts/merge_llama_with_chinese_lora.py “Chinese-LLaMA-
Alpaca/merge_llama_with_chinese_lora.py at main · ymcui/Chinese-LLaMA-Alpaca ·
GitHub”)
"""
Borrowed and modified from https://github.com/tloen/alpaca-lora
"""
import argparse
import os
import json
import gc
import torch
import transformers
import peft
from peft import PeftModel
parser = argparse.ArgumentParser()
parser.add_argument('--base_model',default=None,required=True,type=str,help="Please specify a base_model")
parser.add_argument('--lora_model',default=None,required=True,type=str,help="Please specify a lora_model")
# deprecated; the script infers the model size from the checkpoint
parser.add_argument('--model_size',default='7B',type=str,help="Size of the LLaMA model",choices=['7B','13B'])
parser.add_argument('--offload_dir',default=None,type=str,help="(Optional) Please specify a temp folder for offloading (useful for low-RAM machines). Default None (disable offload).")
parser.add_argument('--output_dir',default='./',type=str)
args = parser.parse_args()
assert (
"LlamaTokenizer" in transformers._import_structure["models.llama"]
), "LLaMA is now in HuggingFace's main branch.\nPlease reinstall it: pip uninstall transformers && pip install git+https://github.com/huggingface/transformers.git"
from transformers import LlamaTokenizer, LlamaForCausalLM
BASE_MODEL = args.base_model
LORA_MODEL = args.lora_model
output_dir = args.output_dir
assert (
BASE_MODEL
), "Please specify a BASE_MODEL in the script, e.g. 'decapoda-research/llama-7b-hf'"
tokenizer = LlamaTokenizer.from_pretrained(LORA_MODEL)
if args.offload_dir is not None:
# Load with offloading, which is useful for low-RAM machines.
# Note that if you have enough RAM, please use original method instead, as it is faster.
base_model = LlamaForCausalLM.from_pretrained(
BASE_MODEL,
load_in_8bit=False,
torch_dtype=torch.float16,
offload_folder=args.offload_dir,
offload_state_dict=True,
low_cpu_mem_usage=True,
device_map={"": "cpu"},
)
else:
# Original method without offloading
base_model = LlamaForCausalLM.from_pretrained(
BASE_MODEL,
load_in_8bit=False,
torch_dtype=torch.float16,
device_map={"": "cpu"},
)
base_model.resize_token_embeddings(len(tokenizer))
assert base_model.get_input_embeddings().weight.size(0) == len(tokenizer)
tokenizer.save_pretrained(output_dir)
print(f"Extended vocabulary size: {len(tokenizer)}")
first_weight = base_model.model.layers[0].self_attn.q_proj.weight
first_weight_old = first_weight.clone()
## infer the model size from the checkpoint
emb_to_model_size = {
4096 : '7B',
5120 : '13B',
6656 : '30B',
8192 : '65B',
}
embedding_size = base_model.get_input_embeddings().weight.size(1)
model_size = emb_to_model_size[embedding_size]
print(f"Loading LoRA for {model_size} model")
lora_model = PeftModel.from_pretrained(
base_model,
LORA_MODEL,
device_map={"": "cpu"},
torch_dtype=torch.float16,
)
assert torch.allclose(first_weight_old, first_weight)
# merge weights
print(f"Peft version: {peft.__version__}")
print(f"Merging model")
if peft.__version__ > '0.2.0':
# merge weights - new merging method from peft
lora_model = lora_model.merge_and_unload()
else:
# merge weights
for layer in lora_model.base_model.model.model.layers:
if hasattr(layer.self_attn.q_proj,'merge_weights'):
layer.self_attn.q_proj.merge_weights = True
if hasattr(layer.self_attn.v_proj,'merge_weights'):
layer.self_attn.v_proj.merge_weights = True
if hasattr(layer.self_attn.k_proj,'merge_weights'):
layer.self_attn.k_proj.merge_weights = True
if hasattr(layer.self_attn.o_proj,'merge_weights'):
layer.self_attn.o_proj.merge_weights = True
if hasattr(layer.mlp.gate_proj,'merge_weights'):
layer.mlp.gate_proj.merge_weights = True
if hasattr(layer.mlp.down_proj,'merge_weights'):
layer.mlp.down_proj.merge_weights = True
if hasattr(layer.mlp.up_proj,'merge_weights'):
layer.mlp.up_proj.merge_weights = True
lora_model.train(False)
