






大模型微调是机器学习中的一项重要技术,旨在帮助我们降低成本,进一步提高模型的性能。具体来说,大模型微调指的是在现有预训练模型的基础上,根据特定任务数据进行微调,以适应任务的特定需求,以便我们更好地解决各种实际问题。
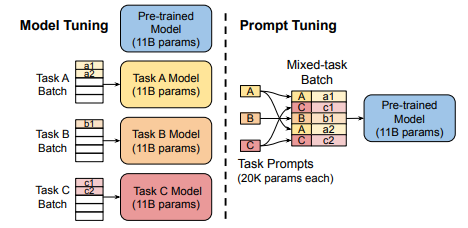
目前较为流行的大模型微调技术是 「PEFT」(Parameter-Efficient Fine Tuning),只对部分的参数进行训练,主要有Prompt Tuning、Prefix Tuning、LoRA、QLoRA等方法。
技术
1、Parameter-efficient fine-tuning of large-scale pre-trained language models
「标题:」 参数高效的大规模预训练语言模型微调
「一句话概括:」 随着预训练语言模型规模的增长,逐渐出现了只优化和改变模型的小部分参数的delta调整方法,这种参数高效的调整方式可以有效地刺激大规模模型,并极大降低计算和存储成本。
2、The Power of Scale for Parameter-Efficient Prompt Tuning
「标题:」 规模化带来的参数高效提示调优的力量
「一句话概括:」 本文通过学习软提示来调节冻结的语言模型,这种提示调优方法随着模型规模的增长而变得更有竞争力,在大模型上几乎匹配全模型调优的性能,还具有鲁棒性和效率优势。
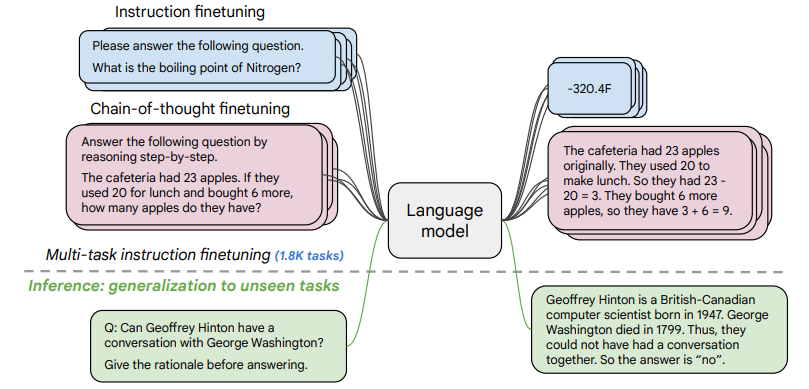
3、Scaling Instruction-Finetuned Language Models
「标题:」 大规模指令微调语言模型
「一句话概括:」 在大规模指令任务上微调语言模型可以极大提升模型在各类设置下的性能和泛化能力,是增强预训练语言模型效果和可用性的通用有效方法。
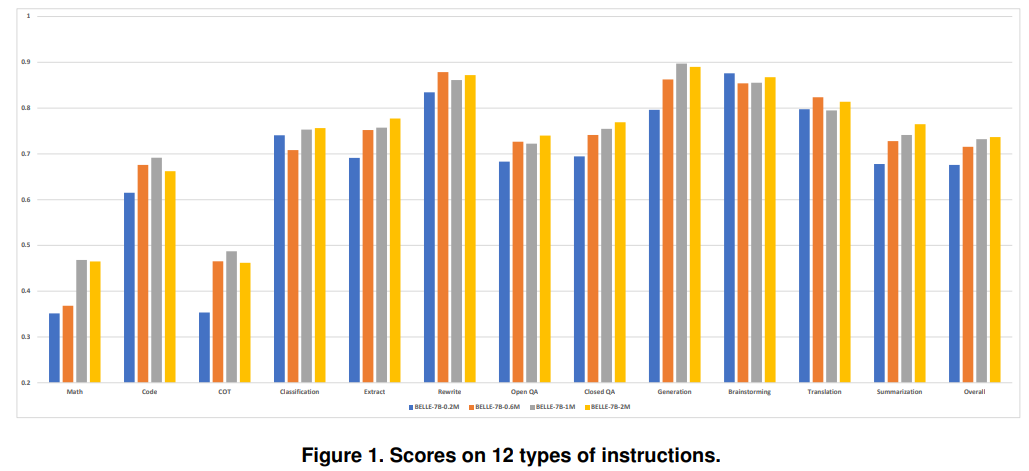
4、Towards Better Instruction Following Language Models for Chinese
「标题:」 面向中文的更好指令遵循语言模型
「一句话概括:」 本文通过在多种公开中文指令数据集上全面评估开源对话模型,发现训练数据的量、质和语言分布等因素对模型性能有重要影响,并通过扩充词表和二次预训练提升了中文领域模型的效果。
5、Exploring the Impact of Instruction Data Scaling on Large Language Models An Empirical Study on Real-World Use Cases
「标题:」 探索指令数据规模化对大规模语言模型的影响——基于真实场景的实证研究