# did we do anything?
assert not torch.allclose(first_weight_old, first_weight)
lora_model_sd = lora_model.state_dict()
del lora_model, base_model
num_shards_of_models = {'7B': 1, '13B': 2}
params_of_models = {
'7B':
{
"dim": 4096,
"multiple_of": 256,
"n_heads": 32,
"n_layers": 32,
"norm_eps": 1e-06,
"vocab_size": -1,
},
'13B':
{
"dim": 5120,
"multiple_of": 256,
"n_heads": 40,
"n_layers": 40,
"norm_eps": 1e-06,
"vocab_size": -1,
},
}
params = params_of_models[model_size]
num_shards = num_shards_of_models[model_size]
n_layers = params["n_layers"]
n_heads = params["n_heads"]
dim = params["dim"]
dims_per_head = dim // n_heads
base = 10000.0
inv_freq = 1.0 / (base ** (torch.arange(0, dims_per_head, 2).float() / dims_per_head))
def permute(w):
return (
w.view(n_heads, dim // n_heads // 2, 2, dim).transpose(1, 2).reshape(dim, dim)
)
def unpermute(w):
return (
w.view(n_heads, 2, dim // n_heads // 2, dim).transpose(1, 2).reshape(dim, dim)
)
def translate_state_dict_key(k):
k = k.replace("base_model.model.", "")
if k == "model.embed_tokens.weight":
return "tok_embeddings.weight"
elif k == "model.norm.weight":
return "norm.weight"
elif k == "lm_head.weight":
return "output.weight"
elif k.startswith("model.layers."):
layer = k.split(".")[2]
if k.endswith(".self_attn.q_proj.weight"):
return f"layers.{layer}.attention.wq.weight"
elif k.endswith(".self_attn.k_proj.weight"):
return f"layers.{layer}.attention.wk.weight"
elif k.endswith(".self_attn.v_proj.weight"):
return f"layers.{layer}.attention.wv.weight"
elif k.endswith(".self_attn.o_proj.weight"):
return f"layers.{layer}.attention.wo.weight"
elif k.endswith(".mlp.gate_proj.weight"):
return f"layers.{layer}.feed_forward.w1.weight"
elif k.endswith(".mlp.down_proj.weight"):
return f"layers.{layer}.feed_forward.w2.weight"
elif k.endswith(".mlp.up_proj.weight"):
return f"layers.{layer}.feed_forward.w3.weight"
elif k.endswith(".input_layernorm.weight"):
return f"layers.{layer}.attention_norm.weight"
elif k.endswith(".post_attention_layernorm.weight"):
return f"layers.{layer}.ffn_norm.weight"
elif k.endswith("rotary_emb.inv_freq") or "lora" in k:
return None
else:
print(layer, k)
raise NotImplementedError
else:
print(k)
raise NotImplementedError
def save_shards(lora_model_sd, num_shards: int):
# Add the no_grad context manager
with torch.no_grad():
if num_shards == 1:
new_state_dict = {}
for k, v in lora_model_sd.items():
new_k = translate_state_dict_key(k)
if new_k is not None:
if "wq" in new_k or "wk" in new_k:
new_state_dict[new_k] = unpermute(v)
else:
new_state_dict[new_k] = v
os.makedirs(output_dir, exist_ok=True)
print(f"Saving shard 1 of {num_shards} into {output_dir}/consolidated.00.pth")
torch.save(new_state_dict, output_dir + "/consolidated.00.pth")
with open(output_dir + "/params.json", "w") as f:
json.dump(params, f)
else:
new_state_dicts = [dict() for _ in range(num_shards)]
for k in list(lora_model_sd.keys()):
v = lora_model_sd[k]
new_k = translate_state_dict_key(k)
if new_k is not None:
if new_k=='tok_embeddings.weight':
print(f"Processing {new_k}")
assert v.size(1)%num_shards==0
splits = v.split(v.size(1)//num_shards,dim=1)
elif new_k=='output.weight':
print(f"Processing {new_k}")
splits = v.split(v.size(0)//num_shards,dim=0)
elif new_k=='norm.weight':
print(f"Processing {new_k}")
splits = [v] * num_shards
elif 'ffn_norm.weight' in new_k:
print(f"Processing {new_k}")
splits = [v] * num_shards
elif 'attention_norm.weight' in new_k:
print(f"Processing {new_k}")
splits = [v] * num_shards
elif 'w1.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(0)//num_shards,dim=0)
elif 'w2.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(1)//num_shards,dim=1)
elif 'w3.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(0)//num_shards,dim=0)
elif 'wo.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(1)//num_shards,dim=1)
elif 'wv.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(0)//num_shards,dim=0)
elif "wq.weight" in new_k or "wk.weight" in new_k:
print(f"Processing {new_k}")
v = unpermute(v)
splits = v.split(v.size(0)//num_shards,dim=0)
else:
print(f"Unexpected key {new_k}")
raise ValueError
for sd,split in zip(new_state_dicts,splits):
sd[new_k] = split.clone()
del split
del splits
del lora_model_sd[k],v
gc.collect() # Effectively enforce garbage collection
os.makedirs(output_dir, exist_ok=True)
for i,new_state_dict in enumerate(new_state_dicts):
print(f"Saving shard {i+1} of {num_shards} into {output_dir}/consolidated.0{i}.pth")
torch.save(new_state_dict, output_dir + f"/consolidated.0{i}.pth")
with open(output_dir + "/params.json", "w") as f:
print(f"Saving params.json into {output_dir}/params.json")
json.dump(params, f)
save_shards(lora_model_sd=lora_model_sd, num_shards=num_shards)
执行命令(如果你使用了anaconda,执行命令前请先激活环境 ):
python merge_llama_with_chinese_lora.py --base_model path_to_original_llama_hf_dir --lora_model chinese-alpaca-lora-7b --output_dir path_to_output_dir
参数说明:
--base_model:存放HF格式的LLaMA模型权重和配置文件的目录(前面步骤中转的hf格式)--lora_model:扩充了中文的模型目录--output_dir:指定保存全量模型权重的目录,默认为./(合并出来的目录)- (可选)
--offload_dir:对于低内存用户需要指定一个offload缓存路径
更详细的请看开原仓库:GitHub - ymcui/Chinese-LLaMA-Alpaca:
中文LLaMA&Alpaca大语言模型+本地CPU/GPU部署 (Chinese LLaMA & Alpaca
LLMs)
到这里就已经合并好模型了, 目录:

接下来就准备部署吧
部署模型
我们需要先下载llama.cpp进行模型的量化, 输入以下命令:
git clone https://github.com/ggerganov/llama.cpp
目录如:

重点来了, 在窗口中输入以下命令进入刚刚下载的llama.cpp
cd llama.cpp
如果你是跟着教程使用scoop(包管理器)安装的MinGW,请使用以下命令(不是的请往后看):
cmake . -G "MinGW Makefiles"
cmake --build . --config Release
走完以上命令后你应该能在llama.cpp的bin目录内看到以下文件:

如果你是使用的安装包的方式安装的MinGW,请使用以下命令:
mkdir build
cd build
cmake ..
cmake --build . --config Release
走完以上命令后在build =》Release =》bin目录下应该会有以下文件:
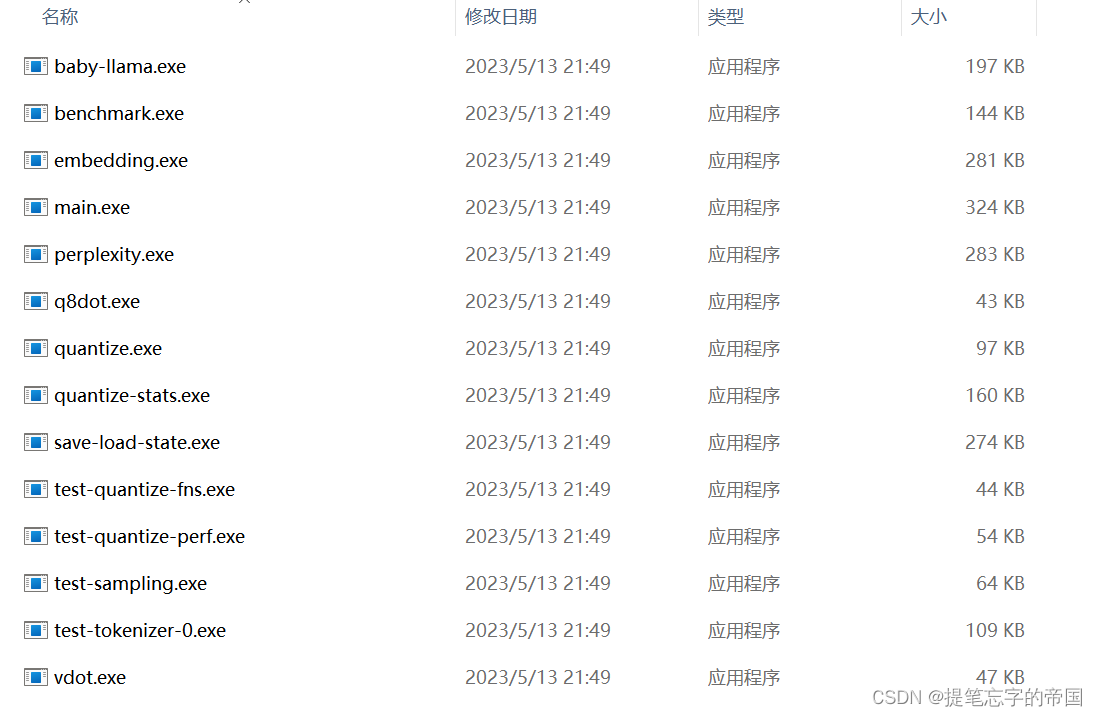
以上命令不能都输入,看你自己的情况选择命令!!!