「一句话概括:」 本文通过构建真实场景的评估集,发现指令调优后模型性能随训练数据量的提升而持续改进,但在某些任务上提升乏力,需要考虑数据质量选择、模型和方法的扩展。
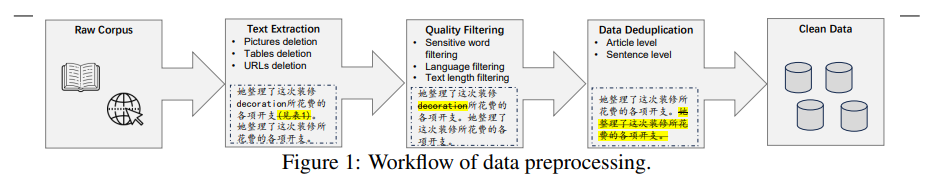
6、ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation
「标题:」 ChatHome:开发并评估一个用于家居装修的领域特定语言模型
「一句话概括:」 本文通过领域自适应预训练和大规模指令调优,开发了ChatHome这一家居装修领域特定语言模型,并在通用和专业评估集上证明了其在提升领域能力的同时保留通用性的效果。
7、A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model
「标题:」 基于中文指令数据的全参数和LoRA调优方式在指令遵循大语言模型上的比较研究
「一句话概括:」 本文通过在中文指令数据集上比较全参数和LoRA调优策略,发现基础模型选择、可学习参数量、训练数据集规模和成本都是影响指令遵循模型性能的关键因素。
8、Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca
「标题:」 为中文LLaMA和Alpaca设计高效和有效的文本编码
「一句话概括:」 本文为LLaMA和Alpaca设计了高效和有效的中文文本编码方法,通过扩充中文词表、中文数据二次预训练和中文指令微调,显著提升了模型对中文的理解和生成能力,在中文按指令执行任务上取得了竞争性能。
9、BloombergGPT: A Large Language Model for Finance(金融)
「标题:」 BloombergGPT:针对金融领域的大规模语言模型
「一句话概括:」 本文提出了BloombergGPT,这是一个针对金融领域训练的500亿参数语言模型,构建了3630亿词元的金融领域数据集进行模型预训练,是目前最大的领域特定数据集之一,BloombergGPT在金融领域任务上明显优于现有模型,同时在通用语言模型基准测试上保持竞争力。
10、XuanYuan 2.0: A Large Chinese Financial Chat Model with Hundreds of Billions Parameters(金融)
「标题:」 轩辕2.0:数百亿参数规模的大型中文金融聊天模型
「一句话概括:」 本文提出了迄今为止最大的中文聊天模型轩辕2.0,基于BLOOM-176B架构,并采用混合调优的新型训练方法来缓解灾难性遗忘问题。通过整合通用领域和特定领域知识,以及预训练和微调阶段的融合,轩辕2.0能够在中文金融领域提供准确、场景适宜的回复。
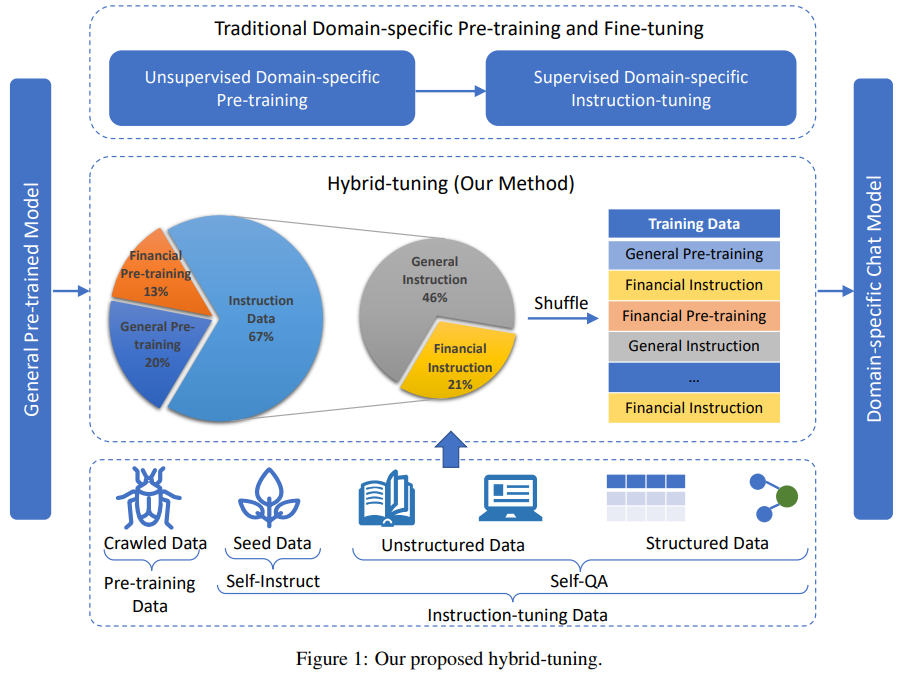