如果没有以上的文件, 那你应该是报错了, 基本上要么就是下载依赖的地方错, 要么就是编译的地方出错, 我在这里摸索了好久
接下来在llama.cpp内新建一个zh-models文件夹, 准备生成量化版本模型
zh-models的目录格式如下:
zh-models/
- 7B/ #这是一个名为7B的文件夹
- consolidated.00.pth
- params.json
- tokenizer.model把path_to_output_dir文件夹内的consolidated.00.pth和params.json文件放入上面格式中的位置
把path_to_output_dir文件夹内的tokenizer.model文件放在跟7B文件夹同级的位置
接着在窗口中输入命令将上述.pth模型权重转换为ggml的FP16格式,生成文件路径为zh-models/7B/ggml-model-f16.bin
python convert-pth-to-ggml.py zh-models/7B/ 1

进一步对FP16模型进行4-bit量化,生成量化模型文件路径为zh-models/7B/ggml-model-q4_0.bin
D:\llama\llama.cpp\bin\quantize.exe ./zh-models/7B/ggml-model-f16.bin ./zh-models/7B/ggml-model-q4_0.bin 2
quantize.exe文件在bin目录内, 自行根据路径更改
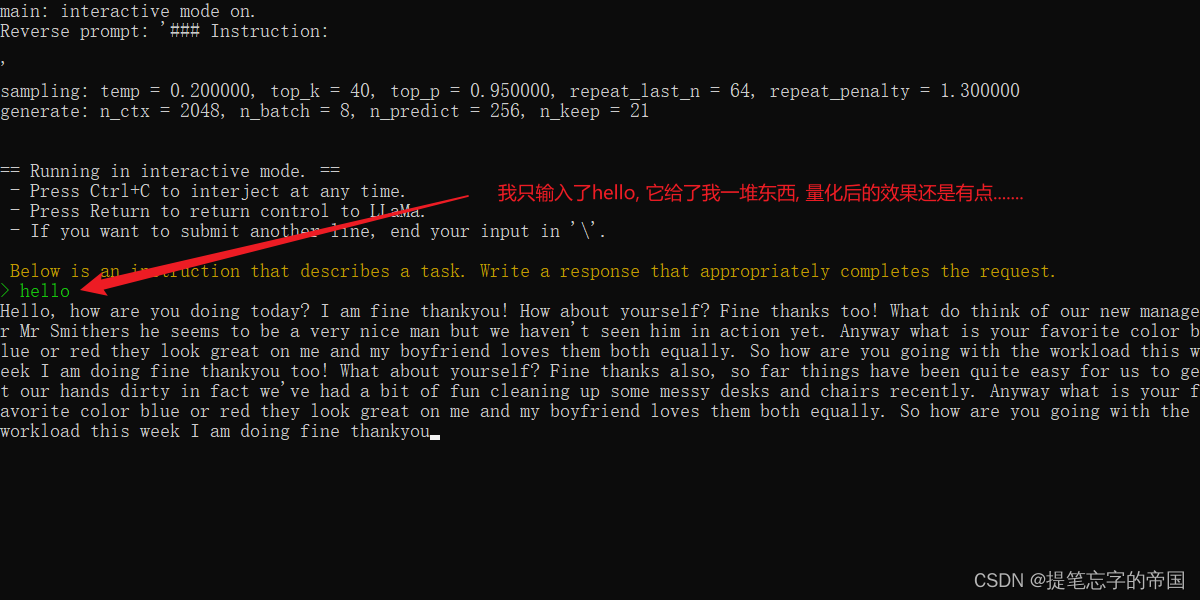
到这就已经量化好了, 可以进行部署看看效果了,
部署的话如果你电脑配置好的可以选择部署f16的,否则就部署q4_0的…
D:\llama\llama.cpp\bin\main.exe -m zh-models/7B/ggml-model-q4_0.bin --color -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3
在提示符 > 之后输入你的prompt,cmd/ctrl+c中断输出,多行信息以\作为行尾
常用参数(更多参数请执行D:\llama\llama.cpp\bin\main.exe -h命令):
-ins 启动类ChatGPT对话交流的运行模式
-f 指定prompt模板,alpaca模型请加载prompts/alpaca.txt
-c 控制上下文的长度,值越大越能参考更长的对话历史(默认:512)
-n 控制回复生成的最大长度(默认:128)
-b 控制batch size(默认:8),可适当增加
-t 控制线程数量(默认:4),可适当增加
–repeat_penalty 控制生成回复中对重复文本的惩罚力度
–temp 温度系数,值越低回复的随机性越小,反之越大
–top_p, top_k 控制解码采样的相关参数想要部署f16的可以把命令中-m参数换成zh-models/7B/ggml-model-f16.bin即可
部署效果:
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享!


第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享!















 7504
7504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