11、Lawyer LLaMA Technical Report(法律)
「标题:」 法律家LLaMA技术报告
「一句话概括:」 本文针对法律领域,探索了如何在持续训练阶段注入领域知识,以及如何设计合适的监督微调任务,来帮助模型处理实际问题;此外,为减轻生成时的虚构问题,添加检索模块在回答查询前提取相关法条作为证据。增强的模型在法律领域问答、法律判断和案例分析任务上都获得显著提升。

12、ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases(法律)
「标题:」 ChatLaw: 集成外部知识源的开源法律大语言模型
「一句话概括:」 本文提出开源法律大语言模型ChatLaw,精心设计法律微调数据集,并结合向量数据库检索与关键词检索的方法有效降低单纯依靠向量检索的不准确率,还通过自注意力机制增强模型处理参考数据错误的能力,从模型层面优化虚构问题,提高问题解析能力。
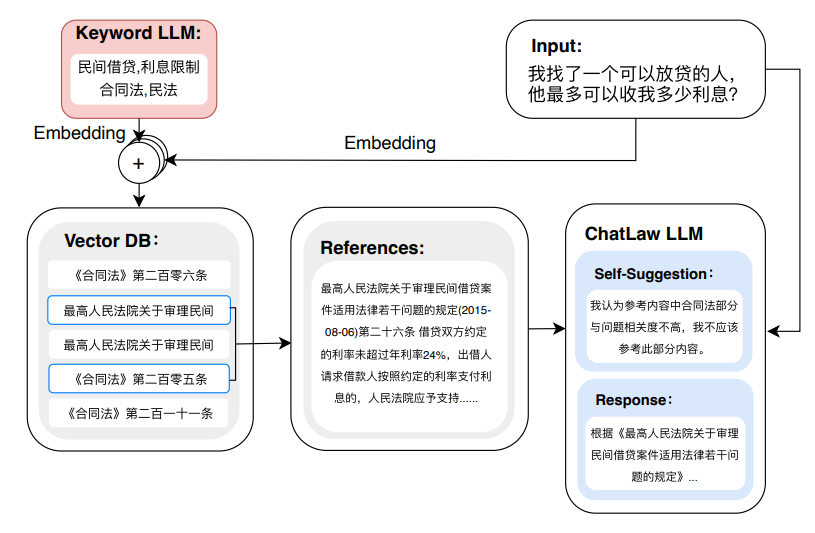
13、LIMA: Less Is More for Alignment
「标题:」 LIMA: 对齐而言,少即是多
「一句话概括:」 通过只用1,000个精选提示训练65B参数的LIMA模型,发现大语言模型的知识主要在预训练中获得,指令调优数据量很小就可产生高质量输出,提示数据越少模型推断能力越强,表明预训练比调优更为关键。
14、How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
「标题:」 骆驼能走多远? 在开放资源上探索指令调优的状态
「一句话概括:」 本文通过在各种开放指令数据集上对6.7B到65B参数量的调优模型进行系统评估,发现单一数据集难以提升所有能力,不同的数据集可强化特定技能,最佳模型平均达到ChatGPT的83%和GPT-4的68%性能,说明基模型与指令调优数据仍需进一步投入以缩小差距。
方法
1、LoRA: Low-Rank Adaptation of Large Language Models
「标题:」 LoRA: 大语言模型的低秩自适应
「一句话概括:」 作者提出了LoRA低秩自适应方法,通过在Transformer架构的每个层中注入可训练的低秩分解矩阵,大大减少下游任务的可训练参数量,相比于对GPT-3 175B完全微调,LoRA可以将可训练参数量减少1万倍,GPU内存需求减少3倍,但性能与完全微调相当或更好。作者还通过实证研究揭示了语言模型自适应中的秩缺陷问题,释明了LoRA的有效性。
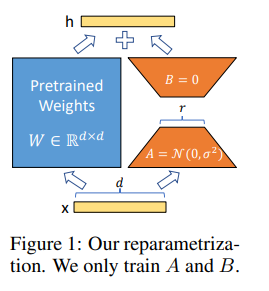
2、Parameter-Efficient Transfer Learning for NLP
「标题:」 NLP中参数高效的迁移学习
「一句话概括:」 作者提出了adapter模块进行迁移,相较于每个任务都要微调整个模型的昂贵方案,adapter为每个任务只增加很少的参数, Tasks可以添加而不需要重新训练以前的模型,原网络的参数保持固定,实现了高度的参数共享。在26项文本分类任务包括GLUE基准测试上,adapter取得接近SOTA的性能,但每个任务只增加很少参数,在GLUE上只增加了3.6%参数就达到完全微调的0.4%性能,大大提升了参数利用效率。
3、MAD-X: An Adapter-Based Framework for Multi-Task Cross-Lingual Transfer
「标题:」 MAD-X: 基于适配器的多任务跨语言迁移框架
「一句话概括:」 作者提出基于adapter的MAD-X框架,通过学习模块化的语言和任务表示,实现对任意任务和语言的高可移植性和参数高效迁移,弥补了当前多语言预训练模型如BERT和XLM-R在低资源语言上的弱点,并在多个跨语言迁移任务上优于或匹敌当前最优方。
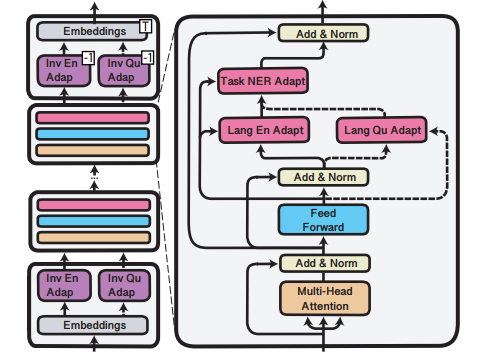
4、Prefix-Tuning: Optimizing Continuous Prompts for Generation
「标题:」 Prefix-Tuning: 优化连续提示进行生成
「一句话概括:」 作者提出了prefix-tuning,这是适用于自然语言生成任务的微调方法的一种轻量化替代方案,可以固定语言模型的参数,仅优化一个小的连续的特定任务向量(称为prefix)。prefix-tuning借鉴提示学习的思想,后续的token可以参照prefix,就像prefix是“虚拟token”一样。在GPT-2的表格到文本生成和BART的摘要任务上,只学习0.1%的参数,prefix-tuning在充分数据下获得了与微调相当的性能,在小数据集上优于微调,并能更好地推广到训练中未见的主题。
5、GPT Understands, Too
「标题:」 GPT也能理解
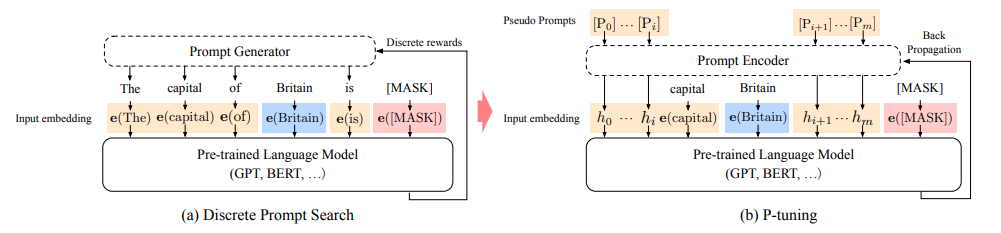
「一句话概括:」 作者提出了P-tuning方法,使用可训练的连续提示嵌入,使GPT在自然语言理解(NLU)任务上优于或匹敌相似规模的BERT。在LAMA知识探测基准测试上,最佳GPT无需在测试时提供额外文本就可以恢复64%的世界知识,比之前最佳提高20%以上。在SuperGLUE基准测试上,GPT在有监督学习中可匹敌相似规模BERT。重要的是,P-tuning也提升了BERT在少样本和全监督场景的表现,大大减少了提示设计的需求,因此P-tuning超越当前在少样本SuperGLUE上的状态oftheart。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









